HARP-VLA: Human-Robot Aligned Representation Learning for Vision-Language-Action Model
Pith reviewed 2026-06-28 22:02 UTC · model grok-4.3
The pith
Limited paired human-robot demonstrations align visual encoders and latent actions to support VLA pretraining on unpaired human videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
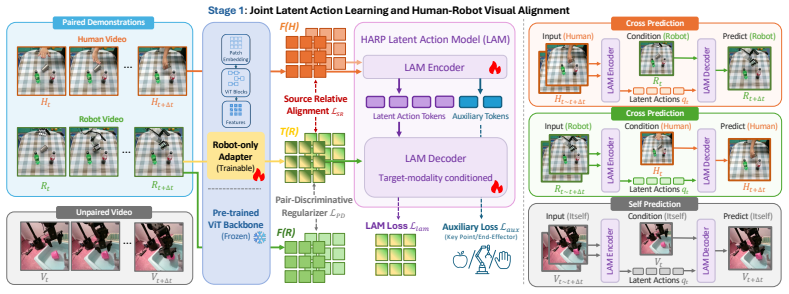
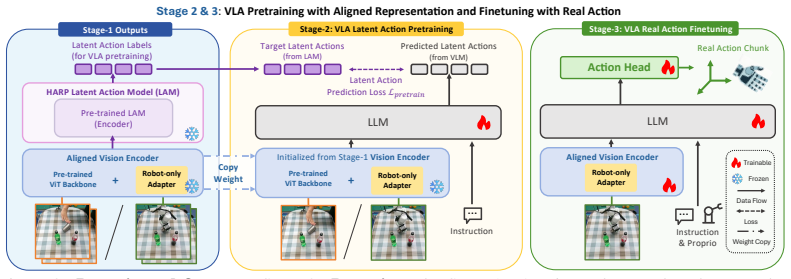
The learned aligned vision encoder and latent action model provide a unified vision and action representation for VLA-style policy learning, where human and robot videos provide vision-language-to-latent-action supervision and a lightweight robot action head grounds latent actions into executable commands.
What carries the argument
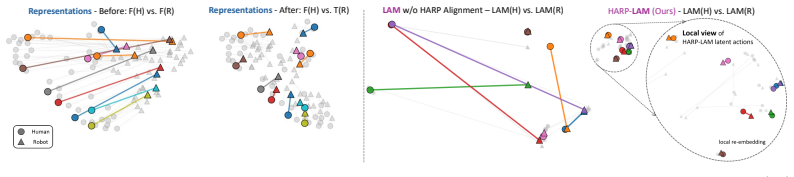
Source-relative pair-discriminative alignment loss that adapts robot representations toward human semantics while preserving pair-level discrimination, together with manipulation-centric auxiliary cues.
Load-bearing premise
A small number of paired human-robot demonstrations can bridge embodiment differences without injecting domain biases into latent actions learned from much larger unpaired video sets.
What would settle it
If policies trained with the aligned representations show no gain over a non-aligned baseline when both use the same human video data, the alignment step would not be contributing.
Figures

read the original abstract
Learning generalizable vision-language-action (VLA) models from large-scale human videos is promising but challenging due to cross-embodiment discrepancies in both visual observations and executable actions. While latent action models reduce the action execution gap by learning action abstractions, they still rely on visual features. Thus, misaligned human and robot visual representations can lead to inconsistencies in policy inputs and induce domain-dependent latent actions, hindering effective co-training with human videos. To address this, we propose HARP, a human-robot aligned representation learning framework for more effective VLA pretraining from human videos. Specifically, HARP uses limited paired human-robot demonstrations as cross-embodiment bridges and abundant unpaired human and robot videos as a scalable dynamics supervision data source. It trains a robot-adapted visual encoder and a latent action model with manipulation-centric auxiliary cues and a source-relative pair-discriminative alignment loss, which adapts robot representations toward human semantics while preserving pair-level discrimination. The learned aligned vision encoder and latent action model provide a unified vision and action representation for VLA-style policy learning, where human and robot videos provide vision-language-to-latent-action supervision and a lightweight robot action head grounds latent actions into executable commands. Experiments on feature visualization, simulation, and realworld manipulation show improved human-robot alignment and downstream policy performance, achieving 4.481 average length on CALVIN ABC$\rightarrow$D and a 7.1\% realworld success rate gain over the strongest baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HARP, a human-robot aligned representation learning framework for VLA pretraining. It leverages limited paired human-robot demonstrations as cross-embodiment bridges together with abundant unpaired videos, training a robot-adapted visual encoder and latent action model via manipulation-centric auxiliary cues and a source-relative pair-discriminative alignment loss. The resulting unified representations are used for VLA-style policy learning with human videos providing vision-language-to-latent-action supervision and a lightweight robot action head for grounding; experiments report 4.481 average length on CALVIN ABC→D and a 7.1% real-world success-rate gain over the strongest baseline.
