GraspLLM: Towards Zero-Shot Generalization on Text-Attributed Graphs with LLMs
Pith reviewed 2026-06-27 09:39 UTC · model grok-4.3
The pith
GraspLLM aligns motif-derived structural patterns from text-attributed graphs into LLM token space to improve zero-shot transfer across datasets and tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
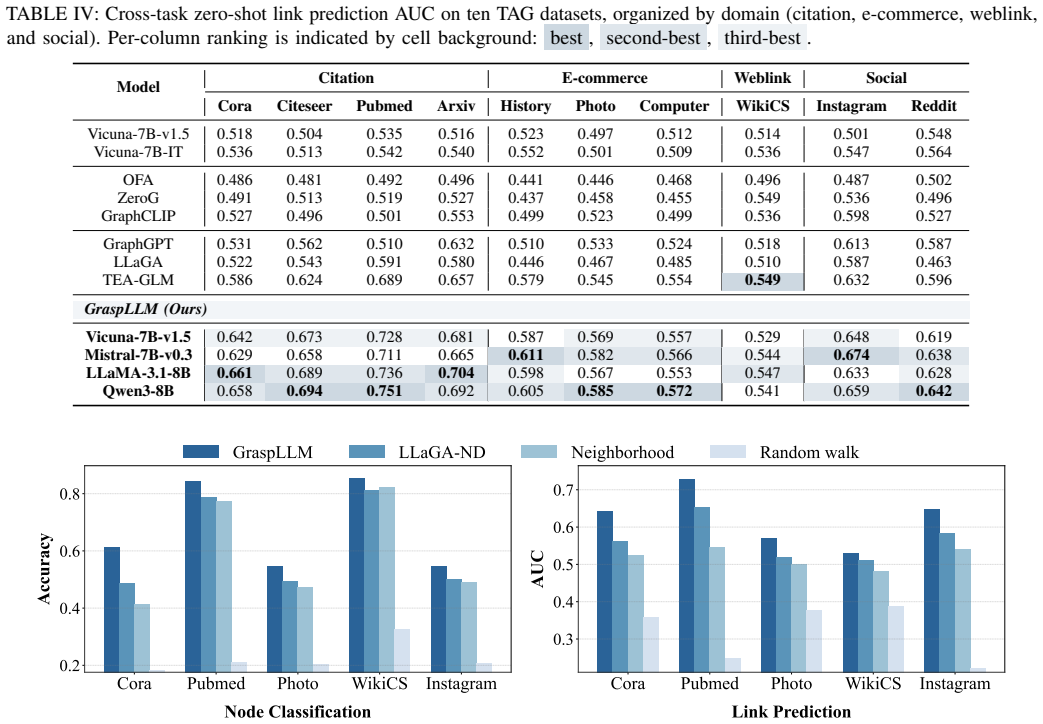
GraspLLM represents node texts from different graphs in a unified semantic space with a frozen general embedding model, performs motif-aware contrastive learning across multiple motif-induced adjacency matrices to extract dataset-agnostic structural information, extracts the most contextually relevant subgraph for each target node with an optimal contextual subgraph, and aligns these subgraphs to LLM token space via an alignment projector; experiments on diverse TAG benchmarks show consistent outperformance over prior LLM-based methods, especially under zero-shot conditions.
What carries the argument
Motif-aware contrastive learning across multiple motif-induced adjacency matrices, followed by optimal contextual subgraph selection and an alignment projector into LLM token space.
If this is right
- The method yields higher accuracy than earlier LLM-based TAG approaches on standard benchmark collections.
- Performance gains are largest when no task-specific examples from the target dataset are available.
- A single trained projector supports multiple graph domains and prediction objectives without further adaptation.
- Structural information extracted via motifs transfers independently of the original graph's domain.
Where Pith is reading between the lines
- The same motif-to-token alignment could be tested on graphs whose node texts are generated rather than observed.
- If the projector is kept fixed, one could measure how much additional gain comes from updating only the motif contrastive stage on new data.
- The approach invites direct comparison with pure graph foundation models that avoid LLMs entirely.
Load-bearing premise
Motif-based contrastive signals learned from one collection of graphs produce structural features that remain useful when the same projector is applied to entirely new graphs and tasks.
What would settle it
On a held-out set of TAG datasets and zero-shot tasks, if GraspLLM accuracy falls to or below the best prior LLM baseline, the transfer claim is false.
