Emo-LiPO: Listwise Preference Optimization for Fine-Grained Emotion Intensity Control in LLM-based Text-to-Speech
Pith reviewed 2026-06-27 05:59 UTC · model grok-4.3
The pith
Emo-LiPO treats emotion intensity control in LLM TTS as a learning-to-rank task solved by listwise preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
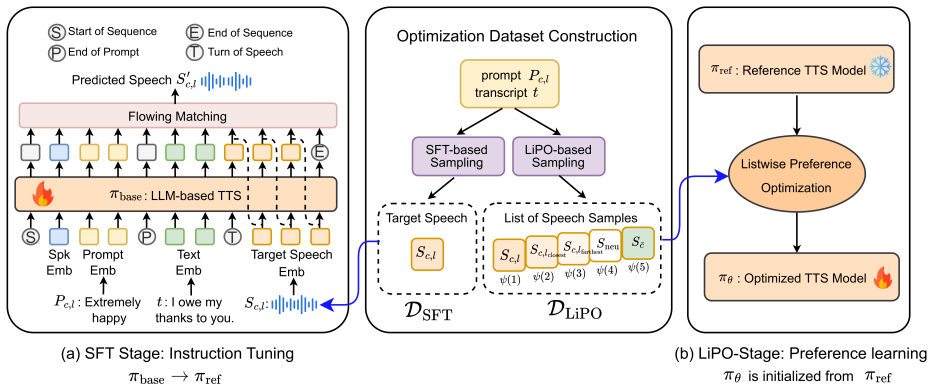
Emo-LiPO explicitly models global intensity ordering within each emotion under fixed transcripts by optimizing listwise preferences, enabling more faithful and continuous emotional expression in prompt-conditioned LLM TTS generation.
What carries the argument
Listwise preference optimization that aligns multiple prompt-conditioned speech candidates to the relative emotion intensity ordering expressed in text.
If this is right
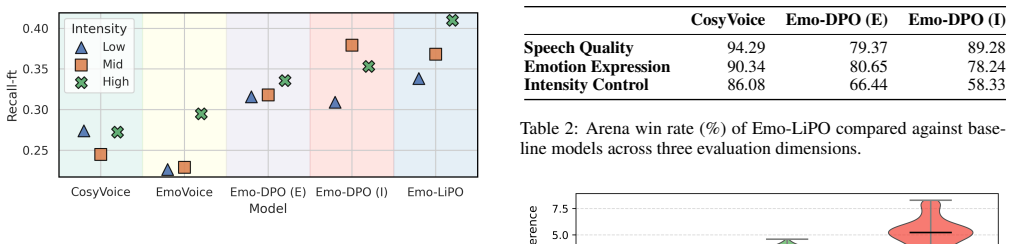
- Emotion accuracy improves over both supervised and pairwise DPO baselines on the same transcripts.
- Intensity controllability gains are largest at the high end of the requested range.
- Emotional expression becomes more continuous because global ordering within each emotion is enforced.
- The ESD-plus dataset supplies explicit intensity labels that support both training and evaluation of fine-grained control.
Where Pith is reading between the lines
- The same listwise-ranking supervision could be applied to other continuous attributes such as speaking rate or pitch range when absolute labels are unavailable.
- Relative ordering extracted from text may reduce reliance on expensive absolute-intensity annotations in other controllable generation tasks.
- The approach could be combined with existing prompt-engineering techniques to further narrow the semantic-acoustic gap without additional model scale.
Load-bearing premise
Relative emotion intensity ordering within fixed transcripts can be reliably extracted from text prompts and used as supervision to close the semantic-acoustic gap in LLM TTS generation.
What would settle it
Listener ratings on ESD-plus samples that show no statistically significant gain in intensity-matching accuracy for Emo-LiPO over DPO baselines at high-intensity prompts would falsify the central claim.
Figures

read the original abstract
Large language model (LLM)-based text-to-speech (TTS) systems enable prompt-conditioned emotional control but struggle with fine-grained emotion intensity due to the semantic -- acoustic gap between text and speech. To address this challenge, we formulate emotion intensity control in LLM-based TTS as a learning-to-rank problem and propose Emo-LiPO, a listwise preference optimization framework that aligns prompt-conditioned speech generation with relative emotion intensity expressed in text. Emo-LiPO explicitly models global intensity ordering within each emotion under fixed transcripts, enabling more faithful and continuous emotional expression. We further construct ESD-plus, a multi-speaker dataset with explicit emotion intensity variations, to support fine-grained emotion modeling and evaluation. Experiments on ESD-plus demonstrate that Emo-LiPO significantly improves emotion accuracy and intensity controllability over both supervised- and DPO-based LLM TTS baselines, with particularly pronounced gains at high intensity levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Emo-LiPO, a listwise preference optimization framework that formulates emotion intensity control in LLM-based TTS as a learning-to-rank problem. It aligns prompt-conditioned speech generation with relative emotion intensity orderings extracted from text under fixed transcripts, introduces the ESD-plus multi-speaker dataset with explicit intensity variations, and reports significant gains in emotion accuracy and intensity controllability over supervised and DPO baselines, especially at high intensity levels.
