Revisiting Structural Dependency in Autoregressive Multi-Task Table Recognition via Order-Independent Cell-Level Representations
Pith reviewed 2026-06-27 01:42 UTC · model grok-4.3
The pith
Non-causal attention produces order-independent cell features for table recognition
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
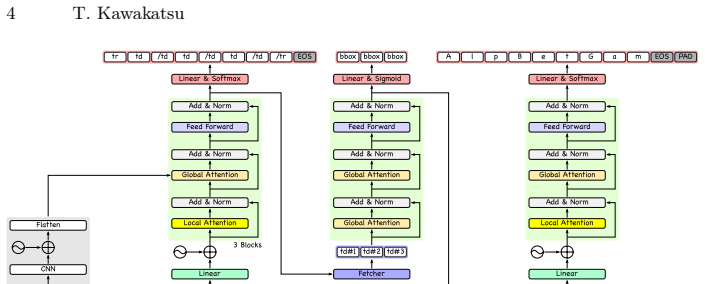
The structural refinement module produces order-independent cell features through non-causal attention. This enables parallel inference of cell contents while conditioning each cell on global context encoded in the refined features, yielding consistent gains in cell localization and end-to-end recognition while reducing overall inference time by around threefold.
What carries the argument
The structural refinement module, which generates order-independent cell features via non-causal attention to allow global context conditioning without sequential dependencies.
If this is right
- Consistent improvements in cell localization accuracy.
- Better end-to-end recognition results on large datasets.
- Reduction in inference time by a factor of about three.
- Support for parallel cell content inference.
Where Pith is reading between the lines
- The technique may help other autoregressive models in vision tasks that require consistent structured outputs.
- By making representations order-independent, it could improve robustness when table structures vary in complexity.
Load-bearing premise
Order dependence in autoregressive generation is the main source of inconsistent cell representations, and non-causal attention can supply the required structural information without new problems.
What would settle it
If experiments controlling for generation order in the original autoregressive setup show similar consistency gains, or if the new module causes accuracy drops on tables with specific structures.
Figures


read the original abstract
Multi-task table recognition jointly addresses table structure prediction, cell localization, and cell content recognition within a unified framework. Existing approaches often rely on autoregressive decoders to generate table structures and reuse their hidden states for cell localization and content recognition. This autoregressive generation process can make cell representations order-dependent, degrading global consistency across cells. This paper proposes a structural refinement module that produces order-independent cell features through non-causal attention. This design enables parallel inference of cell contents while conditioning each cell on global context encoded in the refined features. Experiments on two large datasets demonstrate consistent gains in cell localization and end-to-end recognition, while reducing overall inference time by around threefold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive decoders in multi-task table recognition produce order-dependent cell representations that degrade global consistency; it introduces a structural refinement module using non-causal attention to generate order-independent cell features, enabling parallel cell-content inference while conditioning on global context, and reports consistent gains in cell localization and end-to-end recognition plus ~3x faster inference on two large datasets.
Significance. If the empirical gains are robustly demonstrated with proper controls, the approach could meaningfully advance table recognition by decoupling inference order from structural consistency, offering both accuracy and efficiency benefits in a domain where global table relations are critical. The design directly targets a known limitation of autoregressive models without requiring changes to the core decoder.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): the claim of 'consistent gains' in cell localization and end-to-end recognition is presented without any information on the baselines compared against, statistical tests, ablation studies isolating the refinement module, or error bars; this information is load-bearing for validating the central empirical claim that the module improves performance.
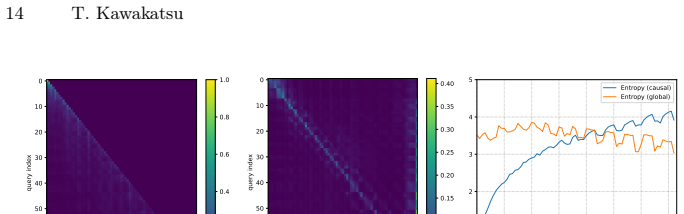
- [§3] §3 (Structural Refinement Module): the description does not clarify whether the non-causal attention operates purely on unordered cell embeddings or is conditioned on already-generated structure tokens; without this, it is unclear whether directed relations (row/column ordering, spanning cells) are preserved or whether new inconsistencies are introduced when the refined features are used for localization and recognition.