Figures






read the original abstract
Research on Text-Attributed Graphs (TAGs) has gained significant attention recently due to its broad applications across various real-world data scenarios, such as citation networks, e-commerce platforms, social media, and web pages. Inspired by the remarkable semantic understanding ability of Large Language Models (LLMs), there have been numerous attempts to integrate LLMs into TAGs. However, existing methods still struggle to generalize across diverse graphs and tasks, and their ability to capture transferable graph structural patterns remains limited. To address this, we introduce the GraspLLM, a framework that combines Graph structural comprehension with semantic understanding prowess of LLMs to enhance the cross-dataset and cross-task generalizability. Specifically, we represent node texts from different graphs in a unified semantic space with a frozen general embedding model, on top of which we perform motif-aware contrastive learning across multiple motif-induced adjacency matrices to extract dataset-agnostic structural information. Then, with our proposed optimal contextual subgraph, we extract the most contextually relevant subgraph for each target node and align these subgraphs to the token space of LLM via an alignment projector. Extensive experiments on TAG benchmark datasets spanning diverse domains reveal that GraspLLM consistently outperforms previous LLM-based methods for TAGs, especially in zero-shot scenarios, highlighting its strong generalizability across different datasets and tasks. Our code is available at https://github.com/Heinz217/GraspLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GraspLLM, a framework for zero-shot generalization on Text-Attributed Graphs (TAGs). It represents node texts via a frozen general embedding model, applies motif-aware contrastive learning across multiple motif-induced adjacency matrices to extract dataset-agnostic structural information, extracts an optimal contextual subgraph per target node, and aligns the subgraphs to LLM token space via a projector. The central claim is that this yields consistent outperformance over prior LLM-based TAG methods, especially in zero-shot cross-dataset and cross-task settings, with code released.
Significance. If the empirical claims and the transferability of the learned structural features hold, the work would be significant for LLM-graph integration, as it directly targets the generalization limitations of existing methods across domains such as citation networks, e-commerce, and social media. The use of a frozen embedder plus contrastive structural alignment is a reasonable combination, and the code release supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that 'extensive experiments... reveal that GraspLLM consistently outperforms previous LLM-based methods... especially in zero-shot scenarios' is presented without any quantitative results, baselines, datasets, metrics, or error bars. This absence makes it impossible to evaluate whether the data support the central generalization claim.
- [Abstract / Proposed Method] Method description (motif-aware contrastive learning paragraph): the framework asserts that contrastive learning over multiple motif-induced adjacency matrices produces 'dataset-agnostic structural information' that transfers in zero-shot settings. No motifs are enumerated, no ablation on motif selection is referenced, and no cross-domain structural similarity analysis (e.g., motif frequency distributions across citation vs. e-commerce graphs) is provided; this assumption is load-bearing for the zero-shot cross-dataset result.
minor comments (1)
- [Abstract] The GitHub link is supplied, which aids reproducibility; ensure the released code includes the exact motif definitions, projector architecture, and all experimental configurations referenced in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments... reveal that GraspLLM consistently outperforms previous LLM-based methods... especially in zero-shot scenarios' is presented without any quantitative results, baselines, datasets, metrics, or error bars. This absence makes it impossible to evaluate whether the data support the central generalization claim.
Authors: We agree that the abstract would be strengthened by including quantitative evidence. In the revised version we will add specific highlights such as average accuracy/F1 improvements over the strongest baselines in zero-shot cross-dataset settings, the main datasets used, and a note on multiple-run error bars. This change directly addresses the concern while keeping the abstract concise. revision: yes
-
Referee: [Abstract / Proposed Method] Method description (motif-aware contrastive learning paragraph): the framework asserts that contrastive learning over multiple motif-induced adjacency matrices produces 'dataset-agnostic structural information' that transfers in zero-shot settings. No motifs are enumerated, no ablation on motif selection is referenced, and no cross-domain structural similarity analysis (e.g., motif frequency distributions across citation vs. e-commerce graphs) is provided; this assumption is load-bearing for the zero-shot cross-dataset result.
