StreamGuard: Low-Overhead Resilience for Real-time HPC Data Streams
Pith reviewed 2026-07-01 01:20 UTC · model grok-4.3
The pith
Two mechanisms keep real-time HPC data streams progressing through failures with under 1% normal overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a dynamic asynchronous non-blocking checkpointing mechanism together with a progress-aware load redistribution strategy maintains forward progress and balanced execution for the producer-consumer streaming pattern even in highly error-prone environments, reducing the impact of failures and performance anomalies by up to 6x while adding less than 1% overhead during failure-free runs.
What carries the argument
The pair of dynamic asynchronous non-blocking checkpointing that preserves progress without interrupting computation, plus progress-aware load redistribution that detects slow workers and rebalances tasks.
If this is right
- Real-time constraints remain satisfied because forward progress continues despite faults.
- The producer-consumer pattern stays balanced, preventing single slow workers from stalling the entire stream.
- Overall workflow output quality stays high with minimal extra resource use when no failures happen.
- The same mechanisms apply directly to other continuous data-stream scientific workflows built on the same pattern.
Where Pith is reading between the lines
- The approach could be tested on workflows that use multiple streaming patterns at once to see whether the two techniques still compose cleanly.
- In very large clusters the redistribution logic might need extra coordination to avoid creating new bottlenecks during rebalancing.
- The low overhead opens the possibility of always-on resilience even on systems where failures are rare but expensive when they occur.
Load-bearing premise
That the checkpointing can save state without any interruption to computation and that the redistribution can reliably detect and correct slow workers even when many failures occur at once.
What would settle it
Measure the observed slowdown factor under injected failures and the overhead percentage in clean runs; if the slowdown reduction stays below 6x or the clean-run overhead exceeds 1%, the central performance claim does not hold.
Figures




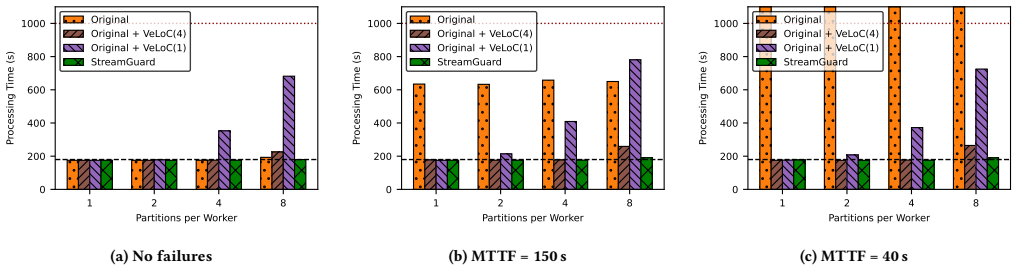
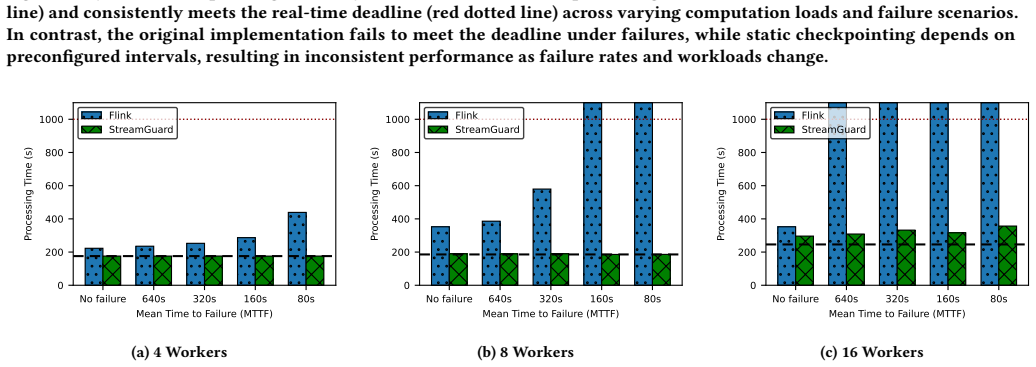