Significance. If the alignment mechanism demonstrably yields domain-invariant latent actions that generalize across unpaired data, the approach would meaningfully advance scalable VLA training by bridging human video corpora to robot policies. The use of paired demonstrations as explicit bridges is a concrete, testable design choice that could be extended to other cross-embodiment settings.
major comments (2)
- [Abstract / §3] Abstract and §3 (alignment loss description): the claim that the source-relative pair-discriminative alignment loss produces latent actions whose distribution is independent of source (human vs. robot) once unpaired data dominates is not supported by any derivation, invariance bound, or ablation that isolates the paired signal from the unpaired volume. Without such evidence the central unification claim remains unverified.
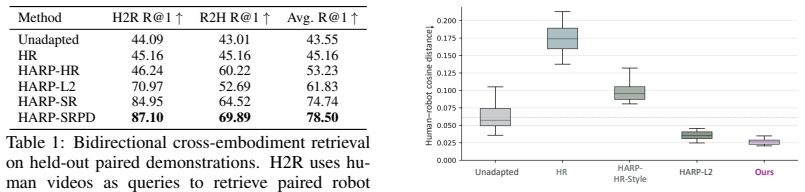
- [Results] Results section (CALVIN and real-world tables): quantitative gains are reported without accompanying controls for the volume of unpaired data, statistical significance tests, or ablations that remove the alignment loss while keeping all other components fixed. This makes it impossible to attribute the 4.481 length and 7.1% gain specifically to the alignment mechanism rather than other factors.
minor comments (2)
- [§3] Notation for the latent action model and the source-relative loss is introduced without an explicit equation or pseudocode block, making the precise objective difficult to reproduce from the text alone.
- [Experiments] Feature visualization figures lack quantitative metrics (e.g., domain classification accuracy or MMD) to accompany the qualitative alignment claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, acknowledging where additional evidence is needed and outlining planned revisions.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (alignment loss description): the claim that the source-relative pair-discriminative alignment loss produces latent actions whose distribution is independent of source (human vs. robot) once unpaired data dominates is not supported by any derivation, invariance bound, or ablation that isolates the paired signal from the unpaired volume. Without such evidence the central unification claim remains unverified.
Authors: We appreciate the referee highlighting this point. The manuscript presents the source-relative pair-discriminative alignment loss as adapting robot representations toward human semantics while preserving pair-level discrimination to enable unified representations for VLA pretraining. No formal derivation or invariance bound is provided; support is empirical via feature visualizations and policy improvements. We will revise the abstract and §3 for precision on the empirical nature of the claim, and add an ablation isolating the paired signal by varying unpaired data volume. revision: yes
-
Referee: [Results] Results section (CALVIN and real-world tables): quantitative gains are reported without accompanying controls for the volume of unpaired data, statistical significance tests, or ablations that remove the alignment loss while keeping all other components fixed. This makes it impossible to attribute the 4.481 length and 7.1% gain specifically to the alignment mechanism rather than other factors.
