Cultural Targets, Structural Frames, Binding Morals: A Cross-Lingual Audit of Online Hate in Multicultural Singapore
Pith reviewed 2026-06-26 11:00 UTC · model grok-4.3
The pith
Online hate in Singapore shows language-specific targets but shared moral and emotional structures across communities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
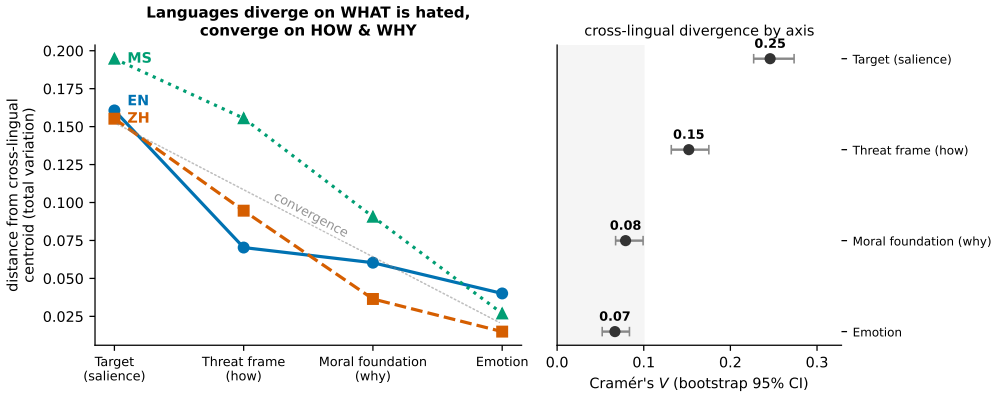
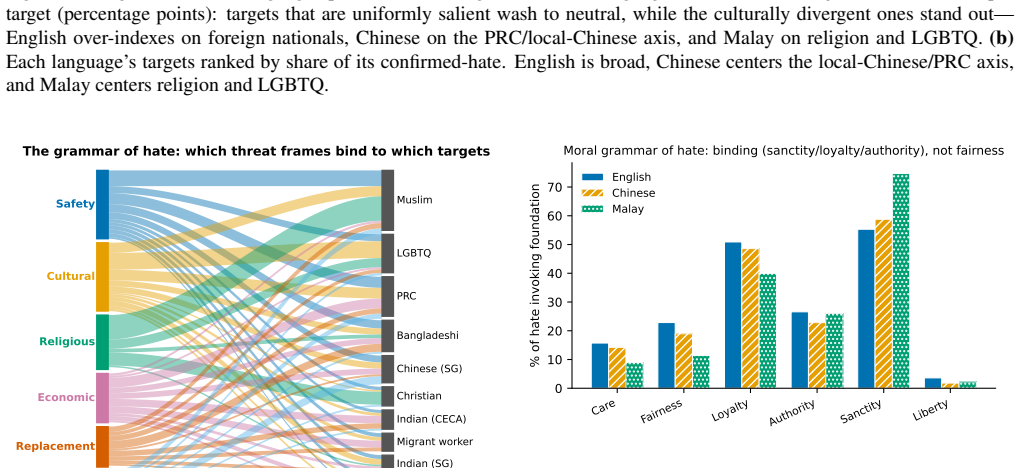
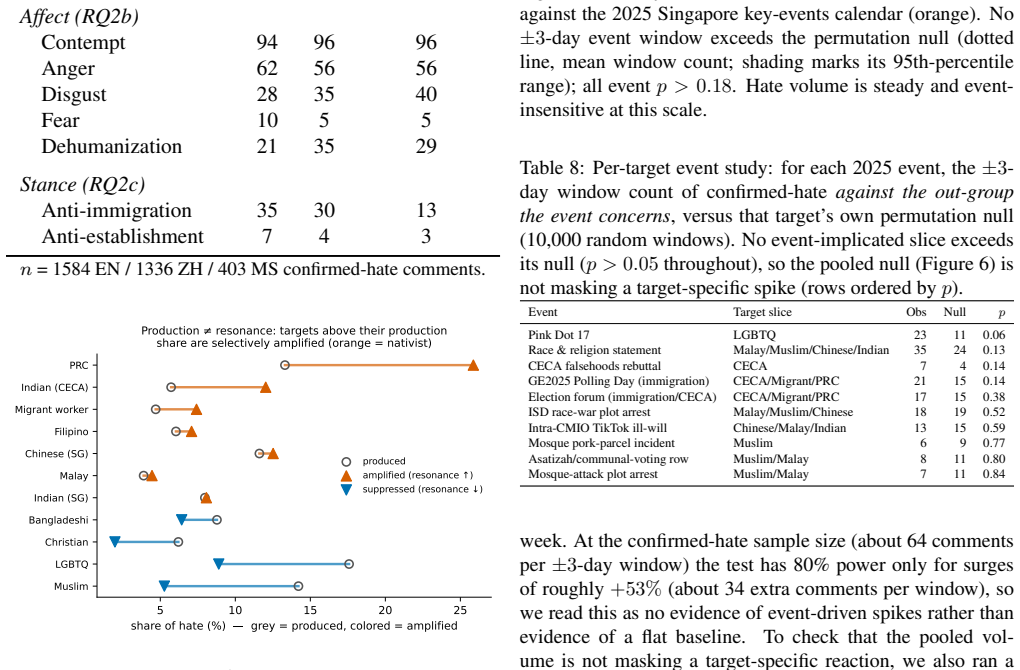
The paper's core claim is that cross-lingual divergence in online hate decreases as analysis moves from targets to structures: language-by-target association is V=0.25, but drops to V=0.08 for moral foundations and V=0.07 for emotion, with binding morals of sanctity and loyalty prominent at 55-75% and hate being contempt-driven with anti-immigration focus.
What carries the argument
Layered cultural contingency, which describes how divergence falls monotonically from what is hated to how and why it is hated.
If this is right
- Out-group targets for hate are specific to each language public.
- Threat frames and binding morals like sanctity and loyalty are shared across languages.
