Resolving Ambiguity in Composed Image Retrieval via Calibrated Interaction
Pith reviewed 2026-06-30 13:45 UTC · model grok-4.3
The pith
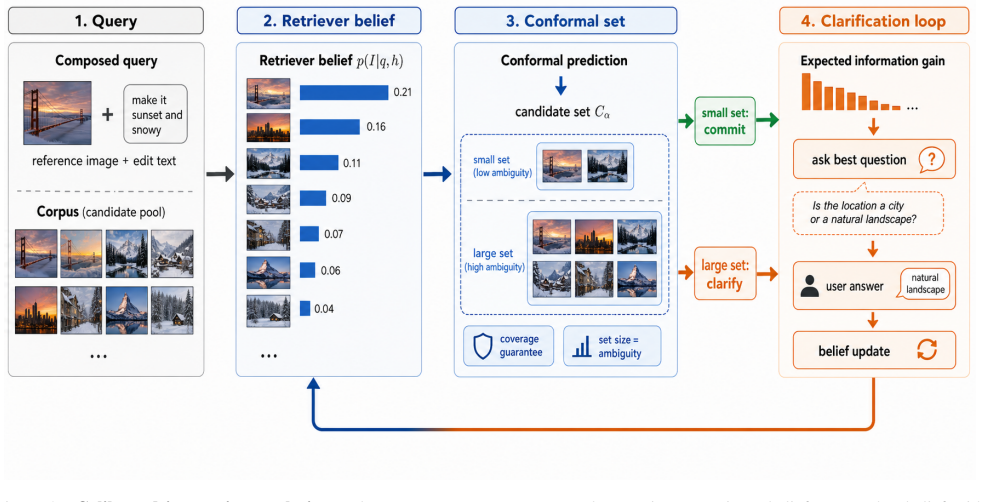
Composed image retrieval queries define regions of the corpus rather than single targets, so a conformal prediction wrapper on any retriever produces a coverage-guaranteed candidate set whose size measures ambiguity and triggers one clarify
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that conformal prediction applied to the scores of any composed-image retriever yields a candidate set whose coverage is guaranteed by exchangeability and whose cardinality quantifies ambiguity; an expected-information-gain policy then selects one clarifying question from predefined axes that is guaranteed to reduce the expected size of the remaining set, allowing the system to reach the intended target in a fraction of the turns required by uncalibrated dialogue baselines while preserving single-turn performance on precise queries.
What carries the argument
The conformal prediction layer that returns a coverage-guaranteed candidate set whose size quantifies ambiguity, paired with an expected-information-gain policy that selects one question from interpretable ambiguity axes.
If this is right
- On queries that are already precise the method returns a singleton set and matches single-turn state-of-the-art recall with no added cost.
- On ambiguous queries the calibrated set plus one information-gain question reaches the intended target using substantially fewer interactions than conversational baselines.
- The method is the first to supply valid coverage and calibration metrics for composed image retrieval.
- The introduced AmbiCIR benchmark revives auxiliary and dialogue annotations from CIRR while extending the multiple-positive setting of CIRCO.
Where Pith is reading between the lines
- If the ambiguity axes prove effective, the same conformal-plus-information-gain pattern could be applied to other underspecified retrieval settings such as text-to-image or video search.
- The size of the conformal set could itself be used as a training signal to encourage retrievers to produce sharper score distributions on precise queries.
- Because the clarifying questions are drawn from human-interpretable axes, the interaction logs may yield reusable data for training future ambiguity-aware models.
Load-bearing premise
The scores produced by the underlying retriever must satisfy the exchangeability condition that conformal prediction requires in order for the coverage guarantee to be valid on composed queries.
What would settle it
Empirical coverage measured on a held-out test split of composed queries; if the fraction of queries for which the true target lies inside the reported set falls below the nominal guarantee level, the calibration claim is false.
