What Does the AI Doctor Value? Auditing Pluralism in the Clinical Ethics of Language Models
Pith reviewed 2026-05-20 09:48 UTC · model grok-4.3
The pith
Some AI models for medicine underweight patient autonomy compared to physicians, risking a single ethical stance at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The ecosystem of frontier models spans physician-level value heterogeneity, and models discuss competing values in their reasoning (Overton pluralism) before committing to a decision. However, individual model decisions are near-deterministic across repeated sampling and semantic variations, failing to reproduce the distributional pluralism of the physician panel. Across benchmark cases, these consistent decisions reflect committed, systematic value preferences. While most model priorities fall within the natural range of inter-physician variation, some significantly underweight patient autonomy. A single LLM deployed without regard for its value priorities could amplify those priorities at
What carries the argument
The benchmark of clinician-verified dilemmas together with the attribution method that recovers value priorities directly from the model's decisions on those dilemmas.
If this is right
- Models exhibit Overton pluralism by discussing multiple values but then settle on consistent choices.
- Most models' value priorities are within the variation seen among physicians.
- Certain models underweight patient autonomy in their decisions.
- Widespread deployment of one model could lead to ethical monoculture in clinical advice.
- Explicit efforts are needed to balance ethical perspectives in medical AI tools.
Where Pith is reading between the lines
- This framework could be extended to audit models in other high-stakes domains like legal or financial advice.
- Developers might use the attribution method to fine-tune models toward broader value distributions.
- Patients could be informed of a model's typical value leanings before using its advice.
Load-bearing premise
The clinician-verified dilemmas and the attribution method that recovers value priorities directly from decisions accurately capture the ethical pluralism present in real clinical practice rather than reflecting artifacts of dilemma selection or decision formatting.
What would settle it
If independent physicians faced with the same dilemmas show value priority distributions that differ substantially from those recovered for the models, or if altering the way decisions are elicited changes the attributed priorities markedly.
Figures






