RouteJudge: An Open Platform for Reproducible and Preference-Aware LLM Routing
Pith reviewed 2026-06-26 21:15 UTC · model grok-4.3
The pith
RouteJudge attributes user preferences from anonymous pairwise comparisons back to the LLM routing strategies that selected each response.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RouteJudge is an online pairwise preference evaluation framework that measures router quality by letting multiple strategies recommend models under the same constraints, presenting the responses anonymously to users, attributing the collected preferences to the originating routers, and storing complete metadata for cost-aware and task-conditioned analysis; it is paired with the ORBIT toolbox that standardizes benchmark loading, router implementation, and submission.
What carries the argument
The anonymous pairwise comparison and preference attribution process that maps user choices to the routing strategies responsible for each response.
If this is right
- Routers can be ranked by the fraction of responses users prefer when the routers operate under matched constraints.
- Evaluations can be broken down by task type, cost, and latency because every record stores that metadata.
- New routing methods can be developed in ORBIT, validated on existing benchmarks, and submitted for continuous online testing.
Where Pith is reading between the lines
- The stored preference data could be used to train or fine-tune routers that directly optimize for user satisfaction rather than proxy metrics.
- Discrepancies may appear between router rankings on static benchmarks and rankings derived from live user preferences.
- The platform supplies a live feedback loop that lets routing research move beyond one-time offline tests.
Load-bearing premise
User preferences collected in anonymous pairwise comparisons can be attributed to specific routing strategies without meaningful interference from presentation order, user fatigue, or other non-router factors.
What would settle it
If collected preference labels correlate more strongly with model identity or response presentation order than with which routing strategy made the selection, the attribution step would fail.
Figures

read the original abstract
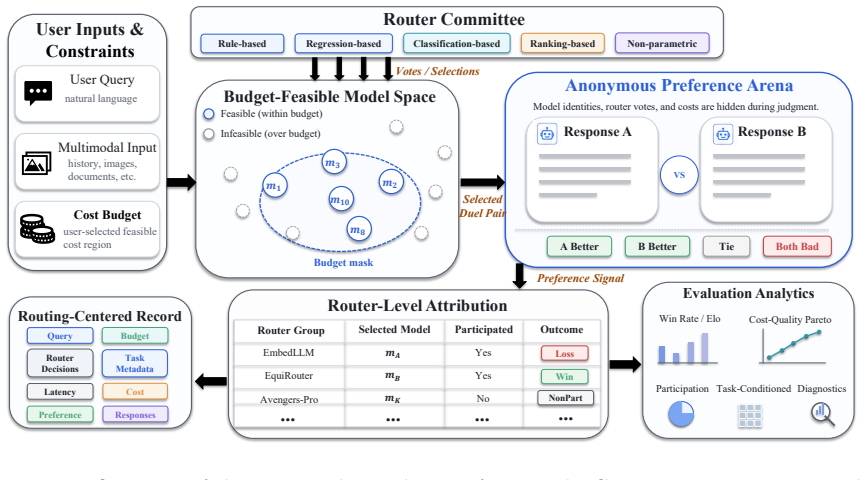
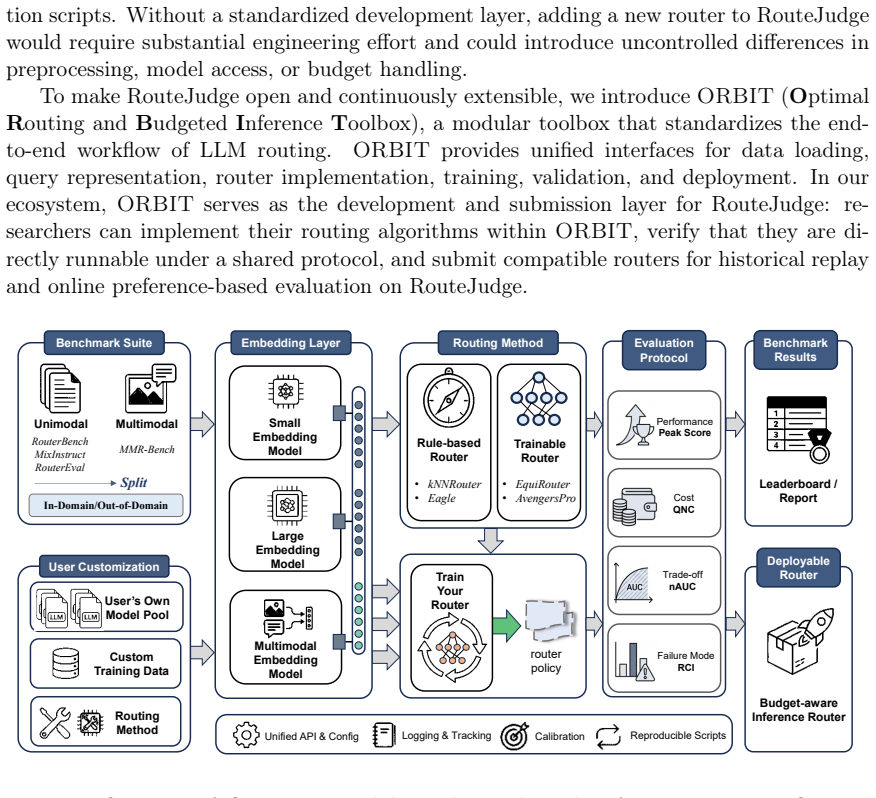
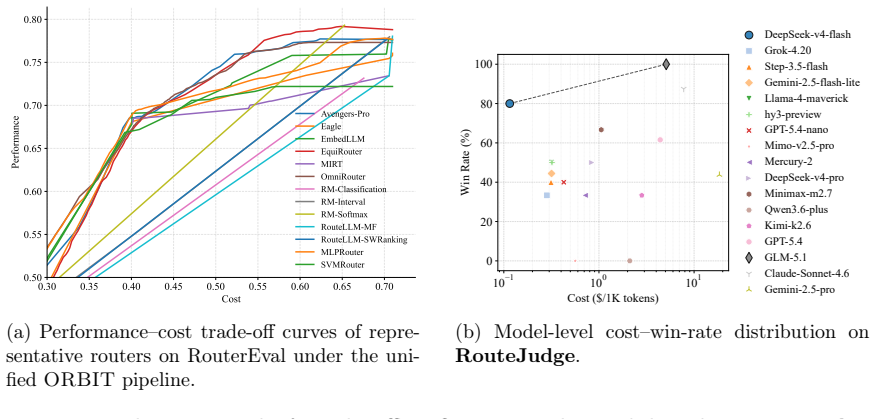
