GeoMix: Descriptor-Free Visual Localization via Global Context and Multi-Detector Training
Pith reviewed 2026-07-03 14:42 UTC · model grok-4.3
The pith
GeoMix closes much of the accuracy gap in descriptor-free visual localization by adding global context and training across multiple keypoint detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
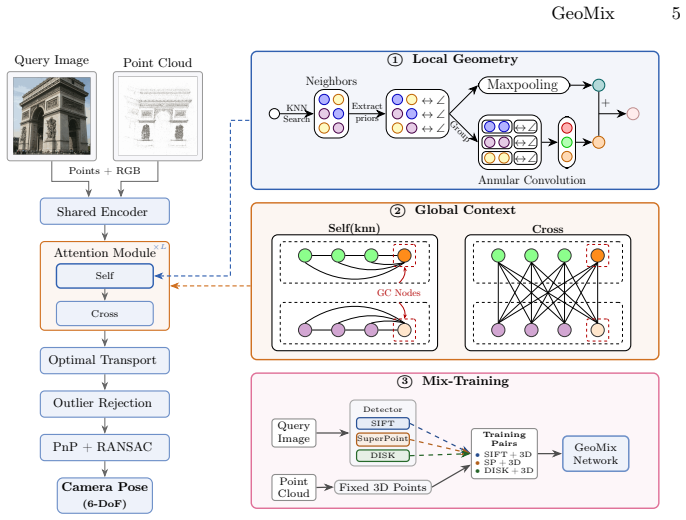
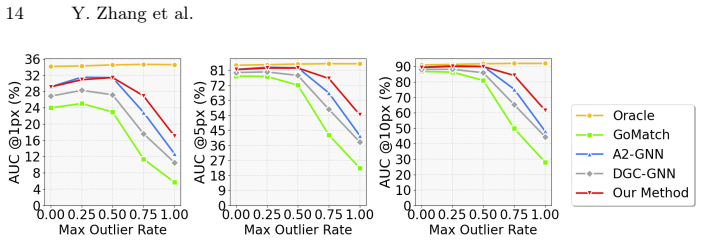
GeoMix is a descriptor-free 2D-3D matching framework that strengthens geometric discriminability at three levels: locally with directional and distance-aware embeddings for neighborhood aggregation, globally with learnable context nodes that aggregate scene-wide information via cross-attention, and at training time with Mix-Training that exploits the detector-agnostic geometry space to optimize representations across multiple keypoint detectors. On MegaDepth, Cambridge Landmarks, 7Scenes, and Aachen Day-Night this yields state-of-the-art results among descriptor-free methods, cutting 75th-percentile rotation error by 89 percent and translation error by up to 90 percent while generalizing zer
What carries the argument
Mix-Training, which jointly optimizes heterogeneous keypoints from multiple detectors inside a single shared geometry-only embedding space, augmented by local directional embeddings and global learnable context nodes with cross-attention.
If this is right
- 75th-percentile rotation error drops by 89 percent and translation error by up to 90 percent versus the prior best descriptor-free baseline.
- The learned representations generalize zero-shot to keypoint detectors never seen during training.
- The performance gap to descriptor-based localization pipelines narrows while still avoiding high-dimensional descriptor storage.
- Scene privacy is preserved and map maintenance is simplified because no appearance descriptors are required.
Where Pith is reading between the lines
- Structure-from-motion or other geometry-only pipelines could adopt similar multi-detector training to reduce dependence on any single keypoint detector.
- Detector choice may become less critical once a shared geometry space is learned, potentially allowing systems to pick detectors based on speed or robustness alone.
- The same global context nodes might help resolve ambiguities in other sparse matching tasks that currently rely only on local neighborhoods.
Load-bearing premise
Keypoints produced by different detectors share enough common geometric structure that they can be trained together in one embedding space without descriptor alignment or detector-specific adaptations.
What would settle it
If single-detector training on the same data produces equal or lower pose error than multi-detector Mix-Training, or if the trained model fails to match performance on a completely new keypoint detector type.
