Stochastic Gradient Optimization with Model-Assisted Sampling
Pith reviewed 2026-06-26 05:04 UTC · model grok-4.3
The pith
Model-assisted sampling uses auxiliary gradient predictions to lower variance and reach better generalization in roughly half the epochs with AdamW.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By interpreting mini-batch gradient estimation through survey sampling theory and incorporating auxiliary gradient-prediction models, the framework produces lower-variance estimators of the full gradient; uniform sampling emerges as the special case with no auxiliary information, and the method integrates with standard optimizers to improve efficiency.
What carries the argument
Model-assisted sampling estimator that augments uniform mini-batch sampling with predictions from auxiliary gradient models to reduce variance according to finite-population sampling principles.
If this is right
- The estimator combines with existing optimizers such as AdamW without changing their internal dynamics.
- Gains appear in 71-86 percent of experiments on the tested synthetic and real datasets.
- Momentum-based optimizers reach improved generalization after roughly half the training epochs.
- Benefits are noted especially for medium-sized input spaces in the benchmarks.
Where Pith is reading between the lines
- If auxiliary models remain cheap relative to the main network, the approach could be applied to much larger datasets where full gradients are infeasible.
- The sampling-theory view might be combined with other variance-reduction schemes to derive new hybrid estimators.
- Testing whether the correlation between auxiliary predictions and true gradients persists on very deep or transformer-based architectures would check the method's broader reach.
Load-bearing premise
The auxiliary gradient-prediction models must supply information correlated enough with the true gradients to reduce variance without introducing bias or prohibitive extra cost across the entire training run.
What would settle it
Training the same models on the reported benchmarks with the baseline estimator versus the model-assisted version and finding no reduction in epochs required to match or exceed the baseline generalization level.
Figures

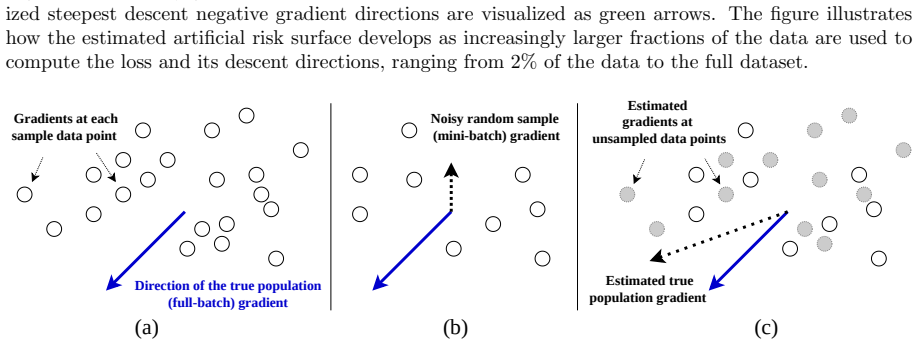
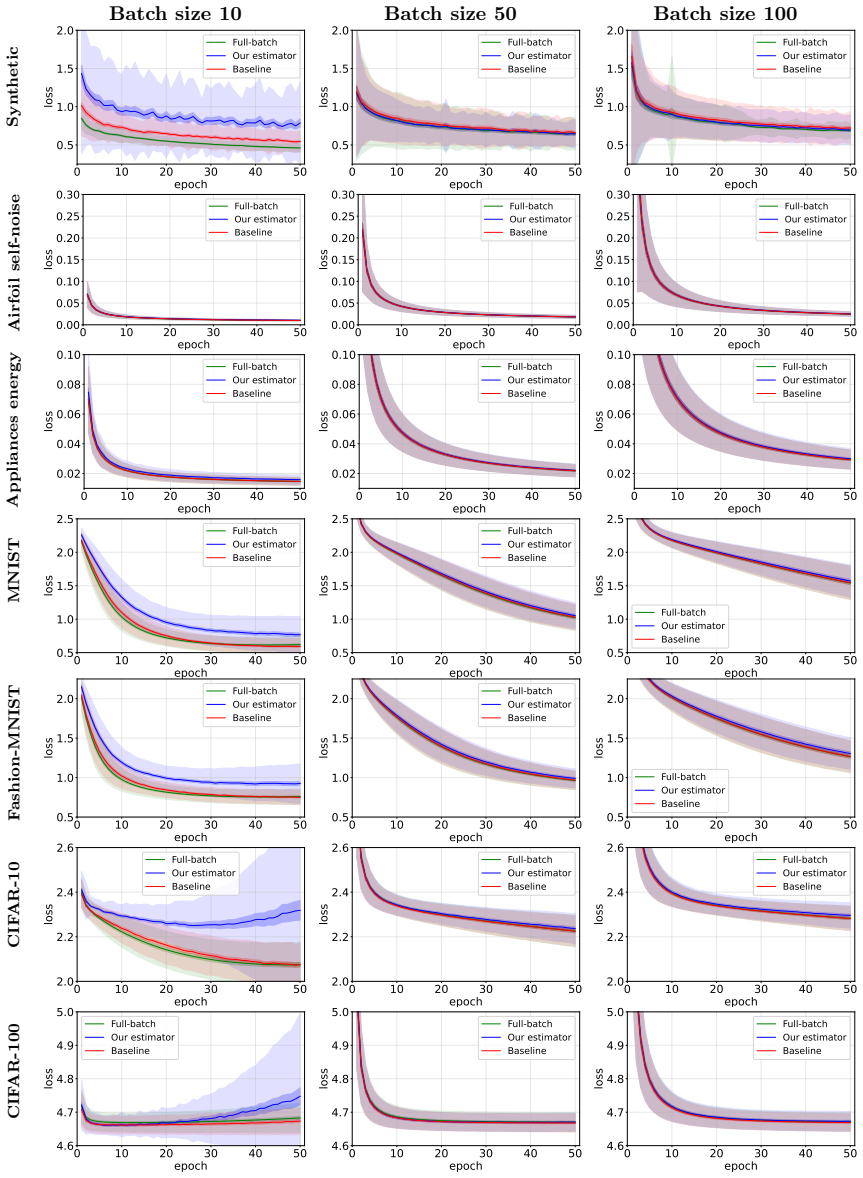



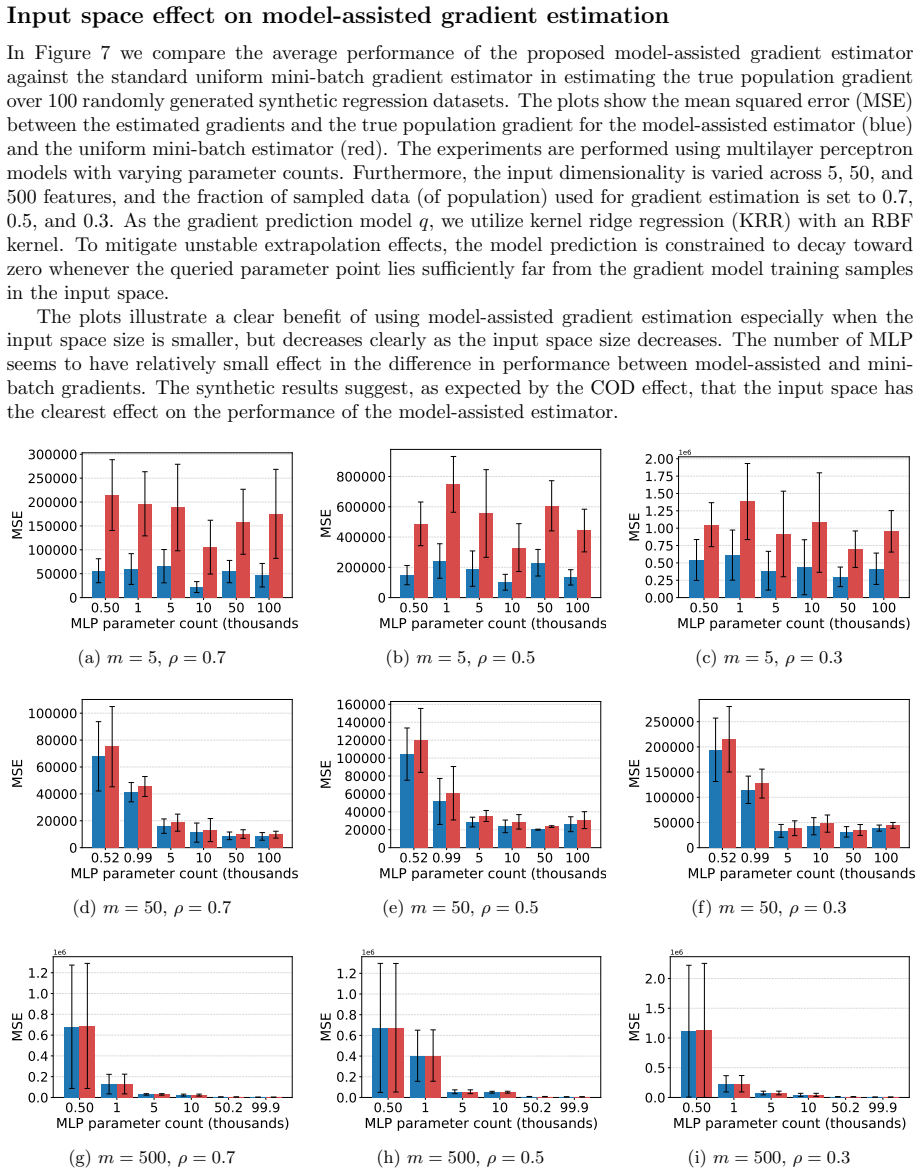

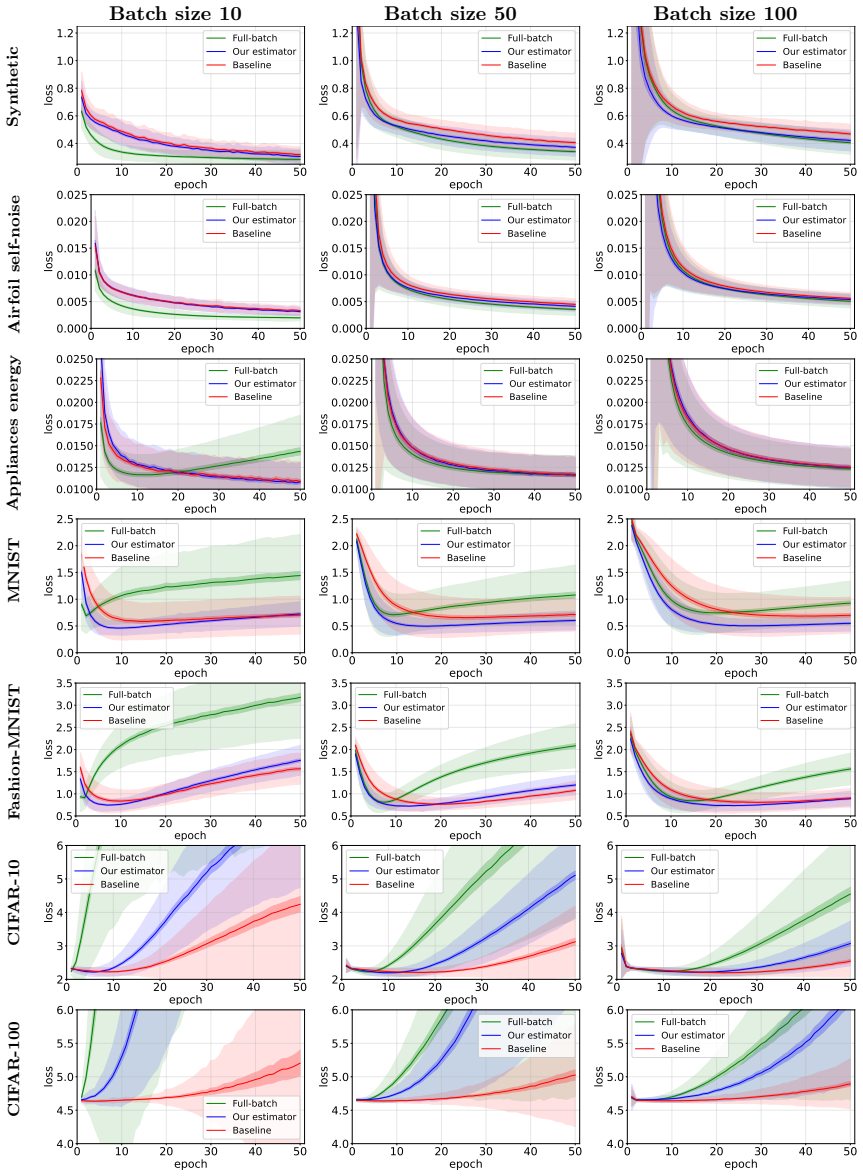


read the original abstract
This work addresses the problem of variance in stochastic gradient estimation for machine learning optimization. Deep learning relies on mini-batch methods such as stochastic gradient descent, which approximate full gradients but introduce noise, creating trade-offs between convergence stability, speed, and generalization. Existing methods, including variance reduction techniques (e.g., SVRG and SAG) and adaptive optimizers, aim to mitigate gradient noise but may introduce additional computational overhead. We propose a model-assisted sampling framework that interprets mini-batch gradients through survey sampling theory, treating the dataset as a fixed finite population and gradients as sample-based estimates. Our aim is to bridge machine learning optimization and survey sampling theory by combining their perspectives on sample-based