ReCache: Learning Budget-Aware Caching Schedules for Diffusion Models via REINFORCE
Pith reviewed 2026-06-28 02:07 UTC · model grok-4.3
The pith
ReCache learns a policy to pick which diffusion denoising steps to recompute given a target budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
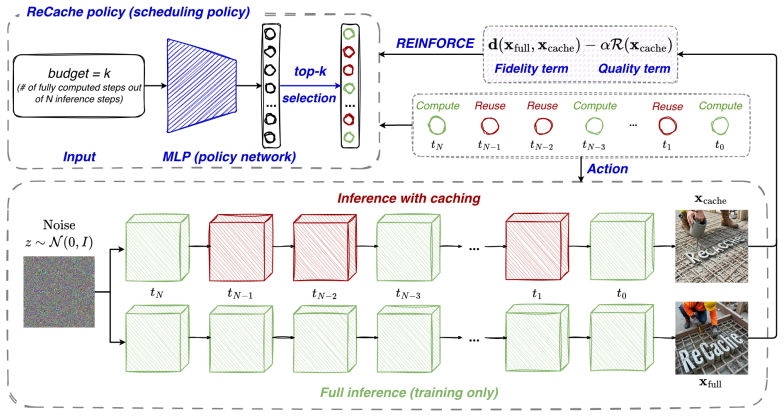
ReCache takes a target budget k and learns the recomputation schedule that maximizes generation quality via policy gradients. Generations from uncached inference serve as matching targets paired with a quality reward. A single trained policy adapts across computational budgets and works with any caching mechanism including feature reuse and feature forecasting.
What carries the argument
A REINFORCE-trained policy that outputs the binary recomputation schedule conditioned on the target budget k.
If this is right
- One policy handles multiple budgets at inference without retraining.
- The approach improves LPIPS and VBench scores over uniform and error-heuristic schedules at the same compute level.
- It applies equally to feature-reuse and feature-forecasting caching mechanisms.
- Quality gains hold for both image models like FLUX and video models like Wan 2.1.
Where Pith is reading between the lines
- The method could extend to other iterative generative processes where full trajectories are expensive to differentiate.
- Direct budget control might enable new user interfaces that let applications adjust quality on the fly.
- Combining the learned schedule with model distillation or quantization could produce further efficiency gains.
Load-bearing premise
That quality measured against full uncached inference serves as a reliable proxy for desired outputs across budgets and caching mechanisms.
What would settle it
A controlled test at fixed budget where human raters or an independent metric consistently prefer outputs from a uniform or heuristic schedule over the learned ReCache schedule.
Figures




read the original abstract
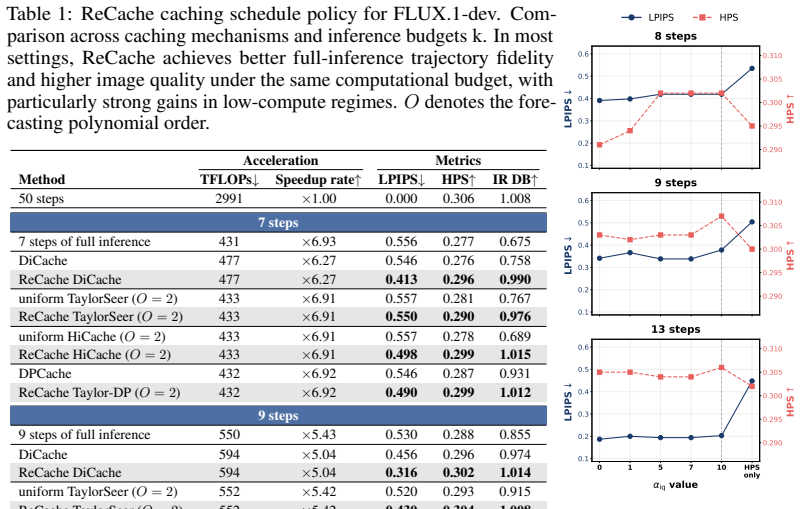
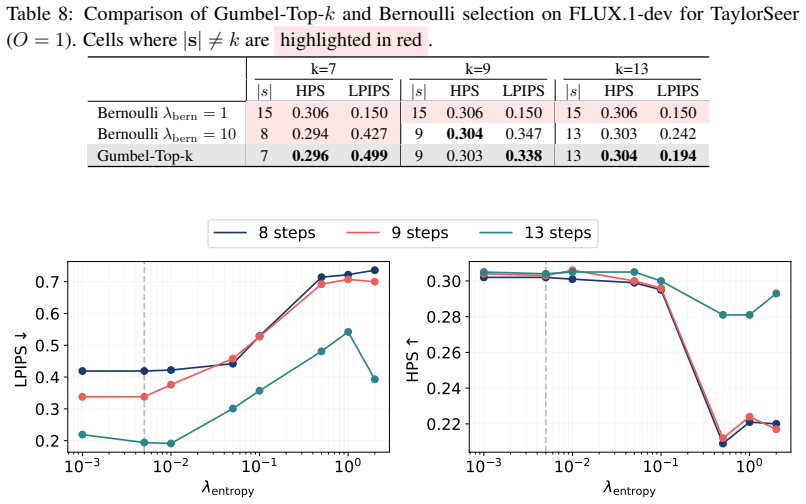
Modern diffusion models generate high-quality images and videos, but their iterative denoising process makes inference expensive. Feature caching accelerates sampling by reusing or predicting intermediate activations across neighboring denoising steps, exploiting the redundancy of computations along the reverse trajectory. In this work, we focus on the caching schedule: selecting which denoising steps should be fully recomputed. Existing schedules are either fixed (e.g. uniform) or chosen adaptively from per-step error heuristics; in both cases, the actual compute cost is a side-effect of hand-tuned thresholds rather than a quantity the user can specify. We propose ReCache, which inverts this: given a target budget k, it learns the recomputation schedule that maximizes generation quality, turning compute into a directly controllable input. ReCache trains via policy gradients, sidestepping backpropagation through full diffusion inference, and uses no labelled data. Generations from uncached inference serve as matching targets, paired with a reward for generation quality. ReCache is compatible with any