Figures


read the original abstract
Composed image retrieval (CIR) searches a corpus with a reference image and a text describing how to modify it. Despite rapid progress from triplet-trained compositors to zero-shot and generative methods, essentially all systems share one assumption: that a query maps to a single target, scored by Recall@K against one annotation. We argue this is fundamentally at odds with the task. A query such as make it more formal does not name an image but a region of the corpus, and which member the user intends is genuinely underdetermined. This underspecification is the root of the well-known false-negative problem and leaves current models unable to tell a precise query from an ambiguous one. We reframe CIR as calibrated intent resolution under uncertainty: a retriever is wrapped in a conformal prediction layer that returns a candidate set with a coverage guarantee and whose size is a principled measure of ambiguity; when the set is large, an expected-information-gain policy asks the single most useful clarifying question, drawn from interpretable ambiguity axes, and the set contracts. We introduce AmbiCIR, a benchmark and human-validated user simulator that revive the dormant auxiliary and dialogue annotations of CIRR and extend the multiple-positive setting of CIRCO. Across open-domain and fashion benchmarks our method matches single-turn state of the art, confirming calibrated resolution is cost-free on precise queries, while reaching the intended target in a fraction of the interaction budget required by naive conversational baselines, and it is the first to report valid coverage and calibration for the task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reframes composed image retrieval (CIR) as calibrated intent resolution under uncertainty. A retriever is wrapped in a conformal prediction layer that outputs candidate sets with coverage guarantees (whose size serves as a principled ambiguity measure); when sets are large, an expected-information-gain policy selects a single clarifying question from interpretable ambiguity axes. The work introduces the AmbiCIR benchmark (reviving auxiliary/dialogue annotations from CIRR and extending CIRCO's multiple-positive setting) together with a human-validated user simulator. Experiments on open-domain and fashion benchmarks show single-turn performance matching state-of-the-art while reducing interaction budget relative to naive conversational baselines, and the paper claims to be the first to report valid coverage and calibration for the task.
Significance. If the coverage guarantees hold, the contribution is significant: it supplies the first explicit treatment of ambiguity in CIR via conformal sets, converts set size into a calibrated ambiguity metric, and demonstrates that interactive clarification can be performed with far fewer turns than baselines while preserving single-turn accuracy on precise queries. The introduction of AmbiCIR with human-validated simulation and the explicit reporting of coverage/calibration are concrete strengths.
major comments (2)
- [Section 4] Conformal prediction setup (Section 4 / conformal layer description): the reported coverage on AmbiCIR/CIRR/CIRCO is presented as a guarantee, yet the manuscript does not describe a disjoint calibration protocol or weighted correction that would ensure exchangeability of nonconformity scores between calibration and test queries. Standard splits share images and similar modifications, violating the exchangeability assumption required for valid coverage; without this detail the central claim that set size is a principled ambiguity measure rests on an unverified premise.
- [Table 2] Experimental validation of coverage (Table 2 / coverage results): the abstract and results claim valid coverage and calibration, but no derivation of the nonconformity scores, no description of how they are constructed or validated, and no error bars or sensitivity analysis to split choice are provided. This makes it impossible to assess whether the reported coverage is robust or an artifact of post-hoc choices.
minor comments (2)
- [Abstract] The abstract states coverage and calibration results but supplies no derivation details; the full paper should include an explicit equation for the nonconformity score and the calibration procedure.
- [Figure 3] Figure captions and ambiguity-axis definitions would benefit from an additional sentence clarifying how the axes are extracted from the revived CIRR annotations.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the conformal prediction setup. We clarify the calibration details below and will revise the manuscript to make the protocol, nonconformity scores, and robustness analysis fully explicit.
read point-by-point responses
-
Referee: Conformal prediction setup (Section 4): the reported coverage is presented as a guarantee, yet the manuscript does not describe a disjoint calibration protocol or weighted correction to ensure exchangeability of nonconformity scores. Standard splits share images and modifications, violating the exchangeability assumption.
Authors: We agree the description was insufficiently explicit. Our calibration set is a disjoint held-out portion of the training data with no image overlap or similar modifications to the test queries, preserving exchangeability. We will add a dedicated paragraph in Section 4 describing the exact split construction, confirming the coverage guarantee under this protocol. revision: yes
-
Referee: Table 2: no derivation of the nonconformity scores, no description of how they are constructed or validated, and no error bars or sensitivity analysis to split choice are provided.
