RoPE-Aware Bit Allocation for KV-Cache Quantization
Pith reviewed 2026-06-26 01:03 UTC · model grok-4.3
The pith
RoPE-aware bit allocation preserves attention logits better than uniform quantization under the same KV-cache bit budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
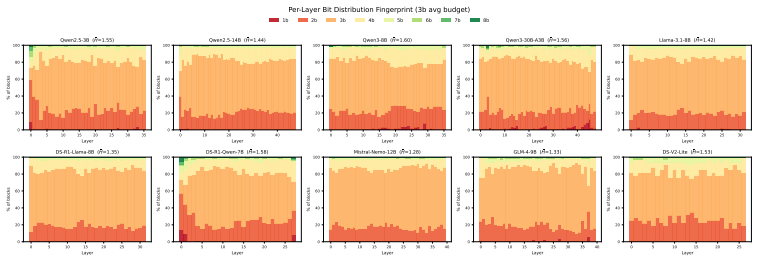
Block-GTQ is a RoPE-aware bit allocator for key-cache quantization built on TurboQuant-MSE. For each layer and KV head it computes a label-free energy score for each RoPE block and greedily allocates integer bit widths by marginal gain. Under matched K/V bit budgets Block-GTQ better preserves RoPE query-key logits, cutting per-layer MAE by 32-80% at 2 and 3 b/dim K-only quantization and winning all 367/367 layer comparisons against uniform TQ-MSE. These fidelity gains translate to stronger downstream long-context performance.
What carries the argument
Label-free energy score per RoPE frequency block driving greedy marginal-gain bit allocation.
If this is right
- Better preserves RoPE query-key logits with lower MAE on all tested layers and models.
- Raises NIAH average from 70.6 to 97.4 at K2V2 on Llama-3.1-8B-Instruct.
- Achieves close to fp16 scores on AIME 2024/2025 with K3V2 where uniform quantization drops to zero.
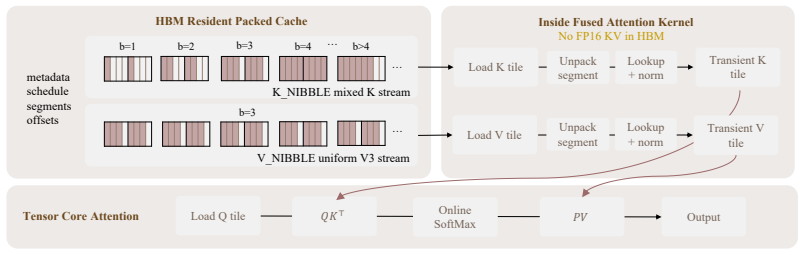
- Enables 3.24x KV-cache compression with packed serving while running 1.34x faster than fp16 at 128K context.
- Supports 256K and 512K contexts where fp16 runs out of memory.
Where Pith is reading between the lines
- The energy-score proxy could be tested on other frequency-based position embeddings to check generality.
- Integration with other quantization or compression methods might yield additive gains in memory efficiency.
- The approach may reduce the need for fp16 recent-key buffers in long-context inference.
- Deployment on edge devices could benefit from the reduced memory footprint at extended contexts.
Load-bearing premise
That the label-free energy score per RoPE block is a reliable proxy for the block's sensitivity to quantization error so that greedy allocation produces near-optimal bit widths.
What would settle it
An experiment that independently quantizes each RoPE block to different bit widths and measures the resulting change in attention logit error; if the error reduction does not track the energy scores the allocation strategy loses its justification.