caching mechanism, including feature reuse and feature forecasting; for each mechanism, a single trained policy adapts across computational budgets at inference time. ReCache consistently outperforms scheduling baselines: under a $\times5.04$ FLOPs reduction on FLUX, it reduces LPIPS by 31% (from 0.456 to 0.316) compared to DiCache; on Wan 2.1 at a $\sim \times2.6$ speedup, it drops LPIPS by 65% (from 0.480 to 0.169) and boosts the VBench score by 7% (5.6 points, from 70.4 to 76.0) over uniform HiCache. Code is available at https://github.com/thecrazymage/ReCache.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReCache, a REINFORCE-based method to learn caching schedules for diffusion models that take a user-specified budget k as input and optimize for generation quality. It trains a policy to select recomputation steps, using uncached full-inference generations as matching targets paired with a quality reward; the resulting policy is compatible with feature reuse or forecasting mechanisms and adapts across budgets at inference time without retraining. Reported results include a 31% LPIPS reduction (0.456 to 0.316) versus DiCache on FLUX at ×5.04 FLOPs reduction and a 65% LPIPS drop plus 7% VBench gain versus uniform HiCache on Wan 2.1 at ×2.6 speedup.
Significance. If the proxy reward is reliable, the work would be significant for turning caching from a heuristic side-effect into a controllable, budget-aware input via RL that avoids backpropagation through the full diffusion process and requires no labeled data. The single-policy adaptation across budgets and compatibility with multiple caching mechanisms are practical strengths. Code release supports reproducibility.
major comments (1)
- Abstract: the central claim that ReCache improves perceptual quality under a user-specified budget rests on using uncached generations as matching targets for the quality reward. No ablation, correlation analysis, or human validation is reported showing that this proxy remains aligned with LPIPS/VBench (or user preference) once cached trajectories diverge substantially from the full trajectory; without such evidence the reported gains (e.g., LPIPS 0.456→0.316 on FLUX) cannot be confidently attributed to genuine quality improvement rather than optimization toward an arbitrary training signal.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about the proxy reward's alignment with perceptual metrics when trajectories diverge is well-taken. We address it below and will revise the manuscript with additional analysis.
read point-by-point responses
-
Referee: Abstract: the central claim that ReCache improves perceptual quality under a user-specified budget rests on using uncached generations as matching targets for the quality reward. No ablation, correlation analysis, or human validation is reported showing that this proxy remains aligned with LPIPS/VBench (or user preference) once cached trajectories diverge substantially from the full trajectory; without such evidence the reported gains (e.g., LPIPS 0.456→0.316 on FLUX) cannot be confidently attributed to genuine quality improvement rather than optimization toward an arbitrary training signal.