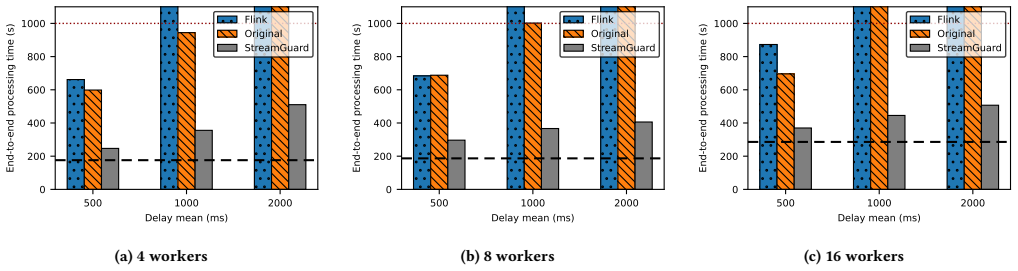
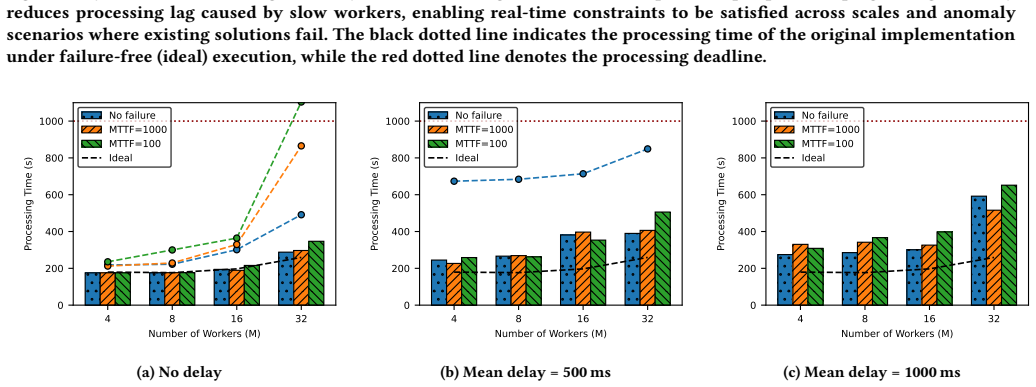
read the original abstract
Real-time scientific workflows operate on continuous data streams and must produce timely, high-quality results despite executing on complex, failure-prone infrastructure. Hardware faults, network disruptions, and performance anomalies caused by resource contention or system heterogeneity can severely degrade performance and violate real-time constraints. We focus on strengthening the resilience of the producer-consumer streaming pattern, a fundamental building block of scientific streaming workflows. We present two complementary techniques: (i) a dynamic, asynchronous, non-blocking checkpointing mechanism that preserves progress without interrupting computation, and (ii) a progress-aware load redistribution strategy that detects slow workers and proactively rebalances tasks. Together, these mechanisms maintain forward progress and balanced execution even in highly error-prone environments. Experimental results show that our approach reduces the impact of failures and performance anomalies by up to 6x, while introducing less than 1% overhead in failure-free execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StreamGuard for resilience in real-time HPC data streams. It introduces two techniques: (i) dynamic asynchronous non-blocking checkpointing that preserves progress without interrupting computation, and (ii) progress-aware load redistribution that detects slow workers and rebalances tasks. The central empirical claim is that the combined approach reduces the impact of failures and performance anomalies by up to 6x while introducing less than 1% overhead in failure-free execution.
Significance. Resilience for continuous data streams on failure-prone HPC infrastructure addresses a practical need in scientific workflows. If the low-overhead claims are substantiated by rigorous experiments, the work could provide a useful building block for producer-consumer streaming patterns.
major comments (1)
- [Abstract] Abstract: The manuscript asserts specific quantitative experimental results (up to 6x reduction in failure impact, <1% overhead) but supplies no details on benchmarks, workloads, failure models, or statistical methods. This prevents any determination of whether the data support the central claim.