We present RouteJudge, an online pairwise preference evaluation framework for LLM routing systems, with a public platform available at https://routejudge.cn. Different from model-level response evaluation, RouteJudge focuses on router-level decision quality. For each user query, multiple routing strategies independently recommend candidate models under the same model pool and budget constraints. The selected model responses are then presented to users through anonymous pairwise comparisons, and the resulting user preferences are attributed back to the routing strategies behind the compared responses. Each evaluation record stores the query, routing decisions, model responses, preference labels, cost, latency, and task metadata, enabling preference-aware, cost-aware, and task-conditioned analysis of LLM routers. To support the continuous expansion of routing methods in RouteJudge, we further release ORBIT (Optimal Routing and Budgeted Inference Toolbox), a modular and extensible toolbox that standardizes the end-to-end workflow of LLM routing. ORBIT provides unified interfaces for benchmark loading, query representation, router implementation, budget-aware evaluation, and method comparison, allowing researchers to develop and evaluate routing algorithms under consistent protocols. It also serves as the submission and integration layer for RouteJudge: researchers can implement routing methods within ORBIT, validate them on existing routing benchmarks, and submit compatible routers for online preference-based evaluation. The code of ORBIT is available at https://github.com/LAMDA-Model-Reuse/ORBIT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RouteJudge, an online platform for evaluating LLM routing strategies at the router level rather than model level. For each query, multiple routers independently select models from the same pool under budget constraints; the resulting responses are presented to users in anonymous pairwise comparisons, with preferences attributed back to the originating routers. Each record stores the query, routing decisions, responses, preference labels, cost, latency, and task metadata. The paper also releases the ORBIT toolbox, which provides unified interfaces for benchmark loading, query representation, router implementation, budget-aware evaluation, and method comparison, serving as the submission layer for RouteJudge.
