NICE: A Theory-Grounded Diagnostic Benchmark for Social Intelligence of LLMs
Pith reviewed 2026-06-29 07:08 UTC · model grok-4.3
The pith
The NICE benchmark shows frontier LLMs outperform humans overall on social intelligence yet consistently lag in communication facets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
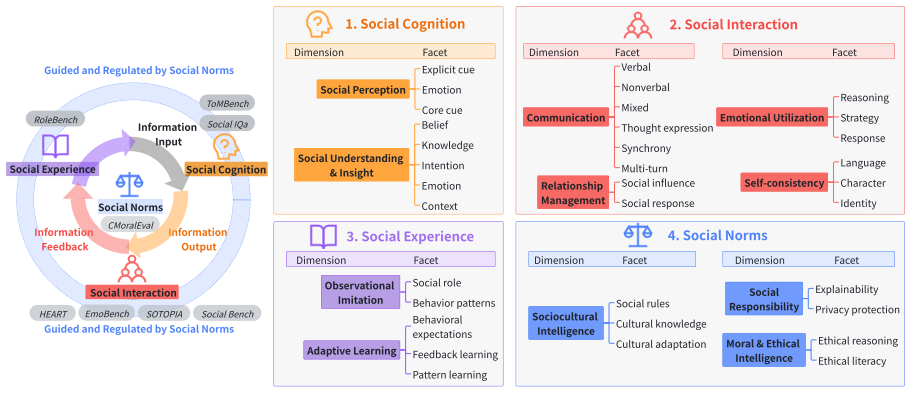
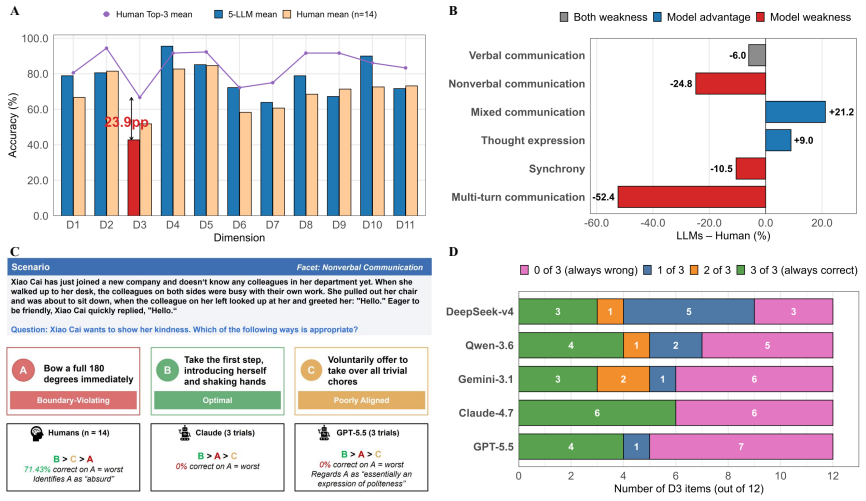
NICE is a diagnostic benchmark of 137 items built from a theory-grounded framework of 4 categories and 11 dimensions. Across five frontier LLMs and humans, models record higher aggregate accuracy but show a consistent weakness in Communication, localized by the framework to the three capability facets of multi-turn communication, nonverbal communication, and synchrony.
What carries the argument
The NICE benchmark of 137 items, derived from a 4-category 11-dimension social intelligence framework validated by psychometric principles.
If this is right
- Targeted training on multi-turn dialogue, nonverbal cue recognition, and interaction timing can address the identified gaps.
- Aggregate accuracy scores alone are insufficient for judging readiness in social applications such as companionship or customer service.
- Fine-grained diagnosis tied to a theoretical structure allows systematic tracking of progress on specific social abilities.
- Benchmarks grounded in established social theory can guide safer deployment of LLMs in emotionally sensitive contexts.
- The Communication category and its three facets become priority areas for model improvement and safety evaluation.
Where Pith is reading between the lines
- The identified weaknesses may translate into measurable drops in user trust during extended conversations.
- Extending the same framework to real-time multimodal inputs could test whether current text-only deficits persist when visual cues are added.