Authors: The nonconformity score is defined as one minus the cosine similarity between the query embedding and each candidate image embedding. We will insert the precise formula and construction details into Section 4. We will also augment the coverage results with error bars over five random calibration splits and a sensitivity table showing coverage stability across split ratios. revision: yes
Circularity Check
No circularity; coverage guarantee is standard conformal prediction applied externally
full rationale
The paper's central claim applies an off-the-shelf conformal prediction wrapper to an existing retriever to produce candidate sets whose size measures ambiguity, with coverage following from the standard exchangeability assumption on nonconformity scores. No equations, self-definitions, or fitted parameters are shown that would make the coverage or set-size measure reduce to the inputs by construction. The AmbiCIR benchmark and human-validated simulator are introduced as independent evaluation resources. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The derivation therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Exchangeability of query-score tuples sufficient for conformal coverage guarantee
Reference graph
Works this paper leans on
-
[1]
Composing text and image for image retrieval - an empirical odyssey
Nam V o, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval - an empirical odyssey. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[2]
1, 2, 3, 4, 6, 7, 8, 9
-
[3]
Image search with text feedback by visiolinguistic attention learn- ing
Yanbei Chen, Shaogang Gong, and Loris Bazzani. Image search with text feedback by visiolinguistic attention learn- ing. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2020. 3
2020
-
[4]
Modality- agnostic attention fusion for visual search with text feedback,
Eric Dodds, Jack Culpepper, Simao Herdade, Yang Zhang, and Kofi Boakye. Modality-agnostic attention fusion for visual search with text feedback.arXiv preprint arXiv:2007.00145, 2020. 1, 3
-
[5]
Pic2Word: Mapping pictures to words for zero-shot composed image retrieval
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Pic2Word: Mapping pictures to words for zero-shot composed image retrieval. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19305–19314, 2023. 1, 3, 7, 8
2023
-
[6]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Al- berto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 15338–15347, 2023. 1, 3, 7, 8, 10
2023
-
[7]
CompoDiff: Versatile composed im- age retrieval with latent diffusion.Transactions on Machine Learning Research (TMLR), 2024
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, Yoohoon Kang, and Sangdoo Yun. CompoDiff: Versatile composed im- age retrieval with latent diffusion.Transactions on Machine Learning Research (TMLR), 2024. 1, 3, 7, 8
2024
-
[8]
Yuanmin Tang, Jue Zhang, Xiaoting Qin, Jing Yu, Gaopeng Gou, Gang Xiong, Qingwei Lin, Saravan Rajmohan, Dong- mei Zhang, and Qi Wu. Reason-before-retrieve: One-stage reflective chain-of-thoughts for training-free zero-shot com- posed image retrieval. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2025. CVPR 2025 Highlight; arXi...