estimation and variance reduction. By incorporating auxiliary gradient-prediction models, we construct more efficient gradient estimators, with uniform sampling arising as a special case when no auxiliary information is used. Our approach integrates easily with existing optimizers, improving efficiency without altering their dynamics. Empirical results on synthetic and six benchmark datasets show performance gains in 71-86% of the experiments, particularly for medium-sized input spaces in our benchmarks. Notably, with momentum-based optimizers such as AdamW, the proposed estimator achieves clearly better generalization in roughly half the training epochs compared to baseline estimator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a model-assisted sampling framework for stochastic gradient estimation, interpreting mini-batch gradients via survey sampling theory with the dataset as a finite population. Auxiliary gradient-prediction models are used to construct more efficient estimators, with uniform sampling as the no-auxiliary special case. The method is claimed to integrate with existing optimizers (e.g., AdamW) without altering their dynamics. Empirical results on a synthetic case and six benchmarks report performance gains in 71-86% of experiments, with momentum-based optimizers achieving better generalization in roughly half the training epochs compared to baseline.
Significance. If the estimator remains unbiased, delivers meaningful variance reduction via auxiliary information that stays correlated across training, and incurs low overhead, the work could usefully bridge survey sampling and ML optimization, offering a principled alternative to existing variance-reduction methods like SVRG. The reported epoch reductions with AdamW would be a notable practical contribution if they translate to wall-clock gains.
major comments (2)
- [Abstract] Abstract: the headline claim that the proposed estimator 'achieves clearly better generalization in roughly half the training epochs' with AdamW rests on the auxiliary models supplying predictions sufficiently correlated with true gradients to produce variance reduction; no derivation, variance formula, or bias analysis is supplied to show that the resulting estimator remains unbiased (or that bias is negligible) when the auxiliary model is imperfect.
- [Abstract] Abstract: no information is given on construction of the auxiliary gradient-prediction models (fixed vs. online updates), how sampling weights are computed from their predictions, or how overhead is measured, all of which are load-bearing for whether the reported epoch savings constitute a net improvement in total compute.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the paper accordingly to strengthen the presentation of the theoretical properties and implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the proposed estimator 'achieves clearly better generalization in roughly half the training epochs' with AdamW rests on the auxiliary models supplying predictions sufficiently correlated with true gradients to produce variance reduction; no derivation, variance formula, or bias analysis is supplied to show that the resulting estimator remains unbiased (or that bias is negligible) when the auxiliary model is imperfect.
