Anisotropy Decides Cosine vs. Rank Metrics for Text Embeddings
Pith reviewed 2026-06-30 07:13 UTC · model grok-4.3
The pith
Anisotropy in text embedding spaces decides whether cosine or rank metrics perform better.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
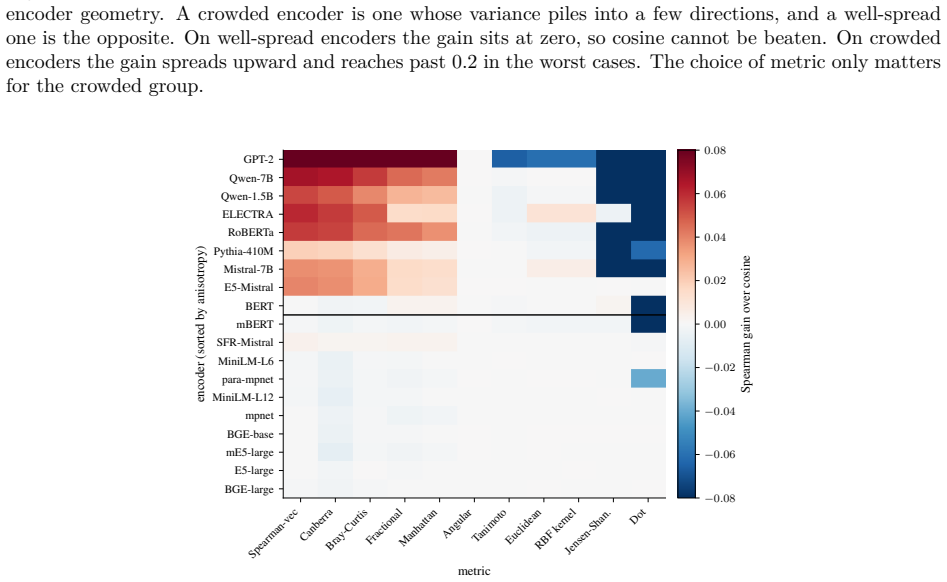
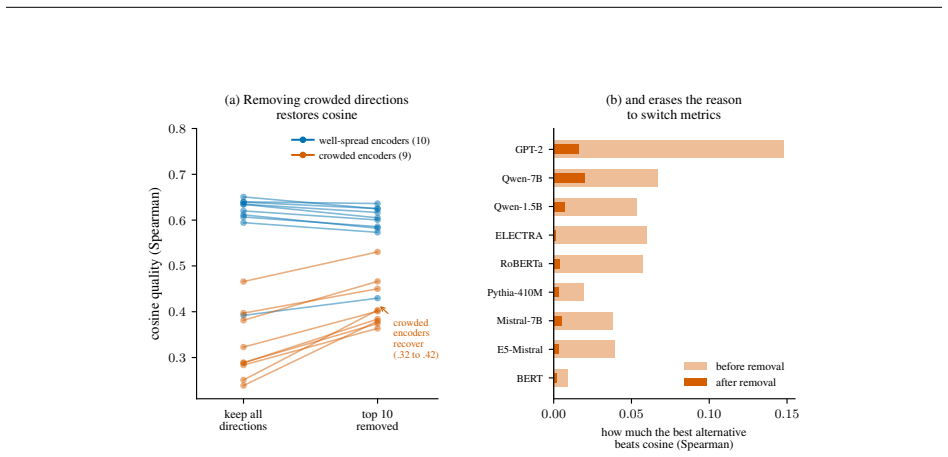
When an encoder spreads its variance evenly across directions, cosine is the best parameter-free choice and no other metric helps by a usable margin. When the variance concentrates into a few dominant directions, a property known as anisotropy, rank-based and L1-type metrics beat cosine by a clear margin. One number, the fraction of variance held by the single most dominant dimension, predicts how much the alternatives help across all nineteen encoders, with a rank correlation of 0.86 and a linear correlation of 0.95. To test this as the cause, projecting out the dominant directions makes cosine recover and the advantage of the other metrics nearly vanishes, but only on the encoders that wer
What carries the argument
The fraction of total variance captured by the single most dominant principal component, which serves as a scalar diagnostic of anisotropy and directly predicts metric preference.
If this is right
- Cosine similarity remains the default wherever encoders are well spread, which covers most fine-tuned sentence transformers used in retrieval.
- For anisotropic encoders the switch to rank or L1 metrics yields a sizable relative gain precisely where cosine starts weakest.
- The geometry of the space, not training method, dictates the right metric; where they disagree the metric follows the geometry.
- Normalizing vectors to unit length does not remove the effect, showing it is directional rather than magnitude-based.
Where Pith is reading between the lines
- The diagnostic could be computed once per encoder and stored as metadata to auto-select the metric at query time.
- The same variance-fraction test might apply to image or audio embeddings if their anisotropy patterns behave similarly.
