Spatial-Temporal Decoupled Reference Conditioning for Identity-Preserving Text-to-Video Generation
Pith reviewed 2026-06-28 15:23 UTC · model grok-4.3
The pith
ST-DRC decouples spatial and temporal reference signals so identity details reach video generation through attention rather than pixel copying.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
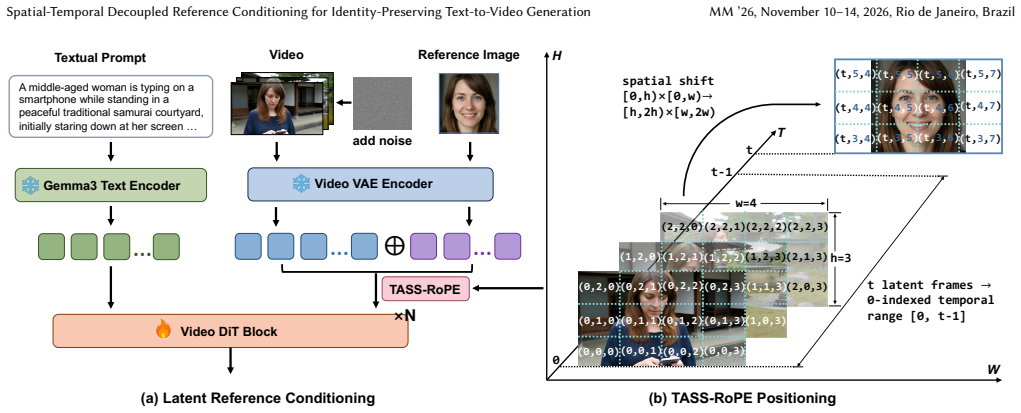
By performing latent in-context feature injection and introducing TASS-RoPE to place reference tokens near the video sequence in time but shifted in space, the model allows reference information to flow through spatio-temporal attention while suppressing pixel-level copy-paste shortcuts; combining this with appearance-invariant reference augmentation and face-guided identity objectives strengthens identity preservation under the diffusion training process.
What carries the argument
TASS-RoPE, a Temporal-Adjacent Spatial-Shifted RoPE scheme that positions reference tokens temporally adjacent yet spatially offset to route identity signals through attention.
If this is right
- Identity preservation improves without requiring extra adapter modules.
- Prompt alignment and temporal consistency remain high alongside identity fidelity.
- Three-stream classifier-free guidance allows independent control of text and reference strength at inference.
- The approach works as a lightweight addition to an existing video diffusion backbone.
Where Pith is reading between the lines
- The same latent concatenation plus shifted positional encoding could be tested on non-human reference subjects such as objects or scenes.
- The decoupling might reduce the need for heavy identity-specific fine-tuning in other generative video tasks.
- Extending the spatial shift distance could be explored to handle longer reference-to-video time gaps.
Load-bearing premise
Spatial shifting of reference tokens in the positional encoding prevents direct pixel copying while still permitting useful identity information to propagate through attention.
What would settle it
Generating videos after removing the spatial shift component of TASS-RoPE and measuring whether copy-paste artifacts increase or identity fidelity drops.
