Reliable Homomorphic Matching for Fuzzy Labeled PSI at Scale
Pith reviewed 2026-06-29 04:19 UTC · model grok-4.3
The pith
CSTPSI uses multiple independent token rounds to drive the realization soundness error of homomorphic fuzzy labeled PSI to negligible levels at million- and billion-scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CSTPSI runs independent token rounds and raises the per-trial bound to a matching power. We prove CSTPSI secure in the semi-honest model. The bound sets the round count: two token rounds suffice for million-scale databases and three for billion-scale at the 10^{-6} engineering threshold. Our evaluation confirms this: at a million records the baseline kernel's RSE reaches 100% while CSTPSI holds it at 0 in every measured configuration.
What carries the argument
CSTPSI kernel that executes independent token rounds to raise the per-trial false-accept probability to the power of the number of rounds.
If this is right
- Two token rounds suffice for million-scale databases at the 10^{-6} threshold.
- Three token rounds suffice for billion-scale databases at the same threshold.
- CSTPSI achieves zero RSE in every measured configuration at a million records while the baseline reaches 100 percent.
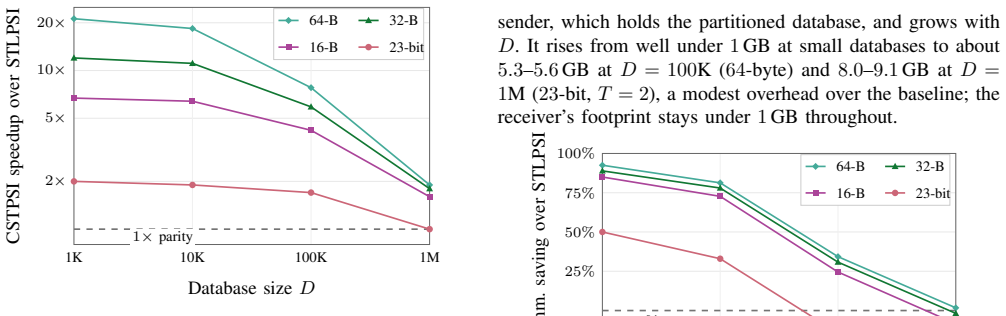
- For large labels at small to moderate scale CSTPSI is more than 20x faster than the baseline with up to 93 percent less communication.
Where Pith is reading between the lines
- The multi-round structure could be applied to other homomorphic protocols where per-element error accumulates with database size.
- The security reduction assumes semi-honest participants, so extensions to malicious models would require additional machinery.
Load-bearing premise
The per-trial false-accept events across independent token rounds are statistically independent so that the overall realization soundness error equals the per-trial probability raised to the power of the rounds.
What would settle it
A measurement in which CSTPSI accepts a non-matching query with probability above 10^{-6} in a million-record database using two token rounds would falsify the claimed bound.
Figures



read the original abstract
Fuzzy Labeled Private Set Intersection (FLPSI) lets a receiver learn the labels of enrolled records similar to its query, and nothing else. Constructions based on a set-threshold reduction reach practical performance: a query matches a record when the two agree on a threshold number of components, and the private matching is delegated to an inner set-threshold kernel. We study its homomorphic form, which combines leveled-BFV homomorphic encryption (HE), a garbled circuit, and secret sharing to decide the match under encryption and release the record's label. We identify a composition gap in this kernel: efficiency is bought with a per-trial false-accept probability, but one query runs a trial for every record, so the error compounds with the database size into the kernel's realization soundness error (RSE), the rate at which it accepts a query the plaintext matcher would reject. The RSE is a reliability property of the cryptographic matching layer, not the matcher's accuracy, and a sound kernel must contribute zero or negligible RSE of its own. We formalize this as a composable security property, give a closed-form bound on the receiver's advantage, and close the gap with CSTPSI, a kernel that runs independent token rounds and raises the per-trial bound to a matching power. We prove CSTPSI secure in the semi-honest model. The bound sets the round count: two token rounds suffice for million-scale databases and three for billion-scale at the $10^{-6}$ engineering threshold. Our evaluation confirms this: at a million records the baseline kernel's RSE reaches 100% while CSTPSI holds it at 0 in every measured configuration. For large labels at small to moderate scale CSTPSI is more than 20x faster than the baseline, with up to 93% less communication, converging to the baseline only at million-scale. Our implementation, with a one-command reproducibility harness, is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CSTPSI, a homomorphic kernel for fuzzy labeled PSI that combines leveled-BFV, garbled circuits, and secret sharing. It identifies a composition gap where per-trial false-accept probability compounds with database size into realization soundness error (RSE), and closes the gap by running k independent token rounds so that RSE equals (per-trial probability)^k. The construction is proved secure in the semi-honest model; the bound implies k=2 suffices for million-scale and k=3 for billion-scale at the 10^{-6} threshold. Evaluation shows the baseline reaches 100% RSE at 1M records while CSTPSI achieves 0% RSE, with >20x speedup and up to 93% less communication for large labels at moderate scale. The implementation is publicly available with a reproducibility harness.
