CrowdMath: A Dataset of Crowdsourced Mathematical Research Discussions
Pith reviewed 2026-06-28 09:43 UTC · model grok-4.3
The pith
CrowdMath dataset shows models follow math discussion sequences at 83-88% accuracy but identify post roles at only 0.42 macro-F1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
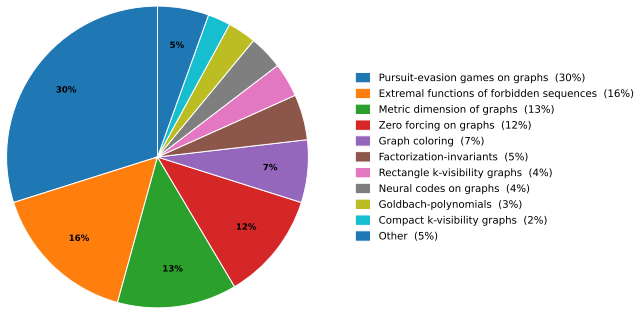
CrowdMath supplies 164 progress chains from the MIT PRIMES-AoPS program, each tracing a multi-participant forum thread from open-problem statement to completed proof, with every post labeled by its functional role in the solution process; benchmarking reveals that models can track the local sequence of discussion but cannot yet assign meaningful significance to individual contributions.
What carries the argument
The annotated progress chain, a sequence of forum posts labeled by functional roles including partial progress, proof completion, erroneous reasoning, and error identification.
If this is right
- Models can follow the local flow of mathematical discussion but not the functional significance of contributions.
- Existing benchmarks on well-specified problems do not measure ability to track open collaborative proofs.
- The dataset supplies a concrete testbed for evaluating incremental collaborative reasoning.
- Performance gaps on role classification point to missing capabilities needed for assisting live research threads.
Where Pith is reading between the lines
- Training on role-labeled chains could improve models' ability to participate in or summarize ongoing proofs.
- The same annotation scheme might be applied to other collaborative platforms to test generality.
- High next-post accuracy combined with low role accuracy suggests models capture surface patterns more readily than underlying proof dynamics.
Load-bearing premise
Expert annotations of post functional roles accurately capture meaningful contributions to the evolving proof and the chosen tasks serve as valid proxies for collaborative reasoning ability.
What would settle it
A model reaching macro-F1 of 0.7 or higher on post-role classification while retaining 83%+ next-post accuracy would indicate the reported gap has closed.
Figures

read the original abstract
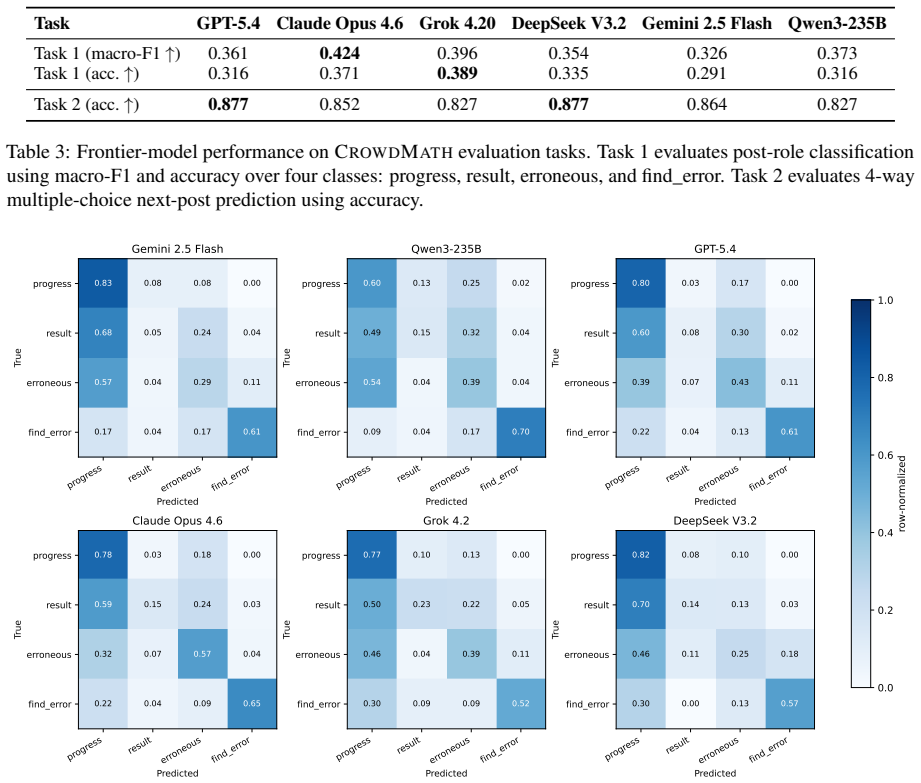
Large language models have made substantial progress on mathematical reasoning, but existing benchmarks typically evaluate well-specified problems with final answers, step-by-step solutions, or complete proofs. They do not capture collaborative open-problem solving: a setting in which participants propose partial arguments, identify gaps or errors in prior steps, repair flawed reasoning, and gradually synthesize incremental contributions into a proof. We introduce CrowdMath, a dataset of 164 expert-annotated progress chains from the MIT PRIMES--Art of Problem Solving (AoPS) CrowdMath program (2016-2025), a collaborative research initiative whose discussions have led to peer-reviewed publications. Each chain traces a multi-participant forum discussion from an open-problem statement to a completed proof. Posts are labeled by their functional roles in the evolving solution process, including partial progress, proof completion, erroneous reasoning, and error identification. We define evaluation tasks and benchmark six frontier models. Models achieve 83-88% accuracy on next-post prediction, suggesting that they can follow the local flow of mathematical discussion. However, they struggle to identify the functional significance of individual contributions with the best model achieving only 0.42 macro-F1 on post-role classification. CrowdMath exposes a gap between solving