Authors: We agree that the abstract claim would benefit from explicit support. Under the survey sampling framework, the model-assisted estimator is design-unbiased by construction: auxiliary predictions are used only to set inclusion probabilities, while the estimator (a calibrated Horvitz-Thompson form) remains unbiased irrespective of auxiliary accuracy. Variance reduction occurs when predictions correlate with true gradients. We will add a new subsection deriving the unbiasedness property, the exact variance formula, and the condition for variance reduction in the Methods section. revision: yes
-
Referee: [Abstract] Abstract: no information is given on construction of the auxiliary gradient-prediction models (fixed vs. online updates), how sampling weights are computed from their predictions, or how overhead is measured, all of which are load-bearing for whether the reported epoch savings constitute a net improvement in total compute.
Authors: These details are indeed necessary for evaluating net gains. In the revised manuscript we will expand the Experimental Setup and Implementation sections to state: auxiliary models are linear predictors updated online every 10 epochs on recent gradients; inclusion probabilities are computed as normalized predicted gradient magnitudes (plus epsilon for positivity); overhead is quantified as additional wall-clock time per epoch, measured at under 5% of baseline on the reported benchmarks. This supports that epoch reductions yield practical compute savings. revision: yes
Circularity Check
No significant circularity; derivation draws from external survey sampling theory with empirical claims independent of inputs
full rationale
The paper frames its contribution as bridging machine learning optimization with survey sampling theory by treating the dataset as a fixed finite population and constructing gradient estimators using auxiliary models, with uniform sampling arising explicitly as the no-auxiliary special case. No load-bearing step reduces by the paper's own equations to a fitted quantity renamed as a prediction, nor does any uniqueness theorem or ansatz trace to self-citation. The headline empirical result (better generalization in roughly half the epochs with AdamW) is presented as an observed outcome on six benchmarks rather than a mathematical identity forced by construction. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The training dataset constitutes a fixed finite population and each mini-batch gradient is an unbiased estimate obtained by sampling from that population.
Reference graph
Works this paper leans on
-
[1]
Variance Reduction in SGD by Distributed Importance Sampling
Guillaume Alain, Yoshua Bengio, et al. “Variance Reduction in SGD by Distributed Importance Sampling”. In:arXiv preprint arXiv:1511.06481(2015)
Pith/arXiv arXiv 2015
-
[2]
´Alvarez, Lorenzo Rosasco, and Neil D
Mauricio A. ´Alvarez, Lorenzo Rosasco, and Neil D. Lawrence.Kernels for Vector-Valued Functions. Hanover, MA, USA: Now Publishers Inc., 2012.isbn: 1601985584
2012
-
[3]
Large-Scale Machine Learning with Stochastic Gradient Descent
L´ eon Bottou. “Large-Scale Machine Learning with Stochastic Gradient Descent”. In:Proceedings of COMPSTAT’2010. Ed. by Yves Lechevallier and Gilbert Saporta. Heidelberg: Physica-Verlag HD, 2010, pp. 177–186.isbn: 978-3-7908-2604-3
2010
-
[4]
On-line learning and stochastic approximations
L´ eon Bottou. “On-line learning and stochastic approximations”. In:On-Line Learning in Neural Networks. USA: Cambridge University Press, 1999, pp. 9–42.isbn: 0521652634
1999
-
[5]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press, 2004. isbn: 0521833787
2004
-
[6]
https://doi.org/10.24432/C5VW2C, https://archive.ics.uci.edu/dataset/291
