Toward Multi-Domain and Long-Tailed Quantization via Feature Alignment and Scaling
Pith reviewed 2026-06-28 07:28 UTC · model grok-4.3
The pith
EmaQ aligns multi-domain distributions with CDF projection and sensitivity-aware aggregation to enable effective low-bit quantization under shifts and imbalance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
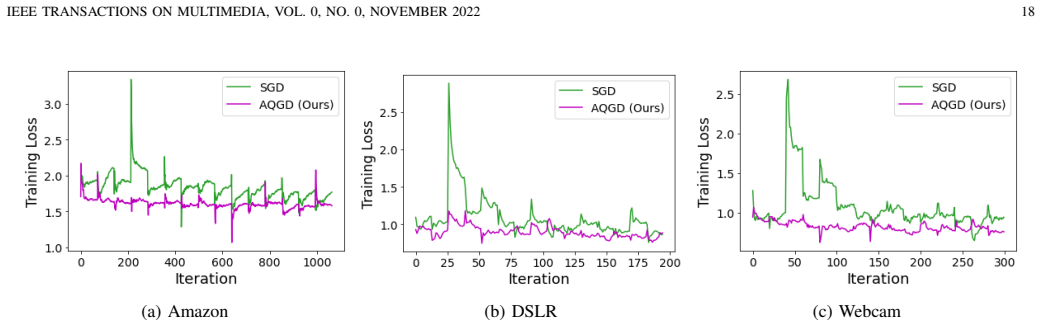
The authors establish that CDF-based feature projection aligns domain distributions while sensitivity-aware weight aggregation stabilizes the quantization process, and that extending these with class-conditioned variance scaling and logit adjustment produces reliable low-bit models for both multi-domain and long-tailed settings, backed by convergence proofs and benchmark results on Office-31, Digits, SynDigits-LT, CIFAR-10-LT, and CIFAR-100-LT.
What carries the argument
CDF-based projection for domain alignment together with sensitivity-aware weight aggregation, extended by class-conditioned variance scaling and confidence-based logit adjustment.
If this is right
- Quantized models can be trained once on mixed-domain data and deployed across domains without retraining.
- Low-bit networks maintain accuracy on long-tailed datasets by reducing majority-class overconfidence.
- Convergence of the quantization process is guaranteed when the sensitivity and scaling terms are used.
- The same alignment and scaling steps apply directly to other low-bit widths such as 2-bit or 3-bit.
Where Pith is reading between the lines
- The same CDF alignment step might transfer to other compression methods such as pruning or knowledge distillation when domain shift is present.
- If the projection truly preserves task-relevant features, quantized models could require less domain-specific adaptation at deployment time.
- Combining EmaQ with online domain detection would allow the method to handle streaming data whose domain distribution changes over time.
Load-bearing premise
The CDF projection aligns domains while keeping information needed for accurate quantization, and the sensitivity aggregation plus class scaling introduce no unaccounted bias and do not require domain labels at test time.
What would settle it
Running EmaQ on Office-31 or CIFAR-10-LT at 4-bit width and finding no accuracy gain over standard post-training quantization baselines would falsify the central performance claim.
Figures




read the original abstract
Quantizing deep neural networks is essential for efficient inference on resource-constrained devices. However, most existing methods are designed for single-domain and class-balanced data, leaving practical settings with domain shifts or severe class imbalance underexplored. We address these challenges with Efficient Multi-Domain Alignment Quantization (EmaQ), which aligns domain distributions through a CDF-based projection and uses sensitivity-aware weight aggregation to stabilize multi-domain quantization. We further extend EmaQ to EmaQ-LT for long-tailed quantization by introducing class-conditioned variance scaling and confidence-based logit adjustment to mitigate majority-class overconfidence. Theoretical analyses establish convergence guarantees and motivate the proposed sensitivity and scaling mechanisms. Experiments on standard, multi-domain (Office-31, Digits), and long-tailed (SynDigits-LT, CIFAR-10-LT, CIFAR-100-LT) benchmarks show that EmaQ and EmaQ-LT achieve strong low-bit performance under domain shift and class imbalance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Efficient Multi-Domain Alignment Quantization (EmaQ) that aligns domain distributions via a CDF-based projection and applies sensitivity-aware weight aggregation for stable multi-domain quantization. It extends the method to EmaQ-LT for long-tailed settings by adding class-conditioned variance scaling and confidence-based logit adjustment. Theoretical analyses are claimed to establish convergence guarantees, and experiments on Office-31, Digits, SynDigits-LT, CIFAR-10-LT, and CIFAR-100-LT are reported to show strong low-bit performance under domain shift and class imbalance.