- Hateful comments overall receive less amplification than neutral ones, but anti-immigrant hate is amplified more.
- Hate expresses out-group grievances rather than anti-system ones.
- Absolute hate rates are hard to define due to low inter-model agreement, so relative structures are emphasized.
Where Pith is reading between the lines
- Moderation policies might benefit from targeting shared structural elements like moral language instead of specific topics.
- Patterns observed here could be tested in other multilingual societies with parallel language communities.
- Further human validation per language could test the reliability of the LLM-based cross-lingual comparisons.
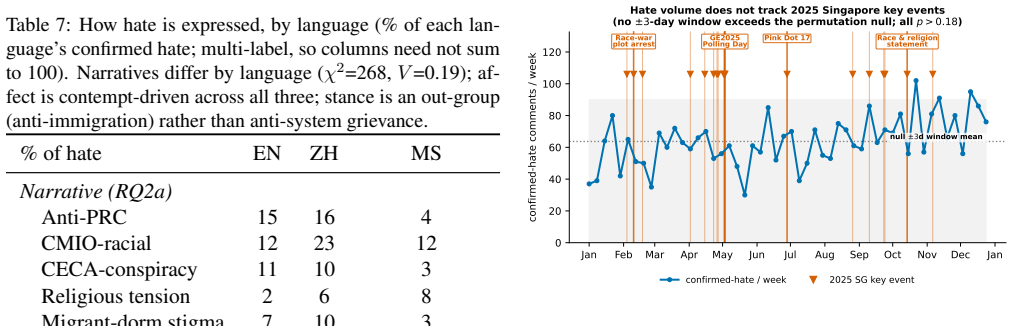
- Volume of hate not tracking events suggests it's driven by ongoing social dynamics rather than temporary triggers.
Load-bearing premise
The LLM chosen for annotation accurately reflects human perceptions of hate, frames, and morals in all three languages.
What would settle it
Human raters from each language group rating the same comments differently from the LLM on moral foundations or emotions at levels inconsistent with the high agreement scores reported.