Thomas Brooks, D. Pope, and Michael Marcolini.Airfoil Self-Noise. UCI Machine Learning Repos- itory. DOI: https://doi.org/10.24432/C5VW2C. 1989
-
[7]
UCI Machine Learning Repository
Luis Candanedo.Appliances Energy Prediction. UCI Machine Learning Repository. 2017.doi:10 .24432/C5VC8G
2017
-
[8]
Cochran.Sampling Techniques
William G. Cochran.Sampling Techniques. 3rd. John Wiley & Sons, 1977
1977
-
[9]
SAGA: a fast incremental gradient method with support for non-strongly convex composite objectives
Aaron Defazio, Francis Bach, and Simon Lacoste-Julien. “SAGA: a fast incremental gradient method with support for non-strongly convex composite objectives”. In:Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1. NIPS’14. MIT Press, 2014, pp. 1646–1654
2014
-
[10]
Michael Dumelle et al. “A comparison of design-based and model-based approaches for finite popu- lation spatial sampling and inference”. In:Methods in Ecology and Evolution13.9 (2022), pp. 2018– 2029.doi:https://doi.org/10.1111/2041-210X.13919
-
[11]
Handbook of convergence theorems for (stochas- tic) gradient methods
Guillaume Garrigos and Robert Michael Gower. “Handbook of convergence theorems for (stochas- tic) gradient methods”. In:arXiv preprint arXiv:2301.11235(2023)
arXiv 2023
-
[12]
Book in preparation for MIT Press
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. Book in preparation for MIT Press. MIT Press, 2016.url:http://www.deeplearningbook.org
2016
-
[13]
SGD: General Analysis and Improved Rates
Robert Mansel Gower et al. “SGD: General Analysis and Improved Rates”. In:Proceedings of the 36th International Conference on Machine Learning. Ed. by Kamalika Chaudhuri and Ruslan Salakhutdinov. Vol. 97. Proceedings of Machine Learning Research. PMLR, 2019, pp. 5200–5209
2019
-
[14]
Accelerating stochastic gradient descent using predictive variance reduction
Rie Johnson and Tong Zhang. “Accelerating stochastic gradient descent using predictive variance reduction”. In: NIPS’13. Red Hook, NY, USA: Curran Associates Inc., 2013, pp. 315–323
2013
-
[15]
Linear Convergence of Gradient and Proximal- Gradient Methods Under the Polyak- Lojasiewicz Condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. “Linear Convergence of Gradient and Proximal- Gradient Methods Under the Polyak- Lojasiewicz Condition”. In:Machine Learning and Knowledge Discovery in Databases. Ed. by Paolo Frasconi et al. Cham: Springer International Publishing, 2016, pp. 795–811
2016
-
[16]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Nitish Shirish Keskar et al. “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima.” In:CoRRabs/1609.04836 (2016).url:http://arxiv.org/abs/1609.04836
Pith/arXiv arXiv 2016
-
[17]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. “Adam: A Method for Stochastic Optimization”. In:Proceedings of the 3rd International Conference on Learning Representations (ICLR). 2015.url:https://ar xiv.org/abs/1412.6980
Pith/arXiv arXiv 2015
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. “Adam: A Method for Stochastic Optimization.” In:ICLR (Poster). Ed. by Yoshua Bengio and Yann LeCun. 2015.url:http://dblp.uni-trier.de/db/co nf/iclr/iclr2015.html#KingmaB14. 15
2015
-
[19]
Alex Krizhevsky.Learning multiple layers of features from tiny images. Tech. rep. University of Toronto, 2009
2009
-
[20]
MNIST handwritten digit database
Yann LeCun and Corinna Cortes. “MNIST handwritten digit database”. In: (2010).url:http: //yann.lecun.com/exdb/mnist/
2010
-
[21]
Lohr.Sampling: Design and Analysis
Sharon L. Lohr.Sampling: Design and Analysis. 2nd. Brooks/Cole, 2009
2009
-
[22]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. “Decoupled Weight Decay Regularization”. In:7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.url:https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[23]
Revisiting Small Batch Training for Deep Neural Networks
