DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models
Pith reviewed 2026-07-01 08:52 UTC · model grok-4.3
The pith
DPRM is a plug-in module for diffusion language models that starts from confidence-driven token ordering and shifts to a reward-tilted Gibbs reveal law through online process-reward estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
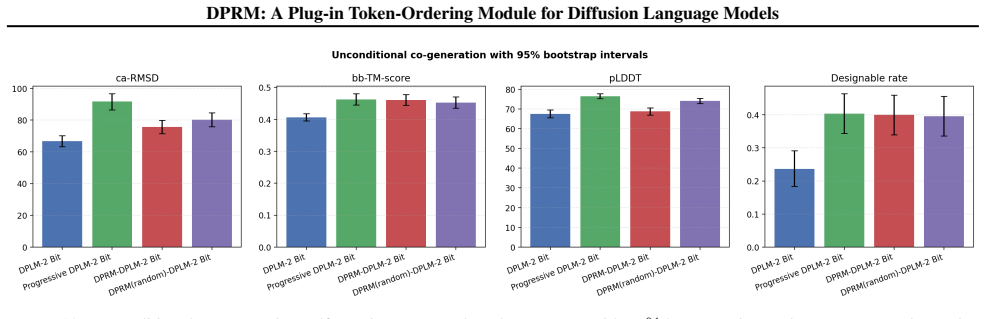
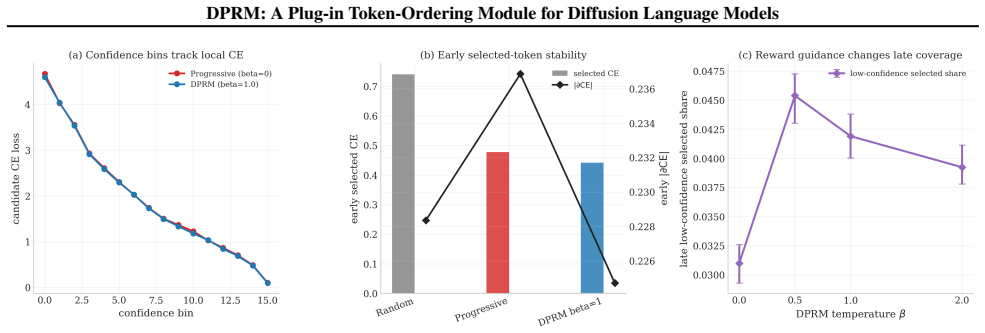
The exact DPRM policy is a reward-tilted Gibbs reveal law; its stagewise Soft-BoN approximation converges, the online bucketized controller tracks the exact score at empirical-Bernstein rates, and the approach yields a sample-complexity advantage under tractable optimization assumptions. When inserted into existing diffusion language models it improves several language-reasoning, DNA, and multimodal benchmarks while identifying boundary cases that favor confidence-only ordering.
What carries the argument
The Doob h-transform-induced process reward model that tilts the token-reveal distribution by estimated process rewards while preserving the original denoising objective.
If this is right
- DPRM ordering improves language reasoning and test-time scaling tasks.
- The same ordering policy yields gains on protein, single-cell, molecular, and DNA sequence generation.
- Text-to-image and VQA hosts also show measurable lifts when DPRM replaces their default ordering.
- Boundary cases exist where confidence-only ordering or task-specific utilities outperform the full DPRM policy.
Where Pith is reading between the lines
- The plug-in design suggests the same ordering module could be tested on other non-autoregressive sequence models without retraining the denoiser.
- If the online controller continues to track at the stated rates, it could reduce the need for expensive full-trajectory reward estimation at inference time.
- The identification of boundary cases implies that a meta-controller choosing between confidence and reward ordering per task might be a natural next step.
Load-bearing premise
The tractable optimization assumptions under which the sample-complexity advantage holds.
What would settle it
An empirical run in which the online bucketized controller deviates from the exact DPRM score by more than the claimed empirical-Bernstein rate on a fixed host model would falsify the tracking guarantee.