Figures
read the original abstract
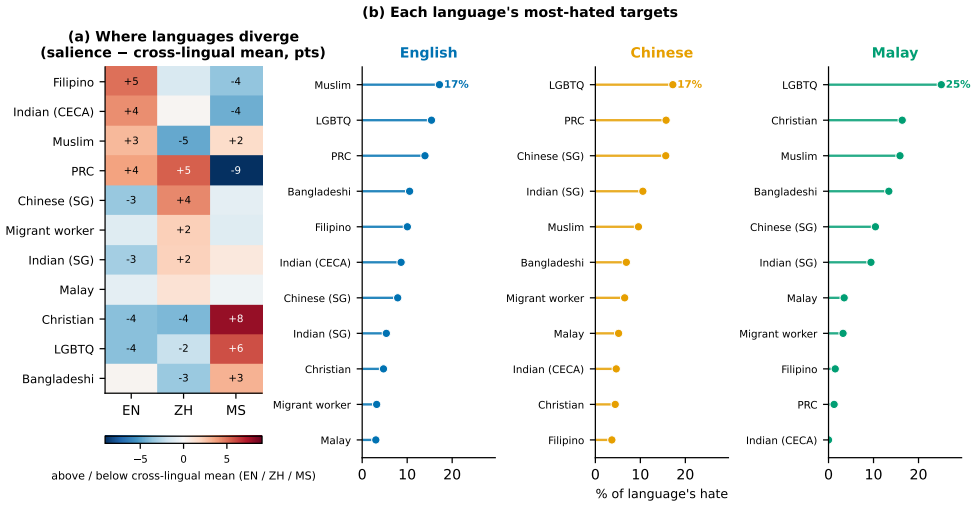
Multicultural Singapore hosts overlapping language publics (English, Chinese, and Malay) that discuss the same out-groups in parallel, a natural setting to ask whether online hate shares a structure across languages and whether what a community $\textit{produces}$ is what it $\textit{amplifies}$. From a Singapore-centric 2025 Facebook, Reddit, and YouTube corpus (31.0M items; 1.76M comments mentioning eleven identity groups), we benchmark eight open large language models as hate annotators against a human-adjudicated gold set, adopt the best (Phi-4: accuracy 0.95, Cohen's $\kappa$=0.91, recall 1.00 on an independent manual check), and replicate every finding under a second model. The results converge on one thesis, $\textit{layered cultural contingency}$: cross-lingual divergence falls monotonically as one moves from what a community hates to how and why it hates. Which out-groups are targeted is culturally specific (language $\times$ target $V$=0.25), but the threat frames and the binding moral grammar of hate (sanctity and loyalty, $55-75\%$, not fairness) are far more shared across languages, with divergence dropping to $V$=0.08 for moral foundations and 0.07 for emotion. Hate is contempt-driven and voices an out-group, anti-immigration grievance rather than an anti-system one. Reception is selectively nativist: hateful comments are amplified less than neutral mentions overall, yet anti-immigrant hate is preferentially amplified while religious and anti-LGBTQ hate is not, and volume does not track 2025 Singapore key events. We further show that absolute hate prevalence is not well defined at the LLM-annotator level, with agreement ceilings at $\kappa\approx0.42$ across models, so we report relative structure as primary. The findings bear directly on cross-lingual content moderation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes a 2025 Singapore corpus (31M items, 1.76M comments on 11 identity groups) across English, Chinese, and Malay to test cross-lingual structure in online hate. After benchmarking eight LLMs against a human gold set and selecting Phi-4 (accuracy 0.95, κ=0.91), it reports that target selection is culturally specific (language × target V=0.25) while threat frames and binding moral foundations (sanctity/loyalty dominant, V=0.08/0.07) converge, supporting a 'layered cultural contingency' thesis; hate is contempt-driven and anti-immigrant, with selective amplification and no event linkage. Absolute prevalence is treated as ill-defined due to model disagreement (κ≈0.42).
Significance. If the structural annotations are reliable, the monotonic decline in divergence from targets to morals provides a testable, empirically grounded distinction between culturally variable and shared components of hate speech, with direct implications for multilingual moderation. The human gold set for binary detection, replication under a second model, and focus on relative structure rather than absolute rates are positive features.
major comments (2)
- [Methods (LLM benchmarking and annotation pipeline)] The reported validation (accuracy 0.95, κ=0.91 on independent manual check) applies exclusively to binary hate detection against the human gold set. No parallel human cross-lingual adjudication is described for the target, threat-frame, or moral-foundation labels whose divergence statistics (V=0.25 → 0.08/0.07) carry the central layered-contingency claim.