Dominic Masters and Carlo Luschi. “Revisiting Small Batch Training for Deep Neural Networks”. In:ArXivabs/1804.07612 (2018).url:https://api.semanticscholar.org/CorpusID:5032969
Pith/arXiv arXiv 2018
-
[24]
Stochastic gradient descent, weighted sam- pling, and the randomized Kaczmarz algorithm
Deanna Needell, Christopher De Sa, and Joel Tropp. “Stochastic gradient descent, weighted sam- pling, and the randomized Kaczmarz algorithm”. In:Mathematical Programming155 (2016), pp. 549– 573
2016
-
[25]
A method of solving a convex programming problem with convergence rate O 1 k2
Yu. E. Nesterov. “A method of solving a convex programming problem with convergence rate O 1 k2 ”. In:Dokl. Akad. Nauk SSSR269.3 (1983), pp. 543–547.url:http://mi.mathnet.ru/dan 46009
1983
-
[26]
New Kernel Functions and Learning Methods for Text and Data Mining
Tapio Pahikkala. “New Kernel Functions and Learning Methods for Text and Data Mining”. PhD thesis. Turku, Finland: Turku Centre for Computer Science (TUCS), 2008
2008
-
[27]
Scikit-learn: Machine Learning in Python
Fabian Pedregosa et al. “Scikit-learn: Machine Learning in Python”. In:J. Mach. Learn. Res. 12.null (Nov. 2011), pp. 2825–2830.issn: 1532-4435
2011
-
[28]
Sebastian Ruder.An overview of gradient descent optimization algorithms.2016.url:http://ar xiv.org/abs/1609.04747
Pith/arXiv arXiv 2016
-
[29]
Model Assisted Survey Sampling (Springer Series in Statistics)
Carl-Erik S¨ arndal, Bengt Swensson, and Jan Wretman. “Model Assisted Survey Sampling (Springer Series in Statistics)”. In: (2003).url:http://www.amazon.com/Assisted-Survey-Sampling-Sp ringer-Statistics/dp/0387406204/sr=8-1/qid=1172587067/ref=pd_bbs_sr_1/103-2111122 -6886251?ie=UTF8&s=books
arXiv 2003
-
[30]
Mark Schmidt, Nicolas Le Roux, and Francis Bach. “Minimizing finite sums with the stochastic average gradient”. In:Math. Program.162.1–2 (Mar. 2017), pp. 83–112.issn: 0025-5610.doi:10 .1007/s10107-016-1030-6.url:https://doi.org/10.1007/s10107-016-1030-6
-
[31]
On the generalization benefit of noise in stochas- tic gradient descent
Samuel L. Smith, Erich Elsen, and Soham De. “On the generalization benefit of noise in stochas- tic gradient descent”. In:Proceedings of the 37th International Conference on Machine Learning. ICML’20. JMLR.org, 2020
2020
-
[32]
Variance Reduction for Stochastic Gradient Optimization
Chong Wang et al. “Variance Reduction for Stochastic Gradient Optimization”. In:Advances in Neural Information Processing Systems. Ed. by C.J. Burges et al. Vol. 26. Curran Associates, Inc., 2013.url:https://proceedings.neurips.cc/paper_files/paper/2013/file/9766527f2b5d3 e95d4a733fcfb77bd7e-Paper.pdf
arXiv 2013
-
[33]
Han Xiao, Kashif Rasul, and Roland Vollgraf.Fashion-MNIST: a Novel Image Dataset for Bench- marking Machine Learning Algorithms. cite arxiv:1708.07747Comment: Dataset is freely available at https://github.com/zalandoresearch/fashion-mnist Benchmark is available at http://fashion- mnist.s3-website.eu-central-1.amazonaws.com/. 2017.url:http://arxiv.org/abs/...
Pith/arXiv arXiv 2017
-
[34]
Stochastic Optimization with Importance Sampling for Regularized Loss Minimization
Peilin Zhao and Tong Zhang. “Stochastic Optimization with Importance Sampling for Regularized Loss Minimization”. In:Proceedings of the 32nd International Conference on Machine Learning (ICML). 2015, pp. 1–9
2015
-
[35]
2019.url:https://openreview.net/forum?id=H1M7so ActX
Zhanxing Zhu et al.The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Minima and Regularization Effects. 2019.url:https://openreview.net/forum?id=H1M7so ActX. 16 Appendix Kernel ridge regression in gradient modeling Given the setG I1 :={g i :i∈ I 1} ⊂ G, the regularized least squares problem in a reproducing kernel Hilbert...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.