Figures





read the original abstract
Descriptor-free visual localization eliminates high-dimensional descriptor storage, preserves scene privacy, and simplifies map maintenance, yet its accuracy still lags far behind descriptor-based pipelines. We identify this gap to insufficient geometric discriminability in geometry-only matching. Without visual appearance, current methods underutilize local geometry cues, lack the global context among keypoints, and overfit to a single keypoint detector. We further observe that descriptor-free matching naturally enables multi-detector training, as heterogeneous keypoints can be optimized in a shared geometry-only space without aligning descriptor spaces. Building on these insights, we propose GeoMix, a descriptor-free 2D-3D matching framework that strengthens geometric discriminability at three levels. Locally, directional and distance-aware embeddings enrich neighborhood aggregation with fine-grained spatial structure. Globally, learnable context nodes aggregate and redistribute scene-wide information via cross-attention to resolve ambiguities beyond local receptive fields. At the training level, Mix-Training exploits this detector-agnostic geometry space to learn representations across multiple keypoint detectors. Extensive experiments on MegaDepth, Cambridge Landmarks, 7Scenes, and Aachen Day-Night show that GeoMix sets a new state of the art among descriptor-free methods, reducing 75th-percentile rotation error by 89\% and translation error by up to 90\% over the previous best, while generalizing zero-shot to unseen detectors and narrowing the gap to descriptor-based pipelines. Code is available at $\href{https://github.com/YejunZhang/Geomix}{\text{this links}}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoMix, a descriptor-free 2D-3D matching framework for visual localization. It strengthens geometric discriminability via local directional/distance-aware embeddings for neighborhood aggregation, global learnable context nodes that use cross-attention to incorporate scene-wide information, and Mix-Training that jointly optimizes heterogeneous keypoints from multiple detectors in a shared geometry-only embedding space. Experiments on MegaDepth, Cambridge Landmarks, 7Scenes, and Aachen Day-Night report new state-of-the-art results among descriptor-free methods, with 75th-percentile rotation error reduced by 89% and translation error by up to 90% relative to prior best, plus zero-shot generalization to unseen detectors and a narrowed gap to descriptor-based pipelines.
Significance. If the empirical claims hold after verification of ablations and generalization, the work would be significant for descriptor-free localization: it directly addresses the accuracy gap with descriptor-based methods while preserving advantages in storage, privacy, and map maintenance. The multi-detector training strategy, if shown to produce detector-agnostic representations, represents a practical advance over single-detector approaches.
major comments (2)
- [Abstract] Abstract: The central claim of zero-shot generalization to unseen detectors rests on the assertion that 'descriptor-free matching naturally enables multi-detector training' in a shared geometry-only space without alignment or detector-specific adaptations. However, the manuscript provides no explicit mechanism (e.g., invariance loss, detector-identity masking, or distribution matching) to enforce detector-agnostic embeddings, leaving open the possibility that reported gains reflect detector-specific biases in keypoint distributions rather than the architecture.
- [Abstract] Abstract and experimental claims: The reported 89% and 90% reductions in 75th-percentile rotation and translation errors are load-bearing for the SOTA conclusion, yet the abstract does not reference ablations isolating the contribution of local embeddings, global context nodes, or Mix-Training, nor does it report error bars or statistical tests. Without these, it is unclear whether the gains are robust or attributable to data selection or baseline implementation details.
minor comments (1)
- [Abstract] The abstract mentions 'Code is available at this links' but the hyperlink text is incomplete; ensure the repository link is functional and includes the exact training and evaluation scripts used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of zero-shot generalization to unseen detectors rests on the assertion that 'descriptor-free matching naturally enables multi-detector training' in a shared geometry-only space without alignment or detector-specific adaptations. However, the manuscript provides no explicit mechanism (e.g., invariance loss, detector-identity masking, or distribution matching) to enforce detector-agnostic embeddings, leaving open the possibility that reported gains reflect detector-specific biases in keypoint distributions rather than the architecture.
Authors: The manuscript argues that the purely geometric nature of the matching task (operating on positions, directions, and distances without appearance descriptors) inherently permits joint optimization across detectors in a shared space, as no descriptor alignment is required. This architectural property is presented as the enabling mechanism, with empirical support from the zero-shot generalization results to unseen detectors. We acknowledge that additional explicit regularizers could further strengthen the claim and will expand the discussion of this design choice in the methods section of the revision. revision: partial
-
Referee: [Abstract] Abstract and experimental claims: The reported 89% and 90% reductions in 75th-percentile rotation and translation errors are load-bearing for the SOTA conclusion, yet the abstract does not reference ablations isolating the contribution of local embeddings, global context nodes, or Mix-Training, nor does it report error bars or statistical tests. Without these, it is unclear whether the gains are robust or attributable to data selection or baseline implementation details.