Figures







read the original abstract
Existing low-bit KV-cache quantizers often treat each cached key as a flat vector. Under RoPE, however, a key's contribution to a future attention logit decomposes into a position-dependent sum over two-dimensional frequency blocks. This makes key-cache quantization a block-wise bit-allocation problem: high-energy RoPE blocks are more sensitive to quantization error and should receive more bits. We introduce Block-GTQ, a RoPE-aware bit allocator for key-cache quantization built on TurboQuant-MSE(TQ-MSE). For each layer and KV head, Block-GTQ computes a label-free energy score for each RoPE block and greedily allocates integer bit widths by marginal gain. Under matched K/V bit budgets, Block-GTQ better preserves RoPE query-key logits on a ten-model diagnostic panel, cutting per-layer MAE by 32-80% at 2 and 3 b/dim K-only quantization and winning all 367/367 layer comparisons against uniform TQ-MSE. These fidelity gains translate to stronger downstream long-context retrieval, understanding, and reasoning. At K2V2 on Llama-3.1-8B-Instruct, Block-GTQ raises the six-task NIAH average from 70.6 to 97.4, and the LongBench-EN average from 36.87 to 53.31. On AIME 2024/2025 with DeepSeek-R1-Distill-Qwen-7B, without an fp16 recent-key buffer, Block-GTQ at K3V2 scores 51.7/37.5, close to fp16's 54.2/37.9, whereas uniform TQ-MSE collapses to 0.0/0.0. We further implement a packed-cache serving path. On a single H800 GPU with Qwen2.5-3B-Instruct, packed K3V3 achieves 3.24x KV-cache compression with fp16-comparable quality, runs 1.34x faster than fp16 FlashAttention2 at 128K context, reduces peak memory from 56.31 GB to 19.85 GB, and remains feasible at 256K and 512K where fp16 OOMs. Code is available at https://github.com/JIA-Lab-research/blockgtq.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Block-GTQ, a RoPE-aware bit allocator for KV-cache quantization built on TurboQuant-MSE. For each layer and KV head it computes a label-free energy score per RoPE frequency block and performs greedy marginal-gain integer bit allocation. Under matched K/V budgets the method is reported to reduce per-layer MAE on preserved query-key logits by 32-80% at 2-3 b/dim K-only quantization, win all 367/367 layer comparisons against uniform TQ-MSE on a ten-model panel, and translate those fidelity gains into large improvements on long-context retrieval (NIAH), understanding (LongBench), and reasoning (AIME) tasks, plus practical serving speedups and memory reductions at 128K-512K contexts.
Significance. If the energy-score proxy is validated, the work supplies a concrete, label-free mechanism for non-uniform KV quantization that respects the block-wise structure induced by RoPE. The scale of the diagnostic panel (ten models, 367 layers) and the downstream task gains (e.g., NIAH 70.6→97.4 at K2V2 on Llama-3.1-8B) would be practically relevant for long-context serving; the public code link is a clear strength.
major comments (2)
- [§3, §4.1] §3 (method) and §4.1 (diagnostics): the headline claim that Block-GTQ’s gains are due to RoPE-aware allocation rather than merely non-uniform bits rests on the energy score being a monotonic proxy for each block’s contribution to query-key logit error. No diagnostic is reported that ranks blocks by the energy score and then measures the resulting per-block MAE under quantization; without this correlation check the 32-80% MAE reduction and 367/367 win rate could be explained by any non-uniform allocator.
- [Table 2, Figure 4] Table 2 / Figure 4 (downstream results): the reported NIAH and LongBench gains at K2V2 and K3V2 are large, but the paper does not state whether the uniform TQ-MSE baseline also received the same packed-cache serving path and recent-key buffer policy; any mismatch would inflate the apparent benefit of the allocator itself.
minor comments (2)
- [§3.2] Notation for the energy score E_b and the marginal-gain function should be introduced with a single equation block rather than scattered across prose.
- [§4] The ten-model diagnostic panel is described only by name; a table listing model sizes, layer counts, and head dimensions would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3, §4.1] §3 (method) and §4.1 (diagnostics): the headline claim that Block-GTQ’s gains are due to RoPE-aware allocation rather than merely non-uniform bits rests on the energy score being a monotonic proxy for each block’s contribution to query-key logit error. No diagnostic is reported that ranks blocks by the energy score and then measures the resulting per-block MAE under quantization; without this correlation check the 32-80% MAE reduction and 367/367 win rate could be explained by any non-uniform allocator.
Authors: We agree that an explicit per-block correlation between the energy score and quantization-induced MAE would provide stronger validation of the RoPE-aware mechanism. While the energy score is derived directly from the RoPE block decomposition of the query-key inner product and the greedy allocator is designed to allocate bits proportionally to these scores, the current diagnostics focus on aggregate MAE and layer-wise win rates. In the revised manuscript we will add a new diagnostic (new figure in §4.1) that ranks RoPE blocks by energy score within each head/layer and reports the corresponding per-block MAE under both uniform TQ-MSE and Block-GTQ quantization, thereby confirming the monotonic relationship. revision: yes
-
Referee: [Table 2, Figure 4] Table 2 / Figure 4 (downstream results): the reported NIAH and LongBench gains at K2V2 and K3V2 are large, but the paper does not state whether the uniform TQ-MSE baseline also received the same packed-cache serving path and recent-key buffer policy; any mismatch would inflate the apparent benefit of the allocator itself.
Authors: All reported downstream results, including those for the uniform TQ-MSE baseline, were obtained using the identical packed-cache serving path and recent-key buffer policy described in §5.3. We will insert an explicit clarifying sentence in the revised §5.2 and §5.3 to state this equivalence and thereby remove any ambiguity. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes Block-GTQ as a new RoPE-aware bit allocator that computes a label-free energy score per RoPE block and uses greedy marginal-gain allocation. This is evaluated empirically against the uniform TQ-MSE baseline on logit MAE and downstream tasks across multiple models. The energy score is not derived from or fitted to the evaluation metrics, and the performance gains are measured externally rather than being tautological. No self-definitional loops, fitted predictions, or load-bearing self-citations reduce the claims to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Under RoPE, a key's contribution to a future attention logit decomposes into a position-dependent sum over two-dimensional frequency blocks.
invented entities (1)
-
Block-GTQ
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages ...