Simulated Author's Rebuttal
We thank the referee for their review and for identifying the need for clearer linkage between the abstract claims and the supporting experimental details. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts specific quantitative experimental results (up to 6x reduction in failure impact, <1% overhead) but supplies no details on benchmarks, workloads, failure models, or statistical methods. This prevents any determination of whether the data support the central claim.
Authors: The abstract is a concise summary by design. The full manuscript supplies the requested details in the body: Section 4 specifies the benchmarks (synthetic and real scientific streaming workloads with given data rates and task granularities), Section 5 describes the failure models (transient node crashes, network delays, and contention-induced slowdowns) together with the measurement protocol (repeated trials, mean and standard deviation, 95% confidence intervals). These sections directly support the quantitative claims. We therefore see no need to alter the manuscript on this point, though we can add a one-sentence pointer from the abstract to Section 4 if the editor prefers. revision: no
Circularity Check
No significant circularity
full rationale
The paper describes two resilience techniques for streaming workflows and supports its claims solely with experimental measurements (up to 6x impact reduction, <1% overhead). No equations, derivations, fitted parameters, or load-bearing self-citations appear in the abstract or described content. The central results are empirical outcomes rather than any claimed first-principles reduction, so the derivation chain is empty and the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ganesh Ananthanarayanan, Srikanth Kandula, Albert Greenberg, Ion Stoica, Yi Lu, Bikas Saha, and Edward Harris. 2010. Reining in the outliers in{Map-Reduce} clusters using mantri. InOSDI’10: The 9th USENIX Symposium on Operating Systems Design and Implementation. Vancouver, Canada, 265–278
2010
-
[2]
Apache Flink. [n. d.]. Checkpoints. https://nightlies.apache.org/flink/flink-docs- stable/docs/ops/state/checkpoints/. Apache Flink Documentation, accessed: 2026-02-09
2026
-
[3]
Michael Armbrust, Tathagata Das, Joseph Torres, Burak Yavuz, Shixiong Zhu, Reynold Xin, Ali Ghodsi, Ion Stoica, and Matei Zaharia. 2018. Structured stream- ing: A declarative api for real-time applications in apache spark. InSIGMOD’18: The 2018 ACM SIGMOD International Conference on Management of Data. Houston, USA, 601–613
2018
-
[4]
Anakha V Babu, Tao Zhou, Saugat Kandel, Tekin Bicer, Zhengchun Liu, William Judge, Daniel J Ching, Yi Jiang, Sinisa Veseli, Steven Henke, et al. 2023. Deep learning at the edge enables real-time streaming ptychographic imaging.Nature Communications14, 1 (2023), 7059
2023
-
[5]
Yadu Babuji, Anna Woodard, Zhuozhao Li, Daniel S Katz, Ben Clifford, Rohan Kumar, Lukasz Lacinski, Ryan Chard, Justin M Wozniak, Ian Foster, et al. 2019. Parsl: Pervasive parallel programming in python. InHPDC’19: The 28th Inter- national Symposium on High-Performance Parallel and Distributed Computing. Phoenix, USA, 25–36
2019
-
[6]