well-specified mathematical problems and understanding collaborative mathematical progress as it unfolds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CrowdMath, a dataset comprising 164 expert-annotated progress chains drawn from the MIT PRIMES-AoPS CrowdMath program (2016-2025). Each chain follows a multi-participant forum discussion from an open problem to a completed proof, with individual posts labeled according to functional roles (e.g., partial progress, erroneous reasoning, error identification, proof completion). The authors define two tasks—next-post prediction and post-role classification—and benchmark six frontier LLMs, reporting 83-88% accuracy on the former and a best macro-F1 of 0.42 on the latter. They conclude that these results expose a gap between LLMs' performance on well-specified mathematical problems and their ability to model collaborative, open-ended mathematical progress.
Significance. If the dataset construction and task validity hold, CrowdMath would provide a valuable resource for studying LLM limitations in collaborative reasoning settings that more closely resemble actual research than standard math benchmarks. The grounding in discussions that have produced peer-reviewed publications is a concrete strength, as is the focus on incremental, multi-agent contributions rather than final answers.
major comments (3)
- [§3] §3 (Dataset and Annotation): The manuscript reports expert annotations for functional roles but supplies no information on the annotation protocol, number of annotators, or inter-annotator agreement. Because the role labels are the sole basis for the role-classification task and the central gap claim, the absence of these reliability metrics leaves the evaluation results difficult to interpret.
- [§4.2] §4.2 (Role Classification Task): The claim that 0.42 macro-F1 demonstrates inability to track collaborative reasoning rests on the assumption that the role labels cannot be recovered from surface features (post position, length, or lexical patterns). The paper provides no ablation or feature analysis showing that the task requires semantic understanding of the mathematical argument beyond what next-post prediction already captures at 83-88% accuracy.
- [§5] §5 (Experiments and Results): The gap conclusion is load-bearing on the interpretation of the role-classification result as a proxy for collaborative understanding. Without evidence that models fail specifically on the mathematical content of the roles (rather than on any multi-class labeling task), the performance difference does not yet establish the claimed distinction from well-specified problem solving.
minor comments (2)
- [Abstract] The abstract states that discussions have led to peer-reviewed publications but does not quantify how many of the 164 chains correspond to published results; adding this statistic would strengthen the dataset's claimed connection to real research outcomes.
- [§5] Table or figure presenting per-role F1 scores (rather than only macro-F1) would clarify which functional roles drive the low aggregate score.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on dataset documentation and task interpretation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Dataset and Annotation): The manuscript reports expert annotations for functional roles but supplies no information on the annotation protocol, number of annotators, or inter-annotator agreement. Because the role labels are the sole basis for the role-classification task and the central gap claim, the absence of these reliability metrics leaves the evaluation results difficult to interpret.