Figures

read the original abstract
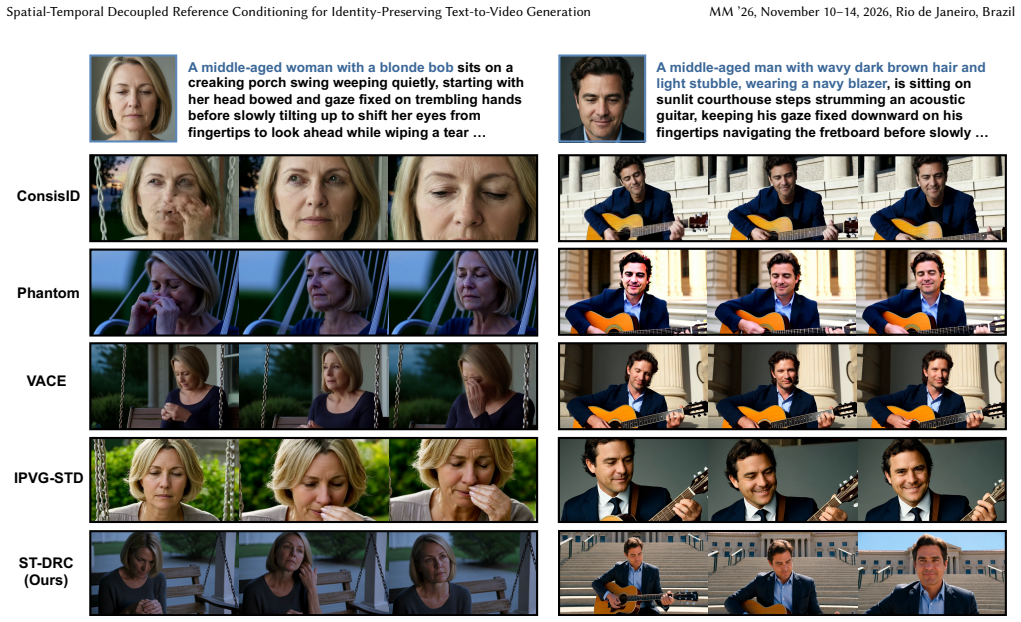
Identity-preserving video generation (IPVG) aims to synthesize high-fidelity videos that follow text prompts while faithfully preserving a reference identity. Despite recent progress, existing IPVG methods still struggle to balance high-level semantic control and low-level identity fidelity. To bridge this gap, we propose ST-DRC, an effective Spatial-Temporal Decoupled Reference Conditioning framework for identity-preserving text-to-video generation. At the framework level, ST-DRC performs latent in-context feature injection by encoding the reference image with the video VAE and concatenating it with noisy video latents, enabling rich low-level identity details to be accessed without additional adapters. To separate identity-aware reference retrieval from appearance copying, we introduce TASS-RoPE, a Temporal-Adjacent Spatial-Shifted RoPE scheme that places reference tokens near the video sequence in time but shifts them in space, allowing reference information to flow through spatio-temporal attention while suppressing pixel-level copy-paste shortcuts. To further prevent shortcut learning and strengthen the otherwise diluted identity supervision in the diffusion objective, we combine appearance-invariant reference augmentation with face-guided identity objectives, encouraging the model to preserve identity under variations in color, pose, and layout. At inference time, we introduce a three-stream reference classifier-free guidance strategy that independently controls text adherence and reference fidelity. Experiments demonstrate that ST-DRC achieves strong identity preservation, prompt alignment, temporal consistency, and video quality with a lightweight design built on LTX-2.3. Our method ranks among the top submissions in the facial identity-preserving video generation track, validating the effectiveness of spatial-temporal decoupled reference conditioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ST-DRC, a Spatial-Temporal Decoupled Reference Conditioning framework for identity-preserving text-to-video generation. It encodes a reference image via the video VAE and concatenates it with noisy video latents for in-context injection; introduces TASS-RoPE (Temporal-Adjacent Spatial-Shifted RoPE) to place reference tokens temporally adjacent but spatially shifted so that spatio-temporal attention carries high-level identity semantics while blocking low-level copy-paste; adds appearance-invariant augmentations and face-guided identity losses; and uses three-stream classifier-free guidance at inference. The method is built on LTX-2.3 and is reported to achieve strong identity preservation, prompt alignment, temporal consistency and video quality, ranking among the top entries in a facial identity-preserving video generation track.
Significance. If the experimental claims hold and the mechanistic assumptions of TASS-RoPE are validated, the work would supply a lightweight, adapter-free approach to balancing semantic control and low-level fidelity in conditional video diffusion. The spatial-temporal decoupling idea could transfer to other reference-conditioned generation settings. The manuscript does not supply machine-checked proofs, parameter-free derivations or open reproducible code, so its primary contribution remains empirical.
major comments (2)
- [Abstract, §3] Abstract and §3: the central mechanistic claim that TASS-RoPE 'suppresses pixel-level copy-paste shortcuts' by spatial shifting while still permitting semantic flow is asserted without supporting evidence. No attention-map visualizations, no isolated ablation that removes only the spatial-shift component, and no analysis of VAE latent correlation distances are provided to show that the chosen shift distance disrupts exact token alignment more than semantic retrieval.