2024
-
[2]
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Wen Xiao. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. InConference on Language Modeling (COLM),
-
[3]
Abdelfattah, and Kai-Chiang Wu
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S. Abdelfattah, and Kai-Chiang Wu. Palu: Kv-cache compression with low-rank projection. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[4]
Lon- glora: Efficient fine-tuning of long-context large language models
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Lon- glora: Efficient fine-tuning of long-context large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[5]
MagicPIG: Lsh sampling for efficient llm generation
Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Léon Bottou, Zhihao Jia, and Beidi Chen. MagicPIG: Lsh sampling for efficient llm generation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[6]
Abdelfattah, and Diana Marculescu
Hung-Yueh Chiang, Chi-Chih Chang, Yu-Chen Lu, Chien-Yu Lin, Kai-Chiang Wu, Mohamed S. Abdelfattah, and Diana Marculescu. UniQL: Unified quantization and low-rank compression for adaptive edge llms. InInternational Conference on Learning Representations (ICLR), 2026. 11
2026
-
[7]
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
Pith/arXiv arXiv 2023
-
[8]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[9]
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[10]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S. Kevin Zhou. Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2407.11550
Pith/arXiv arXiv 2025
-
[11]
Model tells you what to discard: Adaptive KV cache compression for LLMs
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive KV cache compression for LLMs. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[12]
Polarquant: Quantizing kv caches with polar transformation
Insu Han, Praneeth Kacham, Vahab Mirrokni, Amir Zandieh, and Amin Karbasi. Polarquant: Quantizing kv caches with polar transformation. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[13]
Zipcache: Accurate and efficient kv cache quantization with salient token identification
Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, and Bohan Zhuang. Zipcache: Accurate and efficient kv cache quantization with salient token identification. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[14]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[15]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654, 2024
Pith/arXiv arXiv 2024
-
[16]
Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, and Tuo Zhao. GEAR: An efficient KV cache compression recipe for near-lossless generative inference of LLM.arXiv preprint arXiv:2403.05527, 2024
arXiv 2024
-
[17]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
2023
-
[18]
CommVQ: Commutative vector quantization for KV cache compression
Junyan Li, Yang Zhang, Muhammad Yusuf Hassan, Talha Chafekar, Tianle Cai, Zhile Ren, Pengsheng Guo, Foroozan Karimzadeh, Colorado Reed, Chong Wang, and Chuang Gan. CommVQ: Commutative vector quantization for KV cache compression. InPro- ceedings of the 42nd International Conference on Machine Learning, volume 267 ofPro- ceedings of Machine Learning Resear...
2025
-
[19]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[20]
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, and Bohan Zhuang. Mini- Cache: KV cache compression in depth dimension for large language models.arXiv preprint arXiv:2405.14366, 2024
arXiv 2024
-
[21]
PM-KVQ: Progressive mixed-precision kv cache quantization for long-cot llms
Tengxuan Liu, Shiyao Li, Jiayi Yang, Tianchen Zhao, Feng Zhou, Xiaohui Song, Guohao Dai, Shengen Yan, Huazhong Yang, and Yu Wang. PM-KVQ: Progressive mixed-precision kv cache quantization for long-cot llms. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2505.18610; code:https://github.com/thu-nics/PM-KVQ. 12
arXiv 2026
-
[22]
Mellette, Alex Forencich, Rukshani Athapathu, Alex C
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. CacheGen: KV cache compression and streaming for fast language model serving. InProceedings of the ACM SIGCOMM 2024 Conference, 2024. doi: 10.1145/3651890.3672274
-
[23]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time.arXiv preprint arXiv:2305.17118, 2023
arXiv 2023
-
[24]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. InForty-first International Conference on Machine Learning (ICML), 2024
2024
-
[25]
Weian Mao, Xi Lin, Wei Huang, Yuxin Xie, Tianfu Fu, Bohan Zhuang, Song Han, and Yukang Chen. TriAttention: Efficient long reasoning with trigonometric KV compression.arXiv preprint arXiv:2604.04921, 2026
Pith/arXiv arXiv 2026
-
[26]
Yarn: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. InInternational Conference on Learning Repre- sentations (ICLR), 2024
2024
-
[27]
Efficiently scaling transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. arXiv preprint arXiv:2211.05102, 2022
arXiv 2022
-
[28]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y . Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. FlexGen: High-throughput generative inference of large language models with a single GPU.arXiv preprint arXiv:2303.06865, 2023
arXiv 2023
-
[29]
Cache me if you must: Adaptive key-value quantization for large language models
Alina Shutova, Vladimir Malinovskii, Vage Egiazarian, Denis Kuznedelev, Denis Mazur, Nikita Surkov, Ivan Ermakov, and Dan Alistarh. Cache me if you must: Adaptive key-value quantization for large language models. InForty-second International Conference on Machine Learning (ICML), 2025
2025
-
[30]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[31]
Accurate kv cache quantization with outlier tokens trac- ing
Yi Su, Yuechi Zhou, Quantong Qiu, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhe- feng Wang, and Min Zhang. Accurate kv cache quantization with outlier tokens trac- ing. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12895–12915, Vienna, Austria, 2025. Associ- ation for Computati...
