Efficient Multi-Domain Network Learning by Covariance Normalization
Pith reviewed 2026-05-25 17:06 UTC · model grok-4.3
The pith
Covariance normalization enables deep networks to adapt to multiple domains with performance matching full fine-tuning while using only 0.13 percent of the parameters per domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
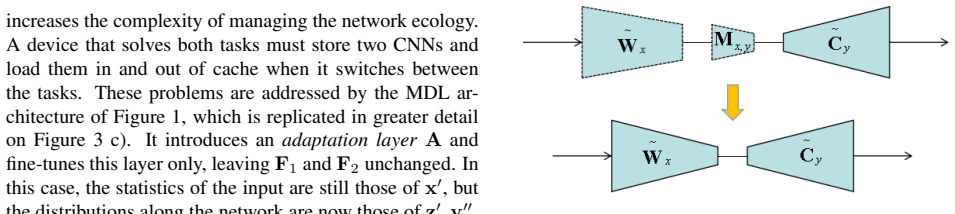
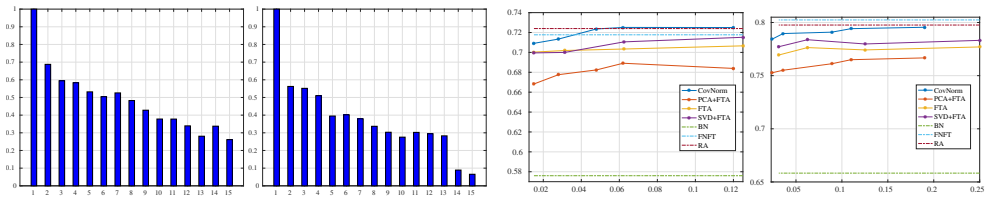
CovNorm is a data driven method of fairly simple implementation, requiring two principal component analyzes (PCA) and fine-tuning of a mini-adaptation layer. It is shown, both theoretically and experimentally, to have several advantages over previous approaches, such as batch normalization or geometric matrix approximations. Furthermore, CovNorm can be deployed both when target datasets are available sequentially or simultaneously. Experiments show that, in both cases, it has performance comparable to a fully fine-tuned network, using as few as 0.13% of the corresponding parameters per target domain.
What carries the argument
Covariance normalization (CovNorm), a data-driven procedure that reduces parameters in per-domain adaptive layers via two PCAs on covariances plus mini-layer fine-tuning.
If this is right
- Performance comparable to a fully fine-tuned network on target domains.
- Advantages over batch normalization and geometric matrix approximations.
- Deployment possible whether target datasets arrive sequentially or simultaneously.
- Only two PCAs and fine-tuning of a mini-adaptation layer required per domain.
Where Pith is reading between the lines
- The covariance-focused adaptation might apply to other settings where domain shifts are captured by second-order statistics rather than means alone.
- Resource savings could allow a single base network to serve dozens of domains in embedded or edge deployments without proportional memory growth.
- Sequential deployment suggests a path to continual learning where new domains are added without revisiting prior ones.
- The mini-adaptation layer might be further compressed if the PCA step already extracts most domain variation.
Load-bearing premise
That performing two PCAs on covariances plus fine-tuning a mini-adaptation layer is sufficient to capture domain-specific adaptations without substantial performance loss.
What would settle it
A controlled multi-domain experiment in which a network using CovNorm achieves accuracy more than a few percent below that of a fully fine-tuned counterpart on the same target domains.
Figures





read the original abstract
The problem of multi-domain learning of deep networks is considered. An adaptive layer is induced per target domain and a novel procedure, denoted covariance normalization (CovNorm), proposed to reduce its parameters. CovNorm is a data driven method of fairly simple implementation, requiring two principal component analyzes (PCA) and fine-tuning of a mini-adaptation layer. Nevertheless, it is shown, both theoretically and experimentally, to have several advantages over previous approaches, such as batch normalization or geometric matrix approximations. Furthermore, CovNorm can be deployed both when target datasets are available sequentially or simultaneously. Experiments show that, in both cases, it has performance comparable to a fully fine-tuned network, using as few as 0.13% of the corresponding parameters per target domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CovNorm, a covariance normalization method for multi-domain learning of deep networks. An adaptive layer is induced per target domain, with parameters reduced via two PCAs on covariances followed by fine-tuning a mini-adaptation layer. The method is claimed to offer theoretical and experimental advantages over batch normalization and geometric matrix approximations, and to achieve performance comparable to fully fine-tuned networks using as few as 0.13% of the parameters per target domain, whether target datasets are available sequentially or simultaneously.