Figures

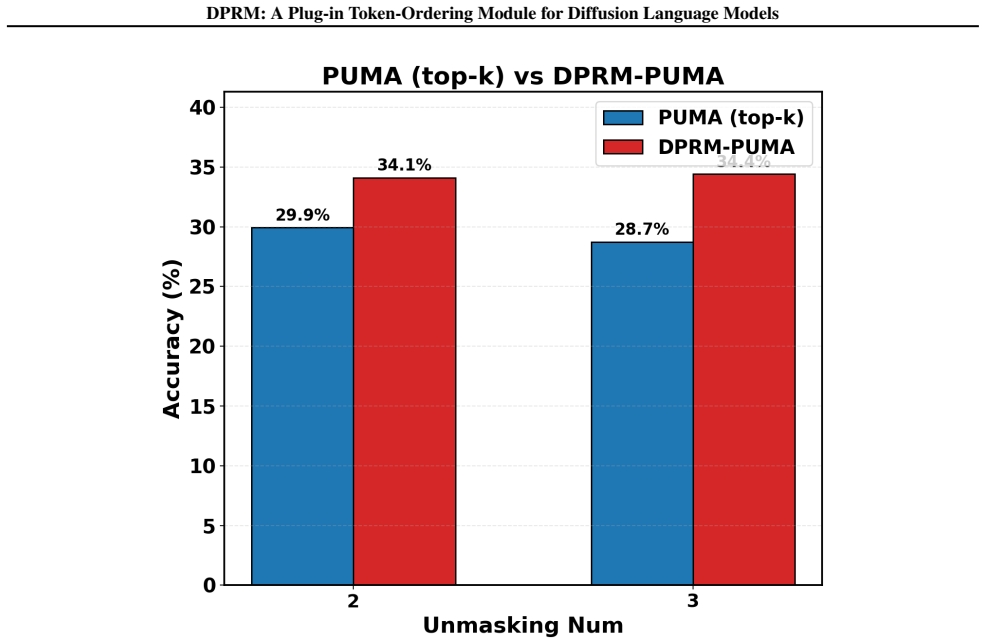
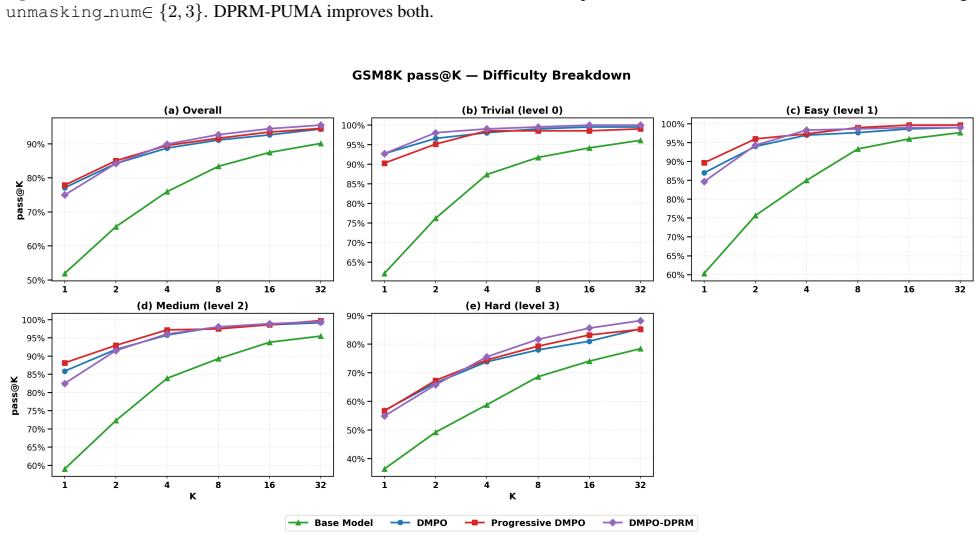
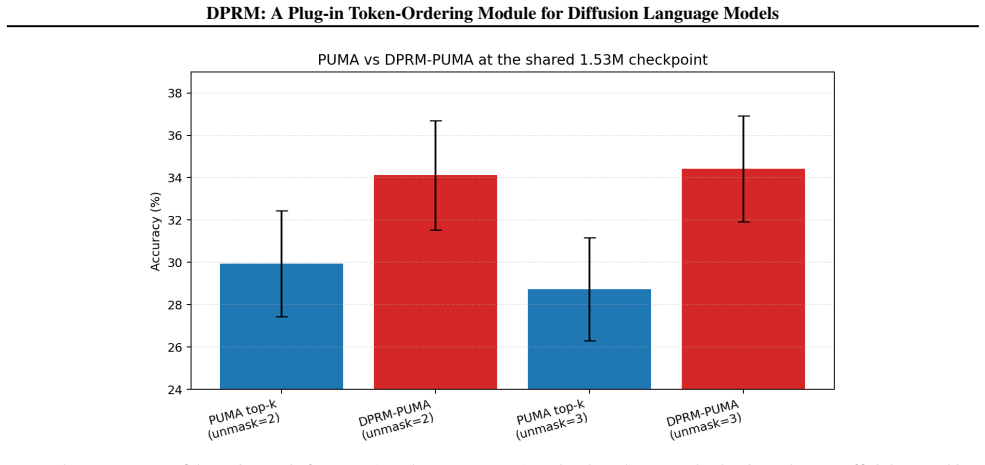


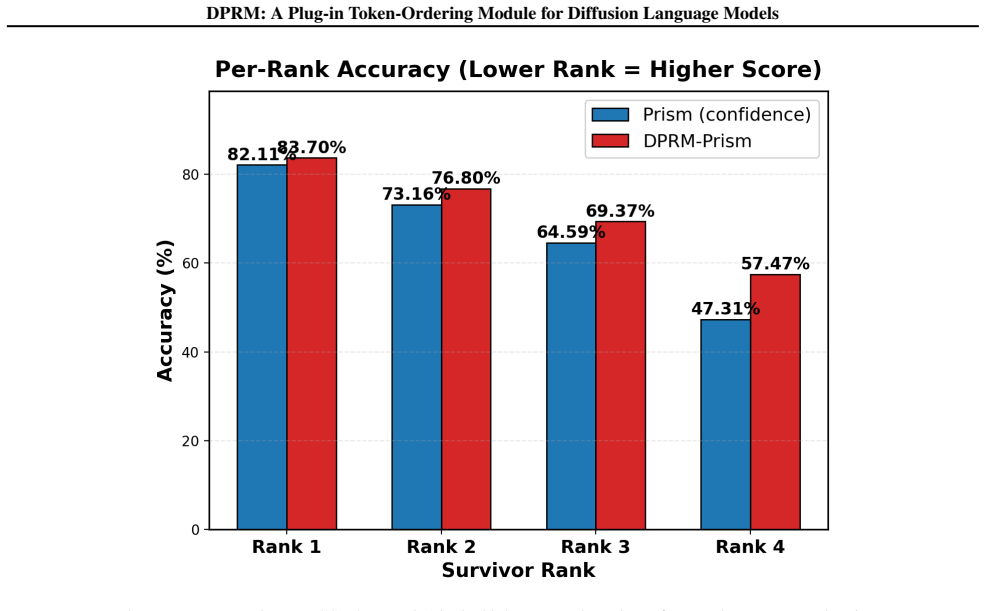









read the original abstract
Diffusion language models generate without a fixed left-to-right order, leaving token ordering as a central algorithmic choice. Existing systems mainly use random masking or confidence-driven ordering, which respectively suffer from train--test mismatch and myopic exploration. We introduce DPRM (Doob -transform Process Reward Model), a plug-in token-ordering module that keeps the host architecture, denoising objective and supervision unchanged, and modifies only the ordering policy. DPRM starts from confidence-driven ordering and gradually shifts to process-reward-guided ordering through online estimates. We characterize the exact DPRM policy as a reward-tilted Gibbs reveal law, prove convergence of its stagewise Soft-BoN approximation, show that the online bucketized controller tracks the exact DPRM score at empirical-Bernstein rates, and establish a sample-complexity advantage under tractable optimization assumptions. Across nine hosts covering language reasoning, test-time scaling, protein, single-cell, molecular, DNA, text-to-image generation, and VQA, DPRM order variants improve several language, DNA, and multimodal settings while also identifying boundary cases where confidence-only ordering or task-specific utilities are preferable. Code is available at: https://github.com/DakeBU/DPRM-DLLM
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DPRM, a plug-in token-ordering module for diffusion language models that starts from confidence-driven ordering and shifts to process-reward-guided ordering via online estimates based on a Doob h-transform. It claims to exactly characterize the DPRM policy as a reward-tilted Gibbs reveal law, prove convergence of its stagewise Soft-BoN approximation, show that the online bucketized controller tracks the exact DPRM score at empirical-Bernstein rates, and establish a sample-complexity advantage under tractable optimization assumptions. Experiments across nine hosts in language reasoning, protein, DNA, molecular, text-to-image, and VQA tasks report improvements in several settings while identifying boundary cases favoring confidence-only ordering.
