Less is More: Geometric Unlearning for LLMs with Minimal Data Disclosure
Pith reviewed 2026-05-10 15:58 UTC · model grok-4.3
The pith
Geometric Unlearning lets LLMs forget specific private facts using only a handful of synthetic prompts while retaining general performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that Geometric Unlearning operates directly on prompt-time planning states by first distilling a low-rank geometry of desired safe behavior from a small set of safe reference prompts, then applying projection-based alignment of hidden representations using synthetic in-context anchors, together with a teacher-distillation regularizer on non-target anchors, to suppress target information without access to the original training corpus.
What carries the argument
Geometric Unlearning (GU): extraction of a compact low-rank safe-behavior geometry from reference prompts followed by projection alignment of hidden planning states via synthetic anchors.
If this is right
- Strong suppression of target entities is achieved on ToFU and UnlearnPII benchmarks without original training data.
- Non-target performance remains largely intact when alignment uses only minimal synthetic prompts.
- Localized projection on hidden states avoids the broad gradient updates common in prior methods.
- A teacher-distillation regularizer on synthetic non-target anchors limits collateral drift during unlearning.
Where Pith is reading between the lines
- The same low-rank alignment idea could be tested on unlearning tasks in non-language models such as vision or multimodal systems.
- Organizations handling regulated data might adopt this approach to meet deletion requests without maintaining full training archives.
- If the safe geometry remains stable across model scales, the method could support repeated unlearning cycles on the same base model.
Load-bearing premise
A low-rank geometry distilled from a few safe prompts can be projected onto hidden states to suppress chosen target information without broad utility loss or access to the original data.
What would settle it
Run the method on a model in which target facts are deliberately entangled across many dimensions in the hidden states; if target suppression fails or non-target accuracy drops sharply, the geometric alignment approach does not hold.
Figures




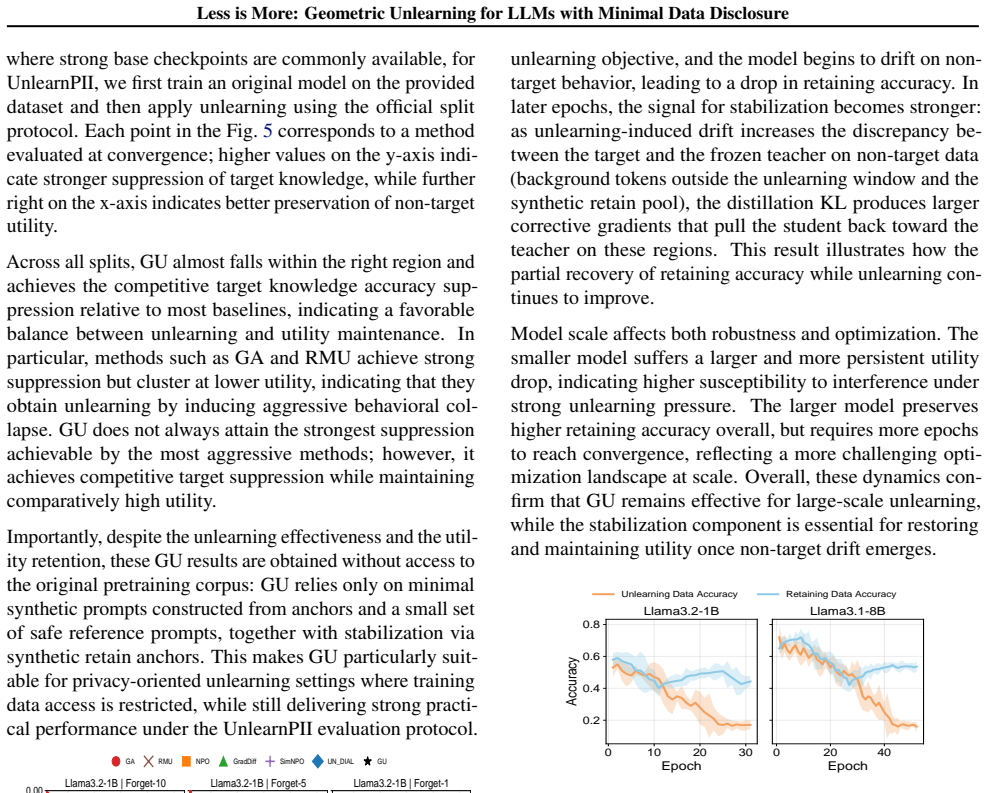
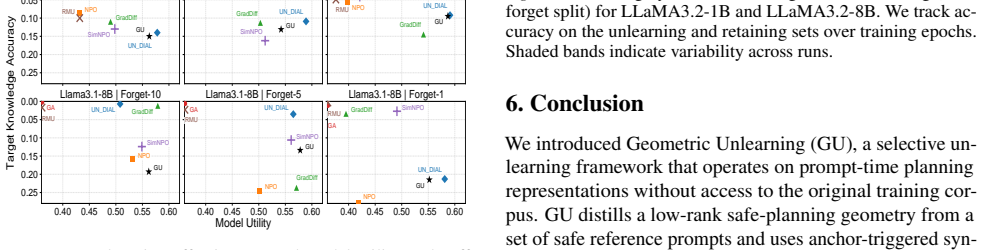
read the original abstract
As large language models (LLMs) are increasingly deployed in real-world systems, they must support post-hoc removal of specific content to meet privacy and governance requirements. This motivates selective unlearning, which suppresses information about a particular entity or topic while preserving the LLM's general utility. However, most existing LLM unlearning methods require access to the original training corpus and rely on output-level refusal tuning or broad gradient updates, creating a tension among unlearning strength, non-target preservation, and data availability. We propose Geometric Unlearning (GU), an approach that operates directly on the model's prompt-conditioned hidden states without access to the original training corpus. Specifically, GU distills a compact, low-rank safe-behavior subspace from a small set of safe reference prompts and uses lightweight anchor-in-context synthetic prompts to trigger localized, projection-based alignment of hidden representations to this safe subspace. A teacher-distillation regularizer on synthetic non-target anchors further reduces collateral drift. Across privacy-oriented unlearning benchmarks (ToFU and UnlearnPII), GU achieves strong target suppression with minimal impact on non-target performance, demonstrating that effective unlearning can be achieved with minimal synthetic data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Geometric Unlearning (GU) for selective unlearning in LLMs. GU distills a compact low-rank geometry of safe behavior from a small set of safe reference prompts and performs projection-based alignment of hidden planning states using lightweight anchor-in-context synthetic prompts, plus a teacher-distillation regularizer on non-target anchors. The method requires no access to the original training corpus. On the ToFU and UnlearnPII privacy benchmarks, GU is reported to achieve strong target suppression while preserving non-target performance, using only minimal synthetic data.