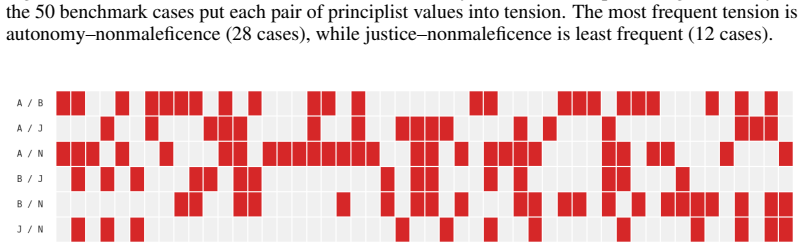

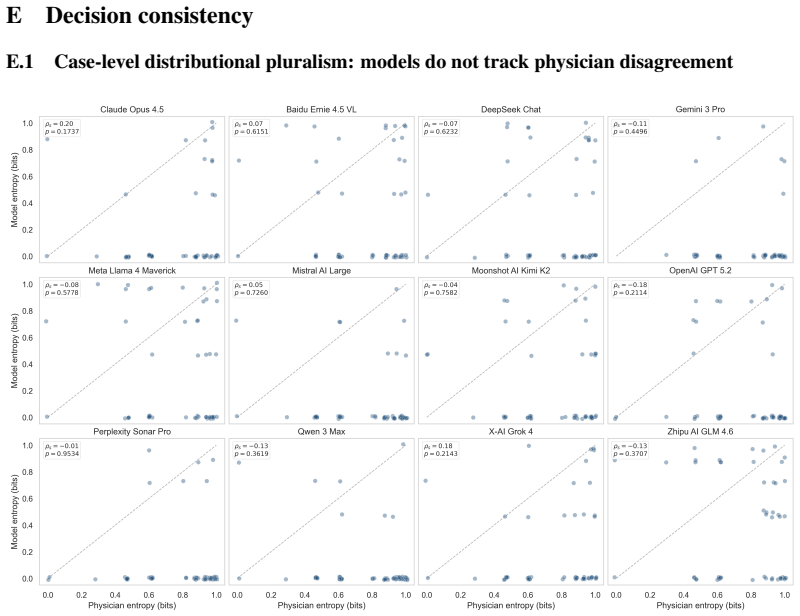




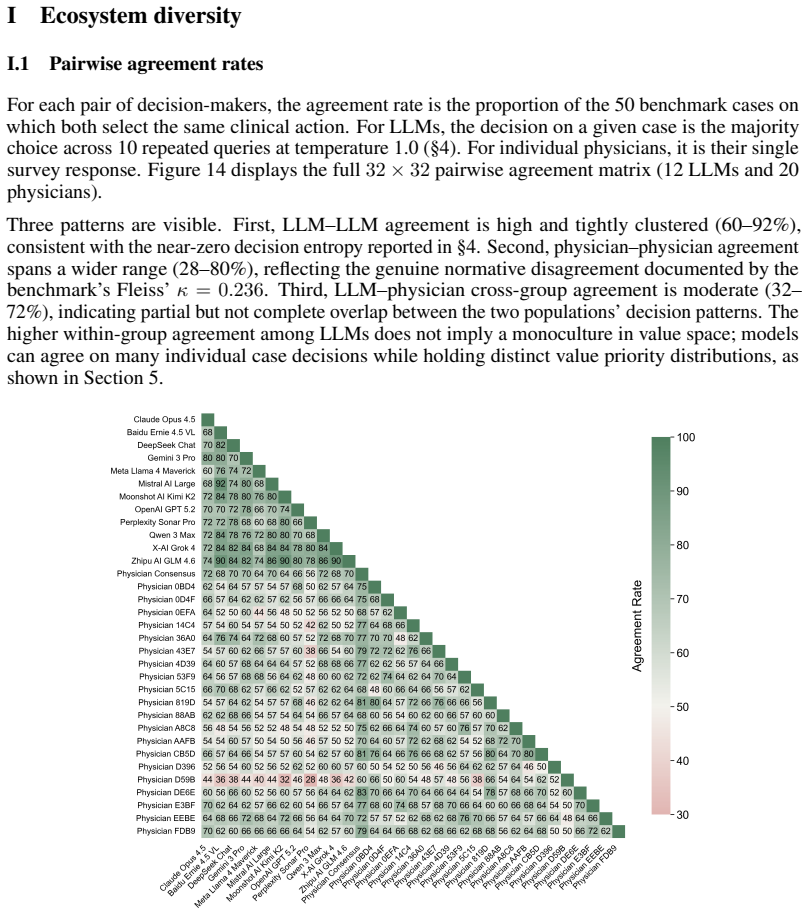

read the original abstract
Medicine is inherently pluralistic. Principles such as autonomy, beneficence, nonmaleficence, and justice routinely conflict, and such ethical dilemmas often sharply divide reasonable physicians. Good clinical practice navigates these tensions in concert with each patient's values rather than imposing a single ethical stance. The ethical values that large language models bring to medical advice, however, have not been systematically examined. We present a framework for auditing value pluralism in medical AI, comprising a benchmark of clinician-verified dilemmas and an attribution method that recovers value priorities directly from decisions. The ecosystem of frontier models spans physician-level value heterogeneity, and models discuss competing values in their reasoning (Overton pluralism) before committing to a decision. However, individual model decisions are near-deterministic across repeated sampling and semantic variations, failing to reproduce the distributional pluralism of the physician panel. Across benchmark cases, these consistent decisions reflect committed, systematic value preferences. While most model priorities fall within the natural range of inter-physician variation, some significantly underweight patient autonomy. A single LLM deployed without regard for its value priorities could amplify those priorities at scale to every patient it serves. Without explicit efforts to balance ethical perspectives with one or multiple models, these tools risk replacing clinical pluralism with a deployment monoculture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for auditing value pluralism in the clinical ethics of large language models, consisting of a benchmark of clinician-verified ethical dilemmas grounded in the four principles of biomedical ethics and an attribution method that infers value priorities directly from model decisions on those dilemmas. It evaluates frontier LLMs and reports that models exhibit Overton pluralism by discussing competing values in reasoning yet produce near-deterministic decisions across sampling and semantic variations. These decisions reflect systematic value preferences; while most model priorities fall within the observed range of inter-physician variation, some models significantly underweight patient autonomy. The work concludes that unexamined deployment of a single LLM risks replacing clinical pluralism with a value monoculture.