- [Abstract, §4–5] Abstract (and presumably §4–5): the claim that 'ST-DRC achieves strong identity preservation, prompt alignment, temporal consistency, and video quality' and 'ranks among the top submissions' is stated without any quantitative metrics, baselines, ablation tables, or error analysis. This prevents evaluation of the magnitude of improvement or the contribution of each proposed component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to strengthen the mechanistic evidence and experimental reporting.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: the central mechanistic claim that TASS-RoPE 'suppresses pixel-level copy-paste shortcuts' by spatial shifting while still permitting semantic flow is asserted without supporting evidence. No attention-map visualizations, no isolated ablation that removes only the spatial-shift component, and no analysis of VAE latent correlation distances are provided to show that the chosen shift distance disrupts exact token alignment more than semantic retrieval.
Authors: We agree that direct supporting evidence for the TASS-RoPE mechanism is currently missing from the manuscript. In the revision we will add (i) attention-map visualizations comparing reference-to-video attention with and without the spatial shift, (ii) an isolated ablation that removes only the spatial-shift component while keeping temporal adjacency, and (iii) quantitative analysis of VAE latent correlation distances at varying shift offsets. These additions will be placed in a new subsection of §3. revision: yes
-
Referee: [Abstract, §4–5] Abstract (and presumably §4–5): the claim that 'ST-DRC achieves strong identity preservation, prompt alignment, temporal consistency, and video quality' and 'ranks among the top submissions' is stated without any quantitative metrics, baselines, ablation tables, or error analysis. This prevents evaluation of the magnitude of improvement or the contribution of each proposed component.
Authors: We acknowledge that the current manuscript version relies primarily on qualitative results and the competition ranking without accompanying quantitative tables. In the revised version we will expand §4 and §5 with (i) numerical metrics for identity preservation (e.g., ArcFace cosine similarity), prompt alignment (CLIP text-video scores), temporal consistency (e.g., frame-wise optical flow consistency), and perceptual quality, (ii) comparisons against relevant baselines, (iii) component-wise ablation tables, and (iv) error analysis across prompt categories. These tables will directly support the claims made in the abstract. revision: yes
Circularity Check
No significant circularity; empirical architectural proposal
full rationale
The paper proposes ST-DRC and TASS-RoPE as an architectural framework for identity-preserving video generation, validated through experiments on LTX-2.3. No mathematical derivations, equations, parameter fittings, or self-referential definitions are present in the abstract or described claims. The central mechanism (spatial shift in RoPE) is an ansatz justified by design intent and empirical results rather than reducing to prior inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Encoding the reference image with the video VAE and concatenating it with noisy video latents enables rich low-level identity details to be accessed without additional adapters.