Authors: We agree that these details are necessary for assessing label reliability. The revised manuscript will expand §3 with a dedicated subsection on the annotation protocol (including guidelines provided to annotators), the number of expert annotators, and inter-annotator agreement metrics (e.g., Fleiss' kappa). revision: yes
-
Referee: [§4.2] §4.2 (Role Classification Task): The claim that 0.42 macro-F1 demonstrates inability to track collaborative reasoning rests on the assumption that the role labels cannot be recovered from surface features (post position, length, or lexical patterns). The paper provides no ablation or feature analysis showing that the task requires semantic understanding of the mathematical argument beyond what next-post prediction already captures at 83-88% accuracy.
Authors: This observation is fair. We will add an ablation analysis to §4.2 comparing LLM performance against simple baselines using only surface features (post position, length, and lexical patterns). This will demonstrate that role classification requires semantic understanding of the mathematical contributions beyond what next-post prediction captures. revision: yes
-
Referee: [§5] §5 (Experiments and Results): The gap conclusion is load-bearing on the interpretation of the role-classification result as a proxy for collaborative understanding. Without evidence that models fail specifically on the mathematical content of the roles (rather than on any multi-class labeling task), the performance difference does not yet establish the claimed distinction from well-specified problem solving.
Authors: We acknowledge the need for clearer linkage. In the revision to §5, we will elaborate on how each role label is defined in terms of specific mathematical actions (e.g., error identification requires detecting flaws in prior reasoning steps) and include per-role performance breakdowns to highlight where models struggle with content-dependent aspects. This will better support the distinction from well-specified problem solving. revision: partial
Circularity Check
No circularity: empirical dataset paper with no derivation chain
full rationale
The paper introduces CrowdMath as a new annotated dataset of forum discussions, defines two evaluation tasks (next-post prediction and role classification), and reports model performance numbers on those tasks. No equations, fitted parameters, predictions derived from inputs, or self-citation chains are present. The central claim rests on the empirical observation that models perform differently on the two tasks; this is a direct reporting of benchmark results rather than any reduction of a result to its own inputs by construction. The skeptic concern about proxy validity is a question of task design, not circularity in a derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[2]
2021 , cdate=
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title=. 2021 , cdate=
2021
-
[3]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[4]
Wang and Kaylie Hausknecht and Jonah Brenner and Danxian Liu and Nianli Peng and Corey Wang and Michael Brenner , booktitle=
Jingxuan Fan and Sarah Martinson and Erik Y. Wang and Kaylie Hausknecht and Jonah Brenner and Danxian Liu and Nianli Peng and Corey Wang and Michael Brenner , booktitle=. 2025 , url=
2025
-
[5]
arXiv preprint arXiv:2505.08744 , year=
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models , author=. arXiv preprint arXiv:2505.08744 , year=
-
[6]
2025 , cdate=
Junyi Ye and Jingyi Gu and Xinyun Zhao and Wenpeng Yin and Grace Guiling Wang , title=. 2025 , cdate=
2025
-
[7]
OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization , author=
-
[8]
2026 , url=
Yiyou Sun and Shawn Hu and Georgia Zhou and Ken Jiankun Zheng and Hannaneh Hajishirzi and Nouha Dziri and Dawn Song , booktitle=. 2026 , url=
2026
-
[9]
Aryan Gulati and Brando Miranda and Eric Chen and Emily Xia and Kai Fronsdal and Bruno de Moraes Dumont and Sanmi Koyejo , booktitle=. Putnam-. 2025 , url=
2025
-
[10]
2024 , cdate=
Shubham Toshniwal and Ivan Moshkov and Sean Narenthiran and Daria Gitman and Fei Jia and Igor Gitman , title=. 2024 , cdate=
2024
-
[11]
CoRR , volume=
Meng Fang and Xiangpeng Wan and Fei Lu and Fei Xing and Kai Zou , title=. CoRR , volume=. 2024 , cdate=
2024
-
[12]
SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers , author=
-
[13]
A Diverse Corpus for Evaluating and Developing E nglish Math Word Problem Solvers
Miao, Shen-yun and Liang, Chao-Chun and Su, Keh-Yih. A Diverse Corpus for Evaluating and Developing E nglish Math Word Problem Solvers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.92
-
[14]
Ling, Wang and Yogatama, Dani and Dyer, Chris and Blunsom, Phil. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1015
-
[15]
Sikai Bai, Haoxi Li, Jie Zhang, Zicong Hong, and Song Guo
Amini, Aida and Gabriel, Saadia and Lin, Shanchuan and Koncel-Kedziorski, Rik and Choi, Yejin and Hajishirzi, Hannaneh. M ath QA : Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, ...