minor comments (1)
- [Abstract] The abstract states inference time is reduced 'by around threefold' but provides no breakdown of which components contribute to the speedup or measurements under identical hardware conditions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for strengthening the empirical validation and technical clarity of the structural refinement module. We address each point below and have revised the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the claim of 'consistent gains' in cell localization and end-to-end recognition is presented without any information on the baselines compared against, statistical tests, ablation studies isolating the refinement module, or error bars; this information is load-bearing for validating the central empirical claim that the module improves performance.
Authors: We agree that the current presentation of results in the abstract and §4 is insufficient to fully substantiate the claims. The full experimental section does compare against standard autoregressive baselines (e.g., the original multi-task model without refinement), but we did not report error bars, statistical tests, or dedicated ablations isolating the non-causal attention component. In the revised manuscript we will: (1) explicitly list all baselines with citations, (2) add error bars from 3–5 random seeds, (3) include an ablation table removing only the refinement module while keeping all other components fixed, and (4) report paired t-test p-values for the observed gains. These additions will appear in §4 and the abstract will be updated to reference the controlled evaluation. revision: yes
-
Referee: [§3] §3 (Structural Refinement Module): the description does not clarify whether the non-causal attention operates purely on unordered cell embeddings or is conditioned on already-generated structure tokens; without this, it is unclear whether directed relations (row/column ordering, spanning cells) are preserved or whether new inconsistencies are introduced when the refined features are used for localization and recognition.
Authors: The non-causal attention is applied after the autoregressive decoder has produced the full set of structure tokens; the cell embeddings are therefore conditioned on the already-generated (ordered) structure sequence. The refinement module then performs bidirectional attention over these conditioned embeddings to remove residual order dependence among cells while retaining the global structural context. Directed relations such as row/column ordering and spanning are preserved because they are encoded in the conditioning tokens and are not altered by the refinement. We will expand §3 with an explicit statement of this conditioning flow, add a small diagram showing the data path (structure tokens → cell embeddings → non-causal refinement), and include a short analysis confirming that no new inconsistencies are introduced (measured by structure F1 before/after refinement). revision: yes
Circularity Check
No circularity: claims rest on architectural design and empirical results without reductions to inputs by construction
full rationale
The paper's core proposal is a structural refinement module using non-causal attention to generate order-independent cell features from autoregressive decoder outputs. This is presented as an architectural change enabling parallel inference and global context conditioning, with reported gains validated on external datasets. No equations, parameter fits, self-citations, or uniqueness theorems are described that would make the order-independence or performance improvements equivalent to the inputs by definition. The derivation chain remains self-contained against external benchmarks, as the refinement step is a distinct module whose effects are measured empirically rather than forced by prior definitions or fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive generation of table structure produces order-dependent cell representations that degrade global consistency.