Authors: We agree that stronger attribution requires additional controls. The reported results include baseline comparisons and alignment visualizations, but lack explicit ablations removing only the alignment loss, unpaired volume controls, and statistical significance. We will add these elements to the results section in revision to better isolate the alignment mechanism's contribution. revision: yes
Circularity Check
No circularity: framework design is self-contained with no reduction to fitted inputs or self-citations
full rationale
The paper introduces HARP as a new framework using paired human-robot demonstrations for alignment via a source-relative pair-discriminative loss plus manipulation-centric cues, then applies the resulting encoder and latent action model to VLA pretraining on unpaired videos. No equations, fitting procedures, or derivation steps are described that would make any claimed prediction equivalent to its inputs by construction. The central claims rest on the proposed loss design and empirical results on CALVIN and real-world tasks rather than any self-citation chain or self-definitional loop. This is the normal case of an independent methodological contribution evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, L. Lid´en, K. Lee, J. Gao, L. S. Zettlemoyer, D. Fox, and M. Seo. Latent action pretraining from videos.ArXiv, abs/2410.11758, 2024. URLhttps://api.semanticscholar.org/ CorpusID:273351190
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.ArXiv, abs/2505.06111, 2025. URLhttps: //api.semanticscholar.org/CorpusID:278481174
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
X. Chen, J. Guo, T. He, C. Zhang, P. Zhang, D. Yang, L. Zhao, and J. Bian. Igor: Image-goal representations are the atomic control units for foundation models in embodied ai. 2024. URL https://api.semanticscholar.org/CorpusID:273811367
2024
-
[5]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video.2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 13226–13233, 2024. URLhttps: //api.semanticscholar.org/CorpusID:273707799
2025
- [6]
- [7]
-
[8]
J. Zhou, T. Ma, K.-Y . Lin, R. Qiu, Z. Wang, and J. Liang. Mitigating the human-robot domain discrepancy in visual pre-training for robotic manipulation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22551–22561, 2024. URLhttps: //api.semanticscholar.org/CorpusID:270619804
2025
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, G. Lam, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. ArXiv, abs/2406.09246, 2024. URLhttps://api.semanticscholar.org/CorpusID: 270440391
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Perts...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, K. Choromanski, T. Ding, D. Driess, K. A. Dubey, C. Finn, P. R. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, 9 A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, S. Levine, H. Michalewski, I. Mordatch, K. Pertsch, K. Rao, K. Reymann...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://api.semanticscholar.org/CorpusID:260293142
-
[13]
O. M. Team, D. Ghosh, H. R. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, Y . L. Tan, P. R. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy.ArXiv, abs/2405.12213, 2024. URL https://api.semanticscholar.org/CorpusID:266379116
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.ArXiv, abs/2410.07864, 2024. URL https://api.semanticscholar.org/CorpusID:273233386
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
J. Gu, S. Kirmani, P. Wohlhart, Y . Lu, M. G. Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakr- ishnan, Z. Xu, P. Sundaresan, P. Xu, H. Su, K. Hausman, C. Finn, Q. H. Vuong, and T. Xiao. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches. ArXiv, abs/2311.01977, 2023. URLhttps://api.semanticscholar.org/CorpusID: 265018996
-
[18]
C. Wang, L. J. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. Mim- icplay: Long-horizon imitation learning by watching human play. InConference on Robot Learning, 2023. URLhttps://api.semanticscholar.org/CorpusID:257205825
2023
-
[19]
Xiong, Q
H. Xiong, Q. Li, Y .-C. Chen, H. Bharadhwaj, S. Sinha, and A. Garg. Learning by watching: Physical imitation of manipulation skills from human videos.2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7827–7834, 2021. URLhttps: //api.semanticscholar.org/CorpusID:231632575
2021
- [20]
-
[21]
K. Dharmarajan, W. Huang, J. Wu, L. Fei-Fei, and R. Zhang. Dream2flow: Bridging video gen- eration and open-world manipulation with 3d object flow.arXiv preprint arXiv:2512.24766, 2025
-
[22]
L. Y . Chen, C. Xu, K. Dharmarajan, M. Z. Irshad, R. Cheng, K. Keutzer, M. Tomizuka, Q. Vuong, and K. Goldberg. Rovi-aug: Robot and viewpoint augmentation for cross- embodiment robot learning.ArXiv, abs/2409.03403, 2024. URLhttps://api. semanticscholar.org/CorpusID:272423529. 10
-
[23]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[24]
A. Jawaid and Y . Xiang. Openego: A large-scale multimodal egocentric dataset for dexterous manipulation.arXiv preprint arXiv:2509.05513, 2025
-
[25]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . My- ers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
- [26]
- [27]
-
[28]
URLhttps://api.semanticscholar.org/CorpusID:276575296
-
[29]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters (RA-L), 7(3):7327–7334, 2022
2022
-
[30]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[31]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
X. Zhu, Y . Liu, H. Li, and J. Chen. Learning generalizable robot policy with human demon- stration video as a prompt, 2025. URLhttps://arxiv.org/abs/2505.20795
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Q. Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European conference on computer vision, pages 38–55. Springer, 2024
2024
-
[35]
Doersch, Y
C. Doersch, Y . Yang, M. Vecerik, D. Gokay, A. Gupta, Y . Aytar, J. Carreira, and A. Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023
2023
-
[36]
R. A. Potamias, J. Zhang, J. Deng, and S. Zafeiriou. Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12242–12254, 2025
2025
- [37]
-
[38]
Yadav and M
M. Yadav and M. A. Alam. Dynamic time warping (dtw) algorithm in speech: a review. International Journal of Research in Electronics and Computer Engineering, 6(1):524–528, 2018
2018
-
[39]
Karamcheti, S
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first Interna- tional Conference on Machine Learning, 2024
2024
-
[40]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[42]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 12 A Appendix A.1 Data Process The objective of paired training data curation is to establish frame-level correspondence between human demon...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.