Significance. If the independence argument and security reduction hold, the work supplies a concrete, composable reliability property for homomorphic matching kernels and demonstrates that modest repetition suffices to drive RSE below engineering thresholds at scale. The public reproducibility harness and concrete performance numbers (RSE 0 vs 100%, communication savings) are strengths that would allow direct follow-up work.
major comments (2)
- [Abstract / CSTPSI construction] Abstract and CSTPSI construction paragraph: the closed-form RSE bound RSE = p^k rests on the claim that false-accept events across token rounds are statistically independent. The semi-honest security proof must explicitly argue that fresh per-round randomness together with the BFV+GC+secret-sharing composition introduces no cross-round correlations (via shared labels, circuit state, or ciphertext reuse) that would make the realized RSE exceed p^k; without this step the bound does not follow from the per-trial analysis.
- [Security proof] Security proof section: the manuscript states a proof in the semi-honest model but the provided abstract does not exhibit the reduction or the hybrid argument that isolates the independence property. A load-bearing step is therefore missing from the central claim that two (resp. three) rounds suffice for the 10^{-6} threshold at million- (resp. billion-) scale.
minor comments (2)
- [Evaluation] Evaluation section: the concrete RSE measurement protocol (how false accepts are counted over the million-record database) should be stated explicitly so that the reported 0% vs 100% figures can be reproduced from the released code.
- [Introduction] Notation: the distinction between per-trial false-accept probability and the overall RSE should be introduced with a short equation in the introduction to make the composition gap easier to follow.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive comments on the independence argument in the security proof. We address each major comment below and will revise the manuscript to make the required steps explicit.
read point-by-point responses
-
Referee: [Abstract / CSTPSI construction] Abstract and CSTPSI construction paragraph: the closed-form RSE bound RSE = p^k rests on the claim that false-accept events across token rounds are statistically independent. The semi-honest security proof must explicitly argue that fresh per-round randomness together with the BFV+GC+secret-sharing composition introduces no cross-round correlations (via shared labels, circuit state, or ciphertext reuse) that would make the realized RSE exceed p^k; without this step the bound does not follow from the per-trial analysis.
Authors: We agree that the independence of false-accept events must be justified explicitly to support the RSE = p^k bound. The current security proof states security in the semi-honest model and gives the closed-form bound, but does not isolate the absence of cross-round correlations in sufficient detail. In the revision we will add a hybrid argument in the security proof section that uses fresh per-round randomness together with the BFV+GC+secret-sharing composition to show that no shared state or ciphertext reuse creates statistical dependence between rounds. revision: yes
-
Referee: [Security proof] Security proof section: the manuscript states a proof in the semi-honest model but the provided abstract does not exhibit the reduction or the hybrid argument that isolates the independence property. A load-bearing step is therefore missing from the central claim that two (resp. three) rounds suffice for the 10^{-6} threshold at million- (resp. billion-) scale.