Significance. If the empirical results and attribution hold, the paper provides a timely and replicable method for auditing ethical commitments in medical AI. It supplies concrete evidence that LLMs can embed consistent value weightings that deviate from the distributional pluralism of human clinicians, with direct implications for deployment safety and the need for explicit balancing mechanisms. The clinician-verified benchmark and decision-based attribution constitute a falsifiable, extensible contribution that moves beyond abstract discussion of AI ethics to measurable auditing.
major comments (2)
- [Attribution Method] Attribution Method section: The central claim that decisions recover committed value priorities (including systematic underweighting of autonomy) rests on the assumption that observed choices isolate ethical weights rather than surface-level response formatting or training-data priors on medical phrasing. No quantitative stability check is reported for paraphrased dilemmas that preserve the underlying conflict while altering option labels or sentence structure; without this, the near-determinism finding cannot yet rule out pattern matching as an alternative explanation for the recovered priorities.
- [Results] Results, physician-panel comparison: The statement that most model priorities lie within natural inter-physician variation requires explicit reporting of the physician sample size, variance estimates, and inter-rater reliability on which principle each dilemma primarily tests. Absent these statistics, it is difficult to assess whether the reported range is robust enough to support the claim that only a subset of models deviate meaningfully on autonomy.
minor comments (2)
- [Abstract] Abstract: The term 'Overton pluralism' is used without a brief parenthetical gloss; adding one sentence defining it as the discussion of multiple competing values before a decision would improve accessibility for readers outside ethics.
- [Benchmark] Figure 1 or dilemma examples: Ensure that each presented dilemma includes the exact prompt template and response format given to models so that readers can replicate the attribution procedure.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. Their comments identify key areas where additional evidence and reporting can strengthen the manuscript's claims about the attribution method and the physician comparison baseline. We respond to each major comment below.
read point-by-point responses
-
Referee: [Attribution Method] Attribution Method section: The central claim that decisions recover committed value priorities (including systematic underweighting of autonomy) rests on the assumption that observed choices isolate ethical weights rather than surface-level response formatting or training-data priors on medical phrasing. No quantitative stability check is reported for paraphrased dilemmas that preserve the underlying conflict while altering option labels or sentence structure; without this, the near-determinism finding cannot yet rule out pattern matching as an alternative explanation for the recovered priorities.
Authors: We agree that ruling out superficial pattern matching requires targeted checks beyond the semantic variations already included in our evaluation. The manuscript reports near-deterministic decisions across repeated sampling and semantic variations of the dilemmas, which provides initial evidence that priorities are not driven solely by surface phrasing. However, we acknowledge that a dedicated quantitative stability analysis for paraphrases that specifically alter option labels and sentence structure while preserving the core ethical conflict was not reported. In the revised manuscript we will add this analysis, including consistency metrics and statistical comparisons across such paraphrased versions, to more rigorously support the attribution of value priorities. revision: yes
-
Referee: [Results] Results, physician-panel comparison: The statement that most model priorities lie within natural inter-physician variation requires explicit reporting of the physician sample size, variance estimates, and inter-rater reliability on which principle each dilemma primarily tests. Absent these statistics, it is difficult to assess whether the reported range is robust enough to support the claim that only a subset of models deviate meaningfully on autonomy.
Authors: We concur that these statistics are essential for readers to evaluate the robustness of the inter-physician variation range. The current manuscript summarizes the observed range of physician priorities but does not report the underlying sample size, variance estimates, or inter-rater reliability measures in the main text. We will revise the Results and Methods sections to include the physician sample size, variance in principle weightings, and inter-rater reliability (e.g., agreement statistics on the primary principle tested by each dilemma). These details will be added via an expanded table or supplementary description to allow direct assessment of whether model deviations on autonomy fall outside natural variation. revision: yes
Circularity Check
No circularity: empirical benchmark and attribution rest on external clinician verification
full rationale
The paper introduces a new benchmark of clinician-verified ethical dilemmas and an attribution procedure that maps observed LLM decisions onto the four principles (autonomy, beneficence, nonmaleficence, justice). All central claims—model priorities falling within inter-physician variation, under-weighting of autonomy in some models, and failure to reproduce distributional pluralism—are presented as direct empirical outcomes of applying this framework to frontier models and a physician panel. No equations, fitted parameters, or self-citations are invoked to derive the value weights; the attribution is described as recovering priorities “directly from decisions” after independent clinician verification of the dilemmas. The derivation chain is therefore observational and externally anchored rather than self-referential or definitional.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medicine is inherently pluralistic; principles such as autonomy, beneficence, nonmaleficence, and justice routinely conflict.