GAUDI& Barrand, I Belyaev, P Binko, M Cattaneo, R Chytracek, G Corti, M Frank, G Gracia, J Harvey, Eric Van Herwijnen, et al. 2001. GAUDI—A software archi- tecture and framework for building HEP data processing applications.Computer physics communications140, 1-2 (2001), 45–55
2001
-
[7]
Leonardo Bautista-Gomez, Seiji Tsuboi, Dimitri Komatitsch, Franck Cappello, Naoya Maruyama, and Satoshi Matsuoka. 2011. FTI: High Performance Fault Tolerance Interface for Hybrid Systems. InSC’11: The International Conference for High Performance Computing, Networking, Storage and Analysis. Seattle, USA, 32:1–32:32
2011
-
[8]
Anne Benoit, Yishu Du, Thomas Herault, Loris Marchal, Guillaume Pallez, Lucas Perotin, Yves Robert, Hongyang Sun, and Frédéric Vivien. 2022. Checkpointing à la Young/Daly: An overview. InIC3’22: The 14th International Conference on Contemporary Computing. Noida, India, 701–710
2022
-
[9]
Anne Benoit, Lucas Perotin, Yves Robert, and Frédéric Vivien. 2024. Checkpoint- ing Strategies to Tolerate Non-Memoryless Failures on HPC Platforms.ACM Trans. Parallel Comput.11, 1 (2024), 1:1–1:26
2024
-
[10]
Tekin Bicer, Doğa Gürsoy, Vincent De Andrade, Rajkumar Kettimuthu, William Scullin, Francesco De Carlo, and Ian T Foster. 2017. Trace: A high-throughput tomographic reconstruction engine for large-scale datasets.Advanced Structural and Chemical Imaging3 (2017), 1–10
2017
-
[11]
Tekin Bicer, Wei Jiang, and Gagan Agrawal. 2010. Supporting fault tolerance in a data-intensive computing middleware. InIPDPS’10: The 24th IEEE International Symposium on Parallel and Distributed Processing. Atlanta, USA, 1–12
2010
-
[12]
Tekin Bicer, Viktor Nikitin, Selin Aslan, Doga Gürsoy, Rajkumar Kettimuthu, and Ian T Foster. 2020. Tomographic Reconstruction of Dynamic Features with Streaming Sliding Subsets. InXLOOP’20: The 2nd IEEE/ACM Annual Workshop on Extreme-Scale Experiment-in-the-Loop Computing. Virtual Event, 8–15
2020
-
[13]
Franck Cappello, Al Geist, William Gropp, Sanjay Kale, Bill Kramer, and Marc Snir. 2014. Toward exascale resilience: 2014 update.Supercomputing Frontiers and Innovations: An International Journal1, 1 (2014), 5–28
2014
-
[14]
Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. 2015. Apache flink: Stream and batch processing in a single engine.The Bulletin of the Technical Committee on Data Engineering38, 4 (2015), 28–38
2015
-
[15]
K Mani Chandy and Leslie Lamport. 1985. Distributed snapshots: Determining global states of distributed systems.ACM Transactions on Computer Systems (TOCS)3, 1 (1985), 63–75
1985
-
[16]
John T Daly. 2006. A higher order estimate of the optimum checkpoint interval for restart dumps.Future Generation Computer Systems22, 3 (2006), 303–312
2006
-
[17]
Jeffrey Dean and Luiz André Barroso. 2013. The tail at scale.Commun. ACM56, 2 (2013), 74–80
2013
-
[18]
Jeffrey Dean and Sanjay Ghemawat. 2008. MapReduce: simplified data processing on large clusters.Commun. ACM51, 1 (2008), 107–113
2008
-
[19]
Martin Dierolf, Andreas Menzel, Pierre Thibault, Philipp Schneider, Cameron M Kewish, Roger Wepf, Oliver Bunk, and Franz Pfeiffer. 2010. Ptychographic X-ray computed tomography at the nanoscale.Nature467, 7314 (2010), 436–439
2010
-
[20]
2015.Fault tolerance techniques for high-performance computing
Jack Dongarra, Thomas Herault, and Yves Robert. 2015.Fault tolerance techniques for high-performance computing. Springer