Authors: The abstract is a high-level summary and is not expected to contain the full reduction. However, we acknowledge that the security proof section does not yet display the hybrid argument isolating the independence property. We will revise that section to include the explicit reduction and hybrid steps that establish why the per-round false-accept probability raises to the k-th power without additional correlations, thereby supporting the concrete round counts for the stated thresholds. revision: yes
Circularity Check
No significant circularity; bound derived from stated independence assumption using standard repetition
full rationale
The paper's central derivation formalizes RSE as a composable property, provides a closed-form bound, and uses k independent token rounds to obtain RSE = (per-trial false-accept prob)^k. This follows directly from the explicit independence assumption stated in the construction, which is a standard cryptographic error-amplification technique rather than a self-referential definition or fitted input. No equations reduce by construction to their own inputs, no self-citations are load-bearing for the uniqueness or security claim, and the semi-honest security proof is asserted on standard primitives (leveled-BFV, garbled circuits, secret sharing) without circular reduction. Evaluation provides empirical confirmation but does not substitute for the derivation. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Security holds in the semi-honest model
invented entities (1)
-
CSTPSI
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Efficient private matching and set intersection,
M. J. Freedman, K. Nissim, and B. Pinkas, “Efficient private matching and set intersection,” inAdvances in Cryptology – EUROCRYPT 2004, ser. Lecture Notes in Computer Science, vol. 3027. Springer, 2004, pp. 1–19
2004
-
[2]
Faster private set intersection based on OT extension,
B. Pinkas, T. Schneider, and M. Zohner, “Faster private set intersection based on OT extension,” in23rd USENIX Security Symposium (USENIX Security 14). USENIX Association, 2014, pp. 797–812
2014
-
[3]
Efficient batched oblivious PRF with applications to private set intersection,
V . Kolesnikov, R. Kumaresan, M. Rosulek, and N. Trieu, “Efficient batched oblivious PRF with applications to private set intersection,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016, pp. 818–829. 14
2016
-
[4]
PSI from PaXoS: Fast, malicious private set intersection,
B. Pinkas, M. Rosulek, N. Trieu, and A. Yanai, “PSI from PaXoS: Fast, malicious private set intersection,” inAdvances in Cryptology – EUROCRYPT 2020, ser. Lecture Notes in Computer Science, vol. 12106. Springer, 2020, pp. 739–767
2020
-
[5]
VOLE-PSI: Fast OPRF and circuit-PSI from vector-OLE,
P. Rindal and P. Schoppmann, “VOLE-PSI: Fast OPRF and circuit-PSI from vector-OLE,” inAdvances in Cryptology – EUROCRYPT 2021, ser. Lecture Notes in Computer Science, vol. 12697. Springer, 2021, pp. 901–930
2021
-
[6]
Blazing fast PSI from improved OKVS and subfield VOLE,
S. Raghuraman and P. Rindal, “Blazing fast PSI from improved OKVS and subfield VOLE,” inProceedings of the 2022 ACM SIGSAC Con- ference on Computer and Communications Security. ACM, 2022, pp. 2505–2517, ePrint 2022/320, https://eprint.iacr.org/2022/320
2022
-
[7]
Fuzzy labeled private set intersection with applications to private real- time biometric search,
E. Uzun, S. P. Chung, V . Kolesnikov, A. Boldyreva, and W. Lee, “Fuzzy labeled private set intersection with applications to private real- time biometric search,” in30th USENIX Security Symposium (USENIX Security 21). USENIX Association, 2021, pp. 911–928
2021
-
[8]
Distance-aware private set intersection,
A. Chakraborti, G. Fanti, and M. K. Reiter, “Distance-aware private set intersection,” in32nd USENIX Security Symposium (USENIX Security 23). USENIX Association, 2023, arXiv:2112.14737