Authors: The body of the manuscript enumerates the motifs (2-paths, triangles, 4-cycles) in Section 3.2 and reports motif-selection ablations in the experimental section. However, we acknowledge that the abstract paragraph does not list them and that an explicit cross-domain motif-frequency comparison is absent. We will revise the abstract to name the motifs and add a supporting analysis (new figure or table) showing motif distributions across citation and e-commerce graphs to substantiate the dataset-agnostic claim. revision: yes
Circularity Check
No significant circularity; framework combines standard components without self-referential reduction.
full rationale
The paper's derivation chain consists of applying a frozen embedding model, performing motif-aware contrastive learning on motif-induced adjacency matrices, extracting contextual subgraphs, and aligning via a projector to LLM token space. These steps are presented as a novel combination of existing techniques rather than any quantity being defined in terms of itself or a prediction being statistically forced by a fitted input. No equations or self-citations are shown that would make the zero-shot generalization claim equivalent to the inputs by construction. The central claims rest on experimental outcomes across datasets, which are externally falsifiable and not tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Can gnn be good adapter for llms?
X. Huang, K. Han, Y . Yang, D. Bao, Q. Tao, Z. Chai, and Q. Zhu, “Can gnn be good adapter for llms?” in Proceedings of the ACM web conference 2024, 2024, pp. 893–904
2024
-
[2]
Domain-informed negative sampling strategies for dy- namic graph embedding in meme stock-related social networks,
Y . Hui, I. M. Zwetsloot, S. Trimborn, and S. Rudinac, “Domain-informed negative sampling strategies for dy- namic graph embedding in meme stock-related social networks,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 518–529
2025
-
[3]
Ogb-lsc: A large-scale challenge for machine learning on graphs,
W. Hu, M. Fey, H. Ren, M. Nakata, Y . Dong, and J. Leskovec, “Ogb-lsc: A large-scale challenge for machine learning on graphs,”arXiv preprint arXiv:2103.09430, 2021
arXiv 2021
-
[4]
Stmgf: an effective spatial-temporal multi-granularity framework for traffic forecasting,
Z. Zhao, H. Yuan, N. Jiang, M. Chen, N. Liu, and Z. Li, “Stmgf: an effective spatial-temporal multi-granularity framework for traffic forecasting,” inInternational Con- ference on Database Systems for Advanced Applications. Springer, 2024, pp. 235–245
2024
-
[5]
Learning to extract symbolic knowledge from the world wide web,
M. Craven, A. McCallum, D. PiPasquo, T. Mitchell, and D. Freitag, “Learning to extract symbolic knowledge from the world wide web,” Tech. Rep., 1998
1998
-
[6]
Text-space graph foundation models: Comprehensive benchmarks and new insights,
Z. Chen, H. Mao, J. Liu, Y . Song, B. Li, W. Jin, B. Fatemi, A. Tsitsulin, B. Perozzi, H. Liuet al., “Text-space graph foundation models: Comprehensive benchmarks and new insights,”Advances in Neural Information Processing Systems, vol. 37, pp. 7464–7492, 2024
2024
-
[7]
Large language models on graphs: A comprehensive survey,
B. Jin, G. Liu, C. Han, M. Jiang, H. Ji, and J. Han, “Large language models on graphs: A comprehensive survey,” IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 12, pp. 8622–8642, 2024
2024
-
[8]
When do llms help with node clas- sification? a comprehensive analysis,
X. Wu, Y . Shen, F. Ge, C. Shan, Y . Jiao, X. Sun, and H. Cheng, “When do llms help with node clas- sification? a comprehensive analysis,”arXiv preprint arXiv:2502.00829, 2025
arXiv 2025
-
[9]
A comprehensive study on text-attributed graphs: Benchmarking and rethinking,
H. Yan, C. Li, R. Long, C. Yan, J. Zhao, W. Zhuang, J. Yin, P. Zhang, W. Han, H. Sunet al., “A comprehensive study on text-attributed graphs: Benchmarking and rethinking,” Advances in Neural Information Processing Systems, vol. 36, pp. 17 238–17 264, 2023
2023
-
[10]
Large language models meet nlp: A survey,
L. Qin, Q. Chen, X. Feng, Y . Wu, Y . Zhang, Y . Li, M. Li, W. Che, and P. S. Yu, “Large language models meet nlp: A survey,”Frontiers of Computer Science, vol. 20, no. 11, p. 2011361, 2026
2026
-
[11]
A survey of large language models,
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Donget al., “A survey of large language models,”arXiv preprint arXiv:2303.18223, vol. 1, no. 2, pp. 1–124, 2023
Pith/arXiv arXiv 2023
-
[12]
A survey on multimodal large language models,
S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, and E. Chen, “A survey on multimodal large language models,”National Science Review, vol. 11, no. 12, p. nwae403, 2024
2024
-
[14]