2015
-
[21]
Matthieu Dorier, Amal Gueroudji, Valérie Hayot-Sasson, Hai Duc Nguyen, Seth Ockerman, Renan Souza, Tekin Bicer, Haochen Pan, Philip Carns, Kyle Chard, et al
-
[22]
Toward a persistent event-streaming system for high-performance com- puting applications.Frontiers in High Performance Computing3 (2025), 1638203
2025
-
[23]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Kurt Ferreira, Jon Stearley, James H Laros III, Ron Oldfield, Kevin Pedretti, Ron Brightwell, Rolf Riesen, Patrick G Bridges, and Dorian Arnold. 2011. Evaluating the viability of process replication reliability for exascale systems. InSC’11: The International Conference for High Performance Computing, Networking, Storage and Analysis. Seattle, USA, 1–12
2011
-
[25]
Michael Goodrich, Carl Timmer, Vardan Gyurjyan, David Lawrence, Graham Heyes, Yatish Kumar, and Stacey Sheldon. 2023. ESnet/JLab FPGA Accelerated Transport.IEEE Transactions on Nuclear Science70, 6 (2023), 1096–1101
2023
-
[26]
Google Cloud. 2026. Google Cloud Dataflow. https://cloud.google.com/products/ dataflow. Accessed: 2026-02-09
2026
-
[27]
Gossman, Bogdan Nicolae, and Jon C
Mikaila J. Gossman, Bogdan Nicolae, and Jon C. Calhoun. 2024. Scalable I/O aggregation for asynchronous multi-level checkpointing.Future Generation Computer Systems160 (2024), 420–432
2024
-
[28]
Amal Gueroudji, Matthieu Dorier, Philip Carns, Parth Patel, Tekin Bicer, Robert Latham, Robert Ross, Kyle Chard, and Ian Foster. 2025. RESILIO: A Scalable and Composable Architecture for Tomographic Reconstruction Workflows. InSC- W’25: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. St. Louis, U...
2025
-
[29]
Salman Habib, Vitali Morozov, Nicholas Frontiere, Hal Finkel, Adrian Pope, and Katrin Heitmann. 2013. HACC: Extreme scaling and performance across diverse architectures. InSC’13: The International Conference for High Performance Computing, Networking, Storage and Analysis. Denver, USA, 1–10
2013
-
[30]
Peng Huang, Chuanxiong Guo, Jacob R Lorch, Lidong Zhou, and Yingneng Dang
-
[31]
InHotOS’17: The 16th Workshop on Hot Topics in Operating Systems
Gray failure: The Achilles’ heel of cloud-scale systems. InHotOS’17: The 16th Workshop on Hot Topics in Operating Systems. Whistler, Canada, 150–155
-
[32]
Eliu Antonio Huerta, Gabrielle Allen, Igor Andreoni, Javier M Antelis, Eti- enne Bachelet, G Bruce Berriman, Federica B Bianco, Rahul Biswas, Matias Carrasco Kind, Kyle Chard, et al . 2019. Enabling real-time multi-messenger astrophysics discoveries with deep learning.Nature Reviews Physics1, 10 (2019), 600–608
2019
-
[33]
Yongho Kim, Seongha Park, Sean Shahkarami, Rajesh Sankaran, Nicola Ferrier, and Pete Beckman. 2022. Goal-driven scheduling model in edge computing for smart city applications.J. Parallel and Distrib. Comput.167 (2022), 97–108
2022
-
[34]
Sanjeev Kulkarni, Nikunj Bhagat, Maosong Fu, Vikas Kedigehalli, Christopher Kellogg, Sailesh Mittal, Jignesh M Patel, Karthik Ramasamy, and Siddarth Taneja
-
[35]
InSIGMOD’15: The 2015 ACM SIGMOD International Conference on Management of Data
Twitter heron: Stream processing at scale. InSIGMOD’15: The 2015 ACM SIGMOD International Conference on Management of Data. Melbourne, Australia, 239–250
