CORE-Bench: A Comprehensive Benchmark for Code Retrieval in the Era of Agentic Coding
Pith reviewed 2026-06-27 08:23 UTC · model grok-4.3
The pith
CORE-Bench shows embedding models drop sharply on requirement-driven repository search for coding agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
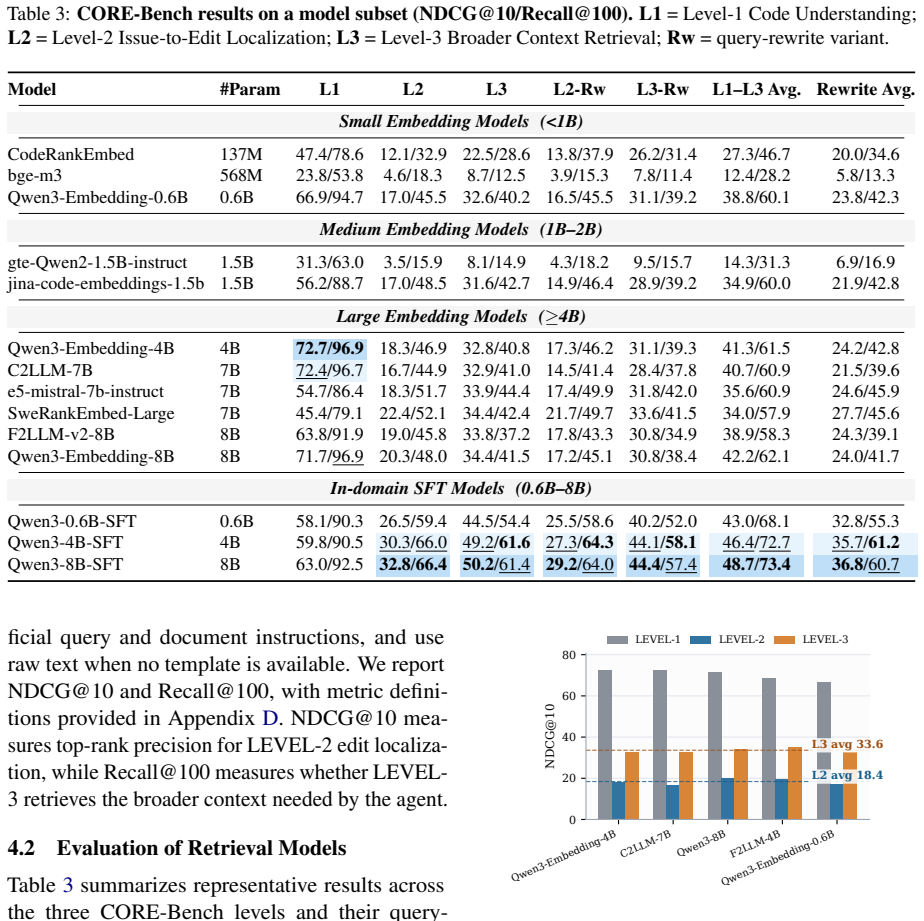
CORE-Bench shows that code retrieval for agentic coding requires navigating concrete repository states, locating files and functions, gathering context, and filtering distractors, a task where existing embedding models suffer a sharp drop relative to traditional snippet matching, though supervised fine-tuning of those models yields significant recovery.
What carries the argument
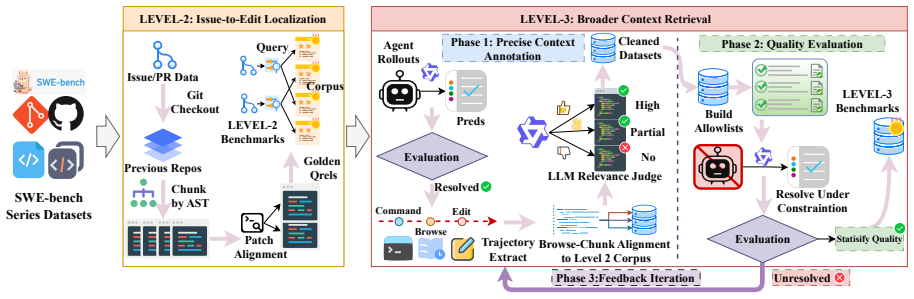
CORE-Bench, a benchmark evaluating code retrieval at three levels (code understanding, issue-to-edit localization, broader context retrieval) built from code-search tasks and SWE-bench instances.