Significance. If the central mechanisms are shown to preserve quantization-relevant statistics under the proposed transforms, the work would address an underexplored practical setting for quantization. The combination of alignment, sensitivity aggregation, and class-conditioned scaling is a coherent attempt to handle distribution mismatch and imbalance simultaneously.
major comments (3)
- [§3.2] §3.2 (CDF-based projection): the manuscript must demonstrate that the per-feature monotonic CDF transform leaves the relative ordering and magnitudes of Hessian-based sensitivities (or activation ranges) unchanged across domains; otherwise the subsequent sensitivity-aware aggregation step operates on misaligned statistics and the convergence analysis does not apply to the composed operator.
- [§4] §4 (theoretical analysis): the convergence guarantee is stated to motivate the sensitivity and scaling mechanisms, yet it is unclear whether the proof accounts for the bias potentially introduced by the CDF projection or the class-conditioned scaling; an explicit statement of the assumptions under which the guarantee holds after these transforms is required.
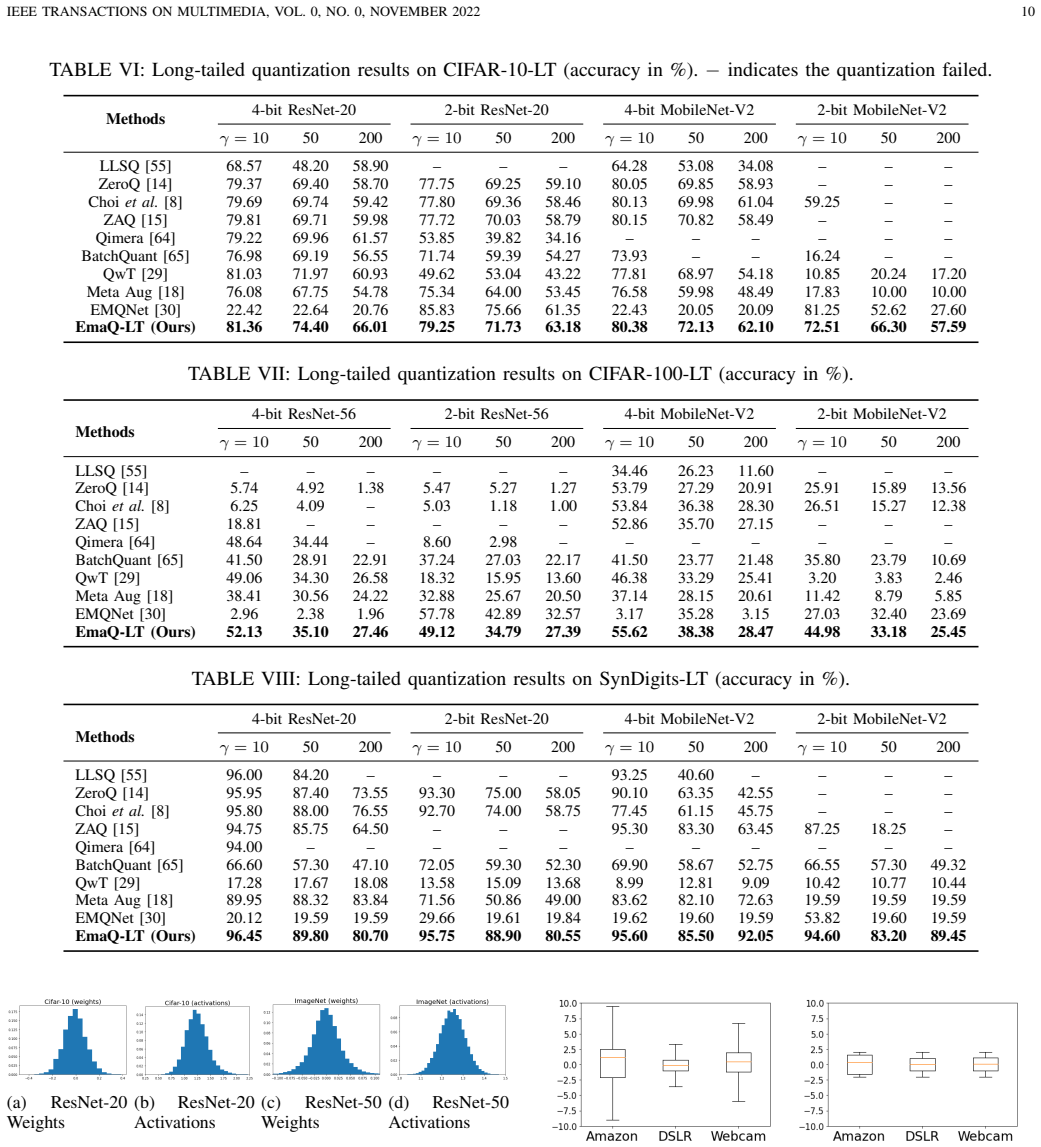
- [Table 2] Table 2 (multi-domain results): the reported gains for EmaQ over single-domain baselines lack error bars and details on the number of random seeds; without this, it is impossible to assess whether the improvement under domain shift is statistically reliable or sensitive to post-hoc hyper-parameter choices.
minor comments (2)
- [§3] Notation for the sensitivity metric (e.g., Eq. (X)) should be defined before its first use in the method section rather than introduced inline.