2015
-
[36]
Yifei Li, Ryan Chard, Yadu Babuji, Kyle Chard, Ian Foster, and Zhuozhao Li. 2024. UniFaaS: Programming across Distributed Cyberinfrastructure with Federated Function Serving. InIPDPS’24: The 38th IEEE International Parallel and Distributed Processing Symposium. San Francisco, USA, 217–229
2024
-
[37]
Gang Liu, Zeting Wang, Amelie Chi Zhou, and Rui Mao. 2024. Adaptive key par- titioning in distributed stream processing.CCF Transactions on High Performance Computing6, 2 (2024), 164–178
2024
-
[38]
Zhengchun Liu, Tekin Bicer, Rajkumar Kettimuthu, Doga Gursoy, Francesco De Carlo, and Ian Foster. 2020. TomoGAN: Low-dose synchrotron x-ray tomog- raphy with generative adversarial networks.JOSA A37, 3 (2020), 422–434
2020
-
[39]
Pengqi Lu, Yue Yue, Liang Yuan, and Yunquan Zhang. 2021. AutoFlow: hotspot- aware, dynamic load balancing for distributed stream processing. InICA3PP’21: The 21st International Conference on Algorithms and Architectures for Parallel Processing. Virtual Event, 133–151
2021
-
[40]
Smart, Emanuele Danovaro, Tiago Quintino, Dean Hildebrand, and Adrian Jackson
Nicolau Manubens, Johann Lombardi, Simon D. Smart, Emanuele Danovaro, Tiago Quintino, Dean Hildebrand, and Adrian Jackson. 2024. Exploring DAOS Interfaces and Performance. arXiv:2409.18682 [cs.DC]
-
[41]
Mustafa Rafique, Franck Cappello, and Bogdan Nicolae
Avinash Maurya, M. Mustafa Rafique, Franck Cappello, and Bogdan Nicolae. 2023. Towards Efficient I/O Pipelines using Accumulated Compression. InHIPC’23: 30th IEEE International Conference on High Performance Computing, Data, and Analytics. Goa, India, 256–265
2023
-
[42]
Mohror, A
K. Mohror, A. Moody, G. Bronevetsky, and B. R. de Supinski. 2014. Detailed Modeling and Evaluation of a Scalable Multilevel Checkpointing System.IEEE Transactions on Parallel and Distributed Systems25, 09 (2014), 2255–2263
2014
-
[43]
Hai Duc Nguyen, Tekin Bicer, Bogdan Nicolae, Rajkumar Kettimuthu, Eliu A Huerta, and Ian T Foster. 2025. Resilient execution of distributed X-ray image analysis workflows.Frontiers in High Performance Computing3 (2025), 1550855
2025
-
[44]
Hai Duc Nguyen, Zhifei Yang, and Andrew A Chien. 2021. Motivating high per- formance serverless workloads. InHiPS’21: The 1st Workshop on High Performance Serverless Computing. Virtual Event, 25–32
2021
-
[45]
Bogdan Nicolae, Adam Moody, Elsa Gonsiorowski, Kathryn Mohror, and Franck Cappello. 2019. VeloC: Towards High Performance Adaptive Asynchronous Checkpointing at Large Scale. InIPDPS’19: The 2019 IEEE International Parallel and Distributed Processing Symposium. Rio de Janeiro, Brazil, 911–920
2019
-
[46]
Bogdan Nicolae, Adam Moody, Greg Kosinovsky, Kathryn Mohror, and Franck Cappello. 2021. VELOC: VEry Low Overhead Checkpointing in the Age of Exascale. InSuperCheck’21: The First International Symposium on Checkpointing for Supercomputing. Virtual Event
2021
-
[47]
Bogdan Nicolae, Justin M Wozniak, Tekin Bicer, Hai Nguyen, Parth Patel, Haochen Pan, Amal Gueroudji, Maxime Gonthier, Valerie Hayot-Sasson, Eliu Huerta, et al. 12
-
[48]
Ine-Science’24: The 20th IEEE International Conference on e-Science
Diaspora: Resilience-enabling services for real-time distributed workflows. Ine-Science’24: The 20th IEEE International Conference on e-Science. Osaka, Japan, 1–9