If this is right
- Existing embedding models require task-specific adaptation to perform effectively in agentic coding retrieval.
- Fine-tuning offers an immediate route to improved localization of edits from issue descriptions.
- Progress on the broader context retrieval level would directly support agents that must assemble supporting evidence across multiple files.
- The benchmark supplies a standardized testbed for measuring future gains in requirement-driven search.
Where Pith is reading between the lines
- Agents built on current retrieval components may systematically underperform on tasks that span entire repositories.
- Retrieval methods tuned only on isolated snippets could be a hidden bottleneck in end-to-end coding agent pipelines.
- Extending the benchmark with multi-turn interaction traces would test whether models can maintain context across sequential retrieval steps.
Load-bearing premise
The curated tasks and SWE-bench instances in CORE-Bench accurately reflect the repository search problems that coding agents encounter in practice.
What would settle it
An experiment in which representative embedding models achieve comparable scores on CORE-Bench queries to their scores on traditional docstring-to-function benchmarks, without any fine-tuning, would falsify the reported performance drop.
Figures


read the original abstract
Code retrieval is becoming central to coding agents, but agentic coding requires more than matching a natural-language query to an isolated snippet. Given a user request, a coding agent needs to navigate a concrete repository state, locate relevant files and functions, gather supporting context, and filter similar in-repository distractors. Existing code retrieval benchmarks mainly evaluate docstring-to-function or snippet-level matching, thereby missing this requirement-driven repository search problem. To address this gap, we introduce CORE-Bench, a comprehensive benchmark for code retrieval in the era of agentic coding. CORE-Bench evaluates code retrieval ability at three levels: code understanding, issue-to-edit localization, and broader context retrieval. Built from curated code-search tasks and SWE-bench-series instances, CORE-Bench contains over 180K queries and 106K broader-context relevance labels. Experiments with representative embedding models show a sharp drop from traditional code search to code retrieval in agentic coding settings. Simple supervised fine-tuning of existing embedding models significantly improves performance in this setting, suggesting substantial room for further progress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CORE-Bench, a benchmark for code retrieval in agentic coding. It is constructed from curated code-search tasks and SWE-bench-series instances and contains over 180K queries plus 106K broader-context relevance labels. The benchmark evaluates retrieval at three levels (code understanding, issue-to-edit localization, broader context retrieval). Experiments with embedding models report a sharp performance drop relative to traditional code search, with simple supervised fine-tuning yielding substantial gains.
Significance. If the benchmark instances genuinely require requirement-driven, multi-step repository navigation rather than static snippet matching, the work would be significant for the IR and agentic-coding communities by quantifying a previously under-tested gap and showing that existing embedding models can be improved via fine-tuning. The scale of the released data is a clear asset for future research.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: the description of how SWE-bench-series instances are adapted does not supply concrete details on distractor selection across files, validation that tasks force gathering of supporting context from live repository state, or metrics confirming multi-step navigation is required. This is load-bearing for the central claim of a 'sharp drop' from traditional code search to agentic settings (Abstract).
- [Experiments] Experiments section: the reported performance drops and fine-tuning gains rest on the assumption that the curated tasks accurately represent the requirement-driven repository search problem; without the missing curation and validation details noted above, the evidence supporting this assumption remains moderate.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments both center on the need for greater transparency in how SWE-bench instances were adapted into CORE-Bench. We agree that these details are important for supporting the central claims and will expand the Benchmark Construction section accordingly.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: the description of how SWE-bench-series instances are adapted does not supply concrete details on distractor selection across files, validation that tasks force gathering of supporting context from live repository state, or metrics confirming multi-step navigation is required. This is load-bearing for the central claim of a 'sharp drop' from traditional code search to agentic settings (Abstract).