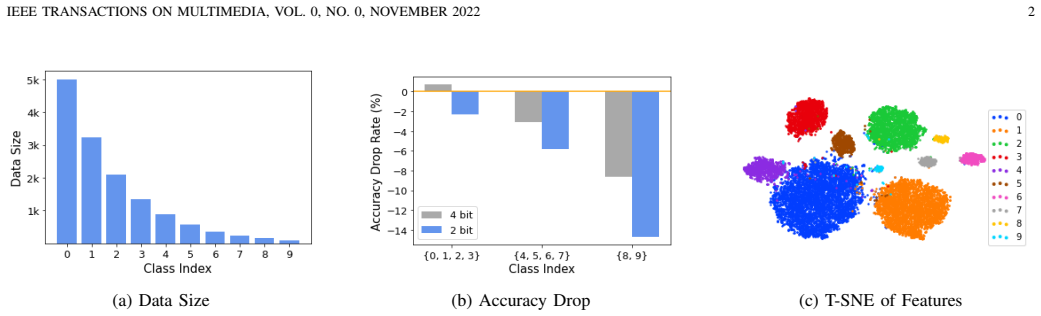
- [§5.2] The long-tailed benchmarks (SynDigits-LT, CIFAR-*-LT) should include a reference or explicit description of how the imbalance ratios were constructed to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (CDF-based projection): the manuscript must demonstrate that the per-feature monotonic CDF transform leaves the relative ordering and magnitudes of Hessian-based sensitivities (or activation ranges) unchanged across domains; otherwise the subsequent sensitivity-aware aggregation step operates on misaligned statistics and the convergence analysis does not apply to the composed operator.
Authors: We thank the referee for this observation. The per-feature CDF transform is strictly monotonic, which preserves the relative ordering of activation values within each feature. To address the concern regarding Hessian-based sensitivities, we will add a supporting argument and lemma in the revised §3.2 (and appendix) showing that, because the transform is applied uniformly after domain alignment, the relative magnitudes of per-feature sensitivities remain consistent across domains. This ensures the sensitivity-aware aggregation operates on aligned statistics. revision: yes
-
Referee: [§4] §4 (theoretical analysis): the convergence guarantee is stated to motivate the sensitivity and scaling mechanisms, yet it is unclear whether the proof accounts for the bias potentially introduced by the CDF projection or the class-conditioned scaling; an explicit statement of the assumptions under which the guarantee holds after these transforms is required.
