Is This AI? Longitudinal Analysis of Strategies Used for AI Detection on Two Subreddits
Pith reviewed 2026-06-26 09:21 UTC · model grok-4.3
The pith
Users in two Reddit communities develop and adapt twelve strategies to detect AI-generated media as models improve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
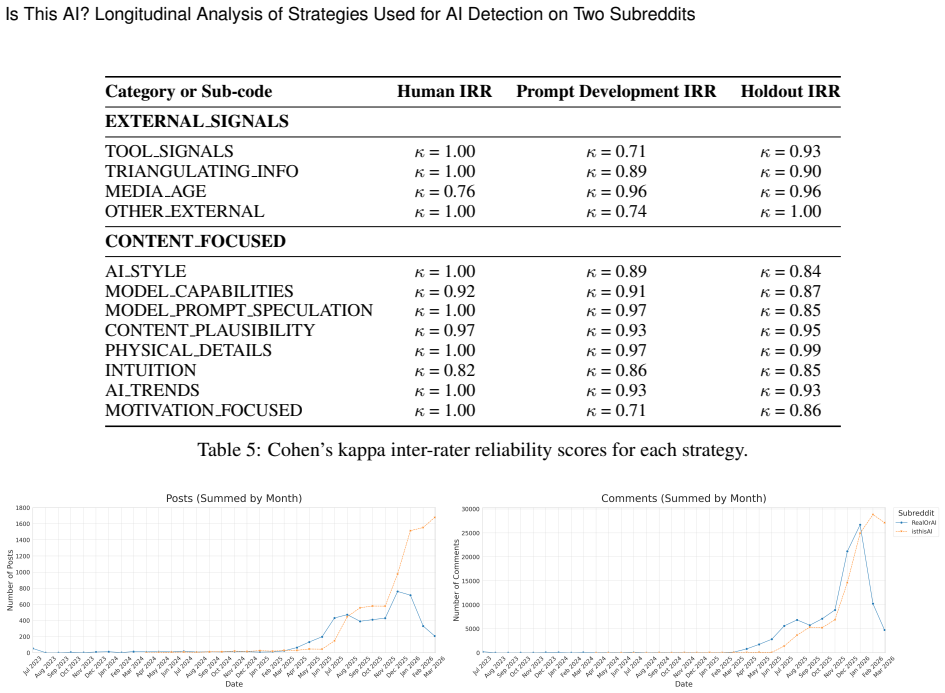
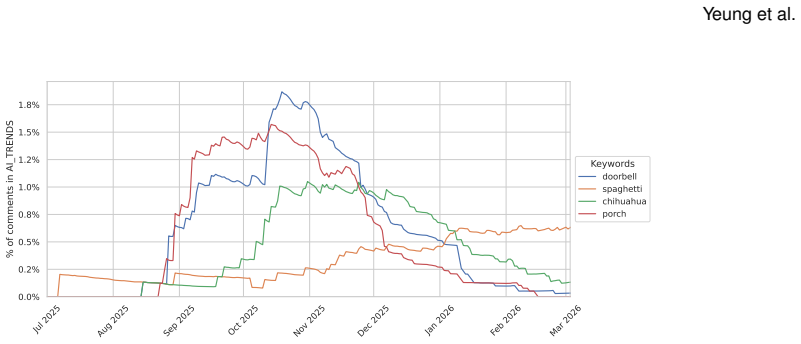
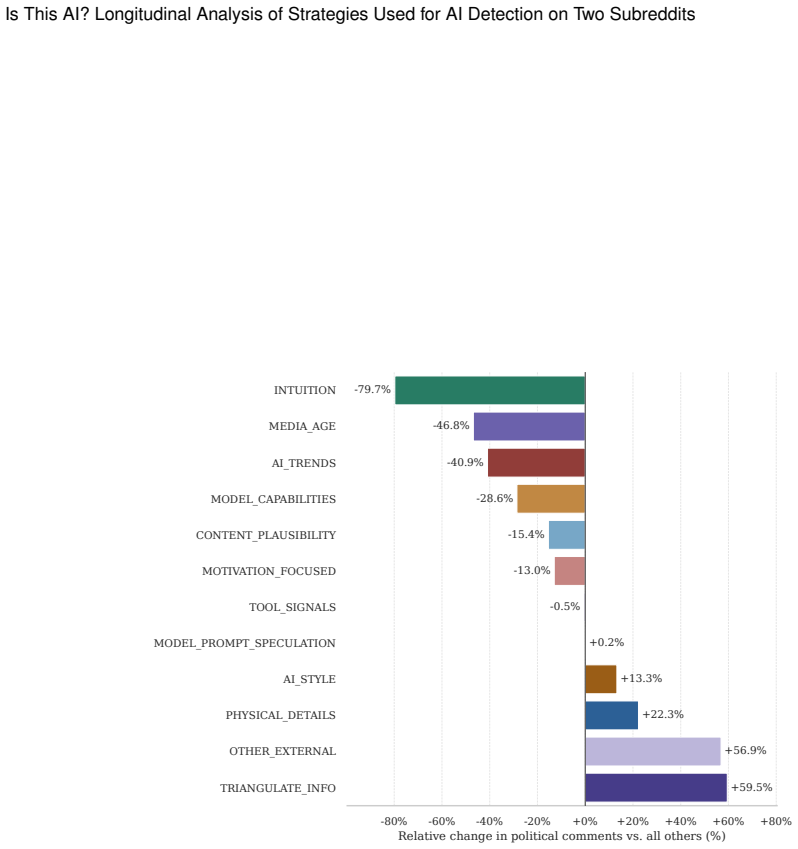
Through mixed-method analysis of posts and comments in r/isthisAI and r/RealOrAI, the paper catalogs twelve AI-detection strategies including examining fine-grained physical details, recognizing trends in AI-created content, and assumptions about model capabilities, and demonstrates that these strategies and associated mental models change over time in line with evolving AI capabilities and social trends.
What carries the argument
Catalog of twelve AI-detection strategies extracted from longitudinal analysis of community discussions and their temporal shifts.
If this is right
- The catalog of strategies can serve as a basis for user-facing guidance on identifying AI content.
- The documented shifts indicate that detection approaches must adapt as generative AI capabilities advance.
- Assumptions users hold about model limitations influence which strategies gain popularity.
- Crowdsourced analysis in these communities reveals collective mental models for distinguishing real and generated media.
Where Pith is reading between the lines
- Similar analysis on other platforms could reveal whether the twelve strategies generalize or vary by community type.
- The observed evolution suggests that static AI detectors risk becoming less effective without updates tied to current model trends.
- This catalog could support development of AI literacy tools that teach people the most reliable current strategies.
Load-bearing premise
The discussions and strategies observed in these two specific subreddits represent the broader strategies and mental models that people use to detect AI-generated media outside these communities.
