Reasoning or Memorization? Direction-Aware Diversity Exploration in LLM Reinforcement Learning
Pith reviewed 2026-06-27 13:37 UTC · model grok-4.3
The pith
DiRL extracts a reasoning-memorization direction from LLM representations to steer reinforcement learning exploration toward genuine reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
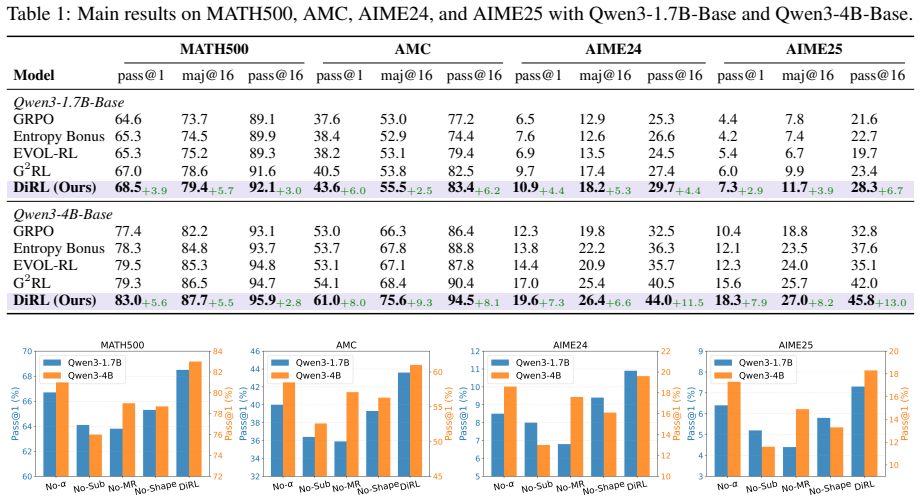
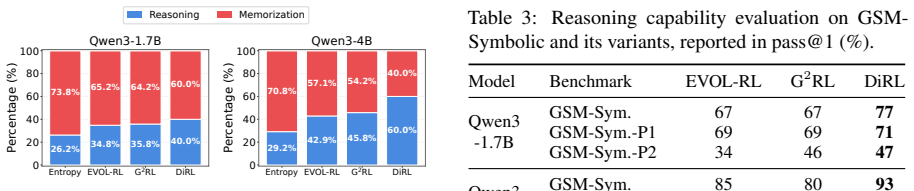
DiRL extracts an internal reasoning-memorization direction from model representations, constructs direction-weighted gradient features to characterize rollout updates, and shapes rewards to amplify reasoning-aligned exploration while suppressing memorization-aligned variations, integrating seamlessly into Group Relative Policy Optimization (GRPO) and producing significant improvements over existing exploration methods on mathematical and general reasoning benchmarks.
What carries the argument
The reasoning-memorization direction extracted from model representations, used to weight gradient features and shape rewards during policy updates.
If this is right
- Exploration in GRPO can be made selective rather than uniformly diverse by anchoring to the internal direction.
- Direction-weighted gradient features provide a practical signal for distinguishing reasoning trajectories from memorization ones during training.
- The method yields measurable performance lifts on both mathematical and general reasoning benchmarks relative to prior exploration baselines.
- Reward shaping that suppresses memorization-aligned updates integrates directly into standard policy optimization without requiring new architectures.
Where Pith is reading between the lines
- If the direction remains stable across training checkpoints, it could be reused to monitor whether later stages of RL drift back toward memorization.
- The same extraction technique might be tested on non-reasoning tasks such as instruction following to check whether analogous directions separate helpful variation from shortcut learning.
- Multi-direction extensions could be explored if different reasoning domains produce distinct axes in representation space.
Load-bearing premise
A single stable direction exists in the model's representations that genuinely separates reasoning processes from memorization patterns.
What would settle it
An ablation in which reward shaping along the extracted direction produces no larger gains in benchmark accuracy than unweighted diversity rewards, or in which the direction correlates more strongly with memorized-answer variation than with novel reasoning steps.
Figures



read the original abstract
Reinforcement learning has become a key paradigm for eliciting reasoning abilities in large language models, where exploration is crucial for discovering effective solution trajectories. Existing exploration methods typically encourage diversity in semantic or gradient spaces, without distinguishing what drives this diversity. A trajectory may appear novel because it follows a new reasoning process, or because it varies memorized patterns and shortcuts. Rewarding both cases equally may steer exploration toward memorization rather than genuine reasoning improvement. In this paper, we propose DiRL, a Direction-Aware Reinforcement Learning framework that anchors exploration to an internal reasoning-memorization direction of the policy. Specifically, DiRL extracts this direction from model representations, constructs direction-weighted gradient features to characterize rollout updates, and shapes rewards to amplify reasoning-aligned exploration while suppressing memorization-aligned variations. DiRL integrates seamlessly into standard Group Relative Policy Optimization (GRPO). Extensive experiments on mathematical and general reasoning benchmarks demonstrate the effectiveness of DiRL, showing significant improvements over various existing exploration methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiRL, a Direction-Aware Reinforcement Learning framework for LLMs. It extracts an internal reasoning-memorization direction from model representations, constructs direction-weighted gradient features to characterize rollout updates, and shapes rewards within standard GRPO to amplify reasoning-aligned exploration while suppressing memorization-aligned variations. Experiments on mathematical and general reasoning benchmarks are reported to show significant improvements over existing exploration methods.