Significance. If the derivations are correct and the sample-complexity advantage holds under the stated assumptions, the plug-in design (leaving host architecture and denoising objective unchanged) and code release would make this a useful contribution for improving ordering policies in diffusion LMs. The empirical-Bernstein tracking and Soft-BoN convergence results, if rigorously derived, would add to the toolkit for online policy adaptation in generative models.
major comments (1)
- [Abstract] Abstract (final sentence of theoretical claims paragraph): The sample-complexity advantage is established only under unspecified 'tractable optimization assumptions.' These must be explicitly defined (e.g., convexity of the objective, Lipschitz continuity of the process reward, or bounded variance) and shown to apply to the DPRM controller and the nine hosts; without this, the advantage claim is not verifiable and does not necessarily transfer to the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that the tractable optimization assumptions underlying the sample-complexity advantage require explicit definition to ensure verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence of theoretical claims paragraph): The sample-complexity advantage is established only under unspecified 'tractable optimization assumptions.' These must be explicitly defined (e.g., convexity of the objective, Lipschitz continuity of the process reward, or bounded variance) and shown to apply to the DPRM controller and the nine hosts; without this, the advantage claim is not verifiable and does not necessarily transfer to the reported improvements.
Authors: We agree with the referee that the assumptions must be stated explicitly. In the revised manuscript we will expand both the abstract and the theoretical section to define them precisely: convexity of the stagewise optimization objective, Lipschitz continuity of the process reward, and bounded variance of the online estimates (with the empirical-Bernstein rate already derived in the paper). We will also add a short paragraph clarifying that these are standard regularity conditions that hold for the DPRM controller under the problem formulation. Demonstrating that the assumptions hold verbatim for every one of the nine heterogeneous hosts would require per-task verification that goes beyond the current scope; we will therefore note the assumptions as general and sufficient for the claimed advantage while identifying the boundary cases already discussed in the experiments. revision: yes
Circularity Check
No significant circularity; derivations are self-contained mathematical claims
full rationale
The paper's core claims consist of a policy characterization as a reward-tilted Gibbs law, a convergence proof for the Soft-BoN approximation, an empirical-Bernstein tracking guarantee for the online controller, and a conditional sample-complexity result. These rest on standard martingale and concentration arguments plus external tractable-optimization assumptions rather than reducing any quantity to its own fitted inputs or self-citations by construction. No equations are presented that equate a derived prediction directly to a parameter chosen during fitting, and the online estimates are shown to track an independently defined score rather than being renamed as that score. The derivation chain therefore remains independent of the experimental hosts and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tractable optimization assumptions
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pages 1068–1080, Miami, Florida, USA
Bridging cultures in the kitchen: A framework and benchmark for cross-cultural recipe retrieval. InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pages 1068–1080, Miami, Florida, USA. Association for Computational Linguistics. Yichong Huang, Baohang Li, Xiaocheng Feng, Wen- shuai Huo, Chengpeng Fu, Ting Liu, and Bing Qin
2024
-
[2]
Aligning translation-specific understanding to general understanding in large language models. InProceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing, pages 5028–5041, Miami, Florida, USA. Association for Computational Linguistics. Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, and 1 others. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556. Yinquan Lu, Wenhao Zhu, Lei Li, Yu Qiao, and Fei Yu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen2.5 Technical Report.arXiv preprint. ArXiv:2412.15115 [cs]. Pushpdeep Singh, Mayur Patidar, and Lovekesh Vig
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
Translating across cultures: LLMs for in- tralingual cultural adaptation. InProceedings of the 28th Conference on Computational Natural Lan- guage Learning, pages 400–418, Miami, FL, USA. Association for Computational Linguistics. Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, A...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Binwei Yao, Ming Jiang, Tara Bobinac, Diyi Yang, and Junjie Hu. 2024. Benchmarking machine translation with cultural awareness. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2024, pages 13078–13096, Miami, Florida, USA. Associa- tion for Computational Linguistics. Yangfan Ye, X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.