What would settle it
A study of detection discussions on other platforms or through direct surveys that reveals substantially different strategies or no comparable temporal shifts would challenge the findings.
Figures

read the original abstract
As AI-generated content (e.g., "slop") becomes more prevalent online, people are developing strategies to attempt to identify it (or, conversely, to gain confidence that something is not AI-generated). What strategies are people using, and how are they changing over time as generative AI models themselves change? In this work, we catalog and analyze 2 years and 8 months of the AI detection strategies discussed by users of two popular Reddit communities (r/isthisAI and r/RealOrAI) that use the wisdom of crowds to identify AI-generated media. Through a mixed-method analysis of 13,098 posts and 222,060 comments within these communities, we catalog and analyze the prevalence of 12 AI-detection strategies, including examining fine-grained physical details, recognizing trends in AI-created content, and the assumptions people make about what models are capable of producing. Furthermore, we find that these strategies and mental models shift over time in accordance with changing AI capabilities and in response to online social trends. By systematically cataloging users' AI detection strategies, we lay the groundwork for user-facing guidance and future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a mixed-method longitudinal study of AI detection strategies in two Reddit subreddits (r/isthisAI and r/RealOrAI) spanning 2 years and 8 months. Analyzing 13,098 posts and 222,060 comments, the authors catalog 12 strategies (e.g., examining physical details, recognizing AI trends, assumptions about model capabilities), quantify their prevalence, and document temporal shifts aligned with AI advancements and social trends. The work positions itself as providing groundwork for user-facing guidance and future research.
