LAST-RAG: Literature-Anchored Stochastic Trajectory Retrieval-Augmented Generation for Knowledge-Conditioned Degradation Model Selection
Pith reviewed 2026-05-20 10:21 UTC · model grok-4.3
The pith
Degradation model selection for remaining useful life works better when literature evidence hierarchically conditions the candidate space alongside observed trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LAST-RAG reframes degradation model selection as a knowledge-conditioned decision-making process that integrates observed health-indicator trajectories with domain-specific theoretical and mechanical evidence retrieved from a local evidence bank; hierarchical conditioning plus Rule-based Confidence Reasoning with Uncertain State prevents premature elimination of plausible models under data scarcity or noise, producing superior classification accuracy over purely statistical baselines in simulated Wiener and gamma process families.
What carries the argument
LAST-RAG retrieval-augmented generation that anchors candidate stochastic processes to literature-derived evidence and applies hierarchical conditioning on the model space.
If this is right
- RUL distributions become more consistent with physical mechanisms when data windows are short.
- Hierarchical literature conditioning reduces selection errors in high-noise sensor environments.
- RCRUS keeps the candidate pool open until evidence accumulates, lowering early misclassification rates.
- Model selection shifts from pure goodness-of-fit optimization to evidence-augmented reasoning.
- The approach generalizes to other stochastic-process families once the evidence bank is populated.
Where Pith is reading between the lines
- The same retrieval-plus-hierarchical-conditioning pattern could be tested on other inverse problems where domain literature exists but observations are sparse.
- If the evidence bank is kept current by periodic expert review, the method may reduce the need for long calibration periods in new assets.
- Combining LAST-RAG with online updating of the evidence bank could create a self-improving loop for fleet-wide degradation monitoring.
Load-bearing premise
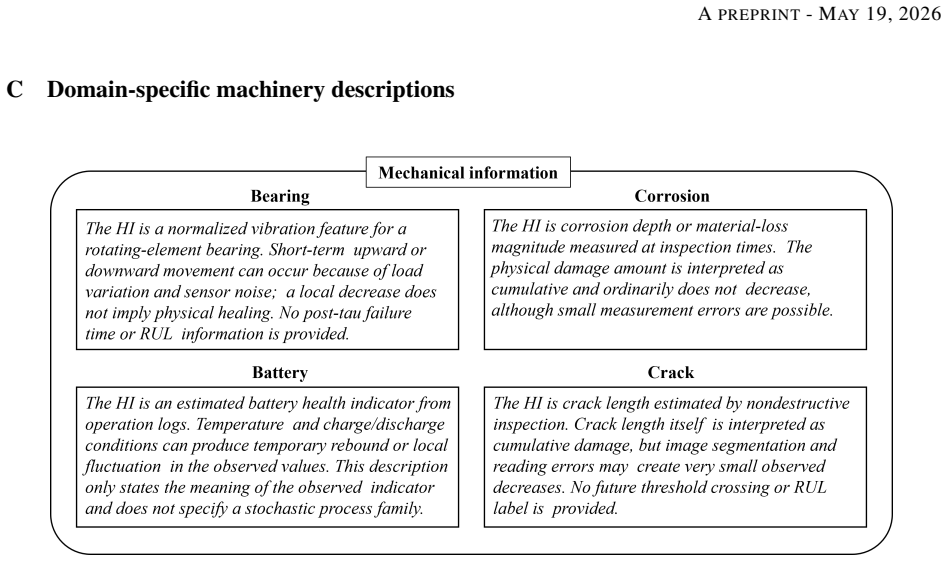
The local evidence bank must contain accurate, relevant, and up-to-date theoretical and mechanical descriptions that correctly reflect the true underlying degradation mechanism.
What would settle it
Run the method on a physical system whose degradation mechanism is independently verified by domain experts; if the selected model disagrees with the verified mechanism more often than statistical baselines despite short noisy trajectories, the claim fails.
Figures




read the original abstract
Stochastic-process-based degradation modeling is a core approach for estimating the distribution of remaining useful life (RUL); however, the selection of an appropriate stochastic process has not been sufficiently addressed. Existing model selection methods mainly rely on the statistical fit of the observed health indicator (HI) trajectory, but this approach may select a model that is inconsistent with the underlying degradation mechanism when the observation window is short or the signal is highly noisy. To address this issue, this paper proposes Literature-Anchored Stochastic Trajectory Retrieval-Augmented Generation (LAST-RAG). The proposed method uses both the observed HI trajectory and domain-specific context, and hierarchically conditions the candidate degradation model space based on theoretical and mechanical evidence retrieved from a local evidence bank. In addition, Rule-based Confidence Reasoning with Uncertain State (RCRUS) is introduced to prevent candidate models from being prematurely eliminated when hierarchical decisions are uncertain. Simulation-based experiments demonstrate that the proposed method outperforms statistical, prognostic, and uncertainty-aware baselines in both Wiener/gamma family classification and detailed degradation model classification. Ultimately, this study reframes degradation model selection from a purely statistical goodness-of-fit problem into a knowledge-conditioned decision-making problem that integrates observed data with domain knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LAST-RAG, a retrieval-augmented generation pipeline that retrieves theoretical and mechanical descriptions from a local literature evidence bank to hierarchically condition the space of candidate stochastic degradation models (Wiener/gamma family and detailed variants). It augments this with RCRUS (Rule-based Confidence Reasoning with Uncertain State) to avoid premature elimination of candidates under uncertainty, and reports simulation results claiming outperformance versus statistical, prognostic, and uncertainty-aware baselines on both family-level and detailed model classification tasks. The work reframes model selection as a knowledge-conditioned rather than purely statistical problem.