- [Results (model replication and structural comparisons)] Post-selection of Phi-4 as the primary annotator, combined with the acknowledged low inter-model agreement on prevalence (κ≈0.42), leaves open the possibility that model-specific artifacts in non-English languages drive the observed convergence in frames and morals even if human judgments diverge.
minor comments (2)
- [Methods] Clarify whether the second-model replication applied the identical prompt templates and label schemas used for Phi-4 or introduced any adjustments.
- [Results] The abstract states that 'volume does not track 2025 Singapore key events'; provide the exact event list and statistical test used for this null result.
Simulated Author's Rebuttal
We thank the referee for the careful review and for noting the strengths of the human gold set for binary detection, the model replication, and the focus on relative structure. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods (LLM benchmarking and annotation pipeline)] The reported validation (accuracy 0.95, κ=0.91 on independent manual check) applies exclusively to binary hate detection against the human gold set. No parallel human cross-lingual adjudication is described for the target, threat-frame, or moral-foundation labels whose divergence statistics (V=0.25 → 0.08/0.07) carry the central layered-contingency claim.
Authors: The referee correctly identifies that human validation was performed only for binary hate detection. Target, threat-frame, and moral-foundation annotations were produced by the selected LLM and subjected to full replication under the second model; the monotonic decline in divergence (V=0.25 to 0.08/0.07) is reproduced in both. We will add an explicit limitations paragraph acknowledging the lack of human cross-lingual adjudication for the structural labels and will clarify how cross-model consistency functions as the primary robustness check for those annotations. revision: partial
-
Referee: [Results (model replication and structural comparisons)] Post-selection of Phi-4 as the primary annotator, combined with the acknowledged low inter-model agreement on prevalence (κ≈0.42), leaves open the possibility that model-specific artifacts in non-English languages drive the observed convergence in frames and morals even if human judgments diverge.
Authors: All structural comparisons were replicated under the second model, and the convergence patterns in threat frames and moral foundations remain unchanged. Because the low inter-model κ on prevalence is already acknowledged, the manuscript centers on relative structure; divergent model artifacts would be expected to produce inconsistent structural signals across models, which is not observed. We will expand the methods and results sections to report the replication statistics specifically for the non-binary labels and to state that this replication directly tests against language-specific model biases. revision: yes
Circularity Check
No significant circularity; empirical statistics from annotated corpus
full rationale
The paper's claims rest on direct computation of association measures (Cramer's V) from LLM-annotated corpus data after benchmarking the annotator on a human gold set for binary hate detection. No equations, fitted parameters, or self-citations are used to derive the layered-contingency thesis; the monotonic decline in V (0.25 to 0.08/0.07) is an observed empirical pattern, not a constructed equivalence. The analysis is self-contained against external benchmarks (human labels, multiple models) and does not reduce to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM annotations validated on a human gold set can be treated as reliable for measuring cross-lingual differences in hate structure