Authors: We appreciate this point. The reward is defined as a perceptual similarity (negative LPIPS or equivalent) between the cached output and the uncached full-inference image, which serves as the reference for maximum quality. The final reported LPIPS and VBench numbers are computed independently on the generated images (not on the training reward), and the consistent gains over strong baselines indicate that the learned schedules improve actual perceptual quality. Nevertheless, we agree that an explicit correlation study would strengthen the claim. In the revision we will add: (i) an analysis plotting reward values against LPIPS/VBench at controlled levels of trajectory divergence, and (ii) a brief ablation comparing policies trained with the proxy versus a direct LPIPS-to-reference reward where feasible. This will be included in a new subsection of the experiments. revision: yes
Circularity Check
No significant circularity; derivation uses independent full-inference targets
full rationale
The paper trains a REINFORCE policy to select caching schedules that maximize a quality reward derived from matching against uncached full-inference generations. This target is generated externally to the learned policy and is not defined in terms of the policy outputs. Evaluation reports LPIPS and VBench improvements over baselines on the same metric, but the baselines are hand-tuned heuristics rather than optimized under the identical objective, so outperformance is not forced by construction. No equations, self-citations, or ansatzes are shown that reduce the central claim to a renaming or fitted input. The approach is self-contained against the external uncached reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption REINFORCE policy gradients can optimize the schedule without backpropagation through the full diffusion inference process
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571, 2022
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571, 2022
Pith/arXiv arXiv 2022
-
[2]
Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
2024
-
[3]
Black Forest Labs. Flux. https://blackforestlabs.ai/ announcing-black-forest-labs, 2024. Accessed: 2024
2024
-
[4]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[5]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4599–4603, 2023
2023
-
[6]
Dicache: Let diffusion model determine its own cache.arXiv preprint arXiv:2508.17356, 2025
Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Dahua Lin, and Jiaqi Wang. Dicache: Let diffusion model determine its own cache.arXiv preprint arXiv:2508.17356, 2025
arXiv 2025
-
[7]
Quip: 2-bit quanti- zation of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quanti- zation of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
2023
-
[8]
Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2024
2024
-
[9]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. PixArt- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
Pith/arXiv arXiv 2023
-
[10]
Q-dit: Accurate post-training quantization for diffusion transformers
Lei Chen, Yuan Meng, Chen Tang, Xinzhu Ma, Jingyan Jiang, Xin Wang, Zhi Wang, and Wenwu Zhu. Q-dit: Accurate post-training quantization for diffusion transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28306–28315, 2025
2025
-
[11]
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. delta-dit: A training-free acceleration method tailored for diffusion transformers.arXiv preprint arXiv:2406.01125, 2024
arXiv 2024
-
[12]
Bowen Cui, Yuanbin Wang, Huajiang Xu, Biaolong Chen, Aixi Zhang, Hao Jiang, Zhengzheng Jin, Xu Liu, and Pipei Huang. Denoising as path planning: Training-free acceleration of diffusion models with dpcache.arXiv preprint arXiv:2602.22654, 2026
arXiv 2026
-
[13]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
2022
-
[14]
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. Spqr: A sparse-quantized representation for near-lossless llm weight compression.arXiv preprint arXiv:2306.03078, 2023. 10
arXiv 2023
-
[15]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[16]
Structural pruning for diffusion models, 2023
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Structural pruning for diffusion models, 2023
2023
-
[17]
Liang Feng, Shikang Zheng, Jiacheng Liu, Yuqi Lin, Qinming Zhou, Peiliang Cai, Xinyu Wang, Junjie Chen, Chang Zou, Yue Ma, et al. Hicache: Training-free acceleration of diffusion models via hermite polynomial-based feature caching.arXiv preprint arXiv:2508.16984, 2025
arXiv 2025
-
[18]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
Pith/arXiv arXiv 2022
-
[19]
Low-variance black-box gradient estimates for the plackett-luce distribution
Artyom Gadetsky, Kirill Struminsky, Christopher Robinson, Novi Quadrianto, and Dmitry Vetrov. Low-variance black-box gradient estimates for the plackett-luce distribution. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 10126–10135, 2020
2020
-
[20]
Vector quantized diffusion model for text-to-image synthesis
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10696–10706, 2022
2022
-
[21]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[22]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[23]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[24]
Adaptive caching for faster video generation with diffusion transformers
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15240– 15252, 2025
2025
-
[25]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[26]
Token fusion: Bridging the gap between token pruning and token merging
Minchul Kim, Shangqian Gao, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. Token fusion: Bridging the gap between token pruning and token merging. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1383–1392, 2024
2024
-
[27]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[28]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[29]
Buy 4 reinforce samples, get a baseline for free! 2019
Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 reinforce samples, get a baseline for free! 2019
2019
-
[30]
Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement
Wouter Kool, Herke Van Hoof, and Max Welling. Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement. InInternational conference on machine learning, pages 3499–3508. PMLR, 2019. 11
2019
-
[31]
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007, 2024
arXiv 2024
-