invented entities (1)
-
Structural refinement module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Machine Learning (ICML)
Deng, Y., Kanervisto, A., Ling, J., Rush, A.M.: Image-to-markup generation with coarse-to-fine attention. In: International Conference on Machine Learning (ICML). vol. 70, pp. 980–989 (2017)
2017
-
[2]
In: International Conference on Document Analysis and Recognition (ICDAR)
Deng, Y., Rosenberg, D., Mann, G.: Challenges in end-to-end neural scientific table recognition. In: International Conference on Document Analysis and Recognition (ICDAR). pp. 894–901 (2019). https://doi.org/10.1109/ICDAR.2019.00148
-
[3]
Huang, Y., Lu, N., Chen, D., Li, Y., Xie, Z., Zhu, S., Gao, L., Peng, W.: Improving table structure recognition with visual-alignment sequential coordinate modeling. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11134–11143 (2023). https://doi.org/10.1109/CVPR52729.2023.01071
-
[4]
In: International Conference on Document Analysis and Recognition (ICDAR)
Itonori, K.: Table structure recognition based on textblock arrangement and ruled line position. In: International Conference on Document Analysis and Recognition (ICDAR). pp. 765–768 (1993). https://doi.org/10.1109/ICDAR.1993.395625
-
[5]
In: Document Analysis and Recognition - ICDAR
Kawakatsu, T.: Multi-cell decoder and mutual learning for table structure and character recognition. In: Document Analysis and Recognition - ICDAR
-
[6]
pp. 389–405. Springer Nature Switzerland (2024). https://doi.org/10.1007/ 978-3-031-70533-5_23
2024
-
[7]
In: Photonics West ’98 Electronic Imaging
Kieninger, T.G.: Table structure recognition based on robust block segmentation. In: Photonics West ’98 Electronic Imaging. vol. 3305, pp. 22–32 (1998). https: //doi.org/10.1117/12.304642
-
[8]
In: Computer Vision – ECCV 2022
Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., Hwang, W., Yun, S., Han, D., Park, S.: OCR-free document understanding transformer. In: Computer Vision – ECCV 2022. pp. 498–517 (2022). https://doi.org/10.1007/978-3-031-19815-1_29
-
[9]
In: 40th International Conference on Machine Learning (2023)
Lee, K., Joshi, M., Turc, I., Hu, H., Liu, F., Eisenschlos, J., Khandelwal, U., Shaw, P., Chang, M.W., Toutanova, K.: Pix2struct: Screenshot parsing as pretraining for visual language understanding. In: 40th International Conference on Machine Learning (2023)
2023
-
[10]
In: 29th ACM International Conference on Multimedia
Liu, H., Li, X., Liu, B., Jiang, D., Liu, Y., Ren, B., Ji, R.: Show, read and rea- son: Table structure recognition with flexible context aggregator. In: 29th ACM International Conference on Multimedia. pp. 1084–1092 (2021). https://doi.org/ 10.1145/3474085.3481534
-
[11]
In: International Conference on Document Analysis and Recognition (IC- DAR)
Ly, N.T., Takasu, A.: An end-to-end local attention based model for table recog- nition. In: International Conference on Document Analysis and Recognition (IC- DAR). pp. 20–36 (2023). https://doi.org/10.1007/978-3-031-41679-8_2
-
[12]
Ly, N.T., Takasu, A.: An end-to-end multi-task learning model for image-based table recognition. In: International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP). pp. 626–634 (2023). https://doi.org/10.5220/0011685000003417
-
[13]
In: International Conference on Pattern Recognition Applications and Methods (ICPRAM)
Ly, N.T., Takasu, A., Nguyen, P., Takeda, H.: Rethinking image-based table recognition using weakly supervised methods. In: International Conference on Pattern Recognition Applications and Methods (ICPRAM). pp. 872–880 (2023). https://doi.org/10.5220/0011682600003411
-
[14]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Nassar, A., Livathinos, N., Lysak, M., Staar, P.: TableFormer: Table structure understanding with transformers. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4604–4613 (2022). https://doi.org/10.1109/ CVPR52688.2022.00457
arXiv 2022
-
[15]
Kawakatsu
OpenMMLab: MMOCR, https://github.com/open-mmlab/mmocr 16 T. Kawakatsu
-
[16]
In: IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops (CVPRW)
Prasad, D., Gadpal, A., Kapadni, K., Visave, M., Sultanpure, K.: CascadeTab- Net: An approach for end to end table detection and structure recognition from image-based documents. In: IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops (CVPRW). pp. 2439–2447 (2020). https://doi.org/10. 1109/CVPRW50498.2020.00294