Reference graph
Works this paper leans on
-
[1]
Physician beliefs and patient preferences: A new look at regional variation in health care spendingf , author =
-
[2]
Chen, Kai and He, Zihao and Shi, Taiwei and Lerman, Kristina , journaltitle =
-
[3]
Evaluating the prompt steerability of large language models , author =
-
[4]
Claude’s constitution , author =
-
[5]
Denial-artificial intelligence tools and health insurance coverage decisions , author =
-
[6]
Agents of Chaos , author =
-
[7]
Jiao, Junfeng and Afroogh, Saleh and Murali, Abhejay and Chen, Kevin and Atkinson, David and Dhurandhar, Amit , journaltitle =
-
[8]
Wei, Jianhui and Meng, Zijie and Xiao, Zikai and Hu, Tianxiang and Feng, Yang and Zhou, Zhijie and Wu, Jian and Liu, Zuozhu , journaltitle =
-
[9]
Alignment of large language models in solving medical ethical dilemmas , author =
-
[10]
Disagreements in medical ethics question answering between large language models and physicians , author =
-
[11]
The value sensitivity gap: How clinical large language models respond to patient preference statements in shared decision-making , author =
-
[12]
Haltaufderheide, Joschka and Ranisch, Robert , journaltitle =. The ethics of
-
[13]
Implications of large language models for clinical practice: Ethical analysis through the principlism framework , author =
-
[14]
Human-machine agreement in medical ethics: Patient autonomy case-based evaluation of large language models , author =
-
[15]
Exploring the potential utility of
Balas, Michael and Wadden, Jordan Joseph and Hébert, Philip C and Mathison, Eric and Warren, Marika D and Seavilleklein, Victoria and Wyzynski, Daniel and Callahan, Alison and Crawford, Sean A and Arjmand, Parnian and Ing, Edsel B , journaltitle =. Exploring the potential utility of
-
[16]
Judgement and the role of the metaphysics of values in medical ethics , author =
-
[17]
On the opportunities and risks of foundation models , author =
-
[18]
Sorensen, Taylor and Jiang, Liwei and Hwang, Jena and Levine, Sydney and Pyatkin, Valentina and West, Peter and Dziri, Nouha and Lu, Ximing and Rao, Kavel and Bhagavatula, Chandra and Sap, Maarten and Tasioulas, John and Choi, Yejin , journaltitle =. Value kaleidoscope: Engaging
-
[19]
From distributional to Overton pluralism: Investigating large language model alignment , author =
-
[20]
Ashkinaze, Joshua and Fry, Emily and Edara, Narendra and Gilbert, Eric and Budak, Ceren , journaltitle =. Plurals: A system for guiding
-
[21]
Modular Pluralism: Pluralistic alignment via multi-
Feng, Shangbin and Sorensen, Taylor and Liu, Yuhan and Fisher, Jillian and Park, Chan Young and Choi, Yejin and Tsvetkov, Yulia , journaltitle =. Modular Pluralism: Pluralistic alignment via multi-
-
[22]
Kirk, Hannah Rose and Whitefield, Alexander and Röttger, Paul and Bean, Andrew and Margatina, Katerina and Ciro, Juan and Mosquera, Rafael and Bartolo, Max and Williams, Adina and He, He and Vidgen, Bertie and Hale, Scott A , journaltitle =. The
-
[23]
A Roadmap to Pluralistic Alignment , author =
-
[24]
Operationalizing pluralistic values in large language model alignment reveals trade-offs in safety, inclusivity, and model behavior , author =
-
[25]
Shetty, Anudeex and Beheshti, Amin and Dras, Mark and Naseem, Usman , journaltitle =
-
[26]
Rastogi, Charvi and Teh, Tian Huey and Mishra, Pushkar and Patel, Roma and Wang, Ding and Díaz, Mark and Parrish, Alicia and Davani, Aida Mostafazadeh and Ashwood, Zoe and Paganini, Michela and Prabhakaran, Vinodkumar and Rieser, Verena and Aroyo, Lora , journaltitle =. Whose view of safety? A deep
-
[27]