- domain assumption The 2025 Singapore Facebook, Reddit, and YouTube corpus adequately represents parallel language publics discussing the same out-groups
Reference graph
Works this paper leans on
-
[1]
Mohammad Atari, Jesse Graham, and Morteza De- hghani. Foundations of morality in iran.Evolution and Human Behavior, 41(5):367–384, 2020. doi: 10.1016/j. evolhumbehav.2020.07.014
work page doi:10.1016/j 2020
-
[2]
Federica Bianco and Ankica Kosic. The effects of binding moral foundations on prejudiced attitudes to- ward migrants: The mediation role of perceived realistic and symbolic threats.Genealogy, 7(3):65, 2023. doi: 10.3390/genealogy7030065
-
[3]
William J. Brady, Julian A. Wills, John T. Jost, Joshua A. Tucker, and Jay J. Van Bavel. Emotion shapes the diffu- sion of moralized content in social networks.Proceed- ings of the National Academy of Sciences, 114(28):7313– 7318, 2017. doi: 10.1073/pnas.1618923114
-
[4]
Brady, Killian McLoughlin, Tuan N
William J. Brady, Killian McLoughlin, Tuan N. Doan, and Molly J. Crockett. How social learning amplifies moral outrage expression in online social networks.Sci- ence Advances, 7(33):eabe5641, 2021. doi: 10.1126/ sciadv.abe5641
2021
-
[5]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Aida Mostafazadeh Davani, Mark Díaz, and Vinodkumar Prabhakaran. Dealing with disagreements: Looking be- yond the majority vote in subjective annotations.Trans- actions of the Association for Computational Linguistics, 10:92–110, 2022. doi: 10.1162/tacl_a_00449
-
[6]
Automated hate speech detection and the problem of offensive language
Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. Automated hate speech detection and the problem of offensive language. InProceedings of ICWSM 2017, volume 11, pages 512–515, 2017. doi: 10.1609/icwsm.v11i1.14955
-
[7]
COLD: A bench- mark for chinese offensive language detection
Jiawen Deng, Jingyan Zhou, Hao Sun, Chujie Zheng, Fei Mi, Helen Meng, and Minlie Huang. COLD: A bench- mark for chinese offensive language detection. InPro- ceedings of EMNLP 2022, pages 11580–11599, 2022. doi: 10.18653/v1/2022.emnlp-main.796
-
[8]
Priyanka Dey, Aayush Bothra, Yugal Khanter, Jieyu Zhao, and Emilio Ferrara. Can LLMs express person- ality across cultures? introducing CulturalPersonas for evaluating trait alignment. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025. doi: 10.18653/v1/2025.findings-emnlp.1101
-
[9]
Latent Hatred: A Benchmark for Understanding Implicit Hate Speech
Mai ElSherief, Caleb Ziems, David Nguyen, Soumya Roy, Diba Wang, and Diyi Yang. Latent hatred: A bench- mark for understanding implicit hate speech. InPro- ceedings of EMNLP 2021, pages 345–363, 2021. doi: 10.18653/v1/2021.emnlp-main.29
-
[10]
Im- pact and dynamics of hate and counter speech online
Joshua Garland, Keyan Ghazi-Zahedi, Jean-Gabriel Young, Laurent Hébert-Dufresne, and Mirta Galesic. Im- pact and dynamics of hate and counter speech online. EPJ Data Science, 11:3, 2022. doi: 10.1140/epjds/ s13688-021-00314-6
-
[12]
Jesse Graham, Jonathan Haidt, and Brian A. Nosek. Lib- erals and conservatives rely on different sets of moral foundations.Journal of Personality and Social Psychol- ogy, 96(5):1029–1046, 2009. doi: 10.1037/a0015141
-
[13]
Nosek, Jonathan Haidt, Ravi Iyer, Spassena Koleva, and Peter H
Jesse Graham, Brian A. Nosek, Jonathan Haidt, Ravi Iyer, Spassena Koleva, and Peter H. Ditto. Mapping the moral domain.Journal of Personality and Social Psy- chology, 101(2):366–385, 2011. doi: 10.1037/a0021847
-
[14]
Detecting social me- dia manipulation in low-resource languages
Samar Haider, Luca Luceri, Ashok Deb, Adam Badawy, Nanyun Peng, and Emilio Ferrara. Detecting social me- dia manipulation in low-resource languages. InCom- panion Proceedings of the ACM Web Conference 2023 (WWW ’23 Companion), 2023. doi: 10.1145/3543873. 3587615