H. Liang, X. Ma, Z. Liu, Z. H. Wong, Z. Zhao, Z. Meng, R. He, C. Shen, Q. Cai, Z. Hanet al., “Dataflow: An llm-driven framework for unified data preparation and workflow automation in the era of data-centric ai,”arXiv preprint arXiv:2512.16676, 2025
arXiv 2025
-
[15]
A survey of multimodal large language model from a data-centric perspective,
T. Bai, H. Liang, B. Wan, Y . Xu, X. Li, S. Li, L. Yang, B. Li, Y . Wang, B. Cuiet al., “A survey of multimodal large language model from a data-centric perspective,” arXiv preprint arXiv:2405.16640, 2024
arXiv 2024
-
[16]
J. Guo, L. Du, H. Liu, M. Zhou, X. He, and S. Han, “Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmark- ing,”arXiv preprint arXiv:2305.15066, 2023
arXiv 2023
-
[17]
Exploring the potential of large language models (llms) in learning on graphs,
Z. Chen, H. Mao, H. Li, W. Jin, H. Wen, X. Wei, S. Wang, D. Yin, W. Fan, H. Liuet al., “Exploring the potential of large language models (llms) in learning on graphs,” ACM SIGKDD Explorations Newsletter, vol. 25, no. 2, pp. 42–61, 2024
2024
-
[18]
Llms are noisy oracles! llm-based noise-aware graph active learning for node classification,
Z. Sheng, W. Guo, Y . Shao, W. Zhang, and B. Cui, “Llms are noisy oracles! llm-based noise-aware graph active learning for node classification,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, ser. KDD ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 2526–2537. [Online]. Available: https:/...
-
[19]
A survey of graph meets large language model: Progress and future directions,
Y . Li, Z. Li, P. Wang, J. Li, X. Sun, H. Cheng, and J. X. Yu, “A survey of graph meets large language model: Progress and future directions,”arXiv preprint arXiv:2311.12399, 2023
arXiv 2023
-
[20]
Opengraph: Towards open graph foundation models,
L. Xia, B. Kao, and C. Huang, “Opengraph: Towards open graph foundation models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 2365–2379
2024
-
[21]
Grenade: Graph-centric language model for self-supervised representation learning on text-attributed graphs,
Y . Li, K. Ding, and K. Lee, “Grenade: Graph-centric language model for self-supervised representation learning on text-attributed graphs,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 2745–2757
2023
-
[22]
Generalization principles for inference over text-attributed graphs with large language models,
H. P. Wang, S. Liu, R. Wei, and P. Li, “Generalization principles for inference over text-attributed graphs with large language models,” inForty-second International Conference on Machine Learning, 2025
2025
-
[23]
Label-free node classification on graphs with large language models (llms),
Z. Chen, H. Mao, H. Wen, H. Han, W. Jin, H. Zhang, H. Liu, and J. Tang, “Label-free node classification on graphs with large language models (llms),” inInterna- tional Conference on Learning Representations, vol. 2024, 2024, pp. 31 632–31 655
2024
-
[24]
Walklm: A uniform language model fine-tuning framework for attributed graph embedding,
Y . Tan, Z. Zhou, H. Lv, W. Liu, and C. Yang, “Walklm: A uniform language model fine-tuning framework for attributed graph embedding,”Advances in neural infor- mation processing systems, vol. 36, pp. 13 308–13 325, 2023
2023
-
[25]
Uniglm: Training one unified language model for text-attributed graphs embedding,
Y . Fang, D. Fan, S. Ding, N. Liu, and Q. Tan, “Uniglm: Training one unified language model for text-attributed graphs embedding,” inProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, 2025, pp. 973–981
2025
-
[26]
Dynamic bundling with large language models for zero-shot inference on text-attributed graphs,
Y . Zhao, Q. Zhang, X. Luo, W. Zhang, Z. Xiao, W. Ju, P. S. Yu, and M. Zhang, “Dynamic bundling with large language models for zero-shot inference on text-attributed graphs,”Advances in Neural Information Processing Systems, vol. 38, pp. 155 296–155 326, 2026
2026
-
[27]
Can large language models analyze graphs like professionals? a benchmark, datasets and models,
X. Li, W. Chen, Q. Chu, H. Li, Z. Sun, R. Li, C. Qian, Y . Wei, Z. Liu, C. Shiet al., “Can large language models analyze graphs like professionals? a benchmark, datasets and models,”Advances in Neural Information Processing Systems, vol. 37, pp. 141 045–141 070, 2024
2024
-
[28]
Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings,
D. Wang, Y . Zuo, F. Li, and J. Wu, “Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 5950–5973
2024
-
[29]
Gofa: A generative one-for-all model for joint graph language modeling,
L. Kong, J. Feng, H. Liu, C. Huang, J. Huang, Y . Chen, and M. Zhang, “Gofa: A generative one-for-all model for joint graph language modeling,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 40 792–40 823
2025
-
[30]
Can we soft prompt llms for graph learning tasks?