- If the projection-out result generalizes, fine-tuning objectives that penalize dominant directions could make cosine universally optimal without changing the metric.
Load-bearing premise
The projection-out experiment isolates anisotropy as the causal factor rather than some other correlated property of the embedding space or the datasets.
What would settle it
Run the same suite of metrics on a new set of encoders, compute the dominant-dimension variance fraction for each, and check whether the observed performance gap between cosine and rank metrics still follows the same 0.95 linear correlation.
Figures


read the original abstract
The standard way to compare two text embeddings is cosine similarity. Scattered studies report that a different metric does better, but never pin down the geometric condition that decides when, or why. We settle both with a comprehensive empirical study: nineteen parameter-free similarity metrics on nineteen encoders, from compact sentence transformers up to seven-billion-parameter large language models, across seven datasets. The answer is geometric. When an encoder spreads its variance evenly across directions, cosine is the best parameter-free choice and no other metric helps by a usable margin. When the variance concentrates into a few dominant directions, a property known as anisotropy, rank-based and L1-type metrics beat cosine by a clear margin. The absolute gain is modest, but because cosine starts low on these encoders it is a sizable relative improvement, around twenty percent on average and largest where cosine is weakest. What decides this is the geometry of the embedding space, not how the model was trained: where the two disagree, the metric follows the geometry. One number, the fraction of variance held by the single most dominant dimension, predicts how much the alternatives help across all nineteen encoders, with a rank correlation of 0.86 and a linear correlation of 0.95. To test this as the cause rather than a correlate, we project out the dominant directions: cosine recovers and the advantage of the other metrics nearly vanishes, but only on the encoders that were anisotropic to begin with. The effect is directional, not magnitude based, since it survives normalizing every vector to unit length. Among parameter-free metrics, then, cosine is the right tool wherever an encoder is well spread, which includes the fine-tuned embedders commonly deployed for retrieval, and we give a one-number diagnostic for when it is not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that anisotropy in text embedding spaces—measured as the fraction of variance in the single most dominant dimension—decides whether cosine similarity or rank-based/L1 metrics perform better. Supported by results on 19 encoders (sentence transformers to 7B LLMs) and 19 parameter-free metrics across 7 datasets, it reports Spearman 0.86 and Pearson 0.95 correlations between this anisotropy measure and the advantage of alternatives; a projection-out intervention on dominant directions causes cosine to recover and the alternatives' gains to vanish on anisotropic encoders.
Significance. If the result holds, the work supplies a practical one-number diagnostic for metric choice and a geometric account of why cosine suffices for typical fine-tuned embedders but alternatives help elsewhere. The study is strengthened by its scale across encoders and metrics plus the explicit projection intervention as a causal probe rather than purely correlational evidence.
major comments (1)
- [Projection-out experiment] Projection-out experiment: the manuscript does not state whether the dominant directions are estimated from embeddings held out independently of the seven evaluation datasets. If computed on the evaluation embeddings themselves, the intervention risks removing dataset-specific semantic alignments correlated with anisotropy rather than isolating the geometric concentration property alone; this directly affects the strength of the causal claim that anisotropy 'decides' the metric choice.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for additional detail on the projection-out experiment. We address the concern directly below and will revise the manuscript to improve clarity on this point.
read point-by-point responses
-
Referee: Projection-out experiment: the manuscript does not state whether the dominant directions are estimated from embeddings held out independently of the seven evaluation datasets. If computed on the evaluation embeddings themselves, the intervention risks removing dataset-specific semantic alignments correlated with anisotropy rather than isolating the geometric concentration property alone; this directly affects the strength of the causal claim that anisotropy 'decides' the metric choice.
Authors: We agree that the manuscript should explicitly state the procedure. The dominant directions were estimated from the embeddings of each evaluation dataset (i.e., not from held-out data independent of the seven datasets). We will revise the relevant section to make this clear. On the potential confound: the projection is performed in a purely unsupervised manner using only the first principal component(s) of the embedding matrix for that dataset; no pairwise similarity labels, task supervision, or downstream metric information is used. The intervention therefore removes directions of maximal variance rather than directions selected for semantic relevance to any particular query-document pair. The fact that the same pattern (cosine recovery and disappearance of alternative-metric gains) appears consistently across all seven datasets, and that the strength of the effect tracks the pre-intervention anisotropy measure, indicates that the geometric concentration property is being isolated. Nevertheless, we acknowledge that a fully held-out estimation would further strengthen the causal interpretation and will note this as a possible direction for follow-up work. revision: yes
Circularity Check
No circularity: empirical correlations and projection intervention are independent of inputs
full rationale
The paper reports an empirical study measuring anisotropy (top-dimension variance fraction) on embeddings and correlating it with downstream metric performance differences across 19 encoders and 7 datasets, yielding rank corr 0.86 and linear corr 0.95. The projection-out experiment removes dominant directions from the same embeddings and observes cosine recovery, serving as a direct manipulation test rather than a definitional reduction. Neither step invokes self-citations, fitted parameters renamed as predictions, ansatzes smuggled via prior work, or uniqueness theorems. The geometry-to-performance link is computed from held-out task evaluations and is falsifiable; no equation or claim reduces the result to its own inputs by construction. This is a standard non-circular empirical finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embeddings are finite-dimensional real vectors whose pairwise comparisons can be meaningfully ranked by the listed parameter-free metrics.