-
[16]
Bofei Gao and Feifan Song and Zhe Yang and Zefan Cai and Yibo Miao and Qingxiu Dong and Lei Li and Chenghao Ma and Liang Chen and Runxin Xu and Zhengyang Tang and Benyou Wang and Daoguang Zan and Shanghaoran Quan and Ge Zhang and Lei Sha and Yichang Zhang and Xuancheng Ren and Tianyu Liu and Baobao Chang , booktitle=. Omni-. 2025 , url=
2025
-
[17]
doi: 10.18653/v1/2024.acl-long.211
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong. O lympiad B ench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. Proceedings of the ...
-
[18]
arXiv preprint arXiv:2412.08819 , year=
Harp: A challenging human-annotated math reasoning benchmark , author=. arXiv preprint arXiv:2412.08819 , year=
-
[19]
Mao, Yujun and Kim, Yoon and Zhou, Yilun. CHAMP : A Competition-level Dataset for Fine-Grained Analyses of LLM s' Mathematical Reasoning Capabilities. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.785
-
[20]
arXiv preprint arXiv:2411.04872 , year=
Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai , author=. arXiv preprint arXiv:2411.04872 , year=
-
[21]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[22]
Forty-second International Conference on Machine Learning , year=
Machine Learning meets Algebraic Combinatorics: A Suite of Datasets Capturing Research-level Conjecturing Ability in Pure Mathematics , author=. Forty-second International Conference on Machine Learning , year=
-
[23]
arXiv preprint arXiv:2603.15617 , year=
HorizonMath: Measuring AI Progress Toward Mathematical Discovery with Automatic Verification , author=. arXiv preprint arXiv:2603.15617 , year=
-
[24]
arXiv preprint arXiv:2309.04295 , year=
Fimo: A challenge formal dataset for automated theorem proving , author=. arXiv preprint arXiv:2309.04295 , year=
-
[25]
2021 , cdate=
Sean Welleck and Jiacheng Liu and Ronan Le Bras and Hanna Hajishirzi and Yejin Choi and Kyunghyun Cho , title=. 2021 , cdate=
2021
-
[26]
Ayers and Dragomir Radev and Jeremy Avigad , title=
Zhangir Azerbayev and Bartosz Piotrowski and Hailey Schoelkopf and Edward W. Ayers and Dragomir Radev and Jeremy Avigad , title=. CoRR , volume=. 2023 , cdate=
2023
-
[27]
International Conference on Learning Representations , year=
miniF2F: a cross-system benchmark for formal Olympiad-level mathematics , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Learning Representations , year=
IsarStep: a Benchmark for High-level Mathematical Reasoning , author=. International Conference on Learning Representations , year=
-
[29]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[30]
Math-Shepherd: Verify and Reinforce
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang. Math-Shepherd: Verify and Reinforce LLM s Step-by-step without Human Annotations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.510
-
[31]
Macina, Jakub and Daheim, Nico and Chowdhury, Sankalan and Sinha, Tanmay and Kapur, Manu and Gurevych, Iryna and Sachan, Mrinmaya. M ath D ial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.372
-
[32]
and Sumner, Tamara
Suresh, Abhijit and Jacobs, Jennifer and Harty, Charis and Perkoff, Margaret and Martin, James H. and Sumner, Tamara. The T alk M oves Dataset: K-12 Mathematics Lesson Transcripts Annotated for Teacher and Student Discursive Moves. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
2022
-
[33]
MathArena: Evaluating
Mislav Balunovic and Jasper Dekoninck and Ivo Petrov and Nikola Jovanovi. MathArena: Evaluating. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.