Z. Liu, X. He, Y . Tian, and N. V . Chawla, “Can we soft prompt llms for graph learning tasks?” inCompanion proceedings of the ACM web conference 2024, 2024, pp. 481–484
2024
-
[31]
Graphgpt: Graph instruction tuning for large language models,
J. Tang, Y . Yang, W. Wei, L. Shi, L. Su, S. Cheng, D. Yin, and C. Huang, “Graphgpt: Graph instruction tuning for large language models,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 491– 500
2024
-
[32]
Llaga: Large language and graph assistant,
R. Chen, T. Zhao, A. Jaiswal, N. Shah, and Z. Wang, “Llaga: Large language and graph assistant,”arXiv preprint arXiv:2402.08170, 2024
arXiv 2024
-
[33]
Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs,
Y . He, Y . Sui, X. He, and B. Hooi, “Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, 2025, pp. 448–459
2025
-
[34]
Semi-supervised classifica- tion with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classifica- tion with graph convolutional networks,”arXiv preprint arXiv:1609.02907, 2016
Pith/arXiv arXiv 2016
-
[35]
P. Veliˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y . Bengio, “Graph attention networks,”arXiv preprint arXiv:1710.10903, 2017
Pith/arXiv arXiv 2017
-
[36]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[37]
Multi-task self-supervised graph neural networks enable stronger task generalization,
M. Ju, T. Zhao, Q. Wen, W. Yu, N. Shah, Y . Ye, and C. Zhang, “Multi-task self-supervised graph neural networks enable stronger task generalization,”arXiv preprint arXiv:2210.02016, 2022
arXiv 2022
-
[38]
Graph contrastive learning with adaptive augmentation,
Y . Zhu, Y . Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Graph contrastive learning with adaptive augmentation,” inProceedings of the web conference 2021, 2021, pp. 2069–2080
2021
-
[39]
Simgrace: A simple framework for graph contrastive learning without data augmentation,
J. Xia, L. Wu, J. Chen, B. Hu, and S. Z. Li, “Simgrace: A simple framework for graph contrastive learning without data augmentation,” inProceedings of the ACM web conference 2022, 2022, pp. 1070–1079
2022
-
[40]
Gcc: Graph contrastive coding for graph neural network pre-training,
J. Qiu, Q. Chen, Y . Dong, J. Zhang, H. Yang, M. Ding, K. Wang, and J. Tang, “Gcc: Graph contrastive coding for graph neural network pre-training,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 1150– 1160
2020
-
[41]
Do transformers really perform badly for graph representation?