arXiv 2023
-
[9]
SANNS: Scaling up secure approximate k-nearest neighbors search,
H. Chen, I. Chillotti, Y . Dong, O. Poburinnaya, I. Razenshteyn, and M. S. Riazi, “SANNS: Scaling up secure approximate k-nearest neighbors search,” in29th USENIX Security Symposium (USENIX Security 20). USENIX Association, 2020, pp. 2111–2128
2020
-
[10]
Microsoft SEAL (release 4.x),
Microsoft Research, “Microsoft SEAL (release 4.x),” https://github.com /microsoft/SEAL, 2023
2023
-
[11]
EMP-toolkit: Efficient multiparty computation toolkit,
X. Wang, A. J. Malozemoff, and J. Katz, “EMP-toolkit: Efficient multiparty computation toolkit,” https://github.com/emp-toolkit, 2016
2016
-
[12]
ABY: A framework for efficient mixed-protocol secure two-party computation,
D. Demmler, T. Schneider, and M. Zohner, “ABY: A framework for efficient mixed-protocol secure two-party computation,” in22nd Annual Network and Distributed System Security Symposium (NDSS), 2015
2015
-
[13]
How to share a secret,
A. Shamir, “How to share a secret,”Communications of the ACM, vol. 22, no. 11, pp. 612–613, 1979
1979
-
[14]
Faster unbalanced private set intersection,
A. C. D. Resende and D. de Freitas Aranha, “Faster unbalanced private set intersection,” inFinancial Cryptography and Data Security (FC 2018), ser. Lecture Notes in Computer Science. Springer, 2018, ePrint 2017/677
2018
-
[15]
Mobile private contact discovery at scale,
D. Kales, C. Rechberger, T. Schneider, M. Senker, and C. Weinert, “Mobile private contact discovery at scale,” in28th USENIX Security Symposium (USENIX Security 19). USENIX Association, 2019
2019
-
[16]
Labeled PSI from homomorphic encryption with reduced computation and communication,
K. Cong, R. C. Moreno, M. B. da Gama, W. Dai, I. Iliashenko, K. Laine, and M. Rosenberg, “Labeled PSI from homomorphic encryption with reduced computation and communication,” inProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2021, pp. 1135–1150
2021
-
[17]
Obliv- ious key-value stores and amplification for private set intersection,
G. Garimella, B. Pinkas, M. Rosulek, N. Trieu, and A. Yanai, “Obliv- ious key-value stores and amplification for private set intersection,” inAdvances in Cryptology – CRYPTO 2021, ser. Lecture Notes in Computer Science, vol. 12828. Springer, 2021, pp. 395–425, iACR ePrint 2021/883
2021
-
[18]
Fuzzy private set intersection with large hyperballs,
A. van Baarsen and S. Pu, “Fuzzy private set intersection with large hyperballs,” inAdvances in Cryptology – EUROCRYPT 2024, ser. Lecture Notes in Computer Science, M. Joye and G. Leander, Eds., vol. 14655. Springer, 2024, pp. 340–369, ePrint 2024/330, https: //eprint.iacr.org/2024/330
2024
-
[19]
Fuzzy private matching,
L. Chmielewski and J.-H. Hoepman, “Fuzzy private matching,” in2008 Third International Conference on Availability, Reliability and Security. IEEE, 2008, pp. 327–334
2008
-
[20]
Efficient fuzzy matching and intersection on private datasets,
Q. Ye, R. Steinfeld, J. Pieprzyk, and H. Wang, “Efficient fuzzy matching and intersection on private datasets,” inInternational Conference on Information Security and Cryptology. Springer, 2009, pp. 211–228
2009
-
[21]
Compact fuzzy private matching using a fully-homomorphic encryption scheme,
I. Calapodescu, S. Estehghari, and J. Clier, “Compact fuzzy private matching using a fully-homomorphic encryption scheme,” Aug. 29 2017, uS Patent 9,749,128
2017
-
[22]
Efficient privacy- preserving face recognition,
A.-R. Sadeghi, T. Schneider, and I. Wehrenberg, “Efficient privacy- preserving face recognition,” inInternational conference on information security and cryptology. Springer, 2009, pp. 229–244
2009
-
[23]
Privacy-preserving face recognition,