-
[49]
Shadi A Noghabi, Kartik Paramasivam, Yi Pan, Navina Ramesh, Jon Bringhurst, Indranil Gupta, and Roy H Campbell. 2017. Samza: stateful scalable stream processing at LinkedIn.Proceedings of the VLDB Endowment10, 12 (2017), 1634– 1645
2017
-
[50]
Norbert Podhorszki et al. 2020. ADIOS 2: The Adaptable Input Output System. A framework for high-performance data management.SoftwareX12 (2020)
2020
-
[51]
Michael Prince, Doğa Gürsoy, Dina Sheyfer, Ryan Chard, Benoit Côté, Hannah Parraga, Barbara Frosik, Jon Tischler, and Nicholas Schwarz. 2023. Demonstrating Cross-Facility Data Processing at Scale With Laue Microdiffraction. InSC-W’23: Workshops of the International Conference for High Performance Computing, Net- work, Storage, and Analysis. Denver, USA, 2133–2139
2023
-
[52]
Charles Reiss, Alexey Tumanov, Gregory R Ganger, Randy H Katz, and Michael A Kozuch. 2012. Heterogeneity and dynamicity of clouds at scale: Google trace analysis. InSoCC’12: The 3rd ACM Symposium on Cloud Computing. San Jose, USA, 1–13
2012
-
[53]
Richard D Schlichting and Fred B Schneider. 1983. Fail-stop processors: An approach to designing fault-tolerant computing systems.ACM Transactions on Computer Systems1, 3 (1983), 222–238
1983
-
[54]
Won Wook Song, Taegeon Um, Sameh Elnikety, Myeongjae Jeon, and Byung-Gon Chun. 2023. Sponge: Fast reactive scaling for stream processing with serverless frameworks. InUSENIX ATC’23: The 2023 USENIX Annual Technical Conference. Boston, USA, 301–314
2023
-
[55]
Sebastian Steiner, Jakob Wolf, Stefan Glatzel, Anna Andreou, Jarosław M Granda, Graham Keenan, Trevor Hinkley, Gerardo Aragon-Camarasa, Philip J Kitson, Davide Angelone, et al. 2019. Organic synthesis in a modular robotic system driven by a chemical programming language.Science363, 6423 (2019), eaav2211
2019
-
[56]
Dawei Sun, Chunlin Zhang, Shang Gao, and Rajkumar Buyya. 2024. An adap- tive load balancing strategy for stateful join operator in skewed data stream environments.Future generation computer systems152 (2024), 138–151
2024
-
[57]
P Thibault, M Dierolf, A Menzel, O Bunk, C David, and F Pfeiffer. 2008. High- resolution scanning x-ray diffraction microscopy.Science321, 5887 (2008), 379– 382
2008
-
[58]
Ankit Toshniwal, Siddarth Taneja, Amit Shukla, Karthik Ramasamy, Jignesh M Patel, Sanjeev Kulkarni, Jason Jackson, Krishna Gade, Maosong Fu, Jake Donham, et al. 2014. Storm@ twitter. InSIGMOD’14: The 2014 ACM SIGMOD International Conference on Management of Data. Snowbird, USA, 147–156
2014
-
[59]
Xiaoli Yan, Nathaniel Hudson, Hyun Park, Daniel Grzenda, J Gregory Pauloski, Marcus Schwarting, Haochen Pan, Hassan Harb, Samuel Foreman, Chris Knight, et al. 2025. MOFA: Discovering Materials for Carbon Capture with a GenAI-and Simulation-Based Workflow.arXiv preprint arXiv:2501.10651(2025)
-
[60]
John W Young. 1974. A first order approximation to the optimum checkpoint interval.Commun. ACM17, 9 (1974), 530–531
1974
-
[61]
Matei Zaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, and Ion Stoica. 2013. Discretized streams: Fault-tolerant streaming computation at scale. InSOSP’13: The 24th ACM Symposium on Operating Systems Principles. Farmington, USA, 423–438. 13
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.