Significance. If the reported findings are robustly supported by the underlying data and methods, the paper offers a substantial empirical contribution by systematically documenting user strategies for identifying AI-generated content in active online communities. The scale of the dataset and the longitudinal design are notable strengths that enable observation of evolving mental models. This could inform the development of detection tools and educational resources, though the scope is limited to these specific communities.
major comments (3)
- [Methods] The mixed-method analysis is described at a high level, but the Methods section provides no details on the coding scheme for identifying the 12 strategies, inter-rater reliability metrics, the sampling frame for selecting the 13,098 posts and 222,060 comments, or the statistical tests used to establish temporal shifts. These omissions prevent verification that the data support the prevalence and change claims.
- [Results] Claims of strategy prevalence and shifts over time (in accordance with AI capabilities and social trends) are central to the abstract and results, yet no tables, figures, or quantitative measures (e.g., percentages with confidence intervals or tests for trend significance) are referenced to ground these observations.
- [Discussion] The Discussion extends the catalog to 'user-facing guidance' and broader mental models, but this rests on the untested assumption that patterns from these two self-selected subreddits generalize; no cross-platform sampling, demographic controls, or comparison to other populations is provided.
minor comments (1)
- Figure captions and table headings should explicitly state the time periods and subreddit breakdowns to allow readers to assess the longitudinal claims independently.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the Methods and Results sections require substantial expansion with specific details and quantitative support, and we will revise the manuscript accordingly. For the Discussion, we will clarify scope and limitations without overclaiming generalizability.
read point-by-point responses
-
Referee: [Methods] The mixed-method analysis is described at a high level, but the Methods section provides no details on the coding scheme for identifying the 12 strategies, inter-rater reliability metrics, the sampling frame for selecting the 13,098 posts and 222,060 comments, or the statistical tests used to establish temporal shifts. These omissions prevent verification that the data support the prevalence and change claims.
Authors: We agree that these details are missing from the current Methods section. In revision we will add: (1) a full description of the iterative coding scheme development and how the 12 strategies were derived from the data; (2) inter-rater reliability statistics (e.g., Cohen’s kappa or percentage agreement) from the coding process; (3) explicit sampling details (the dataset comprises the complete set of posts and comments from the two subreddits over the 2-year-8-month window, with inclusion criteria); and (4) the specific statistical procedures (trend tests, time-series comparisons) used to evaluate temporal shifts. revision: yes
-
Referee: [Results] Claims of strategy prevalence and shifts over time (in accordance with AI capabilities and social trends) are central to the abstract and results, yet no tables, figures, or quantitative measures (e.g., percentages with confidence intervals or tests for trend significance) are referenced to ground these observations.
Authors: This observation is correct. Although the text describes prevalence and shifts, supporting numbers, tables, and figures are absent. We will insert new tables reporting strategy frequencies (percentages) overall and by time period, figures showing temporal trends, and the results of statistical tests (including p-values or confidence intervals) that underpin the claims of change aligned with AI capability shifts. revision: yes
-
Referee: [Discussion] The Discussion extends the catalog to 'user-facing guidance' and broader mental models, but this rests on the untested assumption that patterns from these two self-selected subreddits generalize; no cross-platform sampling, demographic controls, or comparison to other populations is provided.