Authors: We agree that the assumptions require explicit clarification. In the revised §4, we will update the theorem statement and proof sketch to list the assumptions under which the guarantee holds after the transforms: specifically, that the CDF projection is a strictly increasing continuous bijection and that the class-conditioned scaling factors are positive and bounded. Under these conditions, the bias is controlled and the contraction property used in the convergence analysis is preserved for the composed operator. revision: yes
-
Referee: [Table 2] Table 2 (multi-domain results): the reported gains for EmaQ over single-domain baselines lack error bars and details on the number of random seeds; without this, it is impossible to assess whether the improvement under domain shift is statistically reliable or sensitive to post-hoc hyper-parameter choices.
Authors: We acknowledge the importance of reporting statistical reliability. In the revised manuscript, we will update Table 2 to include error bars (standard deviations) computed over multiple random seeds and explicitly state the number of seeds used for the multi-domain experiments. This will allow readers to better evaluate the robustness of the reported gains. revision: yes
Circularity Check
No circularity: derivation self-contained against external benchmarks
full rationale
The provided abstract and excerpts describe CDF projection, sensitivity-aware aggregation, class-conditioned scaling, and convergence analyses without any quoted equations or self-citations that reduce a claimed prediction or uniqueness result to a fitted input or prior author work by construction. Theoretical guarantees are presented as independent motivation rather than tautological. No load-bearing self-citation chain or renaming of known results is exhibited in the given text. This matches the common honest finding of a self-contained paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of quantization methods for efficient neural network infer- ence,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network infer- ence,” inLow-Power Computer Vision. Chapman and Hall/CRC, 2022, pp. 291–326
2022
-
[2]
Quantization networks,
J. Yang, X. Shen, J. Xing, X. Tian, H. Li, B. Deng, J. Huang, and X.-s. Hua, “Quantization networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 7308– 7316
2019
-
[3]
Quantization of deep neural networks for accurate edge computing,
W. Chen, H. Qiu, J. Zhuang, C. Zhang, Y . Hu, Q. Lu, T. Wang, Y . Shi, M. Huang, and X. Xu, “Quantization of deep neural networks for accurate edge computing,”ACM Journal on Emerging Technologies in Computing Systems (JETC), vol. 17, no. 4, pp. 1–11, 2021
2021
-
[4]
Deep learning with low precision by half-wave gaussian quantization,
Z. Cai, X. He, J. Sun, and N. Vasconcelos, “Deep learning with low precision by half-wave gaussian quantization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5918–5926
2017
-
[5]
Learned step size quantization,
S. K. Esser, J. L. McKinstry, D. Bablani, R. Appuswamy, and D. S. Modha, “Learned step size quantization,” inInternational Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=rkgO66VKDS
2020
-
[6]
Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks,
Y . Li, X. Dong, and W. Wang, “Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks,” in International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=BkgXT24tDS
2020
-
[8]
Data-free network quanti- zation with adversarial knowledge distillation,
Y . Choi, J. Choi, M. El-Khamy, and J. Lee, “Data-free network quanti- zation with adversarial knowledge distillation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 710–711
2020
-
[9]
Generative zero- shot network quantization,
X. He, J. Lu, W. Xu, Q. Hu, P. Wang, and J. Cheng, “Generative zero- shot network quantization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3000–3011
2021
-
[11]
A study on real-time image processing applications with edge computing support for mobile devices,
G. P. Mattia and R. Beraldi, “A study on real-time image processing applications with edge computing support for mobile devices,” in2021 IEEE/ACM 25th International Symposium on Distributed Simulation and Real Time Applications (DS-RT). IEEE, 2021, pp. 1–7
2021
-
[12]
Color correction of the document owner’s photograph image during recognition on mobile device,