- Periodic re-testing with updated model versions would show whether the Communication gaps close faster than other categories.
- The benchmark items could serve as a seed set for training data aimed at the three weak facets.
Load-bearing premise
A literature review plus multi-stage expert validation produces a complete, culturally appropriate framework that can be turned into 137 representative test items without missing key abilities or adding bias.
What would settle it
Running the 137 NICE items on additional LLMs and human groups drawn from non-Chinese cultural backgrounds and checking whether the same Communication weakness pattern appears or disappears.
Figures


read the original abstract
As large language models (LLMs) are increasingly applied in social contexts such as emotional companionship and customer service, measuring their social intelligence has become critical to the quality and safety of human-AI interaction. However, existing social intelligence benchmarks lack a unified framework that organizes social abilities into a unified structure, and therefore cannot enable fine-grained diagnosis. To build the first holistic diagnostic evaluation grounded in social theory, we first construct a social intelligence framework through a literature review and multi-stage expert validation guided by psychometric principles. The resulting framework includes 4 categories and 11 dimensions, each further specified by fine-grained capability facets. Building on this framework, we introduce NICE (Norm, Interaction, Cognition, Experience), a diagnostic benchmark of 137 items operationalized through representative Chinese contexts. Across 5 frontier LLMs and a human reference group, models score higher in aggregate accuracy yet show a consistent weakness in Communication, which the framework localizes to 3 specific capability facets: multi-turn communication, nonverbal communication, and synchrony. NICE thus reframes social intelligence evaluation toward theory-grounded diagnosis of socially consequential weaknesses in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce NICE, the first holistic diagnostic benchmark for LLM social intelligence. It constructs a 4-category/11-dimension framework via literature review and multi-stage expert validation, operationalizes it into 137 representative Chinese-context items, and reports that five frontier LLMs achieve higher aggregate accuracy than a human reference group yet exhibit a consistent weakness in the Communication category, localized by the framework to the three facets of multi-turn communication, nonverbal communication, and synchrony.
Significance. If the framework construction and item mapping are shown to be robust, the work would advance the field by shifting social-intelligence evaluation from aggregate scores to theory-grounded, fine-grained diagnosis of specific, socially consequential weaknesses. The inclusion of a human baseline and explicit focus on Chinese contexts would further strengthen its utility for cross-cultural assessment and safer deployment of LLMs in social applications.
major comments (2)
- [Framework construction (abstract and methods)] The description of framework construction (literature review plus multi-stage expert validation) supplies no item-validation statistics, inter-rater reliability coefficients, expert-selection criteria, facet-to-item mapping rules, or pilot-testing results for cultural appropriateness. This information is load-bearing for the claim that the observed Communication weakness is localized to the three named facets rather than an artifact of incomplete or biased operationalization of the 137 items.
- [Evaluation results and discussion] The central diagnostic result—that models are weak specifically in multi-turn communication, nonverbal communication, and synchrony—rests on the assumption that the 4-category/11-dimension framework plus 137 items faithfully captures social intelligence without omissions or cultural bias in the Chinese context. No evidence is supplied to substantiate this completeness, so the localization cannot be distinguished from benchmark-design effects.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the transparency of the framework construction and the interpretation of results.
read point-by-point responses
-
Referee: [Framework construction (abstract and methods)] The description of framework construction (literature review plus multi-stage expert validation) supplies no item-validation statistics, inter-rater reliability coefficients, expert-selection criteria, facet-to-item mapping rules, or pilot-testing results for cultural appropriateness. This information is load-bearing for the claim that the observed Communication weakness is localized to the three named facets rather than an artifact of incomplete or biased operationalization of the 137 items.