Authors: We accept the critique on scope. The study is deliberately limited to these two communities; we do not possess cross-platform or demographic data. In revision we will explicitly state this limitation, remove or qualify any language implying broader generalizability, and reframe the contribution as groundwork specific to these active subreddits while recommending future comparative work. revision: partial
Circularity Check
Empirical content analysis of Reddit data exhibits no circularity
full rationale
The paper conducts a mixed-method analysis of 13,098 posts and 222,060 comments from two subreddits to catalog 12 AI-detection strategies and their temporal shifts. No equations, fitted parameters, predictions, or derivations are present that could reduce to inputs by construction. Claims rest directly on observed comment patterns rather than self-citation chains, ansatzes, or renamed known results. The work is self-contained as an empirical cataloging exercise with no load-bearing steps that equate to their own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Discussions in r/isthisAI and r/RealOrAI reflect authentic user strategies for detecting AI-generated media rather than performative or community-specific biases.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2026. Introducing Claude Sonnet 4.6.https://www.anthropic.com/news/ claude-sonnet-4-6. Accessed: 2026-05-17
2026
-
[2]
Theophilus Azungah. 2018. Qualitative Research: Deductive and Inductive Approaches to Data Analysis.Qual- itative Research Journal18, 4 (2018), 383–400
2018
-
[3]
Elijah Bouma-Sims, Hiba Hassan, Alexandra Nisenoff, Lorrie Faith Cranor, and Nicolas Christin. 2024. ”It was honestly just gambling”: Investigating the Experiences of Teenage Cryptocurrency Users on Reddit. InSymp. on Usable Privacy and Security. 333–352
2024
-
[4]
Elijah Bouma-Sims, Mandy Lanyon, and Lorrie Faith Cranor. 2025. ”Is this a scam?”: The Nature and Quality of Reddit Discussion about Scams. InProc. of the 2025 ACM SIGSAC Conf. on Computer and Communications Security. 2444–2458
2025
-
[5]
Sergi D Bray, Shane D Johnson, and Bennett Kleinberg. 2023. Testing human ability to detect ‘deepfake’images of human faces.Journal of Cybersecurity9, 1 (2023)
2023
-
[6]
C2PA. 2026. Coalition for Content Provenance and Authenticity.https://c2pa.org/
2026
-
[7]
Shuyang Cai and Wanyun Cui. 2023. Evade ChatGPT Detectors via A Single Space. arXiv:2307.02599 [cs.CL] https://arxiv.org/abs/2307.02599
arXiv 2023
-
[8]
Mike Caulfield. 2019. SIFT (The Four Moves).https://hapgood.us/2019/06/19/ sift-the-four-moves/. Accessed: 2026-05-17
2019
-
[9]
Miranda Christ, Sam Gunn, and Or Zamir. 2024. Undetectable watermarks for language models. InThe Thirty Seventh Annual Conference on Learning Theory. PMLR, 1125–1139
2024
-
[10]
Haoran Chu and Sixiao Liu. 2024. Can AI tell good stories? Narrative transportation and persuasion with ChatGPT.Journal of Communication74, 5 (10 2024), 347–358.https://doi.org/10.1093/joc/jqae029 arXiv:https://academic.oup.com/joc/article-pdf/74/5/347/59831381/jqae029.pdf
-
[11]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and psychological measurement 20, 1 (1960), 37–46
1960
-
[12]
Di Cooke, Abigail Edwards, Sophia Barkoff, and Kathryn Kelly. 2025. As Good as a Coin Toss: Human Detec- tion of AI-Generated Content.Commun. ACM68, 10 (2025), 100–109
2025
-
[13]