-
[9]
Zero-shot composed image retrieval with textual inversion (CIRCO benchmark)
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Al- berto Del Bimbo. Zero-shot composed image retrieval with textual inversion (CIRCO benchmark). InIEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 15338–15347, 2023. Introduces the CIRCO dataset with multiple ground-truth targets per query. 1, 2, 7, 9, 10
2023
-
[10]
Algorithmic Learning in a Random World
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer. Algorithmic Learning in a Random World. Springer, 2005. 1, 2, 4, 5, 7, 9
2005
-
[11]
Angelopoulos and Stephen Bates
Anastasios N. Angelopoulos and Stephen Bates. A gentle in- troduction to conformal prediction and distribution-free un- certainty quantification.Foundations and Trends in Machine Learning, 16(4):494–591, 2023. 1, 2, 4, 5, 6, 10
2023
-
[12]
Dennis V . Lindley. On a measure of the information provided by an experiment.The Annals of Mathematical Statistics, 27 (4):986–1005, 1956. 1, 2, 4, 5, 9
1956
-
[13]
Xiaoxiao Guo, Hui Wu, Yu Gao, Steven J. Rennie, and Roge- rio Feris. The Fashion IQ dataset: Retrieving images by com- bining side information and relative natural language feed- back.arXiv preprint arXiv:1905.12794, 2019. 1, 3, 4, 7
-
[14]
Support vector machine active learning for image retrieval
Simon Tong and Edward Chang. Support vector machine active learning for image retrieval. InACM International Conference on Multimedia (ACM MM), 2001. 1, 3
2001
-
[15]
Wen Li, Lixin Duan, Dong Xu, and Ivor W. Tsang. Text- based image retrieval using progressive multi-instance learn- ing. InIEEE International Conference on Computer Vision (ICCV), 2011. 3
2011
-
[16]
Chai, and Rong Jin
Chen Zhang, Joyce Y . Chai, and Rong Jin. User term feed- back in interactive text-based image retrieval.ACM SIGIR Conference on Research and Development in Information Retrieval, 2005. 3
2005
-
[17]
DeepFashion: Powering robust clothes recognition and retrieval with rich annotations
Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. DeepFashion: Powering robust clothes recognition and retrieval with rich annotations. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[18]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational Conference on Machine Learning (ICML), 2023. 1, 3, 4, 5, 7, 10
2023
-
[19]
Generative zero-shot composed image retrieval
Yuanmin Wang et al. Generative zero-shot composed image retrieval. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Verify full author list and pages before camera-ready. 1, 3
2025
-
[20]
Wein- berger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Wein- berger. On calibration of modern neural networks. InIn- ternational Conference on Machine Learning (ICML), pages 1321–1330, 2017. 1, 4, 6
2017
-
[21]
Composed query image retrieval using locally bounded features
Mehrdad Hosseinzadeh and Yang Wang. Composed query image retrieval using locally bounded features. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3
2020
-
[22]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 3
2017
-
[23]
Lim, and Edward H
Phillip Isola, Joseph J. Lim, and Edward H. Adelson. Dis- covering states and transformations in image collections. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 3
2015
-
[24]
Berg, Alexander C
Tamara L. Berg, Alexander C. Berg, and Jonathan Shih. Au- tomatic attribute discovery and characterization from noisy web data. InEuropean Conference on Computer Vision (ECCV), 2010. 3
2010
-
[25]
Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S
Xintong Han, Zuxuan Wu, Phoenix X. Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S. Davis. Au- tomatic spatially-aware fashion concept discovery. InIEEE International Conference on Computer Vision (ICCV), 2017. 3
2017
-
[26]
Learning transferable vi- sual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable vi- sual models from natural language supervision. InInter- national Conference on Machine Learning (ICML), pages 8748–8763, 2021. 3, 4, 7
2021
-
[27]
Deep shape matching
Filip Radenovi ´c, Giorgos Tolias, and Ond ˇrej Chum. Deep shape matching. InEuropean Conference on Computer Vi- sion (ECCV), 2018. 3
2018
-
[28]
FaceNet: A unified embedding for face recognition and clus- tering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. FaceNet: A unified embedding for face recognition and clus- tering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 3
2015
-
[29]
Deep face recognition: A survey.SIBGRAPI Conference on Graphics, Patterns and Images, 2018