-
[32]
KVSink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms
Zunhai Su and Kehong Yuan. KVSink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms. InConference on Language Modeling (COLM), 2025
2025
-
[33]
Zunhai Su, Hanyu Wei, Zhe Chen, Wang Shen, Linge Li, Huangqi Yu, and Kehong Yuan. RotateKV: Accurate and robust 2-bit KV cache quantization for LLMs via outlier-aware adaptive rotations. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI), pages 6200–6208, 2025. doi: 10.24963/ijcai.2025/690. URL https://www...
-
[34]
MoQAE: Mixed-precision quantization for long-context llm inference via mixture of quantization-aware experts
Wei Tao, Haocheng Lu, Xiaoyang Qu, Bin Zhang, Kai Lu, Jiguang Wan, and Jianzong Wang. MoQAE: Mixed-precision quantization for long-context llm inference via mixture of quantization-aware experts. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10810–10820, Vienna, Austria,
-
[35]
doi: 10.18653/v1/2025.acl-long.531
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.531. URL https://aclanthology.org/2025.acl-long.531/. 13
-
[36]
SQuat: Subspace-orthogonal kv cache quantization.arXiv preprint arXiv:2503.24358, 2025
Hao Wang, Ligong Han, Kai Xu, and Akash Srivastava. SQuat: Subspace-orthogonal kv cache quantization.arXiv preprint arXiv:2503.24358, 2025
arXiv 2025
-
[37]
Haojun Xia, Xiaoxia Wu, Jisen Li, Robert Wu, Junxiong Wang, Jue Wang, Chenxi Li, Aman Singhal, Alay Dilipbhai Shah, Alpay Ariyak, Donglin Zhuang, Zhongzhu Zhou, Ben Athi- waratkun, Zhen Zheng, and Shuaiwen Leon Song. Kitty: Accurate and efficient 2-bit kv cache quantization with dynamic channel-wise precision boost.arXiv preprint arXiv:2511.18643,
-
[38]
Code:https://github.com/Summer-Summer/Kitty
-
[39]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[40]
RAP: KV-cache compres- sion via RoPE-aligned pruning.arXiv preprint arXiv:2602.02599, 2026
Jihao Xin, Tian Lyu, David Keyes, Hatem Ltaief, and Marco Canini. RAP: KV-cache compres- sion via RoPE-aligned pruning.arXiv preprint arXiv:2602.02599, 2026
arXiv 2026
-
[41]
June Yong Yang, Byeongwook Kim, Jeongin Bae, Beomseok Kwon, Gunho Park, Eunho Yang, Se Jung Kwon, and Dongsoo Lee. No token left behind: Reliable kv cache compression via importance-aware mixed precision quantization.arXiv preprint arXiv:2402.18096, 2024
arXiv 2024
-
[42]
SubGen: Token generation in sublinear time and memory.arXiv preprint arXiv:2402.06082, 2024
Amir Zandieh, Insu Han, Vahab Mirrokni, and Amin Karbasi. SubGen: Token generation in sublinear time and memory.arXiv preprint arXiv:2402.06082, 2024
arXiv 2024
-
[43]
Turboquant: Online vec- tor quantization with near-optimal distortion rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. Turboquant: Online vec- tor quantization with near-optimal distortion rate. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[44]
Tao Zhang, Ziqian Zeng, Hao Peng, Huiping Zhuang, and Cen Chen. MixKVQ: Query- aware mixed-precision kv cache quantization for long-context reasoning.arXiv preprint arXiv:2512.19206, 2025
arXiv 2025
-
[45]
Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization
Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, and Anshumali Shrivastava. Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[46]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[47]
Yuhao Zhou, Sirui Song, Boyang Liu, Zhiheng Xi, Senjie Jin, Xiaoran Fan, Zhihao Zhang, Wei Li, and Xuanjing Huang. EliteKV: Scalable KV cache compression via RoPE frequency selection and joint low-rank projection.arXiv preprint arXiv:2503.01586, 2025. Appendix Roadmap Appendix A collects proofs for Block-GTQ (error bound, block weight, greedy optimality)....
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.