Reference graph
Works this paper leans on
- [1]
-
[2]
Hila Chefer, Shiran Zada, Roni Paiss, Ariel Ephrat, Omer Tov, Michael Rubinstein, Lior Wolf, Tali Dekel, Tomer Michaeli, and Inbar Mosseri. 2024. Still-moving: Customized video generation without customized video data.ACM Transactions on Graphics (TOG)43, 6 (2024), 1–11
2024
-
[3]
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. 2025. Skyreels- v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Hong Chen, Xin Wang, Guanning Zeng, Yipeng Zhang, Yuwei Zhou, Feilin Han, Yaofei Wu, and Wenwu Zhu. 2025. Videodreamer: Customized multi-subject text- to-video generation with disen-mix finetuning on language-video foundation models.IEEE Transactions on Multimedia(2025)
2025
- [5]
- [6]
-
[7]
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Yuwei Fang, Kwot Sin Lee, Ivan Skorokhodov, Kfir Aberman, Jun-Yan Zhu, Ming-Hsuan Yang, and Sergey Tulyakov. 2025. Multi-subject open-set personalization in video generation. In Proceedings of the Computer Vision and Pattern Recognition Conference. 6099–6110
2025
-
[8]
Yuheng Chen, Qingdong He, Teng Hu, Yuji Wang, Yabiao Wang, Lizhuang Ma, and Jiangning Zhang. 2026. Omni-Customizer: End-to-End MultiModal Cus- tomization for Joint Audio-Video Generation.arXiv preprint arXiv:2605.17488 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [9]
-
[10]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4690–4699
2019
-
[11]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first international conference on machine learning
2024
- [12]
-
[13]
Jiayi Gao, Changcheng Hua, Qingchao Chen, Yuxin Peng, and Yang Liu. 2025. Identity-Preserving Text-to-Video Generation via Training-Free Prompt, Image, and Guidance Enhancement. InProceedings of the 33rd ACM International Confer- ence on Multimedia. 13751–13757
2025
-
[14]
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. 2026. LTX-2: Efficient Joint Audio-Visual Foundation Model. arXiv preprint arXiv:2601.03233(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Junjie He, Yifeng Geng, and Liefeng Bo. 2025. Uniportrait: A unified frame- work for identity-preserving single-and multi-human image personalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14399– 14408
2025
- [16]
-
[17]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, and Liefeng Bo. 2025. Animate anyone 2: High-fidelity character image animation with environment affordance. InProceedings of the IEEE/CVF International Conference on Computer Vision. 10207–10217
2025
- [19]
- [20]
-
[21]
Teng Hu, Zhentao Yu, Zhengguang Zhou, Jiangning Zhang, Yuan Zhou, Qinglin Lu, and Ran Yi. 2026. PolyVivid: Vivid Multi-Subject Video Generation with Cross-Modal Interaction and Enhancement.Advances in Neural Information Processing Systems38 (2026), 49394–49420
2026
-
[22]
Teng Hu, Jiangning Zhang, Zihan Su, and Ran Yi. 2026. UltraGen: High-Resolution Video Generation with Hierarchical Attention. InProceedings of the AAAI Con- ference on Artificial Intelligence, Vol. 40. 4923–4931
2026
-
[23]
Chi-Pin Huang, Yen-Siang Wu, Hung-Kai Chung, Kai-Po Chang, Fu-En Yang, and Yu-Chiang Frank Wang. 2025. Videomage: Multi-subject and motion customiza- tion of text-to-video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17603–17612
2025
-
[24]
Yuge Huang, Yuhan Wang, Ying Tai, Xiaoming Liu, Pengcheng Shen, Shaoxin Li, Jilin Li, and Feiyue Huang. 2020. Curricularface: adaptive curriculum learning loss for deep face recognition. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5901–5910
2020
- [25]
-
[26]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuan- han Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. 2024. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21807– 21818
2024
-
[27]
InsightFace Contributors. 2023. InsightFace: 2D and 3D Face Analysis Project. https://github.com/deepinsight/insightface
2023
-
[28]
Yuming Jiang, Tianxing Wu, Shuai Yang, Chenyang Si, Dahua Lin, Yu Qiao, Chen Change Loy, and Ziwei Liu. 2024. Videobooth: Diffusion-based video generation with image prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6689–6700
2024
-
[29]
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu
-
[30]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision. 17191–17202
-
[31]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision. 5148–5157
2021
-
[32]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. 2024. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
LAION-AI. 2022. LAION-Aesthetics Predictor. https://github.com/LAION-AI/ aesthetic-predictor. A linear estimator on top of CLIP for predicting image aesthetic quality
2022
- [34]
-
[35]
Zhen Li, Zuo-Liang Zhu, Ling-Hao Han, Qibin Hou, Chun-Le Guo, and Ming- Ming Cheng. 2023. Amt: All-pairs multi-field transforms for efficient frame interpolation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9801–9810