D. Polevoy, E. Panfilova, E. Ershov, and D. Nikolaev, “Color correction of the document owner’s photograph image during recognition on mobile device,” inThirteenth International Conference on Machine Vision, vol. 11605. SPIE, 2021, pp. 285–293
2021
-
[13]
Lote-animal: A long time-span dataset for endangered animal behavior understanding,
D. Liu, J. Hou, S. Huang, J. Liu, Y . He, B. Zheng, J. Ning, and J. Zhang, “Lote-animal: A long time-span dataset for endangered animal behavior understanding,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 064–20 075
2023
-
[14]
Zeroq: A novel zero shot quantization framework,
Y . Cai, Z. Yao, Z. Dong, A. Gholami, M. W. Mahoney, and K. Keutzer, “Zeroq: A novel zero shot quantization framework,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 169–13 178
2020
-
[15]
Zero-shot adversarial quantization,
Y . Liu, W. Zhang, and J. Wang, “Zero-shot adversarial quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1512–1521
2021
-
[16]
Aciq: Analytical clipping for integer quantization of neural networks,
R. Banner, Y . Nahshan, E. Hoffer, and D. Soudry, “Aciq: Analytical clipping for integer quantization of neural networks,” 2018
2018
-
[17]
Data-free quantization via pseudo-label filtering,
C. Fan, Z. Wang, D. Guo, and M. Wang, “Data-free quantization via pseudo-label filtering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5589–5598
2024
-
[18]
Metaaug: meta-data augmentation for post-training quan- tization,
C. Pham, A. D. Hoang, C. C. Nguyen, T. Le, D. Phung, G. Carneiro, and T.-T. Do, “Metaaug: meta-data augmentation for post-training quan- tization,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 236–252
2024
-
[19]
Genie: show me the data for quantization,
Y . Jeon, C. Lee, and H.-y. Kim, “Genie: show me the data for quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12 064–12 073
2023
-
[20]
Pd-quant: Post-training quantization based on prediction difference metric,
J. Liu, L. Niu, Z. Yuan, D. Yang, X. Wang, and W. Liu, “Pd-quant: Post-training quantization based on prediction difference metric,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 427–24 437
2023
-
[21]
I&s-vit: An inclusive & stable method for post-training vits quantization,
Y . Zhong, J. Hu, M. Lin, M. Chen, and R. Ji, “I&s-vit: An inclusive & stable method for post-training vits quantization,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[22]
Instance-aware group quantization for vision transformers,
J. Moon, D. Kim, J. Cheon, and B. Ham, “Instance-aware group quantization for vision transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 132–16 141
2024
-
[23]
Towards accu- rate post-training quantization for diffusion models,
C. Wang, Z. Wang, X. Xu, Y . Tang, J. Zhou, and J. Lu, “Towards accu- rate post-training quantization for diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 026–16 035
2024
-
[24]
Aphq- vit: Post-training quantization with average perturbation hessian based reconstruction for vision transformers,
Z. Wu, J. Zhang, J. Chen, J. Guo, D. Huang, and Y . Wang, “Aphq- vit: Post-training quantization with average perturbation hessian based reconstruction for vision transformers,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9686–9695
2025
-
[25]
Enhancing post-training quantization calibration through contrastive learning,
Y . Shang, G. Liu, R. R. Kompella, and Y . Yan, “Enhancing post-training quantization calibration through contrastive learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 921–15 930
2024
-
[26]
Magr: Weight magnitude reduction for enhancing post-training quantization,
A. Zhang, N. Wang, Y . Deng, X. Li, Z. Yang, and P. Yin, “Magr: Weight magnitude reduction for enhancing post-training quantization,”Advances in neural information processing systems, vol. 37, pp. 85 109–85 130, 2024
2024
-
[27]
Towards next-level post-training quantization of hyper-scale transform- ers,
J. Kim, C. Lee, E. Cho, K. Park, H.-y. Kim, J. Kim, and Y . Jeon, “Towards next-level post-training quantization of hyper-scale transform- ers,”Advances in Neural Information Processing Systems, vol. 37, pp. 94 292–94 326, 2024
2024
-
[28]
Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks,
Y . Li, X. Dong, and W. Wang, “Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks,” in IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 0, NO. 0, NOVEMBER 2022 13 International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=BkgXT24tDS