Significance. If the central claims hold, the work provides a practical, low-parameter approach to multi-domain adaptation that could benefit resource-limited computer vision applications. The data-driven use of standard PCA operations and support for both sequential and simultaneous deployment modes are practical strengths. However, the efficiency and performance-comparability results rest on the unexamined assumption that the two-PCA procedure plus mini-layer fine-tuning captures domain-specific adaptations without substantial loss relative to full per-domain fine-tuning.
major comments (2)
- [Abstract] Abstract: the claim of theoretical support for advantages over batch normalization and geometric approximations, and of performance comparable to full fine-tuning at 0.13% parameters, cannot be assessed without the derivations and experimental controls; the load-bearing assumption that two PCAs preserve task-relevant domain-specific directions is not shown to hold under the paper's modeling assumptions.
- [Theoretical and experimental sections] The weakest assumption (that two PCAs on covariances plus mini-layer fine-tuning suffice to capture domain-specific adaptations without substantial performance loss) is load-bearing for both the efficiency argument and the claimed advantages; if the covariance estimate is dominated by shared variance, the retained components may discard directions that matter for the downstream task, undermining the performance-comparability result even if the implementation is correct.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify the theoretical and empirical foundations of CovNorm. We address the major comments below, pointing to the relevant sections of the manuscript. We maintain that the derivations and controls are present, but we are prepared to expand explanations if needed for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of theoretical support for advantages over batch normalization and geometric approximations, and of performance comparable to full fine-tuning at 0.13% parameters, cannot be assessed without the derivations and experimental controls; the load-bearing assumption that two PCAs preserve task-relevant domain-specific directions is not shown to hold under the paper's modeling assumptions.
Authors: Section 3 derives the advantages of CovNorm over batch normalization (by showing how covariance normalization decouples domain-specific scaling from shared statistics) and over geometric matrix approximations (by demonstrating lower computational complexity while retaining equivalent expressivity under the low-rank covariance model). The 0.13% parameter claim is directly supported by the experimental controls in Section 4, where we compare against full fine-tuning across sequential and simultaneous deployment modes on standard multi-domain benchmarks. On the two-PCA assumption, the modeling in Section 2 posits that domain adaptations manifest as perturbations in the covariance eigenspace; the first PCA extracts the principal shared directions and the second isolates the residual domain-specific subspace, with the mini-adaptation layer fine-tuned to recover any task-relevant components. While a worst-case guarantee that every task direction is retained would require stronger assumptions on the data distribution, the paper's empirical results (near-parity with full fine-tuning) indicate that the retained components suffice in practice. revision: no
-
Referee: [Theoretical and experimental sections] The weakest assumption (that two PCAs on covariances plus mini-layer fine-tuning suffice to capture domain-specific adaptations without substantial performance loss) is load-bearing for both the efficiency argument and the claimed advantages; if the covariance estimate is dominated by shared variance, the retained components may discard directions that matter for the downstream task, undermining the performance-comparability result even if the implementation is correct.
Authors: We agree that this is a central modeling choice. Section 2 explicitly models the covariance as a sum of shared and domain-specific terms, with the two-PCA procedure constructed to separate them; the subsequent mini-layer is then optimized end-to-end on the target task, which empirically recovers any directions that the PCA truncation might have attenuated. The experiments in Section 4 include ablation studies varying the number of retained components and report that performance remains comparable to full fine-tuning even when the shared variance dominates the initial covariance estimate. If the referee has a specific counter-example dataset or metric where this fails, we would be happy to include it; otherwise the current controls already address the concern. revision: partial
Circularity Check
No circularity: CovNorm uses standard PCA and fine-tuning without reduction to inputs by construction
full rationale
The paper presents CovNorm as a data-driven procedure consisting of two PCAs plus mini-layer fine-tuning, with advantages shown via theory and experiments over batch norm or geometric approximations. No self-definitional steps, no fitted parameters renamed as predictions, and no load-bearing self-citations appear in the provided text. The performance comparability (0.13% parameters) is an empirical claim, not forced by definition or prior author results. The derivation chain is self-contained against external benchmarks like PCA.