arXiv 2020
-
[17]
In: International Conference on Document Analysis and Recogni- tion (ICDAR)
Qiao, L., Li, Z., Cheng, Z., Zhang, P., Pu, S., Niu, Y., Ren, W., Tan, W., Wu, F.: LGPMA: Complicated table structure recognition with local and global pyramid mask alignment. In: International Conference on Document Analysis and Recogni- tion (ICDAR). pp. 99–114 (2021). https://doi.org/10.1007/978-3-030-86549-8_7
-
[18]
Raja, S., Mondal, A., Jawahar, C.V.: Table structure recognition using top-down and bottom-up cues. In: Computer Vision – ECCV. pp. 70–86 (2020). https://doi. org/10.1007/978-3-030-58604-1_5
-
[19]
Raja, S., Mondal, A., Jawahar, C.V.: Visual understanding of complex table struc- tures from document images. In: IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 2543–2552 (2022). https://doi.org/10.1109/WACV51458. 2022.00260
-
[20]
In: Interna- tional Conference on Document Analysis and Recognition (ICDAR)
Schreiber, S., Agne, S., Wolf, I., Dengel, A., Ahmed, S.: DeepDeSRT: Deep learning for detection and structure recognition of tables in document images. In: Interna- tional Conference on Document Analysis and Recognition (ICDAR). pp. 1162–1167 (2017). https://doi.org/10.1109/ICDAR.2017.192
-
[21]
Wan, J., Song, S., Yu, W., Liu, Y., Cheng, W., Huang, F., Bai, X., Yao, C., Yang, Z.: OmniParser: A unified framework for text spotting, key information extraction and table recognition. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15641–15653 (2024). https://doi.org/10.1109/CVPR52733.2024. 01481
-
[22]
Pattern Recognition37(7), 1479–1497 (2004)
Wang, Y., Phillips, I.T., Haralick, R.M.: Table structure understanding and its performance evaluation. Pattern Recognition37(7), 1479–1497 (2004)
2004
-
[23]
Wright,L.:Ranger-asynergisticoptimizer(2019),https://github.com/lessw2020/ Ranger-Deep-Learning-Optimizer
2019
-
[24]
https://doi.org/10.48550/arXiv.2105.01848
Ye, J., Qi, X., He, Y., Chen, Y., Gu, D., Gao, P., Xiao, R.: PingAn-VCGroup’s solution for ICDAR 2021 competition on scientific literature parsing task B: Table recognition to HTML (2021). https://doi.org/10.48550/arXiv.2105.01848
-
[25]
In: International Conference on Document Analysis and Recognition (ICDAR)
Yepes, A.J., Zhong, P., Burdick, D.: ICDAR 2021 competition on scientific litera- ture parsing. In: International Conference on Document Analysis and Recognition (ICDAR). pp. 605–617 (2021). https://doi.org/10.1007/978-3-030-86337-1_40
-
[26]
Pattern Recognition126, 108565 (2022)
Zhang, Z., Zhang, J., Du, J., Wang, F.: Split, embed and merge: An accurate table structure recognizer. Pattern Recognition126, 108565 (2022). https://doi.org/10. 1016/j.patcog.2022.108565
arXiv 2022
-
[27]
In: 38th International Conference on Neural Information Processing Systems (2024)
Zhao, W., Feng, H., Liu, Q., Tang, J., Wei, S., Wu, B., Liao, L., Ye, Y., Liu, H., Zhou, W., Li, H., Huang, C.: TabPedia: Towards comprehensive visual table understanding with concept synergy. In: 38th International Conference on Neural Information Processing Systems (2024)
2024
-
[28]
In: Computer Vision – ECCV 2022
Zhao, W., Gao, L.: CoMER: Modeling coverage for transformer-based handwritten mathematical expression recognition. In: Computer Vision – ECCV 2022. pp. 392– 408 (2022). https://doi.org/10.1007/978-3-031-19815-1_23
-
[29]
In: IEEE Winter Conference on Applications of Computer Vision (WACV)
Zheng, X., Burdick, D., Popa, L., Zhong, X., Wang, N.X.R.: Global table extractor (GTE): A framework for joint table identification and cell structure recognition using visual context. In: IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 697–706 (2021). https://doi.org/10.1109/WACV48630.2021. 00074 Structural Dependency in Autoregress...
-
[30]
Zhong, X., ShafieiBavani, E., Yepes, A.J.: Image-based table recognition: Data, model, and evaluation. In: Computer Vision – ECCV. pp. 564–580 (2020). https: //doi.org/10.1007/978-3-030-58589-1_34
-
[31]
In: Pattern Recognition and Computer Vision
Zhu, Z., Zhao, W., Gao, L.: Enhancing transformer-based table structure recog- nition for long tables. In: Pattern Recognition and Computer Vision. pp. 216–230 (2025). https://doi.org/10.1007/978-981-97-8511-7_16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.