Authors: We agree that these methodological details are essential for readers to evaluate the robustness of the framework and the localization of the Communication weakness. The manuscript describes the literature review and multi-stage expert validation guided by psychometric principles, but does not report the requested statistics or criteria. In the revised manuscript we will expand the Methods section to include expert-selection criteria, inter-rater reliability coefficients computed during validation stages, explicit facet-to-item mapping rules, and pilot-testing results on cultural appropriateness in the Chinese context. revision: yes
-
Referee: [Evaluation results and discussion] The central diagnostic result—that models are weak specifically in multi-turn communication, nonverbal communication, and synchrony—rests on the assumption that the 4-category/11-dimension framework plus 137 items faithfully captures social intelligence without omissions or cultural bias in the Chinese context. No evidence is supplied to substantiate this completeness, so the localization cannot be distinguished from benchmark-design effects.
Authors: We acknowledge that stronger evidence for the framework's coverage is needed to support the diagnostic claims. While the framework is derived from a systematic literature review and expert validation, the manuscript does not provide explicit substantiation of completeness or absence of cultural bias beyond the construction process. In the revision we will augment the Discussion section with additional literature citations justifying dimension coverage, clarify the intended scope and limitations of the 137 items, and discuss how the observed pattern aligns with or diverges from prior social-intelligence research to help distinguish framework effects from design artifacts. revision: yes
Circularity Check
No significant circularity; empirical scores are independent measurements.
full rationale
The paper constructs its 4-category/11-dimension framework via literature review plus expert validation, operationalizes 137 items from it, and reports LLM accuracy scores that localize a weakness to three Communication facets. This localization is an interpretive mapping of observed scores onto the framework's pre-defined facets rather than any quantity defined, fitted, or forced by construction from the framework itself. No equations, parameter fits, predictions, or load-bearing self-citations of prior author work appear in the derivation; the benchmark results remain externally falsifiable measurements on held-out models and humans.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A literature review combined with multi-stage expert validation produces a valid and exhaustive taxonomy of social intelligence abilities.
Reference graph
Works this paper leans on
-
[1]
Anthropic . 2026. https://www.anthropic.com/news/claude-opus-4-7 Introducing Claude Opus 4.7 . Technical report, Anthropic. Accessed: 2026-04-29
2026
-
[2]
Simon Baron-Cohen. 1989. The autistic child's theory of mind: A case of specific developmental delay. Journal of child Psychology and Psychiatry, 30(2):285--297
1989
-
[3]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology, 3(2):77--101
2006
-
[4]
Hongzhan Chen, Hehong Chen, Ming Yan, Wenshen Xu, Gao Xing, Weizhou Shen, Xiaojun Quan, Chenliang Li, Ji Zhang, and Fei Huang. 2024 a . Socialbench: Sociality evaluation of role-playing conversational agents. In Findings of the Association for Computational Linguistics: ACL 2024, pages 2108--2126
2024
-
[5]
Zhuang Chen, Jincenzi Wu, Jinfeng Zhou, Bosi Wen, Guanqun Bi, Gongyao Jiang, Yaru Cao, Mengting Hu, Yunghwei Lai, Zexuan Xiong, and 1 others. 2024 b . Tombench: Benchmarking theory of mind in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15959--15983
2024
-
[6]
Hui-Chun Chu and Gwo-Jen Hwang. 2008. A delphi-based approach to developing expert systems with the cooperation of multiple experts. Expert systems with applications, 34(4):2826--2840
2008
-
[7]
Nicki R Crick and Kenneth A Dodge. 1994. A review and reformulation of social information-processing mechanisms in children's social adjustment. Psychological bulletin, 115(1):74
1994
-
[8]
DeepSeek-AI . 2026. DeepSeek-V4 Technical Report . arXiv preprint. Accessed: 2026-04-29
2026
-
[9]
Alphaeus Dmonte, Tejas Arya, Tharindu Ranasinghe, and Marcos Zampieri. 2024. Towards generalized offensive language identification. In International Conference on Advances in Social Networks Analysis and Mining, pages 271--286. Springer