Alice Cullinane and Rebecca Woods. 2025. Meta accused of letting AI sellers ‘run rampant’.https://www. bbc.com/news/articles/c4gpz90d4q0o
2025
-
[14]
Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, et al. 2024. Scalable watermarking for iden- tifying large language model outputs.Nature634, 8035 (2024), 818–823
2024
-
[15]
Alexander Diel, Tania Lalgi, Isabel Carolin Schr¨oter, Karl F MacDorman, Martin Teufel, and Alexander B¨auerle
-
[16]
Human performance in detecting deepfakes: A systematic review and meta-analysis of 56 papers.Com- puters in Human Behavior Reports16 (2024), 100538
2024
-
[17]
Ahmed M Elkhatat, Khaled Elsaid, and Saeed Almeer. 2023. Evaluating the efficacy of AI content detection tools in differentiating between human and AI-generated text.International Journal for Educational Integrity 19, 1 (2023), 17
2023
-
[18]
Marie Ernst, Fabian Rupp, and Katharina Simbeck. 2025. You Can’t Detect Me! Using Prompt Engineering to Generate Undetectable Student Answers.. InCSEDU (2). 304–311
2025
-
[19]
Hany Farid. 2022. Creating, using, misusing, and detecting deep fakes.Journal of Online Trust and Safety1, 4 (2022)
2022
-
[20]
Participant
Casey Fiesler and Nicholas Proferes. 2018. “Participant” Perceptions of Twitter Research Ethics.Social Media + Society4, 1 (2018). Y eung et al
2018
-
[21]
Xingyu Fu, Siyi Liu, Yinuo Xu, Pan Lu, Guangqiuse Hu, Tianbo Yang, Taran Anantasagar, Christopher Shen, Yikai Mao, Yuanzhe Liu, Keyush Shah, Chung Un Lee, Yejin Choi, James Zou, Dan Roth, and Chris Callison-Burch. 2025. Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs. arXiv:2509.22646 [cs.CV]https://arxiv.org/abs/2509.22646
arXiv 2025
-
[22]
Dilrukshi Gamage, Dilki Sewwandi, Min Zhang, and Arosha K Bandara. 2025. Labeling synthetic content: User perceptions of label designs for AI-generated content on social media. InProceedings of the 2025 CHI conference on human factors in computing systems. 1–29
2025
-
[23]
Cassidy Gibson, Daniel Olszewski, Natalie Grace Brigham, Anna Crowder, Kevin RB Butler, Patrick Traynor, Elissa M Redmiles, and Tadayoshi Kohno. 2025. Analyzing the{AI}nudification application ecosystem. In34th USENIX Security Symposium (USENIX Security 25). 1–20
2025
-
[24]
JEJ Gotoman, HLT Luna, JCS Sangria, CS Santiago Jr, and DD Barbuco. 2025. Accuracy and reliability of AI-generated text detection tools: a literature review.American Journal of IR4, 0 (2025), 1–9
2025
-
[25]
Arthur Heitmann. 2024. arctic shift.https://github.com/ArthurHeitmann/arctic_shift. GitHub repository, accessed 2026-05-17
2024
-
[26]
Spam.” Now, With A.I., We’ve Got “Slop
Benjamin Hoffman. 2024. First Came “Spam.” Now, With A.I., We’ve Got “Slop”.https://www.nytimes. com/2024/06/11/style/ai-search-slop.html
2024
-
[27]
Sandra H ¨oltervennhoff, Jonas Ricker, Maike M Raphael, Charlotte Schwedes, Rebecca Weil, Asja Fischer, Thorsten Holz, Lea Sch ¨onherr, and Sascha Fahl. 2026. ”That’s another doom I haven’t thought about”: A User Study on AI Labels as a Safeguard Against Image-Based Misinformation. InProceedings of the 2026 CHI Conference on Human Factors in Computing Sys...
2026
-
[28]
Sandra Holtervennhoff, Jonas Ricker, Maike M. Raphael, Charlotte Schwedes, Rebecca Weil, Asja Fischer, Thorsten Holz, Lea Sch ¨onherr, and Sascha Fahl. 2026. ”That’s another doom I haven’t thought about”: A User Study on AI Labels as a Safeguard Against Image-Based Misinformation. InProceedings of the 2026 CHI Conference on Human Factors in Computing Syst...