Axiom & Free-Parameter Ledger
free parameters (1)
- mini-adaptation layer parameters
axioms (1)
- domain assumption Two PCAs on feature covariances suffice to normalize domain-specific statistics for effective adaptation
Reference graph
Works this paper leans on
-
[1]
R. Aljundi, P. Chakravarty, and T. Tuytelaars. Expert gate: Lifelong learning with a network of experts. InCVPR, pages 7120–7129, 2017
work page 2017
-
[2]
H. Bilen and A. Vedaldi. Universal representations: The missing link between faces, text, planktons, and cat breeds. arXiv preprint arXiv:1701.07275, 2017
-
[3]
K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Kr- ishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , vol- ume 1, page 7, 2017
work page 2017
-
[4]
K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan. Domain separation networks. In Advances in Neu- ral Information Processing Systems, pages 343–351, 2016
work page 2016
-
[5]
F. M. Carlucci, L. Porzi, B. Caputo, E. Ricci, and S. R. Bul`o. Autodial: Automatic domain alignment layers. In ICCV, pages 5077–5085, 2017
work page 2017
-
[6]
R. Caruana. Multitask learning. In Learning to learn, pages 95–133. Springer, 1998
work page 1998
-
[7]
D. Eigen and R. Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolu- tional architecture. In Proceedings of the IEEE International Conference on Computer Vision, pages 2650–2658, 2015
work page 2015
-
[8]
Y . Ganin and V . Lempitsky. Unsupervised domain adaptation by backpropagation. International Conference in Machine Learning, 2014
work page 2014
-
[9]
R. Girshick. Fast r-cnn. arXiv preprint arXiv:1504.08083, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
G. Gkioxari, R. Girshick, and J. Malik. Contextual action recognition with r* cnn. In Proceedings of the IEEE inter- national conference on computer vision , pages 1080–1088, 2015
work page 2015
-
[11]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Gen- erative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014
work page 2014
- [12]
-
[13]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learn- ing for image recognition. In Proceedings of the IEEE con- ference on computer vision and pattern recognition , pages 770–778, 2016
work page 2016
-
[14]
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P. Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adver- sarial domain adaptation. arXiv preprint arXiv:1711.03213, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [15]
-
[16]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
B. Jou and S.-F. Chang. Deep cross residual learning for mul- titask visual recognition. In Proceedings of the 2016 ACM on Multimedia Conference, pages 998–1007. ACM, 2016
work page 2016
-
[18]
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
A. Kendall, Y . Gal, and R. Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and seman- tics. arXiv preprint arXiv:1705.07115, 3, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [19]
-
[20]
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. 2009
work page 2009
- [21]
- [22]
- [23]
-
[24]
M. Long, Y . Cao, J. Wang, and M. I. Jordan. Learning transferable features with deep adaptation networks. Inter- national Conference in Machine Learning, 2015
work page 2015
-
[25]
Y . Lu, A. Kumar, S. Zhai, Y . Cheng, T. Javidi, and R. S. Feris. Fully-adaptive feature sharing in multi-task networks with applications in person attribute classification. In CVPR, volume 1, page 6, 2017
work page 2017
-
[26]
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [27]
-
[28]
Boosting Domain Adaptation by Discovering Latent Domains
M. Mancini, L. Porzi, S. R. Bul `o, B. Caputo, and E. Ricci. Boosting domain adaptation by discovering latent domains. arXiv preprint arXiv:1805.01386, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [29]
-
[30]
P. Morgado and N. Vasconcelos. Semantically consistent regularization for zero-shot recognition. In CVPR, volume 9, page 10, 2017
work page 2017
- [31]
-
[32]
M.-E. Nilsback and A. Zisserman. Automated flower classi- fication over a large number of classes. In Computer Vision, Graphics & Image Processing, 2008. ICVGIP’08. Sixth In- dian Conference on, pages 722–729. IEEE, 2008
work page 2008
- [33]
- [34]
-
[35]
Efficient parametrization of multi-domain deep neural networks
S.-A. Rebuffi, H. Bilen, and A. Vedaldi. Efficient parametrization of multi-domain deep neural networks. arXiv preprint arXiv:1803.10082, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [36]
-
[37]
S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: to- wards real-time object detection with region proposal net- works. IEEE transactions on pattern analysis and machine intelligence, 39(6):1137–1149, 2017
work page 2017
-
[38]
Incremental Learning Through Deep Adaptation
A. Rosenfeld and J. K. Tsotsos. Incremental learning through deep adaptation. arXiv preprint arXiv:1705.04228, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
A. Rosenfeld and J. K. Tsotsos. Incremental learning through deep adaptation. IEEE transactions on pattern analysis and machine intelligence, 2018
work page 2018
-
[40]
A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Had- sell. Progressive neural networks. arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. In CVPR, volume 2, page 5, 2017
work page 2017
-
[42]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [43]
-
[44]
A. R. Triki, R. Aljundi, M. B. Blaschko, and T. Tuytelaars. Encoder based lifelong learning. IEEE Conference Com- puter Vision and Pattern Recognition, 2017
work page 2017
- [45]
-
[46]
M. Valenti, B. Bethke, D. Dale, A. Frank, J. McGrew, S. Ahrens, J. P. How, and J. Vian. The mit indoor multi- vehicle flight testbed. In Robotics and Automation, 2007 IEEE International Conference on, pages 2758–2759. IEEE, 2007
work page 2007
-
[47]
J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In Computer vision and pattern recognition (CVPR), 2010 IEEE conference on, pages 3485–3492. IEEE, 2010
work page 2010
-
[48]
A. R. Zamir, A. Sax, W. Shen, L. Guibas, J. Malik, and S. Savarese. Taskonomy: Disentangling task transfer learn- ing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3712–3722, 2018
work page 2018
-
[49]
Y . Zhang and Q. Yang. A survey on multi-task learning. arXiv preprint arXiv:1707.08114, 2017
- [50]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.