Authors: Abstracts are concise by nature and highlight the main results; the full manuscript provides ablations in the experiments section that isolate the contributions of local directional embeddings, global context nodes, and Mix-Training. The error reductions are obtained under standard benchmark protocols on multiple datasets. We agree that reporting error bars would improve transparency and will add them to the revised manuscript or supplementary material. revision: partial
Circularity Check
No circularity: empirical engineering contribution with external validation
full rationale
The paper presents GeoMix as an empirical architecture (local directional embeddings, global context nodes via cross-attention, and multi-detector Mix-Training) whose performance claims rest on benchmark results (MegaDepth, Cambridge Landmarks, 7Scenes, Aachen) rather than any closed-form derivation or first-principles reduction. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the zero-shot generalization claim is asserted as a consequence of the detector-agnostic geometry space but is not derived by construction from the inputs. This is the normal case of a methods paper whose central results are externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks trained on geometry-only inputs can learn representations that generalize across different keypoint detectors without descriptor alignment.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Fully Geometric Panoramic Localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[2]
Advances in Neural Information Processing Systems , year=
LoD-Loc: Aerial Visual Localization using LoD 3D Map with Neural Wireframe Alignment , author=. Advances in Neural Information Processing Systems , year=
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Superglue: Learning feature matching with graph neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Lightglue: Local feature matching at light speed , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
LoFTR: Detector-free local feature matching with transformers , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Wang, Shuzhe and Kannala, Juho and Barath, Daniel , booktitle=
-
[7]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
Predator: Registration of 3d point clouds with low overlap , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[8]
European Conference on Computer Vision , pages=
Is geometry enough for matching in visual localization? , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[9]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[10]
Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part II 16 , pages=
Solving the blind perspective-n-point problem end-to-end with robust differentiable geometric optimization , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part II 16 , pages=. 2020 , organization=
2020
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Progressive correspondence pruning by consensus learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Geometric transformer for fast and robust point cloud registration , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Are large-scale 3d models really necessary for accurate visual localization? , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
From coarse to fine: Robust hierarchical localization at large scale , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[15]
Vision Research Lab, University of California, Santa Barbara , year=
RANSAC for Dummies , author=. Vision Research Lab, University of California, Santa Barbara , year=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
How privacy-preserving are line clouds? recovering scene details from 3d lines , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Privacy Preserving Localization via Coordinate Permutations , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
Instance Normalization: The Missing Ingredient for Fast Stylization
Instance normalization: The missing ingredient for fast stylization , author=. arXiv preprint arXiv:1607.08022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Rectifier nonlinearities improve neural network acoustic models , author=. Proc. icml , volume=. 2013 , organization=
2013
-
[20]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[21]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Learning to find good correspondences , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[22]
FirstName LastName , title =
-
[23]
FirstName Alpher , title =
-
[24]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[25]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[26]
FirstName Alpher and FirstName Gamow , title =
-
[27]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Megadepth: Learning single-view depth prediction from internet photos , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[28]
Proceedings of the IEEE international conference on computer vision , pages=
Posenet: A convolutional network for real-time 6-dof camera relocalization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[29]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Scene coordinate regression forests for camera relocalization in RGB-D images , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[31]
Structure-from-Motion Revisited , booktitle=
Sch\". Structure-from-Motion Revisited , booktitle=
-
[32]
NetVLAD:
Arandjelovic, Relja and Gronat, Petr and Torii, Akihiko and Pajdla, Tomas and Sivic, Josef , booktitle=. NetVLAD:
-
[33]
Fine-tuning
Radenovi. Fine-tuning. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
2018
-
[34]
Advances in neural information processing systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in neural information processing systems , volume=
-
[35]
Pacific Journal of Mathematics , volume=
Concerning nonnegative matrices and doubly stochastic matrices , author=. Pacific Journal of Mathematics , volume=. 1967 , publisher=
1967
-
[36]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Learning multi-scene absolute pose regression with transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[37]
IEEE transactions on pattern analysis and machine intelligence , volume=
Visual camera re-localization from RGB and RGB-D images using DSAC , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[38]
IEEE transactions on pattern analysis and machine intelligence , volume=
Efficient & effective prioritized matching for large-scale image-based localization , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2016 , publisher=
2016
-
[39]
Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Superpoint: Self-supervised interest point detection and description , author=. Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hybrid scene compression for visual localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
International journal of computer vision , volume=
EP n P: An accurate O (n) solution to the P n P problem , author=. International journal of computer vision , volume=. 2009 , publisher=
2009
-
[42]
Pattern Recognition: 25th DAGM Symposium, Magdeburg, Germany, September 10-12, 2003