Significance. If the extracted direction genuinely isolates reasoning processes from memorization (rather than surface proxies), DiRL could provide a targeted mechanism for improving exploration in LLM RL without reinforcing shortcuts. The seamless integration with GRPO and benchmark gains would then represent a practical advance in reasoning elicitation. The absence of methodological specifics, however, leaves the significance conditional on unverified assumptions about the direction's stability and specificity.
major comments (2)
- [Abstract] Abstract: the central claim that DiRL extracts a direction that 'genuinely separates reasoning processes from memorization patterns' rests on an extraction procedure (contrastive examples, method such as difference-of-means/PCA/probe, stability checks) that is not described; without this, it is impossible to evaluate whether the direction is load-bearing or merely re-labels length/entropy variation.
- [Method] Method description (as summarized): no validation is supplied that the direction remains stable across prompt distributions or that weighting updates along it changes reasoning depth rather than surface statistics; this directly undermines the claim that reward shaping preferentially improves reasoning over memorization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional methodological transparency is needed. We address the major comments point by point below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DiRL extracts a direction that 'genuinely separates reasoning processes from memorization patterns' rests on an extraction procedure (contrastive examples, method such as difference-of-means/PCA/probe, stability checks) that is not described; without this, it is impossible to evaluate whether the direction is load-bearing or merely re-labels length/entropy variation.
Authors: We agree that the abstract does not describe the extraction procedure in sufficient detail. In the revised manuscript we will expand the abstract to briefly specify the construction of contrastive reasoning versus memorization examples and the difference-of-means method used to obtain the direction, together with a short note on the stability checks that were performed. revision: yes
-
Referee: [Method] Method description (as summarized): no validation is supplied that the direction remains stable across prompt distributions or that weighting updates along it changes reasoning depth rather than surface statistics; this directly undermines the claim that reward shaping preferentially improves reasoning over memorization.
Authors: The referee correctly notes the absence of explicit validation. While the reported benchmark gains are consistent with the intended effect, the manuscript does not contain dedicated experiments measuring direction stability across prompt distributions or isolating reasoning depth from surface statistics such as length or entropy. We will add a new subsection with these analyses, including cross-prompt consistency metrics and appropriate controls. revision: yes
Circularity Check
No significant circularity; direction extraction treated as independent modeling step
full rationale
The paper's core proposal extracts a reasoning-memorization direction from model representations, builds direction-weighted gradient features, and shapes rewards within GRPO. This extraction and weighting are presented as an independent modeling choice rather than a quantity fitted to the target benchmark outcomes or reduced by construction to prior self-citations. No equations or procedures are described that would make the reported gains equivalent to re-labeling of inputs already present in the data or in the authors' prior work. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model hidden states contain a stable, extractable direction that separates reasoning trajectories from memorization trajectories.
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
The reasoning-memorization interplay in language models is mediated by a single direction , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[2]
arXiv preprint arXiv:2512.15687 , year=
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning , author=. arXiv preprint arXiv:2512.15687 , year=
-
[3]
Information Fusion , volume=
Exploration in deep reinforcement learning: A survey , author=. Information Fusion , volume=. 2022 , publisher=
2022
-
[4]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[5]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[7]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[8]
arXiv preprint arXiv:2509.15194 , year=
Evolving language models without labels: Majority drives selection, novelty promotes variation , author=. arXiv preprint arXiv:2509.15194 , year=
-
[9]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[10]
arXiv preprint arXiv:2509.06941 , year=
Outcome-based exploration for llm reasoning , author=. arXiv preprint arXiv:2509.06941 , year=
-
[11]
arXiv preprint arXiv:2509.02534 , year=
Jointly reinforcing diversity and quality in language model generations , author=. arXiv preprint arXiv:2509.02534 , year=
-
[12]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[15]
arXiv preprint arXiv:2311.03658 , year=
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
-
[16]
Advances in neural information processing systems , volume=
Faith and fate: Limits of transformers on compositionality , author=. Advances in neural information processing systems , volume=
-
[17]
arXiv preprint arXiv:2201.02177 , year=
Grokking: Generalization beyond overfitting on small algorithmic datasets , author=. arXiv preprint arXiv:2201.02177 , year=
-
[18]
arXiv preprint arXiv:2301.05217 , year=
Progress measures for grokking via mechanistic interpretability , author=. arXiv preprint arXiv:2301.05217 , year=
-
[19]
International Conference on Learning Representations , volume=
Linearity of relation decoding in transformer language models , author=. International Conference on Learning Representations , volume=
-
[20]
A is B” fail to learn “B is A
The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” , author=. International Conference on Learning Representations , volume=
-
[21]
International Conference on Learning Representations , volume=
Physics of language models: Part 2.1, grade-school math and the hidden reasoning process , author=. International Conference on Learning Representations , volume=
-
[22]
arXiv preprint arXiv:1909.08593 , year=
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
Pith/arXiv arXiv 1909
-
[23]
Machine learning , volume=
Near-optimal reinforcement learning in polynomial time , author=. Machine learning , volume=. 2002 , publisher=
2002
-
[24]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[25]
International Conference on Learning Representations , volume=
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models , author=. International Conference on Learning Representations , volume=
-
[26]
arXiv preprint arXiv:1912.09713 , year=
Measuring compositional generalization: A comprehensive method on realistic data , author=. arXiv preprint arXiv:1912.09713 , year=
arXiv 1912
-
[27]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Towards a mechanistic interpretation of multi-step reasoning capabilities of language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[28]
arXiv preprint arXiv:2211.00593 , year=
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=. arXiv preprint arXiv:2211.00593 , year=
-
[29]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[30]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[31]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[32]
arXiv preprint arXiv:2210.03057 , year=
Language models are multilingual chain-of-thought reasoners , author=. arXiv preprint arXiv:2210.03057 , year=
-
[33]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[34]
Advances in neural information processing systems , volume=
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.