Z. Erkin, M. Franz, J. Guajardo, S. Katzenbeisser, I. Lagendijk, and T. Toft, “Privacy-preserving face recognition,” inInternational sympo- sium on privacy enhancing technologies symposium. Springer, 2009, pp. 235–253
2009
-
[24]
Scifi-a system for secure face identification,
M. Osadchy, B. Pinkas, A. Jarrous, and B. Moskovich, “Scifi-a system for secure face identification,” in2010 IEEE Symposium on Security and Privacy. IEEE, 2010, pp. 239–254
2010
-
[25]
Privacy- preserving fingercode authentication,
M. Barni, T. Bianchi, D. Catalano, M. Di Raimondo, R. Donida Labati, P. Failla, D. Fiore, R. Lazzeretti, V . Piuri, F. Scottiet al., “Privacy- preserving fingercode authentication,” inProceedings of the 12th ACM workshop on Multimedia and security, 2010, pp. 231–240
2010
-
[26]
Secure and efficient protocols for iris and fingerprint identification,
M. Blanton and P. Gasti, “Secure and efficient protocols for iris and fingerprint identification,” inEuropean Symposium on Research in Computer Security. Springer, 2011, pp. 190–209
2011
-
[27]
Structure-aware private set intersection, with applications to fuzzy matching,
G. Garimella, M. Rosulek, and J. Singh, “Structure-aware private set intersection, with applications to fuzzy matching,” inAdvances in Cryptology – CRYPTO 2022, Part I, ser. Lecture Notes in Computer Science, vol. 13507. Springer, Heidelberg, 2022, pp. 323–352, ePrint 2022/1011, https://eprint.iacr.org/2022/1011
2022
-
[28]
Efficient fuzzy private set intersection from fuzzy mapping,
Y . Gao, L. Qi, X. Liu, Y . Luo, and L. Wang, “Efficient fuzzy private set intersection from fuzzy mapping,” inAdvances in Cryptology – ASIACRYPT 2024, 2024, code: https://github.com/ql70ql70/Fuzzy-P rivate-Set-Intersection-from-Fuzzy-Mapping
2024
-
[29]
Distance- aware OT with application to fuzzy PSI,
L. Piske, J. Singh, N. Trieu, V . Kolesnikov, and V . Zikas, “Distance- aware OT with application to fuzzy PSI,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’25. ACM, 2025, pp. 4679–4691, full version: ePrint 2025/996
2025
-
[30]
Fast fuzzy PSI from symmetric-key techniques,
C. Zhang, Y . Chen, Y . Cao, Y . Bai, S. Li, J. Lin, A. Wang, and X. Wang, “Fast fuzzy PSI from symmetric-key techniques,” 2025, iACR ePrint 2025/885, https://eprint.iacr.org/2025/885; venue not stated in manuscript
2025
-
[31]
Efficient fuzzy private set intersection from secret-shared OPRF,
X. Yang, M. Hao, C. Weng, R. H. Deng, Y . Wen, and T. Zhang, “Efficient fuzzy private set intersection from secret-shared OPRF,” inProceedings of the 2026 IEEE Symposium on Security and Privacy (S&P), 2026, arXiv:2604.14909v1
Pith/arXiv arXiv 2026
-
[32]
Unbalanced fuzzy private set intersection for L ∞ distance: Achieving sublinear communication with large set size,
S. Meng, X. Wang, X. Zhou, and B. Liang, “Unbalanced fuzzy private set intersection for L ∞ distance: Achieving sublinear communication with large set size,” in35th USENIX Security Symposium (USENIX Security 26). USENIX Association, 2026, code: https://doi.org/10 .5281/zenodo.18223806
2026
-
[33]
Efficient fuzzy PSI based on prefix representation,
C. Dang, X. Zhou, and B. Liang, “Efficient fuzzy PSI based on prefix representation,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2025, pp. 2204–2218
2025
-
[34]
The communication complexity of threshold private set intersection,
S. Ghosh and M. Simkin, “The communication complexity of threshold private set intersection,” inAdvances in Cryptology - CRYPTO 2019, 2019, pp. 3–29
2019
-
[35]
Multi- party threshold private set intersection with sublinear communication,
S. Badrinarayanan, P. Miao, S. Raghuraman, and P. Rindal, “Multi- party threshold private set intersection with sublinear communication,” inPublic-Key Cryptography - PKC 2021, 2021
2021
-
[36]
Labeled PSI from fully homomorphic encryption with malicious security,