[32]
Q-diffusion: Quantizing diffusion models
Xiuyu Li, Yijiang Liu, Long Lian, Huanrui Yang, Zhen Dong, Daniel Kang, Shanghang Zhang, and Kurt Keutzer. Q-diffusion: Quantizing diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17535–17545, 2023
2023
-
[33]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[34]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[35]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7353–7363, 2025
2025
-
[36]
Faster diffusion via temporal attention decomposition.arXiv preprint arXiv:2404.02747, 2024
Haozhe Liu, Wentian Zhang, Jinheng Xie, Francesco Faccio, Mengmeng Xu, Tao Xiang, Mike Zheng Shou, Juan-Manuel Perez-Rua, and Jürgen Schmidhuber. Faster diffusion via temporal attention decomposition.arXiv preprint arXiv:2404.02747, 2024
arXiv 2024
-
[37]
From reusing to forecasting: Accelerating diffusion models with TaylorSeers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerating diffusion models with TaylorSeers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15853–15863, 2025
2025
-
[38]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
Pith/arXiv arXiv 2022
-
[39]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
2022
-
[40]
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025
2025
-
[41]
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
Pith/arXiv arXiv 2023
-
[42]
Zhengyao Lv, Chenyang Si, Junhao Song, Zhenyu Yang, Yu Qiao, Ziwei Liu, and Kwan-Yee K Wong. Fastercache: Training-free video diffusion model acceleration with high quality.arXiv preprint arXiv:2410.19355, 2024
arXiv 2024
-
[43]
Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
Pith/arXiv arXiv 2024
-
[44]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15762–15772, 2024
2024
-
[45]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14297–14306, 2023
2023
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[47]
The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
Robin L Plackett. The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975. 12
1975
-
[48]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
Pith/arXiv arXiv 2023
-
[49]
Vargrad: a low-variance gradient estimator for variational inference.Advances in Neural Information Processing Systems, 33:13481–13492, 2020
Lorenz Richter, Ayman Boustati, Nikolas Nüsken, Francisco Ruiz, and Omer Deniz Akyildiz. Vargrad: a low-variance gradient estimator for variational inference.Advances in Neural Information Processing Systems, 33:13481–13492, 2020
2020
-
[50]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[51]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[52]
Omid Saghatchian, Atiyeh Gh Moghadam, and Ahmad Nickabadi. Cached adaptive token merging: Dynamic token reduction and redundant computation elimination in diffusion model. arXiv preprint arXiv:2501.00946, 2025
arXiv 2025
-
[53]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[54]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022
Pith/arXiv arXiv 2022
-
[55]
Fast high-resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[56]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer, 2024
2024
-
[57]
Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
2022
-
[58]
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. Fora: Fast- forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425, 2024
arXiv 2024
-
[59]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[60]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Pith/arXiv arXiv 2010
-
[61]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[62]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
Pith/arXiv arXiv 2011
-
[63]
Scale-wise distillation of diffusion models.arXiv preprint arXiv:2503.16397, 2025
Nikita Starodubcev, Ilya Drobyshevskiy, Denis Kuznedelev, Artem Babenko, and Dmitry Baranchuk. Scale-wise distillation of diffusion models.arXiv preprint arXiv:2503.16397, 2025
arXiv 2025
-
[64]
Leveraging recursive gumbel-max trick for approximate inference in combinatorial spaces
Kirill Struminsky, Artyom Gadetsky, Denis Rakitin, Danil Karpushkin, and Dmitry P Vetrov. Leveraging recursive gumbel-max trick for approximate inference in combinatorial spaces. Advances in Neural Information Processing Systems, 34:10999–11011, 2021. 13
2021
-
[65]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.Proceedings of machine learning research, 235:48630, 2024
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.Proceedings of machine learning research, 235:48630, 2024
2024
-
[66]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[67]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[68]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity. volume 13, pages 600–612, 2004
2004
-
[69]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
1992
-
[70]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
Pith/arXiv arXiv 2023
-
[71]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[72]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[73]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[74]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[75]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[76]
Ditfastattn: Attention compression for diffusion transformer models.Advances in Neural Information Processing Systems, 37:1196–1219, 2024
Zhihang Yuan, Hanling Zhang, Pu Lu, Xuefei Ning, Linfeng Zhang, Tianchen Zhao, Shengen Yan, Guohao Dai, and Yu Wang. Ditfastattn: Attention compression for diffusion transformer models.Advances in Neural Information Processing Systems, 37:1196–1219, 2024
2024
-
[77]
Training-free and hardware- friendly acceleration for diffusion models via similarity-based token pruning
Evelyn Zhang, Jiayi Tang, Xuefei Ning, and Linfeng Zhang. Training-free and hardware- friendly acceleration for diffusion models via similarity-based token pruning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9878–9886, 2025
2025
-
[78]
Blockdance: Reuse structurally similar spatio-temporal features to accelerate diffusion transformers
Hui Zhang, Tingwei Gao, Jie Shao, and Zuxuan Wu. Blockdance: Reuse structurally similar spatio-temporal features to accelerate diffusion transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12891–12900, 2025
2025
-
[79]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[80]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 14
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.