Significance. If the central results hold and the text-derived orderings prove reliable, the work offers a targeted extension of preference optimization to fine-grained TTS control, addressing the semantic-acoustic gap via global ranking within emotions. The ESD-plus dataset construction would also support more rigorous evaluation of intensity modeling.
major comments (2)
- [Method and Experiments] The central claim that Emo-LiPO closes the semantic-acoustic gap rests on text-expressed relative intensity orderings serving as valid acoustic supervision. No validation is shown that these orderings correspond to measurable acoustic intensity differences in the generated outputs or in ESD-plus (e.g., via objective metrics on intensity or human ratings of perceived ordering). This assumption is load-bearing for the superiority over DPO baselines.
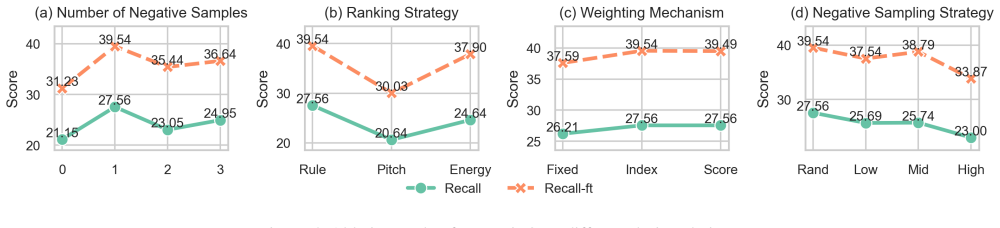
- [Abstract and §4] The abstract and experimental claims state performance gains without reporting concrete metrics, baseline implementations, statistical significance tests, or ablation on the listwise vs. pairwise formulation. This prevents verification that the reported improvements at high intensities are attributable to the listwise objective rather than dataset or training differences.
minor comments (2)
- [§3] Notation for the listwise loss and preference pairs should be defined more explicitly with respect to the LLM TTS generation process.
- [Figures] Figure captions and axis labels for intensity controllability plots could be clarified to distinguish text-prompt ordering from acoustic realization.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation and strengthen the validation of our approach. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim that Emo-LiPO closes the semantic-acoustic gap rests on text-expressed relative intensity orderings serving as valid acoustic supervision. No validation is shown that these orderings correspond to measurable acoustic intensity differences in the generated outputs or in ESD-plus (e.g., via objective metrics on intensity or human ratings of perceived ordering). This assumption is load-bearing for the superiority over DPO baselines.
Authors: We acknowledge that explicit validation of the text-derived orderings against acoustic measures strengthens the central claim. The orderings originate from prompts engineered to express graded intensity under fixed transcripts, and the performance gains (particularly at high intensities) provide indirect support. However, to directly address the concern, the revised version will include objective acoustic analyses (e.g., energy, pitch range, and duration variance) on both ESD-plus and model outputs, plus human ratings of perceived intensity ordering, to confirm alignment between text supervision and acoustic realizations. revision: yes
-
Referee: [Abstract and §4] The abstract and experimental claims state performance gains without reporting concrete metrics, baseline implementations, statistical significance tests, or ablation on the listwise vs. pairwise formulation. This prevents verification that the reported improvements at high intensities are attributable to the listwise objective rather than dataset or training differences.
Authors: We agree that concrete numbers, implementation details, significance testing, and targeted ablations are necessary for rigorous verification. The original Section 4 contains some quantitative results and baseline descriptions, but these will be expanded: the abstract will be updated with key metrics; full baseline code and hyperparameter details will be added to the appendix; statistical significance (p-values) will be reported for all comparisons; and a new ablation will isolate listwise versus pairwise objectives under identical data and training conditions to attribute gains specifically to the listwise formulation. revision: yes
Circularity Check
No circularity: empirical claims rest on independent dataset and experiments
full rationale
The provided abstract and description contain no equations, no fitted parameters, and no derivations. Emo-LiPO is introduced as a new listwise preference optimization framework that treats relative intensity ordering as supervision; ESD-plus is a constructed dataset for evaluation. No step reduces a claimed result to its own inputs by construction, no self-citation is invoked as a uniqueness theorem, and no prediction is statistically forced by a prior fit. The central claims are presented as outcomes of experiments on the new dataset, which are externally falsifiable. This matches the default expectation that most papers are non-circular when no load-bearing self-referential reduction is exhibited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Emotion intensity can be treated as a relative ordering problem within each emotion and fixed transcript.