Significance. If the central geometric alignment mechanism is shown to reliably remove target encodings from hidden states, the work would be significant for practical LLM governance. It reduces reliance on original data and broad updates, offering a data-efficient alternative to existing unlearning techniques. The emphasis on low-rank distillation and synthetic anchors could influence future privacy-preserving methods, provided the approach generalizes beyond output-level metrics.
major comments (2)
- [§3] §3 (Geometric Unlearning procedure): The core claim that projection onto the distilled low-rank safe geometry suppresses target information encoded during original training is load-bearing, yet the manuscript provides no hidden-state probing, membership-inference, or subspace analysis to confirm that target signals are removed rather than merely masked at the output level. Without such verification, residual encodings in orthogonal subspaces cannot be ruled out.
- [§4] §4 (Benchmark evaluation): Results on ToFU and UnlearnPII report strong target suppression with minimal non-target degradation, but the evaluation relies on output accuracy and refusal metrics. No ablation isolating the contribution of the low-rank projection versus the synthetic anchors or regularizer is presented, making it difficult to attribute success specifically to the geometric component.
minor comments (2)
- [§3.1] The notation for the projection operator and the rank parameter in the low-rank geometry distillation should be defined more explicitly, ideally with a small illustrative equation.
- [Figure 1] Figure captions for the method overview diagram could more clearly label the flow from safe prompts to anchor alignment and the role of the teacher regularizer.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will incorporate revisions to strengthen the empirical support for the geometric mechanism.
read point-by-point responses
-
Referee: [§3] §3 (Geometric Unlearning procedure): The core claim that projection onto the distilled low-rank safe geometry suppresses target information encoded during original training is load-bearing, yet the manuscript provides no hidden-state probing, membership-inference, or subspace analysis to confirm that target signals are removed rather than merely masked at the output level. Without such verification, residual encodings in orthogonal subspaces cannot be ruled out.
Authors: We agree that direct verification of hidden-state suppression is important for substantiating the central mechanism. While the method explicitly aligns planning states via projection and the output-level results on ToFU and UnlearnPII demonstrate effective target suppression with preserved utility, we acknowledge the absence of internal analysis. In the revision we will add hidden-state probing, membership-inference attacks on the target subspace, and before/after subspace overlap metrics to show that target encodings are reduced rather than merely masked at the output. revision: yes
-
Referee: [§4] §4 (Benchmark evaluation): Results on ToFU and UnlearnPII report strong target suppression with minimal non-target degradation, but the evaluation relies on output accuracy and refusal metrics. No ablation isolating the contribution of the low-rank projection versus the synthetic anchors or regularizer is presented, making it difficult to attribute success specifically to the geometric component.
Authors: We thank the referee for highlighting the need for component-wise attribution. The current results show the full pipeline works with minimal data, but we agree that isolating the low-rank projection is necessary. In the revised manuscript we will include ablations that remove or replace the projection step (while retaining anchors and regularizer) and report the resulting changes in target suppression and non-target performance on both benchmarks. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes Geometric Unlearning as a new method that distills a low-rank safe geometry from a small set of reference prompts and performs projection-based alignment on hidden states using synthetic anchors, with a teacher-distillation regularizer. All load-bearing steps (geometry distillation, projection alignment, and regularizer) are defined from first principles and external synthetic data rather than fitted to target outcomes or reduced to self-citations. Empirical results on ToFU and UnlearnPII are independent external benchmarks, not constructed by definition from the method inputs. No self-definitional, fitted-prediction, or uniqueness-imported circularity is present in the described chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The internal hidden states of LLMs during prompt processing contain planning representations that can be aligned geometrically to achieve unlearning.
invented entities (2)
-
low-rank geometry of desired safe behavior
no independent evidence
-
anchor-in-context synthetic prompts
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.