Authors: We accept this observation. The current manuscript provides only a high-level description of the adaptation process. In the revision we will add a dedicated subsection that specifies: (i) the exact procedure for selecting in-repository distractors (sampling from files outside the minimal edit set while preserving repository structure), (ii) the validation steps performed to ensure each query requires retrieval of supporting context that is not present in any single static snippet, and (iii) quantitative indicators (average number of files touched, dependency depth, and manual review statistics) that confirm multi-step navigation is necessary. These additions will directly underpin the reported performance gap. revision: yes
-
Referee: [Experiments] Experiments section: the reported performance drops and fine-tuning gains rest on the assumption that the curated tasks accurately represent the requirement-driven repository search problem; without the missing curation and validation details noted above, the evidence supporting this assumption remains moderate.
Authors: We agree that the strength of the experimental conclusions is tied to the fidelity of the benchmark construction. Once the additional details requested above are incorporated, the link between task design and the observed drop (and subsequent fine-tuning gains) will be more explicit and verifiable. No new experiments are required; the existing results already show consistent degradation across embedding models and recovery after supervised fine-tuning. The revision will simply make the supporting evidence for the task design transparent. revision: yes
Circularity Check
No circularity: empirical benchmark with direct experimental reporting
full rationale
The paper constructs CORE-Bench from existing code-search tasks and SWE-bench instances, then reports direct experimental measurements of embedding model performance on the new dataset. No equations, fitted parameters renamed as predictions, self-citation load-bearing arguments, or uniqueness theorems appear in the provided text. The central claims (performance drop and fine-tuning gains) are empirical observations on the benchmark, not derivations that reduce to the inputs by construction. This is a standard benchmark paper with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 40th International Conference on Software Engineering , pages =
Deep Code Search , author =. Proceedings of the 40th International Conference on Software Engineering , pages =. 2018 , doi =
2018
-
[2]
Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021) , pages=
Bag-of-words baselines for semantic code search , author=. Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021) , pages=
2021
-
[3]
Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019 , author=. arXiv preprint arXiv:1909.09436 , year=
Pith/arXiv arXiv 2019
-
[4]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Codebert: A pre-trained model for programming and natural languages , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[5]
International Conference on Learning Representations , year=
GraphCodeBERT: Pre-training Code Representations with Data Flow , author=. International Conference on Learning Representations , year=
-
[6]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unixcoder: Unified cross-modal pre-training for code representation , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =
CodeRetriever: A Large Scale Contrastive Pre-Training Method for Code Search , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =. 2022 , doi =
2022
-
[8]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
CodeT5+: Open Code Large Language Models for Code Understanding and Generation , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , doi =
2023
-
[9]
OASIS: Order-Augmented Strategy for Improved Code Search , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =. doi:10.18653/v1/2025.acl-long.904 , url =
-
[10]
Proceedings of the Conference on Language Modeling , year =
CodeXEmbed: A Generalist Embedding Model Family for Multilingual and Multi-task Code Retrieval , author =. Proceedings of the Conference on Language Modeling , year =
-
[11]
Cosqa: 20,000+ web queries for code search and question answering , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[12]
arXiv preprint arXiv:2105.09938 , year=
Measuring coding challenge competence with apps , author=. arXiv preprint arXiv:2105.09938 , year=
-
[13]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[14]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[15]
International Conference on Machine Learning , pages=
DS-1000: A natural and reliable benchmark for data science code generation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Codetransocean: A comprehensive multilingual benchmark for code translation , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[17]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Coir: A comprehensive benchmark for code information retrieval models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
The Fourteenth International Conference on Learning Representations , year =
CLARC: C/C++ Benchmark for Robust Code Search , author =. The Fourteenth International Conference on Learning Representations , year =
-
[19]
Advances in Neural Information Processing Systems , volume=