Significance. If the reported gains prove robust when the evidence bank is not perfectly aligned with simulation ground truth, the approach could improve remaining-useful-life estimation in engineering systems by reducing selection of statistically plausible but mechanistically inconsistent models. The combination of RAG with explicit uncertainty handling via RCRUS is a concrete step toward integrating domain literature into stochastic-process selection pipelines.
major comments (2)
- [§4 Experiments] §4 Experiments: the simulation protocol does not describe whether the local evidence bank was populated with excerpts chosen independently of the ground-truth mechanisms used to generate the synthetic HI trajectories. Because hierarchical conditioning and RCRUS both rely on accurate retrieval of mechanism-specific descriptions, any alignment between bank content and simulation design would confer an information advantage unavailable in real deployments; this directly affects the validity of the outperformance claim.
- [Table 3] Table 3 (detailed model classification): the reported accuracy improvements lack accompanying standard deviations across repeated simulation runs or statistical significance tests against the uncertainty-aware baseline; without these, it is impossible to determine whether the gains are stable or sensitive to particular random seeds or evidence-bank realizations.
minor comments (2)
- [§3.2] §3.2: the pseudocode for the RCRUS decision rules would benefit from an accompanying flowchart to clarify the flow of uncertain-state handling.
- [Abstract] Abstract: quantitative metrics (accuracy, F1, or confusion-matrix summaries) are absent; adding one or two headline numbers would strengthen the summary of the simulation results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and proposed revisions to improve transparency and statistical rigor in the experimental section.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments: the simulation protocol does not describe whether the local evidence bank was populated with excerpts chosen independently of the ground-truth mechanisms used to generate the synthetic HI trajectories. Because hierarchical conditioning and RCRUS both rely on accurate retrieval of mechanism-specific descriptions, any alignment between bank content and simulation design would confer an information advantage unavailable in real deployments; this directly affects the validity of the outperformance claim.
Authors: We appreciate the referee's emphasis on this critical detail of the experimental protocol. The evidence bank was constructed from general theoretical and mechanical descriptions drawn from standard literature on Wiener and gamma processes (e.g., drift-diffusion formulations and shape-scale parameterizations) without reference to the specific parameter values, trajectory lengths, or random seeds used to synthesize the HI data. To eliminate any ambiguity and strengthen the validity of the outperformance claims, we will add an explicit subsection in the revised §4 detailing the evidence bank population process, including source selection criteria and confirmation of independence from simulation ground truth. This revision will also discuss implications for real-world deployments where literature alignment may be imperfect. revision: yes
-
Referee: [Table 3] Table 3 (detailed model classification): the reported accuracy improvements lack accompanying standard deviations across repeated simulation runs or statistical significance tests against the uncertainty-aware baseline; without these, it is impossible to determine whether the gains are stable or sensitive to particular random seeds or evidence-bank realizations.
Authors: We agree that measures of variability and formal statistical testing are necessary to substantiate the robustness of the reported gains. In the revised manuscript, Table 3 will be updated to include standard deviations computed across 20 independent simulation runs for each method and metric. We will also add results from paired statistical significance tests (McNemar's test for accuracy and t-tests on performance differences) against the uncertainty-aware baseline, reporting p-values to confirm that improvements are statistically significant and not attributable to specific random seeds or evidence-bank configurations. revision: yes
Circularity Check
No circularity detected in LAST-RAG pipeline
full rationale
The paper describes LAST-RAG as a retrieval-augmented procedural pipeline that hierarchically conditions degradation model candidates using observed HI trajectories plus evidence retrieved from a local bank, with RCRUS added to handle uncertainty in decisions. No equations, closed-form derivations, or fitted parameters are presented whose outputs reduce by construction to the method's own inputs or to self-citations. The central performance claim rests on simulation experiments that compare against external baselines, rendering the result falsifiable outside any internal definition or ansatz. This is a standard self-contained methodological proposal with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain literature in the evidence bank accurately describes the true degradation physics for the systems under study.