Iacopo Masi, Yue Wu, Tal Hassner, and Prem Natarajan. Deep face recognition: A survey.SIBGRAPI Conference on Graphics, Patterns and Images, 2018. 3
2018
-
[30]
J. Song, T. He, L. Gao, X. Xu, and H. T. Shen. Deep region hashing for efficient large-scale instance search from images. InProceedings of the AAAI Conference on Artificial Intelli- gence, volume 32, 2017. 3
2017
-
[31]
J. Song, T. He, H. Fan, and L. Gao. Deep discrete hashing with self-supervised pairwise labels. InJoint European Con- ference on Machine Learning and Knowledge Discovery in Databases, 2017. 3
2017
-
[32]
J. Song, T. He, L. Gao, X. Xu, A. Hanjalic, and H. T. Shen. Binary generative adversarial networks for image retrieval. InProceedings of the AAAI Conference on Artificial Intelli- gence, volume 32, 2018. 3, 10
2018
-
[33]
J. Song, T. He, L. Gao, X. Xu, A. Hanjalic, and H. T. Shen. Unified binary generative adversarial network for image re- trieval and compression.International Journal of Computer Vision, 128(8):2243–2264, 2020. 3, 10
2020
-
[34]
He, Y .-F
T. He, Y .-F. Li, L. Gao, D. Zhang, and J. Song. One net- work for multi-domains: Domain adaptive hashing with in- tersectant generative adversarial network. InProceedings of the International Joint Conference on Artificial Intelligence,
-
[35]
T. He, L. Gao, J. Song, X. Wang, K. Huang, and Y . Li. Sneq: Semi-supervised attributed network embedding with attention-based quantisation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 4091–4098, 2020. 3
2020
-
[36]
T. He, L. Gao, J. Song, and Y .-F. Li. Semisupervised net- work embedding with differentiable deep quantization.IEEE Transactions on Neural Networks and Learning Systems, 34 (8):4791–4802, 2021. 3
2021
-
[37]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 3
2017
-
[38]
BERT: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional trans- formers for language understanding. InConference of the North American Chapter of the Association for Computa- tional Linguistics (NAACL), 2019. 3
2019
-
[39]
ViL- BERT: Pretraining task-agnostic visiolinguistic representa- tions for vision-and-language tasks
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. ViL- BERT: Pretraining task-agnostic visiolinguistic representa- tions for vision-and-language tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2019. 3
2019
-
[40]
VisualBERT: A Simple and Performant Baseline for Vision and Language
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. VisualBERT: A simple and perfor- mant baseline for vision and language.arXiv preprint arXiv:1908.03557, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[41]
LXMERT: Learning cross- modality encoder representations from transformers
Hao Tan and Mohit Bansal. LXMERT: Learning cross- modality encoder representations from transformers. InCon- ference on Empirical Methods in Natural Language Process- ing (EMNLP), 2019. 3
2019
-
[42]
UNITER: Universal image-text representation learning
Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. UNITER: Universal image-text representation learning. In European Conference on Computer Vision (ECCV), 2020. 3
2020
-
[43]
OSCAR: Object- semantics aligned pre-training for vision-language tasks
Xiujun Li, Xi Yin, Chunyuan Li, Xiaowei Hu, Pengchuan Zhang, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. OSCAR: Object- semantics aligned pre-training for vision-language tasks. In European Conference on Computer Vision (ECCV), 2020. 3, 4, 7, 8
2020
-
[44]
A recurrent vision-and-language BERT for navigation
Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez- Opazo, and Stephen Gould. A recurrent vision-and-language BERT for navigation. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2021. 3
2021
-
[45]
T. He, L. Gao, J. Song, J. Cai, and Y .-F. Li. Learning from the scene and borrowing from the rich: Tackling the long tail in scene graph generation. InProceedings of the International Joint Conference on Artificial Intelligence, 2020. 3
2020
-
[46]
T. He, L. Gao, J. Song, and Y .-F. Li. State-aware composi- tional learning toward unbiased training for scene graph gen- eration.IEEE Transactions on Image Processing, 32:43–56,
- [47]
-
[48]
T. He, L. Gao, J. Song, and Y .-F. Li. Towards open- vocabulary scene graph generation with prompt-based fine- tuning. InEuropean Conference on Computer Vision, 2022
2022
-
[49]
X. Hu, K. Qin, G. Duan, M. Li, Y .-F. Li, and T. He. Spade: Spatial-aware denoising network for open- vocabulary panoptic scene graph generation with long- and local-range context reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision,
-
[50]