Reference graph
Works this paper leans on
-
[1]
Aggarwal, Alexander Hinneburg, and Daniel A
Charu C. Aggarwal, Alexander Hinneburg, and Daniel A. Keim. On the surprising behavior of distance metrics in high dimensional space.Database Theory — ICDT 2001, pp. 420–434,
2001
-
[2]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated corpusforlearningnaturallanguageinference. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 632–642,
2015
-
[3]
Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation
Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. InProceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pp. 1–14,
2017
-
[4]
BERT: Pre-training of deep bidirec- tional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirec- tional transformers for language understanding. InProceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL- HLT), pp. 4171–4186,
2019
-
[5]
How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 55–65,
2019
-
[6]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6894–6910,
2021
-
[7]
Exploring anisotropy and outliers in multilingual language models for cross-lingual semantic sentence similarity
Katharina Hämmerl, Alina Fastowski, Jindřich Libovický, and Alexander Fraser. Exploring anisotropy and outliers in multilingual language models for cross-lingual semantic sentence similarity. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 7023–7037,
2023
-
[8]
WhiteningBERT: An easy unsupervised sentence embedding approach.Findings of the Association for Computational Linguistics: EMNLP 2021, pp
Junjie Huang, Duyu Tang, Wanjun Zhong, Shuai Lu, Linjun Shou, Ming Gong, Daxin Jiang, and Nan Duan. WhiteningBERT: An easy unsupervised sentence embedding approach.Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 238–244,
2021
-
[9]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B. arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
BERT busters: Outlier di- mensions that disrupt transformers
Olga Kovaleva, Saurabh Kulshreshtha, Anna Rogers, and Anna Rumshisky. BERT busters: Outlier di- mensions that disrupt transformers. InFindings of the Association for Computational Linguistics: ACL- IJCNLP 2021, pp. 3392–3405,
2021
-
[11]
Riva Shalom, and Michal Chalamish
Avivit Levy, B. Riva Shalom, and Michal Chalamish. A guide to similarity measures.arXiv preprint arXiv:2408.07706,
-
[12]
On the sentence embeddings from pre-trained language models
Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. On the sentence embeddings from pre-trained language models. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9119–9130,
2020
-
[13]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[14]
MTEB: Massive text embedding bench- mark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. MTEB: Massive text embedding bench- mark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 2014–2037,
2014
- [15]
-
[16]
Outlier dimensions that dis- rupt transformers are driven by frequency
Giovanni Puccetti, Anna Rogers, Aleksandr Drozd, and Felice Dell’Orletta. Outlier dimensions that dis- rupt transformers are driven by frequency. InFindings of the Association for Computational Linguistics: EMNLP 2022, pp. 1286–1304,
2022
-
[17]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 3982–3992,
2019
-
[18]
IsoScore: Measuring the uniformity of embedding space utilization
14 William Rudman, Nate Gillman, Tyler Rayne, and Carsten Eickhoff. IsoScore: Measuring the uniformity of embedding space utilization. InFindings of the Association for Computational Linguistics: ACL 2022, pp. 3325–3339,
2022
-
[19]
Is cosine-similarity of embeddings really about similarity? InCompanion Proceedings of the ACM Web Conference 2024 (WWW ’24 Companion), pp
Harald Steck, Chaitanya Ekanadham, and Nathan Kallus. Is cosine-similarity of embeddings really about similarity? InCompanion Proceedings of the ACM Web Conference 2024 (WWW ’24 Companion), pp. 887–890,
2024
-
[20]
Jianlin Su, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. Whitening sentence representations for better semantics and faster retrieval.arXiv preprint arXiv:2103.15316,
-
[21]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Federico Tessari, Kunpeng Yao, and Neville Hogan. Surpassing cosine similarity for multidimensional com- parisons: Dimension insensitive euclidean metric.arXiv preprint arXiv:2407.08623,
-
[23]
All bark and no bite: Rogue dimensions in transformer language models obscure representational quality
William Timkey and Marten van Schijndel. All bark and no bite: Rogue dimensions in transformer language models obscure representational quality. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4527–4546,
2021
-
[24]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Adina Williams, Nikita Nangia, and Samuel R. Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pp. 1112–1122,
2018
-
[26]
PAWS: Paraphrase adversaries from word scrambling
Yuan Zhang, Jason Baldridge, and Luheng He. PAWS: Paraphrase adversaries from word scrambling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pp. 1298–1308,
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.