2023
-
[36]
Feng Liang, Haoyu Ma, Zecheng He, Tingbo Hou, Ji Hou, Kunpeng Li, Xiaoliang Dai, Felix Juefei-Xu, Samaneh Azadi, Animesh Sinha, et al. 2025. Movie weaver: Tuning-free multi-concept video personalization with anchored prompts. In Proceedings of the Computer Vision and Pattern Recognition Conference. 13146– 13156
2025
-
[37]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[38]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, and Xinglong Wu. 2025. Phantom: Subject-consistent video generation via cross-modal alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14951–14961
2025
-
[40]
Xingchao Liu, Chengyue Gong, and Qiang Liu. 2022. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Yexin Liu, Manyuan Zhang, Yueze Wang, Hongyu Li, Dian Zheng, Weiming Zhang, Changsheng Lu, Xunliang Cai, Yan Feng, Peng Pei, et al. 2025. OpenSub- ject: Leveraging Video-Derived Identity and Diversity Priors for Subject-driven Image Generation and Manipulation.arXiv preprint arXiv:2512.08294(2025)
-
[42]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Chetwin Low, Weimin Wang, and Calder Katyal. 2025. Ovi: Twin backbone cross-modal fusion for audio-video generation.arXiv preprint arXiv:2510.01284 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
Xiangyu Meng, Zixian Zhang, Zhenghao Zhang, Junchao Liao, Long Qin, and Weizhi Wang. 2025. Identity-grpo: Optimizing multi-human identity-preserving video generation via reinforcement learning.arXiv preprint arXiv:2510.14256 MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Chen et al. (2025)
-
[46]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[47]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[48]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22500–22510
2023
- [49]
-
[50]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
2024
- [51]
-
[52]
Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision. Springer, 402–419
2020
-
[53]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[54]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Yuji Wang, Moran Li, Xiaobin Hu, Ran Yi, Jiangning Zhang, Han Feng, Weijian Cao, Yabiao Wang, Chengjie Wang, and Lizhuang Ma. 2025. Identity-preserving text-to-video generation guided by simple yet effective spatial-temporal decou- pled representations. InProceedings of the 33rd ACM International Conference on Multimedia. 13743–13750
2025
-
[56]
Zhao Wang, Aoxue Li, Lingting Zhu, Yong Guo, Qi Dou, and Zhenguo Li. 2026. Customvideo: Customizing text-to-video generation with multiple subjects.IEEE Transactions on Multimedia(2026)
2026
- [57]
-
[58]
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhiheng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, and Hongming Shan. 2024. Dreamvideo: Composing your dream videos with customized subject and motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6537–6549
2024
-
[59]
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al . 2025. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Tao Wu, Yong Zhang, Xintao Wang, Xianpan Zhou, Guangcong Zheng, Zhongang Qi, Ying Shan, and Xi Li. 2025. Customcrafter: Customized video generation with preserving motion and concept composition abilities. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8469–8477
2025
-
[61]
Jiahao Xu, Jianjie Luo, and Zhenguo Yang. 2025. Improving Identity Preservation in Video Generation with Multi-Branch Models. InProceedings of the 33rd ACM International Conference on Multimedia. 13758–13765
2025
- [62]
-
[63]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al . 2025. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. InThe Thirteenth International Conference on Learning Representations
2025
-
[64]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. 2023. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Shenghai Yuan, Xianyi He, Yufan Deng, Yang Ye, Jinfa Huang, Bin Lin, Chongyang Ma, Jiebo Luo, and Li Yuan. 2025. OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2025
-
[66]
Shenghai Yuan, Jinfa Huang, Xianyi He, Yunyang Ge, Yujun Shi, Liuhan Chen, Jiebo Luo, and Li Yuan. 2025. Identity-preserving text-to-video generation by frequency decomposition. InProceedings of the Computer Vision and Pattern Recognition Conference. 12978–12988
2025
- [67]
-
[68]
Yuechen Zhang, Yaoyang Liu, Bin Xia, Bohao Peng, Zexin Yan, Eric Lo, and Jiaya Jia. 2025. Magicmirror: Id-preserved video generation in video diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14464–14474
2025
-
[69]
Yiheng Zhang, Zhaofan Qiu, Qi Cai, Yehao Li, Fuchen Long, Yingwei Pan, Ting Yao, and Tao Mei. 2025. Identity-Preserving Video Generation Challenge. In Proceedings of the 33rd ACM International Conference on Multimedia. 13737–13742
2025
- [70]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.