Locally optimized RANSAC , author=. Pattern Recognition: 25th DAGM Symposium, Magdeburg, Germany, September 10-12, 2003. Proceedings 25 , pages=. 2003 , organization=
2003
-
[43]
Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part IV 16 , pages=
Self-supervising fine-grained region similarities for large-scale image localization , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part IV 16 , pages=. 2020 , organization=
2020
-
[44]
International Journal of Computer Vision , volume=
End-to-end learning of deep visual representations for image retrieval , author=. International Journal of Computer Vision , volume=. 2017 , publisher=
2017
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Learning with average precision: Training image retrieval with a listwise loss , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[46]
2012 IEEE conference on computer vision and pattern recognition , pages=
Three things everyone should know to improve object retrieval , author=. 2012 IEEE conference on computer vision and pattern recognition , pages=. 2012 , organization=
2012
-
[47]
2011 International Conference on Computer Vision , pages=
Fast image-based localization using direct 2d-to-3d matching , author=. 2011 International Conference on Computer Vision , pages=. 2011 , organization=
2011
-
[48]
Computer Vision--ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part I 12 , pages=
Improving image-based localization by active correspondence search , author=. Computer Vision--ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part I 12 , pages=. 2012 , organization=
2012
-
[49]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Clustergnn: Cluster-based coarse-to-fine graph neural network for efficient feature matching , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[50]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
CoMatcher: Multi-View Collaborative Feature Matching , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Learning two-view correspondences and geometry using order-aware network , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[53]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Minimal scene descriptions from structure from motion models , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[54]
2015 IEEE international conference on robotics and automation (ICRA) , pages=
The gist of maps-summarizing experience for lifelong localization , author=. 2015 IEEE international conference on robotics and automation (ICRA) , pages=. 2015 , organization=
2015
-
[55]
Computer Vision--ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part II 11 , pages=
Location recognition using prioritized feature matching , author=. Computer Vision--ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part II 11 , pages=. 2010 , organization=
2010
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scenesqueezer: Learning to compress scene for camera relocalization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
European Conference on Computer Vision (ECCV) , pages=
MAD-DR: Map Compression for Visual Localization with Matchness Aware Descriptor Dimension Reduction , author=. European Conference on Computer Vision (ECCV) , pages=. 2025 , publisher=
2025
-
[58]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Learning-based dimensionality reduction for computing compact and effective local feature descriptors , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[59]
Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004
PCA-SIFT: A more distinctive representation for local image descriptors , author=. Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004. , volume=. 2004 , organization=
2004
-
[60]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Hyperpoints and fine vocabularies for large-scale location recognition , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[61]
IEEE transactions on pattern analysis and machine intelligence , volume=
Product quantization for nearest neighbor search , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2010 , publisher=
2010
-
[62]
arXiv preprint arXiv:2407.15540 , year=
Differentiable Product Quantization for Memory Efficient Camera Relocalization , author=. arXiv preprint arXiv:2407.15540 , year=
-
[63]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Structure-from-motion revisited , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[64]
ACM siggraph 2006 papers , pages=
Photo tourism: exploring photo collections in 3D , author=. ACM siggraph 2006 papers , pages=
2006
-
[65]
2013 International Conference on 3D Vision-3DV 2013 , pages=
Towards linear-time incremental structure from motion , author=. 2013 International Conference on 3D Vision-3DV 2013 , pages=. 2013 , organization=
2013
-
[66]
Handbook of augmented reality , pages=
Augmented reality: an overview , author=. Handbook of augmented reality , pages=. 2011 , publisher=
2011
-
[67]
Foundations and Trends
A survey of augmented reality , author=. Foundations and Trends. 2015 , publisher=
2015
-
[68]
IEEE Transactions on robotics , volume=
Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age , author=. IEEE Transactions on robotics , volume=. 2016 , publisher=
2016
-
[69]
Artificial intelligence review , volume=
Visual simultaneous localization and mapping: a survey , author=. Artificial intelligence review , volume=. 2015 , publisher=
2015
-
[70]
IEEE transactions on robotics , volume=
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras , author=. IEEE transactions on robotics , volume=. 2017 , publisher=
2017
-
[71]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Continual learning for image-based camera localization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[72]
International Journal of Computer Vision , pages=
Hscnet++: Hierarchical scene coordinate classification and regression for visual localization with transformer , author=. International Journal of Computer Vision , pages=. 2024 , publisher=
2024
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hierarchical scene coordinate classification and regression for visual localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
GLACE: Global Local Accelerated Coordinate Encoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Cross-descriptor visual localization and mapping , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[76]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[77]
Advances in neural information processing systems , volume=
R2d2: Reliable and repeatable detector and descriptor , author=. Advances in neural information processing systems , volume=
-
[78]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
D2-net: A trainable cnn for joint description and detection of local features , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[79]
Advances in Neural Information Processing Systems , volume=
DISK: Learning local features with policy gradient , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
24/7 place recognition by view synthesis , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.