invented entities (2)
-
LAST-RAG pipeline
no independent evidence
-
RCRUS (Rule-based Confidence Reasoning with Uncertain State)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LAST-RAG uses both the observed HI trajectory and domain-specific context, and hierarchically conditions the candidate degradation model space based on theoretical and mechanical evidence retrieved from a local evidence bank... RCRUS... prevents candidate models from being prematurely eliminated when hierarchical decisions are uncertain.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Simulation-based experiments demonstrate that the proposed method outperforms statistical, prognostic, and uncertainty-aware baselines in both Wiener/gamma family classification and detailed degradation model classification.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Xiaopeng Xi, Donghua Zhou, Maoyin Chen, Narayanaswamy Balakrishnan, and Hanwen Zhang. Remaining useful life prediction for multivariable stochastic degradation systems with non-markovian diffusion processes. Quality and Reliability Engineering International, 36(4):1402–1421, 2020
work page 2020
-
[2]
Yu Zang, Wei Shangguan, Baigen Cai, Huasheng Wang, and Michael G. Pecht. Hybrid remaining useful life prediction method. a case study on railway d-cables.Reliability Engineering & System Safety, 213:107746, 2021
work page 2021
-
[3]
Yaogang Hu, Hui Li, Pingping Shi, Zhaosen Chai, Kun Wang, Xiangjie Xie, and Zhe Chen. A prediction method for the real-time remaining useful life of wind turbine bearings based on the wiener process.Renewable Energy, 127:452–460, 2018
work page 2018
-
[4]
Zhengxin Zhang, Changhua Hu, Xiaosheng Si, Jianxun Zhang, and Jianfei Zheng. Stochastic degradation process modeling and remaining useful life estimation with flexible random-effects.Journal of the Franklin Institute, 354(6):2477–2499, 2017
work page 2017
-
[5]
Khanh Le Son, Mitra Fouladirad, Anne Barros, Eric Levrat, and Benoît Iung. Remaining useful life estimation based on stochastic deterioration models: A comparative study.Reliability Engineering & System Safety, 112:165– 175, 2013
work page 2013
-
[6]
Khanh T. P. Nguyen, Mitra Fouladirad, and Antoine Grall. Model selection for degradation modeling and prognosis with health monitoring data.Reliability Engineering & System Safety, 169:105–116, 2018
work page 2018
-
[7]
Shuyi Zhang, Qingqing Zhai, Xin Shi, and Xuejuan Liu. A wiener process model with dynamic covariate for degradation modeling and remaining useful life prediction.IEEE Transactions on Reliability, 72(1):214–223, 2023
work page 2023
-
[8]
Xiao-Sheng Si, Wenbin Wang, Chang-Hua Hu, Dong-Hua Zhou, and Michael G. Pecht. Remaining useful life estimation based on a nonlinear diffusion degradation process.IEEE Transactions on Reliability, 61(1):50–67, 2012
work page 2012
-
[9]
Yong Yu, Xiaosheng Si, Changhua Hu, Jianfei Zheng, and Jianxun Zhang. Online remaining-useful-life estima- tion with a bayesian-updated expectation-conditional-maximization algorithm and a modified bayesian-model- averaging method.Science China Information Sciences, 64(1), 2020
work page 2020
-
[10]
Ling Li, Min Liu, Weiming Shen, and Guoqing Cheng. An expert knowledge-based dynamic maintenance task assignment model using discrete stress–strength interference theory.Knowledge-Based Systems, 131:135–148, 2017
work page 2017
-
[11]
Khanh Le Son, Mitra Fouladirad, and Anne Barros. Remaining useful lifetime estimation and noisy gamma deterioration process.Reliability Engineering & System Safety, 149:76–87, 2016
work page 2016
-
[12]
Zhengxin Zhang, Xiaosheng Si, Changhua Hu, and Yaguo Lei. Degradation data analysis and remaining useful life estimation: A review on wiener-process-based methods.European Journal of Operational Research, 271(3):775– 796, 2018
work page 2018
-
[13]
Ameneh Forouzandeh Shahraki. A review on degradation modelling and its engineering applications.International Journal of Performability Engineering, 2017
work page 2017
-
[14]
Yong Yu, Changhua Hu, Xiaosheng Si, and Jianxun Zhang. Degradation data-driven remaining useful life estimation in the absence of prior degradation knowledge.Journal of Control Science and Engineering, 2017:1– 11, 2017
work page 2017
-
[15]
A novel criterion of degradation model selection for remaining life prediction, 2025/05/09 2025
Yue Zhuo, Jianxun Zhang, Lei Feng, Zhengxin Zhang, and Xiaosheng Si. A novel criterion of degradation model selection for remaining life prediction, 2025/05/09 2025
work page 2025
-
[16]
Behrad Bagheri, Maryam Rezapoor, and Jay Lee. A unified data security framework for federated prognostics and health management in smart manufacturing.Manufacturing Letters, 24:136–139, 2020
work page 2020
-
[17]
Hanbyeol Park, Sunghyun Sim, Yunkyung Park, and Hyerim Bae. Trend-fluctuation correlated attention unit for remaining useful life prediction.IEEE Access, 13:164486–164507, 2025
work page 2025
-
[18]
Dense x retrieval: What retrieval granularity should we use?, 2024
Tong Chen, Hongwei Wang, Sihao Chen, Wenhao Yu, Kaixin Ma, Xinran Zhao, Hongming Zhang, and Dong Yu. Dense x retrieval: What retrieval granularity should we use?, 2024. 14
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.