2022
-
[29]
Quantization without tears,
M. Fu, H. Yu, J. Shao, J. Zhou, K. Zhu, and J. Wu, “Quantization without tears,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 4462–4472
2025
-
[30]
Efficient multi-bit quantization network training via weight bias correction and bit- wise coreset sampling,
J. Kim, J. J. An, K. E. Jeon, and J. H. Ko, “Efficient multi-bit quantization network training via weight bias correction and bit- wise coreset sampling,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. [Online]. Available: https://openreview.net/forum?id=VBKgukQlRG
2026
-
[31]
Eq-net: Elastic quanti- zation neural networks,
K. Xu, L. Han, Y . Tian, S. Yang, and X. Zhang, “Eq-net: Elastic quanti- zation neural networks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 1505–1514
2023
-
[32]
Automatic joint structured pruning and quantization for efficient neural network training and compression,
X. Qu, D. Aponte, C. Banbury, D. P. Robinson, T. Ding, K. Koishida, I. Zharkov, and T. Chen, “Automatic joint structured pruning and quantization for efficient neural network training and compression,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 15 234–15 244
2025
-
[33]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavi- olette, M. March, and V . Lempitsky, “Domain-adversarial training of neural networks,”Journal of machine learning research, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[34]
Intraq: Learning synthetic images with intra-class heterogeneity for zero-shot network quantization,
Y . Zhong, M. Lin, G. Nan, J. Liu, B. Zhang, Y . Tian, and R. Ji, “Intraq: Learning synthetic images with intra-class heterogeneity for zero-shot network quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 339–12 348
2022
-
[35]
Towards better robust- ness against common corruptions for unsupervised domain adaptation,
Z. Gao, K. Huang, R. Zhang, D. Liu, and J. Ma, “Towards better robust- ness against common corruptions for unsupervised domain adaptation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 18 882–18 893
2023
-
[36]
Qt-dog: Quantization-aware training for domain generalization,
S. Javed, H. Le, and M. Salzmann, “Qt-dog: Quantization-aware training for domain generalization,”arXiv preprint arXiv:2410.06020, 2024
-
[37]
Gaqat: gradient-adaptive quantization-aware training for domain gen- eralization,
J. Jiang, Y . Meng, C. Tang, H. Yu, Q. Li, Z. Wang, and W. Zhu, “Gaqat: gradient-adaptive quantization-aware training for domain gen- eralization,”arXiv preprint arXiv:2412.05551, 2024
-
[38]
Alignq: Alignment quan- tization with admm-based correlation preservation,
T.-A. Chen, D.-N. Yang, and M.-S. Chen, “Alignq: Alignment quan- tization with admm-based correlation preservation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 538–12 547
2022
-
[39]
Large- scale long-tailed recognition in an open world,
Z. Liu, Z. Miao, X. Zhan, J. Wang, B. Gong, and S. X. Yu, “Large- scale long-tailed recognition in an open world,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2537–2546
2019
-
[40]
Deep long-tailed learning: A survey,
Y . Zhang, B. Kang, B. Hooi, S. Yan, and J. Feng, “Deep long-tailed learning: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[41]
Decoupling representation and classifier for long-tailed recognition,
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y . Kalantidis, “Decoupling representation and classifier for long-tailed recognition,”arXiv preprint arXiv:1910.09217, 2019
-
[42]
Dynamic curriculum learning for imbalanced data classification,
Y . Wang, W. Gan, J. Yang, W. Wu, and J. Yan, “Dynamic curriculum learning for imbalanced data classification,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5017– 5026
2019
-
[43]
Rethinking classifier re-training in long-tailed recognition: Label over-smooth can balance,
S. Sun, H. Lu, J. Li, Y . Xie, T. Li, X. Yang, L. Zhang, and J. Yan, “Rethinking classifier re-training in long-tailed recognition: Label over-smooth can balance,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=OeKp3AdiVO
2025
-
[44]
Ltgc: Long- tail recognition via leveraging llms-driven generated content,
Q. Zhao, Y . Dai, H. Li, W. Hu, F. Zhang, and J. Liu, “Ltgc: Long- tail recognition via leveraging llms-driven generated content,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 510–19 520