Significance. If the attribution mechanism can isolate router decision quality from interface artifacts, the platform would offer a novel, user-preference-driven complement to existing routing benchmarks. The release of ORBIT as a modular, open-source toolbox with standardized protocols is a clear strength that supports reproducibility and community extension of routing methods.
major comments (2)
- [Abstract] Abstract (paragraph on the evaluation record and attribution process): the central claim that preferences can be reliably attributed to routing strategies is load-bearing, yet the description provides no indication of randomization of response order within pairs, counterbalancing across users, session-length limits, or statistical modeling to isolate router effects from presentation biases. Without these, order preferences would be misattributed to whichever router was assigned the first slot.
- [Abstract] Abstract (description of ORBIT integration): while ORBIT is positioned as the submission and integration layer, no concrete protocol is given for how submitted routers are paired in live comparisons or how preference data are aggregated to produce router-level scores, leaving the end-to-end evaluation pipeline underspecified for the claimed reproducibility.
minor comments (2)
- [Abstract] The abstract is dense; expanding the single paragraph on the evaluation loop into a short dedicated section with a diagram of the data flow would improve clarity of the attribution process.
- No mention is made of how the public platform at routejudge.cn handles data privacy or consent for storing user preference labels alongside routing metadata.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on the evaluation record and attribution process): the central claim that preferences can be reliably attributed to routing strategies is load-bearing, yet the description provides no indication of randomization of response order within pairs, counterbalancing across users, session-length limits, or statistical modeling to isolate router effects from presentation biases. Without these, order preferences would be misattributed to whichever router was assigned the first slot.
Authors: We agree that explicit bias controls are essential to support reliable attribution of preferences to routers. The provided abstract is intentionally concise and omits these implementation details. The RouteJudge platform does randomize response order within pairs, applies counterbalancing across users, imposes session limits, and employs statistical modeling to isolate router effects. However, these safeguards are not described in the abstract. We will revise the abstract to note the presence of these measures and add a dedicated paragraph in the methods section detailing the bias-mitigation protocol. revision: yes
-
Referee: [Abstract] Abstract (description of ORBIT integration): while ORBIT is positioned as the submission and integration layer, no concrete protocol is given for how submitted routers are paired in live comparisons or how preference data are aggregated to produce router-level scores, leaving the end-to-end evaluation pipeline underspecified for the claimed reproducibility.
Authors: We acknowledge that the abstract does not supply concrete protocols for router pairing or preference aggregation. The full manuscript positions ORBIT as the submission layer but leaves the live-comparison mechanics high-level. To address the concern, we will add a new subsection describing (1) the pairing protocol that matches submitted routers on identical queries and budgets and (2) the aggregation procedure that converts pairwise preferences into router-level scores with uncertainty estimates. This addition will make the end-to-end pipeline explicit and support the reproducibility claim. revision: yes
Circularity Check
No circularity: platform and toolbox description with no derivations or predictions
full rationale
The paper presents RouteJudge as an online evaluation framework and releases the ORBIT toolbox for standardizing LLM routing workflows. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The central contribution is infrastructural (storing queries, decisions, responses, and labels for later analysis), with no load-bearing steps that reduce to self-definition, self-citation, or renaming of inputs. This is a normal non-finding for a descriptive systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176,
-
[2]
Routerbench: A benchmark for multi- llm routing system
QitianJasonHu, JacobBieker, XiuyuLi, NanJiang, BenjaminKeigwin, GauravRanganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. Routerbench: A benchmark for multi- llm routing system. InarXiv preprint arXiv:2403.12031,
-
[3]
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm-blender: Ensembling large language models with pairwise ranking and generative fusion.arXiv preprint arXiv:2306.02561, 2023a. 15 Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm-blender: Ensembling large language models with pairwise comparison and generative fusion. InACL, 2023b. Hannah R Kirk, Alexander...