Forward citations
Cited by 1 Pith paper
-
HPRO: Hierarchical Progressive Reward Optimization via Preference Extraction for Emotional Text-to-Speech
HPRO uses a differentiable HD-Emo codec to extract separate content and style tokens and progressively aligns frame-, word-, and sentence-level rewards to improve emotional expressiveness in TTS while preserving intel...
Reference graph
Works this paper leans on
-
[1]
[Choet al., 2024 ] Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, Sang-Hoon Lee, and Seong-Whan Lee. Emosphere-tts: Emotional style and intensity modeling via spherical emotion vector for controllable emotional text-to-speech.arXiv preprint arXiv:2406.07803,
arXiv 2024
-
[2]
Emosphere++: Emotion-controllable zero-shot text-to-speech via emotion-adaptive spherical vector.IEEE Transactions on Affective Computing,
[Choet al., 2025 ] Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, and Seong-Whan Lee. Emosphere++: Emotion-controllable zero-shot text-to-speech via emotion-adaptive spherical vector.IEEE Transactions on Affective Computing,
2025
-
[3]
[Duet al., 2024a ] Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilin- gual zero-shot text-to-speech synthesizer based on super- vised semantic tokens.arXiv preprint arXiv:2407.05407,
-
[4]
Cosyvoice 2: Scalable streaming speech synthesis with large language models
[Duet al., 2024b ] Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models. arXiv preprint arXiv:2412.10117,
-
[5]
Kto: Model alignment as prospect theoretic optimization
[Ethayarajhet al., 2024 ] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306,
Pith/arXiv arXiv 2024
-
[6]
Emo-dpo: Control- lable emotional speech synthesis through direct preference optimization
[Gaoet al., 2025 ] Xiaoxue Gao, Chen Zhang, Yiming Chen, Huayun Zhang, and Nancy F Chen. Emo-dpo: Control- lable emotional speech synthesis through direct preference optimization. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2025
-
[7]
Emodiff: Intensity controllable emotional text-to-speech with soft-label guidance
[Guoet al., 2023a ] Yiwei Guo, Chenpeng Du, Xie Chen, and Kai Yu. Emodiff: Intensity controllable emotional text-to-speech with soft-label guidance. InICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[8]
Prompttts: Controllable text-to- speech with text descriptions
[Guoet al., 2023b ] Zhifang Guo, Yichong Leng, Yihan Wu, Sheng Zhao, and Xu Tan. Prompttts: Controllable text-to- speech with text descriptions. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[9]
Emoq-tts: Emotion inten- sity quantization for fine-grained controllable emotional text-to-speech
[Imet al., 2022 ] Chae-Bin Im, Sang-Hoon Lee, Seung-Bin Kim, and Seong-Whan Lee. Emoq-tts: Emotion inten- sity quantization for fine-grained controllable emotional text-to-speech. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6317–6321. IEEE,
2022
-
[10]
Msemotts: Multi-scale emotion transfer, pre- diction, and control for emotional speech synthesis
[Leiet al., 2022 ] Yi Lei, Shan Yang, Xinsheng Wang, and Lei Xie. Msemotts: Multi-scale emotion transfer, pre- diction, and control for emotional speech synthesis. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:853–864,
2022
-
[11]
Prompttts 2: De- scribing and generating voices with text prompt.arXiv preprint arXiv:2309.02285,
[Lenget al., 2023 ] Yichong Leng, Zhifang Guo, Kai Shen, Xu Tan, Zeqian Ju, Yanqing Liu, Yufei Liu, Dongchao Yang, Leying Zhang, Kaitao Song, et al. Prompttts 2: De- scribing and generating voices with text prompt.arXiv preprint arXiv:2309.02285,
arXiv 2023
-
[12]
Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models
[Liet al., 2024 ] Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models. InInterna- tional Conference on Machine Learning, pages 29128– 29163. PMLR,
2024
-
[13]
Emorl-tts: Reinforcement learning for fine-grained emotion control in llm-based tts
[Liet al., 2025 ] Haoxun Li, Yu Liu, Yuqing Sun, Hanlei Shi, Leyuan Qu, and Taihao Li. Emorl-tts: Reinforcement learning for fine-grained emotion control in llm-based tts. arXiv preprint arXiv:2510.05758,
arXiv 2025
-
[14]
Ece-tts: A zero-shot emotion text-to- speech model with simplified and precise control.Applied Sciences, 15(9):5108,
[Lianget al., 2025 ] Shixiong Liang, Ruohua Zhou, and Qingsheng Yuan. Ece-tts: A zero-shot emotion text-to- speech model with simplified and precise control.Applied Sciences, 15(9):5108,
2025
-
[15]
Lipo: Listwise preference optimization through learning- to-rank
[Liuet al., 2025a ] Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mo- hammad Saleh, Simon Baumgartner, Jialu Liu, et al. Lipo: Listwise preference optimization through learning- to-rank. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Huma...