C. Ying, T. Cai, S. Luo, S. Zheng, G. Ke, D. He, Y . Shen, and T.-Y . Liu, “Do transformers really perform badly for graph representation?”Advances in neural information processing systems, vol. 34, pp. 28 877–28 888, 2021
2021
-
[42]
Isgcl: Informative sample-aware progressive graph contrastive learning,
J. Zeng, P. Wang, L. Ma, J. Tao, and X. Guan, “Isgcl: Informative sample-aware progressive graph contrastive learning,” in2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2025, pp. 1787–1799
2025
-
[43]
P. Veliˇckovi´c, W. Fedus, W. L. Hamilton, P. Liò, Y . Bengio, and R. D. Hjelm, “Deep graph infomax,”arXiv preprint arXiv:1809.10341, 2018
Pith/arXiv arXiv 2018
-
[44]
Deep graph contrastive representation learning,
Y . Zhu, Y . Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Deep graph contrastive representation learning,”arXiv preprint arXiv:2006.04131, 2020
arXiv 2006
-
[45]
From canonical correlation analysis to self-supervised graph neural networks,
H. Zhang, Q. Wu, J. Yan, D. Wipf, and P. S. Yu, “From canonical correlation analysis to self-supervised graph neural networks,”Advances in Neural Information Processing Systems, vol. 34, pp. 76–89, 2021
2021
-
[46]
Think-on-graph: Deep and responsible reasoning of large language model on knowl- edge graph,
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y . Gong, L. Ni, H.-Y . Shum, and J. Guo, “Think-on-graph: Deep and responsible reasoning of large language model on knowl- edge graph,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 3868–3898
2024
-
[47]
Plan-on-graph: Self-correcting adaptive planning of large language model on knowledge graphs,
L. Chen, P. Tong, Z. Jin, Y . Sun, J. Ye, and H. Xiong, “Plan-on-graph: Self-correcting adaptive planning of large language model on knowledge graphs,”Advances in Neural Information Processing Systems, vol. 37, pp. 37 665–37 691, 2024
2024
-
[48]
Agrag: Advanced graph-based retrieval-augmented generation for llms,
Y . Wang, H. Li, F. Teng, and L. Chen, “Agrag: Advanced graph-based retrieval-augmented generation for llms,” arXiv preprint arXiv:2511.05549, 2025
arXiv 2025
-
[49]
An llm-guided query-aware inference system for gnn models on large knowledge graphs,
W. Afandi, H. Abdallah, A. Aboulnaga, and E. Mansour, “An llm-guided query-aware inference system for gnn models on large knowledge graphs,”arXiv preprint arXiv:2603.04545, 2026
Pith/arXiv arXiv 2026
-
[50]
Simteg: A frustratingly simple approach improves textual graph learning,
K. Duan, Q. Liu, T.-S. Chua, S. Yan, W. T. Ooi, Q. Xie, and J. He, “Simteg: A frustratingly simple approach improves textual graph learning,”arXiv preprint arXiv:2308.02565, 2023
arXiv 2023
-
[51]
Efficient tuning and inference for large language models on textual graphs,
Y . Zhu, Y . Wang, H. Shi, and S. Tang, “Efficient tuning and inference for large language models on textual graphs,” arXiv preprint arXiv:2401.15569, 2024
arXiv 2024
-
[52]
Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning,
X. He, X. Bresson, T. Laurent, A. Perold, Y . LeCun, and B. Hooi, “Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning,” inInternational conference on learning representations, vol. 2024, 2024, pp. 5711–5732
2024
-
[53]
Language models are few-shot learn- ers,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learn- ers,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[54]
One for all: Towards training one graph model for all classification tasks,
H. Liu, J. Feng, L. Kong, N. Liang, D. Tao, Y . Chen, and M. Zhang, “One for all: Towards training one graph model for all classification tasks,” inInternational conference on learning representations, vol. 2024, 2024, pp. 20 188– 20 210
2024
-
[55]
Zerog: Investigating cross-dataset zero-shot transferability in graphs,
Y . Li, P. Wang, Z. Li, J. X. Yu, and J. Li, “Zerog: Investigating cross-dataset zero-shot transferability in graphs,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 1725–1735
2024
-
[56]
Graphclip: Enhancing transferabil- ity in graph foundation models for text-attributed graphs,
Y . Zhu, H. Shi, X. Wang, Y . Liu, Y . Wang, B. Peng, C. Hong, and S. Tang, “Graphclip: Enhancing transferabil- ity in graph foundation models for text-attributed graphs,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 2183–2197
2025
-
[57]
Llm2vec: Large language models are secretly powerful text encoders,
P. BehnamGhader, V . Adlakha, M. Mosbach, D. Bah- danau, N. Chapados, and S. Reddy, “Llm2vec: Large language models are secretly powerful text encoders,” arXiv preprint arXiv:2404.05961, 2024
arXiv 2024
-
[58]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[59]
Graphprompt: Unifying pre-training and downstream tasks for graph neural networks,
Z. Liu, X. Yu, Y . Fang, and X. Zhang, “Graphprompt: Unifying pre-training and downstream tasks for graph neural networks,” inProceedings of the ACM web conference 2023, 2023, pp. 417–428
2023
-
[60]
Graphagent: Agentic graph language assistant,
Y . Yang, J. Tang, L. Xia, X. Zou, Y . Liang, and C. Huang, “Graphagent: Agentic graph language assistant,” inPro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 26 360–26 379
2025
-
[61]
Language is all a graph needs,
R. Ye, C. Zhang, R. Wang, S. Xu, and Y . Zhang, “Language is all a graph needs,” inFindings of the association for computational linguistics: EACL 2024, 2024, pp. 1955–1973
2024
-
[62]
Can language models solve graph problems in natural language?