-
[4]
Guannan Lai and Han-Jia Ye. When routing collapses: On the degenerate convergence of llm routers.arXiv preprint arXiv:2602.03478,
-
[5]
Guannan Lai, Haoran Hu, Long Chen, Zhenguo Li, and Han-Jia Ye. From sampled out- comes to capability distributions: Rethinking supervision for llm routing.arXiv preprint arXiv:2606.06924,
-
[6]
Mmr-bench: A comprehensive benchmark for multimodal llm routing.arXiv preprint arXiv:2601.17814,
Haoxuan Ma, Guannan Lai, and Han-Jia Ye. Mmr-bench: A comprehensive benchmark for multimodal llm routing.arXiv preprint arXiv:2601.17814,
-
[7]
Omnirouter: Budget and perfor- mance controllable multi-llm routing.arXiv preprint arXiv:2502.20576,
Kai Mei, Wujiang Xu, Shuhang Lin, and Yongfeng Zhang. Omnirouter: Budget and perfor- mance controllable multi-llm routing.arXiv preprint arXiv:2502.20576,
-
[8]
Guillem Ramírez, Alexandra Birch, and Ivan Titov. Optimising calls to large language models with uncertainty-based two-tier selection.arXiv preprint arXiv:2405.02134,
-
[9]
Llm routing with benchmark datasets
Tal Shnitzer, Anthony Ou, Mírian Silva, Kate Soule, Yuekai Sun, Justin Solomon, Neil Thompson, and Mikhail Yurochkin. Llm routing with benchmark datasets. InNeurIPS 2023 Workshop on Distribution Shifts: New Frontiers with Foundation Models,
2023
-
[10]
Clovis Varangot-Reille, Christophe Bouvard, Antoine Gourru, Mathieu Ciancone, Mar- ion Schaeffer, and François Jacquenet. Doing more with less–implementing routing strategies in large language model-based systems: An extended survey.arXiv preprint arXiv:2502.00409,
-
[11]
Mixllm: Dynamic routing in mixed large language models
Xinyuan Wang, Yanchi Liu, Wei Cheng, Xujiang Zhao, Zhengzhang Chen, Wenchao Yu, Yanjie Fu, and Haifeng Chen. Mixllm: Dynamic routing in mixed large language models. arXiv preprint arXiv:2502.18482,
-
[12]
Murong Yue, Jie Zhao, Min Zhang, Liang Du, and Ziyu Yao. Large language model cas- cades with mixture of thoughts representations for cost-efficient reasoning.arXiv preprint arXiv:2310.03094,
-
[13]
Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
Pith/arXiv arXiv 1904
-
[14]
Capability instruction tuning: A new paradigm for dynamic llm routing
Yi-Kai Zhang, De-Chuan Zhan, and Han-Jia Ye. Capability instruction tuning: A new paradigm for dynamic llm routing. InAAAI, 2025a. Yiqun Zhang, Hao Li, Jianhao Chen, Hangfan Zhang, Peng Ye, Lei Bai, and Shuyue Hu. Be- yond gpt-5: Making llms cheaper and better via performance-efficiency optimized routing. InDAI, 2025b. Yiqun Zhang, Hao Li, Chenxu Wang, Li...
-
[15]
18 Appendix A. Candidate Models and Routing Strategies Thisappendixprovidesadditionaldetailsaboutthecandidatemodelpoolandroutingstrate- gies used in the current RouteJudge platform and supported by the ORBIT toolbox. Route- Judge evaluates routers over a shared model pool under the same budget-feasible model space, ensuring that performance differences ar...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.