-
[15]
Dominik Hangartner, Gloria Gennaro, Sary Alasiri, et al. Empathy-based counterspeech can reduce racist hate speech in a social media field experiment.Proceed- ings of the National Academy of Sciences, 118(50): e2116310118, 2021. doi: 10.1073/pnas.2116310118
-
[16]
Dehumanization: An integrative review
Nick Haslam. Dehumanization: An integrative review. Personality and Social Psychology Review, 10(3):252– 264, 2006. doi: 10.1207/s15327957pspr1003_4
-
[17]
Maik Herold. Who believes in the “great replacement”? political attitudes and democratic alienation among sup- porters of immigration-related conspiracy theories in eu- rope.Social Science Quarterly, 2025. doi: 10.1111/ssqu. 13481
-
[18]
Gordon Hodson and Kimberly Costello. Interpersonal disgust, ideological orientations, and dehumanization as predictors of intergroup attitudes.Psychological Science, 18(8):691–698, 2007. doi: 10.1111/j.1467-9280.2007. 01962.x
-
[19]
Frederic R. Hopp, Jacob T. Fisher, Devin Cornell, Richard Huskey, and René Weber. The extended moral foundations dictionary (eMFD): Development and appli- cations of a crowd-sourced approach to extracting moral intuitions from text.Behavior Research Methods, 53: 232–246, 2021. doi: 10.3758/s13428-020-01433-0
-
[20]
Multi-label hate speech and abusive language detection in indonesian twitter
Muhammad Okky Ibrohim and Indra Budi. Multi-label hate speech and abusive language detection in indonesian twitter. InProceedings of the Third Workshop on Abusive Language Online (ALW3), pages 46–57, 2019. doi: 10. 18653/v1/W19-3506. 9
2019
-
[21]
Julie Jiang, Luca Luceri, Joseph B. Walther, and Emilio Ferrara. Social approval and network ho- mophily as motivators of online toxicity. arXiv preprint arXiv:2310.07779, 2024
arXiv 2024
-
[22]
Moral values underpinning COVID-19 online communication patterns
Julie Jiang, Luca Luceri, and Emilio Ferrara. Moral values underpinning COVID-19 online communication patterns. InCompanion Proceedings of the ACM Web Conference 2025 (WWW ’25 Companion), 2025. doi: 10.1145/3701716.3717538
-
[23]
N. F. Johnson, R. Leahy, N. J. Restrepo, N. Velasquez, M. Zheng, P. Manrique, P. Devkota, and S. Wuchty. Hid- den resilience and adaptive dynamics of the global online hate ecology.Nature, 573(7773):261–265, 2019. doi: 10.1038/s41586-019-1494-7
-
[24]
Jost, and Sharareh Noor- baloochi
Matthew Kugler, John T. Jost, and Sharareh Noor- baloochi. Another look at moral foundations theory: Do authoritarianism and social dominance orientation explain liberal-conservative differences in “moral” intu- itions?Social Justice Research, 27(4):413–431, 2014. doi: 10.1007/s11211-014-0223-5
-
[25]
Kristina Lerman, Minh Duc Chu, Charles Bickham, Luca Luceri, and Emilio Ferrara. Safe spaces or toxic places? content moderation and social dynamics of online eating disorder communities.EPJ Data Science, 14(1), 2025. doi: 10.1140/epjds/s13688-025-00575-5
-
[26]
Junyu Lu, Bo Xu, Xiaokun Zhang, Changrong Min, Liang Yang, and Hongfei Lin. Facilitating fine-grained detection of chinese toxic language: Hierarchical taxon- omy, resources, and benchmarks. InProceedings of ACL 2023 (Long Papers), pages 16235–16250, 2023. doi: 10.18653/v1/2023.acl-long.898
-
[27]
Mackie, Thierry Devos, and Eliot R
Diane M. Mackie, Thierry Devos, and Eliot R. Smith. Intergroup emotions: Explaining offensive action ten- dencies in an intergroup context.Journal of Personal- ity and Social Psychology, 79(4):602–616, 2000. doi: 10.1037/0022-3514.79.4.602
-
[28]
Thou shalt not hate: Countering online hate speech
Binny Mathew, Punyajoy Saha, Hardik Tharad, Sub- ham Rajgaria, Prajwal Singhania, Suman Kalyan Maity, Pawan Goyal, and Animesh Mukherjee. Thou shalt not hate: Countering online hate speech. InProceedings of ICWSM 2019, volume 13, pages 369–380, 2019. doi: 10.1609/icwsm.v13i01.3237