Z. Yang, X. Liu, D. Ouyang, G. Duan, D. Zhang, T. He, and Y .-F. Li. Towards open-vocabulary hoi detection with cal- ibrated vision-language models and locality-aware queries. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1495–1504, 2024. 3, 4
2024
-
[51]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. InIEEE Inter- national Conference on Computer Vision (ICCV), 2015. 3
2015
-
[52]
Bottom-up and top-down attention for image captioning and visual question answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[53]
Tips and tricks for visual question an- swering: Learnings from the 2017 challenge
Damien Teney, Peter Anderson, Xiaodong He, and Anton van den Hengel. Tips and tricks for visual question an- swering: Learnings from the 2017 challenge. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 3
2017
-
[54]
R. Y . Zakari, J. W. Owusu, K. Qin, T. He, and G. Luo. Seeing and reasoning: A simple deep learning approach to visual question answering.Big Data Mining and Analytics, 8(2): 458, 2025. 3
2025
-
[55]
R. Y . Zakari, J. W. Owusu, K. Qin, H. Wang, Z. K. Lawal, and T. He. Vqa and visual reasoning: An overview of ap- proaches, datasets, and future direction.Neurocomputing, 622:129345, 2025. 3
2025
-
[56]
Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap
Adam Santoro, David Raposo, David G. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A simple neural network module for relational rea- soning. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2017. 3, 5
2017
-
[57]
Girshick
Ross B. Girshick. Fast R-CNN. InIEEE International Con- ference on Computer Vision (ICCV), 2015. 3
2015
-
[58]
Girshick, and Jian Sun
Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with re- gion proposal networks.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (TPAMI), 2015. 3
2015
-
[59]
Multimodal residual learning for visual qa
Jin-Hwa Kim, Sang-Woo Lee, Donghyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. Multimodal residual learning for visual qa. InAdvances in Neural Information Processing Systems (NeurIPS), 2016. 3
2016
-
[60]
FiLM: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Du- moulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer. InAAAI Conference on Artificial Intelligence, 2018. 3
2018
- [61]
-
[62]
R. Dai, C. Li, Y . Yan, L. Mo, K. Qin, and T. He. Unbi- ased missing-modality multimodal learning. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, 2025. 3, 6, 10
2025
- [63]
-
[64]
Y . Dong, T. He, Q. Dong, and K. Qin. Kmg-ll: Knowledge- enhanced multimodal graph for dialogue generation. In ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing, 2025. 3, 4, 10
2025
-
[65]
Dialog-based interactive image retrieval
Xiaoxiao Guo, Hui Wu, Yu Cheng, Steven Rennie, Gerald Tesauro, and Rogerio Feris. Dialog-based interactive image retrieval. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2018. 3, 10
2018
-
[66]
Plummer, Leonid Sigal, Stan Sclaroff, and Kate Saenko
Huijuan Xu, Kun He, Bryan A. Plummer, Leonid Sigal, Stan Sclaroff, and Kate Saenko. Multilevel language and vision integration for text-to-clip retrieval. InAAAI Conference on Artificial Intelligence, 2019. 3, 10
2019
-
[67]
Cand `es
Yaniv Romano, Matteo Sesia, and Emmanuel J. Cand `es. Classification with valid and adaptive coverage. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. 4, 5, 9
2020
-
[68]
Mondrian confidence machine
Vladimir V ovk, David Lindsay, Ilia Nouretdinov, and Alex Gammerman. Mondrian confidence machine. InTechnical Report, Royal Holloway, University of London, 2003. 4, 5, 7, 9, 10
2003
-
[69]
Zhang, S
D. Zhang, S. Liang, T. He, J. Shao, and K. Qin. Cviformer: Cross-view interactive transformer for efficient stereoscopic image super-resolution.IEEE Transactions on Emerging Topics in Computational Intelligence, 9(2), 2024. 4
2024
-
[70]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 4
2016
-
[71]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet classification with deep convolutional neural net- works. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2012. 4
2012
-
[72]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations (ICLR), 2019. 6
2019
-
[73]
Williams
Ronald J. Williams. Simple statistical gradient-following al- gorithms for connectionist reinforcement learning.Machine Learning, 8:229–256, 1992. 6
1992
-
[74]
A corpus for reasoning about natural language grounded in photographs
Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A corpus for reasoning about natural language grounded in photographs. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2019. 7
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.