CPRet: A Dataset, Benchmark, and Model for Retrieval in Competitive Programming , author=. Advances in Neural Information Processing Systems , volume=. 2025 , note=
2025
-
[20]
Advances in Neural Information Processing Systems , volume=
Freshstack: Building realistic benchmarks for evaluating retrieval on technical documents , author=. Advances in Neural Information Processing Systems , volume=. 2025 , note=
2025
-
[21]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Coderag-bench: Can retrieval augment code generation? , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[22]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
Mteb: Massive text embedding benchmark , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[23]
arXiv preprint arXiv:2102.04664 , year=
Codexglue: A machine learning benchmark dataset for code understanding and generation , author=. arXiv preprint arXiv:2102.04664 , year=
-
[24]
International Conference on Learning Representations , year=
Openhands: An open platform for ai software developers as generalist agents , author=. International Conference on Learning Representations , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Opencodeinterpreter: Integrating code generation with execution and refinement , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[27]
Foundations and Trends in Information Retrieval , volume=
The Probabilistic Relevance Framework: BM25 and Beyond , author=. Foundations and Trends in Information Retrieval , volume=. 2009 , publisher=
2009
-
[28]
arXiv preprint arXiv:2402.05672 , year=
Multilingual e5 text embeddings: A technical report , author=. arXiv preprint arXiv:2402.05672 , year=
-
[29]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[30]
Findings of the association for computational linguistics: ACL 2024 , pages=
M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation , author=. Findings of the association for computational linguistics: ACL 2024 , pages=
2024
-
[31]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
mgte: Generalized long-context text representation and reranking models for multilingual text retrieval , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2024
-
[32]
arXiv preprint arXiv:2308.03281 , year=
Towards general text embeddings with multi-stage contrastive learning , author=. arXiv preprint arXiv:2308.03281 , year=
-
[33]
International Conference on Learning Representations , year=
CoRNStack: High-quality contrastive data for better code retrieval and reranking , author=. International Conference on Learning Representations , year=
-
[34]
arXiv preprint arXiv:2508.21290 , year=
Efficient Code Embeddings from Code Generation Models , author=. arXiv preprint arXiv:2508.21290 , year=
-
[35]
Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025) , pages=
jina-embeddings-v4: Universal embeddings for multimodal multilingual retrieval , author=. Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025) , pages=. 2025 , url=
2025
-
[36]
arXiv preprint arXiv:2602.15547 , year=
jina-embeddings-v5-text: Task-targeted embedding distillation , author=. arXiv preprint arXiv:2602.15547 , year=
-
[37]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 embedding: Advancing text embedding and reranking through foundation models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[38]
arXiv preprint arXiv:2512.21332 , year=
C2LLM Technical Report: A New Frontier in Code Retrieval via Adaptive Cross-Attention Pooling , author=. arXiv preprint arXiv:2512.21332 , year=
-
[39]
arXiv preprint arXiv:2603.19223 , year=
F2llm-v2: Inclusive, performant, and efficient embeddings for a multilingual world , author=. arXiv preprint arXiv:2603.19223 , year=
-
[40]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improving text embeddings with large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
arXiv preprint arXiv:2505.07849 , year=
Swerank: Software issue localization with code ranking , author=. arXiv preprint arXiv:2505.07849 , year=
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Locagent: Graph-guided llm agents for code localization , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
arXiv preprint arXiv:2602.05892 , year=
ContextBench: A Benchmark for Context Retrieval in Coding Agents , author=. arXiv preprint arXiv:2602.05892 , year=
-
[44]
International Conference on Learning Representations , year=
Nv-embed: Improved techniques for training llms as generalist embedding models , author=. International Conference on Learning Representations , year=
-
[45]
arXiv preprint arXiv:2602.11151 , year=
Diffusion-pretrained dense and contextual embeddings , author=. arXiv preprint arXiv:2602.11151 , year=
-
[46]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[47]
International Conference on Learning Representations , year =
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author =. International Conference on Learning Representations , year =
-
[48]
Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Splade: Sparse lexical and expansion model for first stage ranking , author=. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[49]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[50]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models , author =. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.