-
[29]
Modeling framing in immigration discourse on social media
Julia Mendelsohn, Ceren Budak, and David Jurgens. Modeling framing in immigration discourse on social media. InProceedings of NAACL 2021, pages 2219– 2263, 2021. doi: 10.18653/v1/2021.naacl-main.179
-
[30]
SGH ate C heck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of S ingapore
Ri Chi Ng, Nirmalendu Prakash, Ming Shan Hee, Kenny Tsu Wei Choo, and Roy Ka-Wei Lee. SGHateCheck: Functional tests for detecting hate speech in low-resource languages of singapore. InProceedings of the 8th Work- shop on Online Abuse and Harms (WOAH 2024), pages 312–331, 2024. doi: 10.18653/v1/2024.woah-1.24
-
[31]
Moral exclusion and injustice: An intro- duction.Journal of Social Issues, 46(1):1–20, 1990
Susan Opotow. Moral exclusion and injustice: An intro- duction.Journal of Social Issues, 46(1):1–20, 1990. doi: 10.1111/j.1540-4560.1990.tb00268.x
-
[32]
Pennebaker, Ryan L
James W. Pennebaker, Ryan L. Boyd, Kayla Jordan, and Kate Blackburn. The development and psychometric properties of LIWC2015. Technical report, University of Texas at Austin, Austin, TX, 2015
2015
-
[33]
Steve Rathje, Jay J. Van Bavel, and Sander van der Lin- den. Out-group animosity drives engagement on social media.Proceedings of the National Academy of Sci- ences, 118(26):e2024292118, 2021. doi: 10.1073/pnas. 2024292118
-
[34]
H ate C heck: Functional Tests for Hate Speech Detection Models
Paul Röttger, Bertie Vidgen, Dong Nguyen, Zeerak Waseem, Helen Margetts, and Janet Pierrehumbert. Hat- eCheck: Functional tests for hate speech detection mod- els. InProceedings of ACL-IJCNLP 2021 (Long Papers), pages 41–58, 2021. doi: 10.18653/v1/2021.acl-long.4
-
[35]
Multilingual HateCheck: Func- tional tests for multilingual hate speech detection mod- els
Paul Röttger, Haitham Seelawi, Debora Nozza, Zeerak Talat, and Bertie Vidgen. Multilingual HateCheck: Func- tional tests for multilingual hate speech detection mod- els. InProceedings of WOAH 2022, pages 154–169,
2022
-
[36]
doi: 10.18653/v1/2022.woah-1.15
-
[37]
Maarten Sap, Swabha Swayamdipta, Laura Vianna, Xuhui Zhou, Yejin Choi, and Noah A. Smith. Annota- tors with attitudes: How annotator beliefs and identities bias toxic language detection. InProceedings of NAACL 2022, pages 5884–5906, 2022. doi: 10.18653/v1/2022. naacl-main.431
-
[38]
Moralized lan- guage predicts hate speech on social media.PNAS Nexus, 1(5):pgac281, 2022
Kirill Solovev and Nicolas Pröllochs. Moralized lan- guage predicts hate speech on social media.PNAS Nexus, 1(5):pgac281, 2022. doi: 10.1093/pnasnexus/pgac281
-
[39]
Stephan and Cookie White Stephan
Walter G. Stephan and Cookie White Stephan. An integrated threat theory of prejudice. In Stuart Os- kamp, editor,Reducing Prejudice and Discrimination, pages 23–45. Lawrence Erlbaum, 2000. doi: 10.4324/ 9781410605634-7
2000
-
[40]
Stephan and Cookie White Stephan
Walter G. Stephan and Cookie White Stephan. Inter- group threats. In Chris G. Sibley and Fiona Kate Barlow, editors,The Cambridge Handbook of the Psychology of Prejudice, pages 131–148. Cambridge University Press,
-
[41]
doi: 10.1017/9781316161579.007
-
[42]
Henri Tajfel and John C. Turner. An integrative theory of intergroup conflict. InThe Social Psychology of Inter- group Relations, pages 33–47. Brooks/Cole, 1979. doi: 10.4324/9780203505984-16
-
[43]
Detecting east asian prejudice on social media
Bertie Vidgen, Austin Botelho, David Broniatowski, Ella Guest, Matthew Hall, Helen Margetts, Rebekah Tromble, Zeerak Waseem, and Scott Hale. Detecting east asian prejudice on social media. InProceedings of the 4th Workshop on Online Abuse and Harms (WOAH), pages 162–172, 2020. doi: 10.18653/v1/2020.alw-1.19. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.