2025
-
[16]
[Liuet al., 2025b ] Zhijun Liu, Dongya Jia, Xiaoqiang Wang, Chenpeng Du, Shuai Wang, Zhuo Chen, and Haizhou Li. Direct preference optimization for speech autoregressive diffusion models.arXiv preprint arXiv:2509.18928,
-
[17]
emotion2vec: Self-supervised pre-training for speech emotion representation
[Maet al., 2024 ] Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, Shiliang Zhang, and Xie Chen. emotion2vec: Self-supervised pre-training for speech emotion representation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 15747– 15760,
2024
-
[18]
[Mittaget al., 2021 ] Gabriel Mittag, Babak Naderi, Assmaa Chehadi, and Sebastian Möller. Nisqa: A deep cnn- self-attention model for multidimensional speech quality prediction with crowdsourced datasets.arXiv preprint arXiv:2104.09494,
arXiv 2021
-
[19]
Robust speech recognition via large-scale weak supervision
[Radfordet al., 2023 ] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR,
2023
-
[20]
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
[Rafailovet al., 2023 ] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
2023
-
[21]
Dnsmos: A non-intrusive perceptual objec- tive speech quality metric to evaluate noise suppressors
[Reddyet al., 2021 ] Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objec- tive speech quality metric to evaluate noise suppressors. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6493–6497. IEEE,
2021
-
[22]
Utmos: Utokyo-sarulab sys- tem for voicemos challenge 2022.arXiv preprint arXiv:2204.02152,
[Saekiet al., 2022 ] Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. Utmos: Utokyo-sarulab sys- tem for voicemos challenge 2022.arXiv preprint arXiv:2204.02152,
arXiv 2022
-
[23]
Improving emotional tts with an emotion intensity input from unsupervised extraction
[Schnell and Garner, 2021] Bastian Schnell and Philip N Garner. Improving emotional tts with an emotion intensity input from unsupervised extraction. InProc. 11th ISCA Speech Synth. Workshop, pages 60–65,
2021
-
[24]
Prox- imal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
[Schulmanet al., 2017 ] John Schulman, Filip Wolski, Pra- fulla Dhariwal, Alec Radford, and Oleg Klimov. Prox- imal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
Pith/arXiv arXiv 2017
-
[25]
Preference ranking optimization for human alignment
[Songet al., 2024 ] Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference ranking optimization for human alignment. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 38, pages 18990–18998,
2024
-
[26]
Fine-grained emotional control of text- to-speech: Learning to rank inter-and intra-class emo- tion intensities
[Wanget al., 2023 ] Shijun Wang, Jón Guðnason, and Damian Borth. Fine-grained emotional control of text- to-speech: Learning to rank inter-and intra-class emo- tion intensities. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[27]
Laugh now cry later: Controlling time-varying emotional states of flow-matching-based zero-shot text-to-speech
[Wuet al., 2024 ] Haibin Wu, Xiaofei Wang, Sefik Emre Es- kimez, Manthan Thakker, Daniel Tompkins, Chung-Hsien Tsai, Canrun Li, Zhen Xiao, Sheng Zhao, Jinyu Li, et al. Laugh now cry later: Controlling time-varying emotional states of flow-matching-based zero-shot text-to-speech. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 690–697. IEEE,
2024
-
[28]
[Yanget al., 2025b ] Qing Yang, Zhenghao Liu, Junxin Wang, Yangfan Du, Pengcheng Huang, and Tong Xiao. Rlaif-spa: Optimizing llm-based emotional speech synthe- sis via rlaif.arXiv preprint arXiv:2510.14628,
-
[29]
TS-align: A teacher-student collaborative framework for scalable iterative finetuning of large lan- guage models
[Zhanget al., 2024a ] Chen Zhang, Chengguang Tang, Dad- ing Chong, Ke Shi, Guohua Tang, Feng Jiang, and Haizhou Li. TS-align: A teacher-student collaborative framework for scalable iterative finetuning of large lan- guage models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP ...
2024
-
[30]
[Zhanget al., 2025b ] Shaozuo Zhang, Ambuj Mehrish, Yingting Li, and Soujanya Poria. Proemo: Prompt-driven text-to-speech synthesis based on emotion and intensity control.arXiv preprint arXiv:2501.06276,
-
[31]
Slic- hf: Sequence likelihood calibration with human feedback
[Zhaoet al., 2023 ] Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. Slic- hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425,
arXiv 2023
-
[32]
Emoshift: Lightweight activation steering for enhanced emotion-aware speech synthesis
[Zhouet al., 2026 ] Li Zhou, Hao Jiang, Junjie Li, Tianrui Wang, and Haizhou Li. Emoshift: Lightweight activation steering for enhanced emotion-aware speech synthesis. In ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17262–17266, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.