H. Wang, S. Feng, T. He, Z. Tan, X. Han, and Y . Tsvetkov, “Can language models solve graph problems in natural language?”Advances in Neural Information Processing Systems, vol. 36, pp. 30 840–30 861, 2023
2023
-
[63]
Qwen3 embed- ding: Advancing text embedding and reranking through foundation models,
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Linet al., “Qwen3 embed- ding: Advancing text embedding and reranking through foundation models,”arXiv preprint arXiv:2506.05176, 2025
Pith/arXiv arXiv 2025
-
[64]
An analysis of approximations for maximizing submodular set functions—i,
G. L. Nemhauser, L. A. Wolsey, and M. L. Fisher, “An analysis of approximations for maximizing submodular set functions—i,”Mathematical programming, vol. 14, no. 1, pp. 265–294, 1978
1978
-
[65]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,
W.-L. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalezet al., “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,”See https://vicuna. lmsys. org (accessed 14 April 2023), vol. 2, no. 3, p. 6, 2023
2023
-
[66]
Augmenting low-resource text classi- fication with graph-grounded pre-training and prompting,
Z. Wen and Y . Fang, “Augmenting low-resource text classi- fication with graph-grounded pre-training and prompting,” inProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023, pp. 506–516
2023
-
[67]
Citeseer: An automatic citation indexing system,
C. L. Giles, K. D. Bollacker, and S. Lawrence, “Citeseer: An automatic citation indexing system,” inProceedings of the third ACM conference on Digital libraries, 1998, pp. 89–98
1998
-
[68]
Collective classification in network data,
P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad, “Collective classification in network data,”AI magazine, vol. 29, no. 3, pp. 93–93, 2008
2008
-
[69]
Wiki-cs: A wikipedia-based benchmark for graph neural networks,
P. Mernyei and C. Cangea, “Wiki-cs: A wikipedia-based benchmark for graph neural networks,”arXiv preprint arXiv:2007.02901, 2020
arXiv 2007
-
[70]
Node- former: A scalable graph structure learning transformer for node classification,
Q. Wu, W. Zhao, Z. Li, D. P. Wipf, and J. Yan, “Node- former: A scalable graph structure learning transformer for node classification,”Advances in neural information processing systems, vol. 35, pp. 27 387–27 401, 2022
2022
-
[71]
Difformer: Scalable (graph) transformers in- duced by energy constrained diffusion,
Q. Wu, C. Yang, W. Zhao, Y . He, D. Wipf, and J. Yan, “Difformer: Scalable (graph) transformers in- duced by energy constrained diffusion,”arXiv preprint arXiv:2301.09474, 2023
arXiv 2023
-
[72]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[73]
Roberta: A robustly optimized bert pretraining approach,
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019
Pith/arXiv arXiv 1907
-
[74]
Text embeddings by weakly-supervised contrastive pre-training,
L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, and F. Wei, “Text embeddings by weakly-supervised contrastive pre-training,”arXiv preprint arXiv:2212.03533, 2022
Pith/arXiv arXiv 2022
-
[75]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
2019
-
[76]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huanget al., “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
Pith/arXiv arXiv 2024
-
[77]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[78]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Ka- dian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[79]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnieret al., “Mistral 7b,”CoRR, vol. abs/2310.06825
-
[80]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[81]
Exploring format consistency for instruction tuning,
S. Liang, R. Tian, K. Zhu, Y . Qin, H. Wang, X. Cong, Z. Liu, X. Liu, and M. Sun, “Exploring format consistency for instruction tuning,”arXiv preprint arXiv:2307.15504, 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.