2024
-
[45]
Breaking long-tailed learning bottlenecks: A controllable paradigm with hypernetwork-generated diverse experts,
Z. Zhao, H. Wen, Z. Wang, P. Wang, F. Wang, S. Lai, Q. Zhang, and Y . Wang, “Breaking long-tailed learning bottlenecks: A controllable paradigm with hypernetwork-generated diverse experts,”Advances in Neural Information Processing Systems, vol. 37, pp. 7493–7520, 2024
2024
-
[46]
Disentangling label distribution for long-tailed visual recognition,
Y . Hong, S. Han, K. Choi, S. Seo, B. Kim, and B. Chang, “Disentangling label distribution for long-tailed visual recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6626–6636
2021
-
[47]
Overcoming forgetting catas- trophe in quantization-aware training,
T.-A. Chen, D.-N. Yang, and M.-S. Chen, “Overcoming forgetting catas- trophe in quantization-aware training,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 358–17 367
2023
-
[48]
Lightlt: a lightweight representation quantization framework for long-tail data,
H. Wang, R. Li, Z. Wang, X. Tang, D. Zhang, M. Cheng, B. Yin, J. Droppo, S. Wang, and J. Gao, “Lightlt: a lightweight representation quantization framework for long-tail data,” in2024 IEEE 40th Inter- national Conference on Data Engineering (ICDE). IEEE, 2024, pp. 1380–1393
2024
-
[49]
Metaquant: Learning to quantize by learning to penetrate non-differentiable quantization,
S. Chen, W. Wang, and S. J. Pan, “Metaquant: Learning to quantize by learning to penetrate non-differentiable quantization,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[50]
Adaptive proximal gradient meth- ods for structured neural networks,
J. Yun, A. C. Lozano, and E. Yang, “Adaptive proximal gradient meth- ods for structured neural networks,”Advances in Neural Information Processing Systems, vol. 34, pp. 24 365–24 378, 2021
2021
-
[51]
Shalev-Shwartz and S
S. Shalev-Shwartz and S. Ben-David,Understanding machine learning: From theory to algorithms. Cambridge university press, 2014
2014
-
[52]
Levene tests of homogeneity of variance for general block and treatment designs,
M. E. O’Neill and K. L. Mathews, “Levene tests of homogeneity of variance for general block and treatment designs,”Biometrics, vol. 58, no. 1, pp. 216–224, 2002
2002
-
[54]
A tutorial on the cross-entropy method,
P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y . Rubinstein, “A tutorial on the cross-entropy method,”Annals of operations research, vol. 134, pp. 19–67, 2005
2005
-
[55]
Linear symmetric quantization of neural networks for low-precision integer hardware,
X. Zhao, Y . Wang, X. Cai, C. Liu, and L. Zhang, “Linear symmetric quantization of neural networks for low-precision integer hardware,” in International Conference on Learning Representations, 2020
2020
-
[56]
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
S. Zhou, Y . Wu, Z. Ni, X. Zhou, H. Wen, and Y . Zou, “Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients,”arXiv preprint arXiv:1606.06160, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[57]
Improving neural network quantization without retraining using outlier channel splitting,
R. Zhao, Y . Hu, J. Dotzel, C. De Sa, and Z. Zhang, “Improving neural network quantization without retraining using outlier channel splitting,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 7543–7552
2019
-
[58]
Generative zero- shot network quantization,
X. He, J. Lu, W. Xu, Q. Hu, P. Wang, and J. Cheng, “Generative zero- shot network quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3000–3011
2021
-
[59]
Gener- ative low-bitwidth data free quantization,
S. Xu, H. Li, B. Zhuang, J. Liu, J. Cao, C. Liang, and M. Tan, “Gener- ative low-bitwidth data free quantization,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 1–17
2020
-
[60]
It’s all in the teacher: Zero-shot quantization brought closer to the teacher,
K. Choi, H. Y . Lee, D. Hong, J. Yu, N. Park, Y . Kim, and J. Lee, “It’s all in the teacher: Zero-shot quantization brought closer to the teacher,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8311–8321
2022
-
[61]
Rethinking data-free quan- tization as a zero-sum game,
B. Qian, Y . Wang, R. Hong, and M. Wang, “Rethinking data-free quan- tization as a zero-sum game,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 8, 2023, pp. 9489–9497
2023
-
[62]
Adaptive data-free quantization,