-
[29]
Shehzeen Hussain, Paarth Neekhara, Malhar Jere, Farinaz Koushanfar, and Julian McAuley. 2021. Adversar- ial deepfakes: Evaluating vulnerability of deepfake detectors to adversarial examples. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 3348–3357
2021
-
[30]
JeremyFindsAI. 2026. Instagram profile: JeremyFindsAI.https://www.instagram.com/jeremyfindsai/. Accessed: 2026-05-07
2026
-
[31]
Kaitlyn Van Kampen. 2025. Library Guides: Evaluating Resources and Misinformation: The SMART Check. https://guides.lib.uchicago.edu/c.php?g=1241077&p=9082345
2025
-
[32]
Brian Kennedy, Eileen Yam, Emma Kikuchi, Isabelle Pula, and Javier Fuentes. 2025. How Americans View AI and Its Impact on People and Society.https://www.pewresearch.org/science/2025/09/17/ how-americans-view-ai-and-its-impact-on-people-and-society/Accessed: 2026-05-02
2025
-
[33]
Helena Chmura Kraemer, David J. Kupfer, Diana E. Clarke, William E. Narrow, and Dar- rel A. Regier. 2012. DSM-5: How Reliable Is Reliable Enough?American Journal of Psychiatry169, 1 (2012), 13–15.https://doi.org/10.1176/appi.ajp.2011.11010050 arXiv:https://psychiatryonline.org/doi/pdf/10.1176/appi.ajp.2011.11010050
-
[34]
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. 2023. Paraphrasing Evades Detectors of AI-generated Text, but Retrieval is an Effective Defense. arXiv:2303.13408 [cs.CL]https: //arxiv.org/abs/2303.13408
arXiv 2023
-
[35]
Seth Layton, Bernardo B. P. Medeiros, Kevin Butler, and Patrick Traynor. 2026. AI Wrote My Paper and All I Got Was This False Negative: Measuring the Efficacy of Commercial AI Text Detectors. InIEEE Symposium on Security & Privacy
2026
-
[36]
Weixin Liang, Mert Yuksekgonul, Yining Mao, Eric Wu, and James Zou. 2023. GPT detectors are biased against non-native English writers.Patterns4, 7 (2023), 100779.https://doi.org/10.1016/j.patter.2023. 100779
-
[37]
Gabriel Lima, Nina Grgi ´c-Hlaˇca, and Elissa M. Redmiles. 2025. Public Opinions About Copyright for AI- Generated Art: The Role of Egocentricity, Competition, and Experience. InProceedings of the 2025 CHI Con- ference on Human Factors in Computing Systems (CHI ’25). ACM, 1–32.https://doi.org/10.1145/ 3706598.3713338 Is This AI? Longitudinal Analysis of S...
arXiv 2025
-
[38]
Aiwei Liu, Leyi Pan, Yijian Lu, Jingjing Li, Xuming Hu, Xi Zhang, Lijie Wen, Irwin King, Hui Xiong, and Philip Yu. 2024. A Survey of Text Watermarking in the Era of Large Language Models.ACM Comput. Surv.57, 2, Article 47 (Nov. 2024), 36 pages.https://doi.org/10.1145/3691626
-
[39]
Ning Lu, Shengcai Liu, Rui He, Qi Wang, Yew-Soon Ong, and Ke Tang. 2024. Large Language Models can be Guided to Evade AI-Generated Text Detection. arXiv:2305.10847 [cs.CL]https://arxiv.org/abs/2305. 10847
arXiv 2024
-
[40]
Kimberly T Mai, Sergi Bray, Toby Davies, and Lewis D Griffin. 2023. Warning: Humans cannot reliably detect speech deepfakes.Plos one18, 8 (2023), e0285333
2023
-
[41]
Tim Marcin. 2025. AI-generated animals in fake surveillance videos are fooling the internet.https:// mashable.com/article/ai-generated-animals-footage-fake
2025
-
[42]
Barbosa, Olivia Figueira, Yang Wang, and Gang Wang
Jaron Mink, Licheng Luo, Nat ˜a M. Barbosa, Olivia Figueira, Yang Wang, and Gang Wang. 2022. DeepPhish: Understanding User Trust Towards Artificially Generated Profiles in Online Social Networks. In31st USENIX Security Symposium (USENIX Security 22). USENIX Association, Boston, MA, 1669–1686.https://www. usenix.org/conference/usenixsecurity22/presentation/mink
2022
-
[43]
Munyendo, Kurt Hugenberg, Tadayoshi Kohno, Elissa M
Jaron Mink, Miranda Wei, Collins W. Munyendo, Kurt Hugenberg, Tadayoshi Kohno, Elissa M. Redmiles, and Gang Wang. 2024. It’s Trying Too Hard To Look Real: Deepfake Moderation Mistakes and Identity-Based Bias. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New...