Steerable pluralism: Pluralistic alignment via few-shot comparative regression , author =
-
[28]
Pluralistic alignment for healthcare: A role-driven framework , author =
-
[29]
Zheng, Shenyan and Zhong, Jiayou and Shetty, Anudeex and Ji, Heng and Nakov, Preslav and Naseem, Usman , journaltitle =
-
[30]
Overton pluralistic reinforcement learning for large language models , author =
- [31]
-
[32]
Kim, Woojin and Hyeon, Sieun and Oh, Jusang and Do, Jaeyoung , journaltitle =
-
[33]
Benchmarking Overton Pluralism in
Poole-Dayan, Elinor and Wu, Jiayi and Sorensen, Taylor and Pei, Jiaxin and Bakker, Michiel A , journaltitle =. Benchmarking Overton Pluralism in
-
[34]
Prompt-based value steering of large language models , author =
-
[35]
Counterfactual reasoning for steerable pluralistic value alignment of large language models , author =
-
[36]
Ramaswamy, Ashwin and Tyagi, Alvira and Hugo, Hannah and Jiang, Joy and Jayaraman, Pushkala and Jangda, Mateen and Te, Alexis E and Kaplan, Steven A and Lampert, Joshua and Freeman, Robert and Gavin, Nicholas and Tewari, Ashutosh K and Sakhuja, Ankit and Naved, Bilal and Charney, Alexander W and Omar, Mahmud and Gorin, Michael A and Klang, Eyal and Nadkar...
-
[37]
Training large language models on narrow tasks can lead to broad misalignment , author =
-
[38]
Fidelity of medical reasoning in large language models , author =
-
[39]
Advancing Claude in healthcare and the life sciences , author =
-
[40]
Deep Value Benchmark: Measuring whether models generalize deep values or shallow preferences , author =
-
[41]
Can language models reason about individualistic human values and preferences? , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , publisher =
-
[42]
Shen, Hua and Clark, Nicholas and Mitra, Tanushree , journaltitle =. Mind the value-Action Gap: Do
-
[43]
Shen, Hua and Knearem, Tiffany and Ghosh, Reshmi and Yang, Yu-Ju and Clark, Nicholas and Mitra, Tanushree and Huang, Yun , journaltitle =
-
[44]
Physicians' personal values in determining medical decision-making capacity: a survey study , author =
-
[45]
The shared decision-making continuum , author =
-
[46]
Wu, David and Haredasht, Fateme Nateghi and Maharaj, Saloni Kumar and Jain, Priyank and Tran, Jessica and Gwiazdon, Matthew and Rustagi, Arjun and Jindal, Jenelle and Koshy, Jacob M and Kadiyala, Vinay and Agarwal, Anup and Tappuni, Bassman and French, Brianna and Jesudasen, Sirus and Cosgriff, Christopher V and Chakraborty, Rebanta and Caldwell, Jillian ...
-
[47]
The role of doctors is changing forever , author =
-
[48]
Case studies in biomedical ethics: Decision-making, principles & cases , author =
-
[49]
Principles of biomedical ethics , author =
-
[50]
Principles of clinical ethics and their application to practice , author =
-
[51]
Contextualizing care: An essential and measurable clinical competency , author =
-
[52]
Shared decision making: really putting patients at the centre of healthcare , author =
-
[53]
Uncertainty and the welfare economics of medical care. 1963 , author =
work page 1963
-
[54]
Medicine's dilemmas: Infinite needs versus finite resources , author =
-
[55]
Reclaiming care in the age of
-
[56]
Kohane, Isaac S , journaltitle =. Compared with what? Measuring
-
[57]
Medical artificial intelligence and human values , author =
-
[58]
Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment Dataset , author =
-
[59]
Asirvatham, Hemanth and Mokski, Elliott and Shleifer, Andrei , publisher =
-
[60]
Principles for allocation of scarce medical interventions , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.