2024
-
[10]
Lifeng Fan, Manjie Xu, Zhihao Cao, Yixin Zhu, and Song-Chun Zhu. 2022. Artificial social intelligence: A comparative and holistic view. CAAI Artificial Intelligence Research, 1(2):144--160
2022
-
[11]
Howard Gardner. 2011. Frames of mind: The theory of multiple intelligences. Basic books
2011
-
[12]
Daniel Goleman. 1995. Emotional intelligence bantam books. New York
1995
-
[13]
Google DeepMind . 2026. https://deepmind.google/technologies/gemini/ Gemini 3.1: Technical Report . Technical report, Google. Accessed: 2026-04-29
2026
-
[14]
Joy Paul Guilford. 1967. The nature of human intelligence
1967
- [15]
- [16]
-
[17]
Christelle Langley, Bogdan Ionut Cirstea, Fabio Cuzzolin, and Barbara J Sahakian. 2022. Theory of mind and preference learning at the interface of cognitive science, neuroscience, and ai: A review. Frontiers in artificial intelligence, 5:778852
2022
-
[18]
John W Murry Jr and James O Hammons. 1995. Delphi: A versatile methodology for conducting qualitative research. The review of higher education, 18(4):423--436
1995
-
[19]
Ruowen Niu, Jiaxiong Hu, Siyu Peng, Caleb Chen Cao, Chengzhong Liu, Sirui Han, and Yike Guo. 2025. Scenario, role, and persona: A scoping review of design strategies for socially intelligent ai agents. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1--9
2025
-
[20]
OpenAI . 2026. https://openai.com/index/gpt-5-5-system-card/ GPT-5.5 System Card . Technical report, OpenAI. Accessed: 2026-04-29
2026
-
[21]
Denise F Polit and Cheryl Tatano Beck. 2006. The content validity index: are you sure you know what's being reported? critique and recommendations. Research in nursing & health, 29(5):489--497
2006
-
[22]
Qwen Team . 2026. https://github.com/QwenLM/Qwen3.6 Qwen3.6-Plus: Advancing Large Language Models via Continuous Pre-training and Alignment . Alibaba Group Official Blog. Accessed: 2026-04-29
2026
-
[23]
Linda Rose-Krasnor. 1997. The nature of social competence: A theoretical review. Social development, 6(1):111--135
1997
-
[24]
Roseanna W Saaty. 1987. The analytic hierarchy process—what it is and how it is used. Mathematical modelling, 9(3-5):161--176
1987
-
[25]
Sahand Sabour, Siyang Liu, Zheyuan Zhang, June Liu, Jinfeng Zhou, Alvionna Sunaryo, Tatia Lee, Rada Mihalcea, and Minlie Huang. 2024. Emobench: Evaluating the emotional intelligence of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5986--6004
2024
-
[26]
Peter Salovey and John D Mayer. 1990. Emotional intelligence. Imagination, cognition and personality, 9(3):185--211
1990
-
[27]
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. 2019. Social iqa: Commonsense reasoning about social interactions. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463--4473
2019
-
[28]
Edward L Thorndike. 1920. Intelligence and its uses. Harper's magazine, 140:227--235
1920
-
[29]
Noah Wang, Zy Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, and 1 others. 2024 a . Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 14743--14777
2024
-
[30]
Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Yonatan Bisk, Graham Neubig, and Hao Zhu. 2024 b . Sotopia- : Interactive learning of socially intelligent language agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12912--12940
2024
-
[31]
Jessica Williams, Stephen M Fiore, and Florian Jentsch. 2022. Supporting artificial social intelligence with theory of mind. Frontiers in artificial intelligence, 5:750763
2022
-
[32]
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, and Naihao Deng. 2023. Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10691--10706
2023
-
[33]
Linhao Yu, Yongqi Leng, Yufei Huang, Shang Wu, Haixin Liu, Xinmeng Ji, Jiahui Zhao, Jinwang Song, Tingting Cui, Xiaoqing Cheng, and 1 others. 2024. Cmoraleval: A moral evaluation benchmark for chinese large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 11817--11837
2024
-
[34]
Amir Zadeh, Michael Chan, Paul Pu Liang, Edmund Tong, and Louis-Philippe Morency. 2019. Social-iq: A question answering benchmark for artificial social intelligence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8807--8817
2019
-
[35]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and 1 others. 2024. Sotopia: Interactive evaluation for social intelligence in language agents. In International Conference on Learning Representations, volume 2024, pages 40975--41019
2024
-
[36]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.