-
[44]
Anders Giovanni Møller, Daniel M Romero, David Jurgens, and Luca Maria Aiello. 2026. The impact of gener- ative AI on social media: An experimental study.Scientific Reports(2026)
2026
-
[45]
Nicolas M M ¨uller, Karla Pizzi, and Jennifer Williams. 2022. Human perception of audio deepfakes. InProceed- ings of the 1st international workshop on deepfake detection for audio multimedia. 85–91
2022
-
[46]
Amal Naitali, Mohammed Ridouani, Fatima Salahdine, and Naima Kaabouch. 2023. Deepfake attacks: Genera- tion, detection, datasets, challenges, and research directions.Computers12, 10 (2023), 216
2023
-
[47]
Souradip Nath, Chih-Yi Huang, Aditi Ganapathi, Kashyap Thimmaraju, Jaron Mink, and Gail-Joon Ahn. 2026. Like a Hammer, It Can Build, It Can Break: Large Language Model Uses, Perceptions, and Adoption in Cyber- security Operations on Reddit. arXiv:2604.09998 [cs.CR]https://arxiv.org/abs/2604.09998
Pith/arXiv arXiv 2026
-
[48]
Rajvardhan Oak and Zubair Shafiq. 2025. Victims, Vigilantes, and Advice Givers: An Analysis of{Scam- Related}Discourse on Reddit. InSOUPS 2025. 57–71
2025
-
[49]
James Peckham. 2025.Sora 2 Now Lets You Make 15-Second Clips, 25 Seconds for $200 Pro Users.https://www.pcmag.com/news/ sora-2-now-lets-you-make-15-second-clips-25-seconds-for-200-pro-usersAccessed: 2026-05-20
2025
-
[50]
Reddit. 2026. r/AIorFake.https://www.reddit.com/r/AIorFake/. Accessed: 2026-05-17
2026
-
[51]
Reddit. 2026. r/AI or Real.https://www.reddit.com/r/AI_or_Real. Accessed: 2026-05-17
2026
-
[52]
r/isthisAI Mods. 2025. Flair has been added along with a SOLVED flair.https://www.reddit.com/r/ isthisAI/comments/1ox0uk2/flair_has_been_added_along_with_a_solved_flair/
2025
-
[53]
r/isthisAI Mods. 2026. [ANSWERS FROM THE MODS].https://www.reddit.com/r/isthisAI/ comments/1rvem0n/answers_from_the_mods_why_are_mods_removing_all/
2026
-
[54]
Thomas Roca, Anthony Cintron Roman, Jeh ´u Torres Vega, Marcelo Duarte, Pengce Wang, Kevin White, Amit Misra, and Juan Lavista Ferres. 2025. How good are humans at detecting AI-generated images? Learnings from an experiment. arXiv:2507.18640 [cs.HC]https://arxiv.org/abs/2507.18640
arXiv 2025
-
[55]
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. 2025. Can AI-Generated Text be Reliably Detected? arXiv:2303.11156 [cs.CL]https://arxiv.org/abs/2303.11156
Pith/arXiv arXiv 2025
-
[56]
Gerard Salton and Christopher Buckley. 1988. Term-weighting approaches in automatic text retrieval.Infor- mation Processing & Management24, 5 (1988), 513–523.https://doi.org/10.1016/0306-4573(88) 90021-0
-
[57]
Chantal Shaib, Tuhin Chakrabarty, Diego Garcia-Olano, and Byron C Wallace. 2025. Measuring AI” Slop” in Text.arXiv preprint arXiv:2509.19163(2025)
arXiv 2025
-
[58]
Rosie Thomas. 2025. AI Bunnies on Trampoline Causing Crisis of Confidence on TikTok.https://www. 404media.co/ai-bunnies-on-trampoline-causing-crisis-of-confidence-on-tiktok/. Y eung et al
2025
-
[59]
Debora Weber-Wulff, Alla Anohina-Naumeca, Sonja Bjelobaba, Tom ´aˇs Folt´ynek, Jean Guerrero-Dib, Olumide Popoola, Petr ˇSigut, and Lorna Waddington. 2023. Testing of detection tools for AI-generated text.International Journal for Educational Integrity19, 1 (Dec. 2023).https://doi.org/10.1007/s40979-023-00146-z
-
[60]
Miranda Wei, Sunny Consolvo, Patrick Gage Kelley, Tadayoshi Kohno, Tara Matthews, Sarah Meiklejohn, Franziska Roesner, Renee Shelby, Kurt Thomas, and Rebecca Umbach. 2024. Understanding Help-Seeking and Help-Giving on Social Media for Image-Based Sexual Abuse. In33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, Philadelphia, PA, 439...