——, “Adaptive data-free quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7960–7968
2023
-
[63]
Texq: Zero- shot network quantization with texture feature distribution calibration,
X. Chen, Y . Wang, R. Yan, Y . Liu, T. Guan, and Y . He, “Texq: Zero- shot network quantization with texture feature distribution calibration,” Advances in Neural Information Processing Systems, vol. 36, pp. 274– 287, 2023
2023
-
[64]
Qimera: Data-free quantization with synthetic boundary supporting samples,
K. Choi, D. Hong, N. Park, Y . Kim, and J. Lee, “Qimera: Data-free quantization with synthetic boundary supporting samples,”Advances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[65]
Batchquant: Quantized- for-all architecture search with robust quantizer,
H. Bai, M. Cao, P. Huang, and J. Shan, “Batchquant: Quantized- for-all architecture search with robust quantizer,”Advances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[66]
SQuant: On-the-fly data-free quantization via diagonal hessian approximation,
C. Guo, Y . Qiu, J. Leng, X. Gao, C. Zhang, Y . Liu, F. Yang, Y . Zhu, and M. Guo, “SQuant: On-the-fly data-free quantization via diagonal hessian approximation,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=JXhROKNZzOc
2022
-
[67]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[68]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y . Ng, “Reading digits in natural images with unsupervised feature learning,” 2011
2011
-
[69]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International journal of computer vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[70]
Adapting visual category models to new domains,
K. Saenko, B. Kulis, M. Fritz, and T. Darrell, “Adapting visual category models to new domains,” inEuropean conference on computer vision. Springer, 2010, pp. 213–226
2010
-
[71]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 0, NO. 0, NOVEMBER 2022 14
1998
-
[72]
Unsupervised domain adaptation by back- propagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by back- propagation,” inInternational conference on machine learning. PMLR, 2015, pp. 1180–1189
2015
-
[73]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[74]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[75]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 4700–4708
2017
-
[76]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520
2018
-
[77]
Research in probability and statistics: Reflections and directions
J. M. Shaughnessy, “Research in probability and statistics: Reflections and directions.” 1992
1992
-
[78]
Up or down? adaptive rounding for post-training quantization,
M. Nagel, R. A. Amjad, M. Van Baalen, C. Louizos, and T. Blankevoort, “Up or down? adaptive rounding for post-training quantization,” in International Conference on Machine Learning. PMLR, 2020, pp. 7197–7206
2020
-
[79]
Rethinking the evaluation protocol of domain generalization,
H. Yu, X. Zhang, R. Xu, J. Liu, Y . He, and P. Cui, “Rethinking the evaluation protocol of domain generalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 897–21 908
2024
-
[80]
Learning frequency-adapted vision foundation model for domain generalized semantic segmentation,
Q. Bi, J. Yi, H. Zheng, H. Zhan, Y . Huang, W. Ji, Y . Li, and Y . Zheng, “Learning frequency-adapted vision foundation model for domain generalized semantic segmentation,”Advances in Neural Infor- mation Processing Systems, vol. 37, pp. 94 047–94 072, 2024
2024
-
[81]
Transferrable prototypical networks for unsupervised domain adaptation,
Y . Pan, T. Yao, Y . Li, Y . Wang, C.-W. Ngo, and T. Mei, “Transferrable prototypical networks for unsupervised domain adaptation,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 2239–2247
2019
-
[82]
Contrastively smoothed class alignment for unsupervised domain adaptation,
S. Dai, Y . Cheng, Y . Zhang, Z. Gan, J. Liu, and L. Carin, “Contrastively smoothed class alignment for unsupervised domain adaptation,” in Proceedings of the Asian conference on computer vision, 2020
2020
-
[83]
Joint domain alignment and class alignment method for cross-domain fault diagnosis of rotating machinery,
Y . Zhang, K. Yu, Z. Ren, and S. Zhou, “Joint domain alignment and class alignment method for cross-domain fault diagnosis of rotating machinery,”IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–12, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.