H. Chen, Z. Huang, K. Laine, and P. Rindal, “Labeled PSI from fully homomorphic encryption with malicious security,” inProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2018, pp. 1223–1237
2018
-
[37]
Circuit-PSI with linear complex- ity via relaxed batch OPPRF,
N. Chandran, D. Gupta, and A. Shah, “Circuit-PSI with linear complex- ity via relaxed batch OPPRF,” inProceedings on Privacy Enhancing Technologies (PoPETs), vol. 2022, no. 1, 2022, pp. 353–372
2022
-
[38]
Efficient circuit- based PSI with linear communication,
B. Pinkas, T. Schneider, O. Tkachenko, and A. Yanai, “Efficient circuit- based PSI with linear communication,” inAdvances in Cryptology – EUROCRYPT 2019, ser. Lecture Notes in Computer Science, vol. 11478, 2019, pp. 122–153
2019
-
[39]
Efficient fuzzy search on encrypted data,
A. Boldyreva and N. Chenette, “Efficient fuzzy search on encrypted data,” inFast Software Encryption (FSE), ser. LNCS, vol. 8540. Springer, 2014, pp. 613–633
2014
-
[40]
Fast private set intersection from homomorphic encryption,
H. Chen, K. Laine, and P. Rindal, “Fast private set intersection from homomorphic encryption,” inProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2017, pp. 1243–1255
2017
-
[41]
(Leveled) fully ho- momorphic encryption without bootstrapping,
Z. Brakerski, C. Gentry, and V . Vaikuntanathan, “(Leveled) fully ho- momorphic encryption without bootstrapping,”ACM Transactions on Computation Theory (TOCT), vol. 6, no. 3, pp. 13:1–13:36, 2014, preliminary version: ITCS 2012
2014
-
[42]
Fully homomorphic SIMD operations,
N. P. Smart and F. Vercauteren, “Fully homomorphic SIMD operations,” Designs, Codes and Cryptography, vol. 71, no. 1, pp. 57–81, 2014
2014
-
[43]
Phasing: Private set intersection using permutation-based hashing,
B. Pinkas, T. Schneider, G. Segev, and M. Zohner, “Phasing: Private set intersection using permutation-based hashing,” in24th USENIX Security Symposium (USENIX Security), 2015, pp. 515–530
2015
-
[44]
Efficient circuit- based PSI via cuckoo hashing,
B. Pinkas, T. Schneider, C. Weinert, and U. Wieder, “Efficient circuit- based PSI via cuckoo hashing,” inAdvances in Cryptology – EURO- CRYPT 2018, ser. LNCS, vol. 10822. Springer, 2018, pp. 125–157. 15
2018
-
[45]
Keyword search and oblivious pseudorandom functions,
M. J. Freedman, Y . Ishai, B. Pinkas, and O. Reingold, “Keyword search and oblivious pseudorandom functions,” inTheory of Cryptography (TCC), ser. LNCS, vol. 3378. Springer, 2005, pp. 303–324
2005
-
[46]
Sanitization of FHE ciphertexts,
L. Ducas and D. Stehl ´e, “Sanitization of FHE ciphertexts,” inAdvances in Cryptology – EUROCRYPT 2016, ser. LNCS, vol. 9665. Springer, 2016, pp. 294–310
2016
-
[47]
ØMQ (ZeroMQ): An open-source universal messaging library,
“ØMQ (ZeroMQ): An open-source universal messaging library,” https: //zeromq.org, 2024
2024
-
[48]
FLINT: Fast Library for Number Theory (release 3.4),
W. Hartet al., “FLINT: Fast Library for Number Theory (release 3.4),” https://flintlib.org, 2024
2024
-
[49]
Labeled faces in the wild: A database for studying face recognition in uncon- strained environments,
G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller, “Labeled faces in the wild: A database for studying face recognition in uncon- strained environments,” University of Massachusetts, Amherst, Tech. Rep. 07-49, 2007
2007
-
[50]
Efficient indexing of billion-scale datasets of deep descriptors,
A. Babenko and V . Lempitsky, “Efficient indexing of billion-scale datasets of deep descriptors,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2055–2063. APPENDIXA QUERY-POWERTRANSMISSIONVARIANTS The sender’s per-partition polynomial evaluation ft,i,p(bj) = Pd−1 ℓ=0 ct,i,p,ℓ ·Enc(b ℓ j)withd=s part requires ciphertextsEnc...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.