2024
-
[61]
Sam Wineburg and Sarah McGrew. 2019. Lateral Reading and the Nature of Expertise: Reading Less and Learning More When Evaluating Digital Information.Teachers College Record121, 11 (2019), 1–40.https: //doi.org/10.1177/016146811912101102
-
[62]
Xuandong Zhao, Sam Gunn, Miranda Christ, Jaiden Fairoze, Andres Fabrega, Nicholas Carlini, Sanjam Garg, Sanghyun Hong, Milad Nasr, Florian Tramer, Somesh Jha, Lei Li, Yu-Xiang Wang, and Dawn Song. 2025. SoK: Watermarking for AI-Generated Content. arXiv:2411.18479 [cs.CR]https://arxiv.org/abs/2411.18479
arXiv 2025
-
[63]
Xuandong Zhao, Kexun Zhang, Zihao Su, Saastha Vasan, Ilya Grishchenko, Christopher Kruegel, Giovanni Vi- gna, Yu-Xiang Wang, and Lei Li. 2024. Invisible Image Watermarks Are Provably Removable Using Generative AI. arXiv:2306.01953 [cs.CR]https://arxiv.org/abs/2306.01953 A Ethics and Adverse Impact Statement We describe here several ethical considerations ...
arXiv 2024
-
[64]
Our University’s IRB does not consider studies like this one to be federally-regulated human subjects re- search, because they work with public data that does not (typically) contain personally-identifiable or other sensitive information. Nevertheless, we acknowledge that although we draw our dataset from a public source (publicly-available Reddit comment...
-
[65]
There are also ethical considerations with using LLMs to label data, since this may (for example) result in the unexpected downstream use of sensitive or participant data for model training. We selected the option to disallow Claude from using our data for training, and we used Anthropic’s API to batch-send data, which (according to the company’s document...
-
[66]
AI can’t do physics,
In terms of adverse impacts, we recognize that AI companies or AI-generated content creators who are acting in bad faith (or simply want to improve the “quality” of their content by some metrics) could use our findings to make AI-generated content harder to detect. However, this is an ongoing arms race that is likely to be minimally impacted by our paper....
-
[67]
Read the comment carefully
-
[68]
Assign one or more category labels from the taxonomy above
-
[69]
Quote the specific phrase(s) from the comment that support each label
-
[70]
A quote may be reused across labels if necessary
Each label must have at least one supporting quote. A quote may be reused across labels if necessary
-
[71]
If the label is IRRELEVANT, return an empty evidence array
-
[72]
labels": [
Return only valid JSON, as formatted in ##OUTPUT FORMAT. Do not include any explanation, preamble, or markdown formatting outside of the JSON object. ## OUTPUT FORMAT Return your answer as a JSON object using this exact structure: { "labels": ["LABEL 1", ‘‘LABEL 2’’], "evidence": [ { "label": "LABEL 1", "quote": "exact quote from the comment" }, { "label"...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.