Self-Play Reinforcement Learning under Imperfect Information in Big 2
Pith reviewed 2026-06-30 16:38 UTC · model grok-4.3
The pith
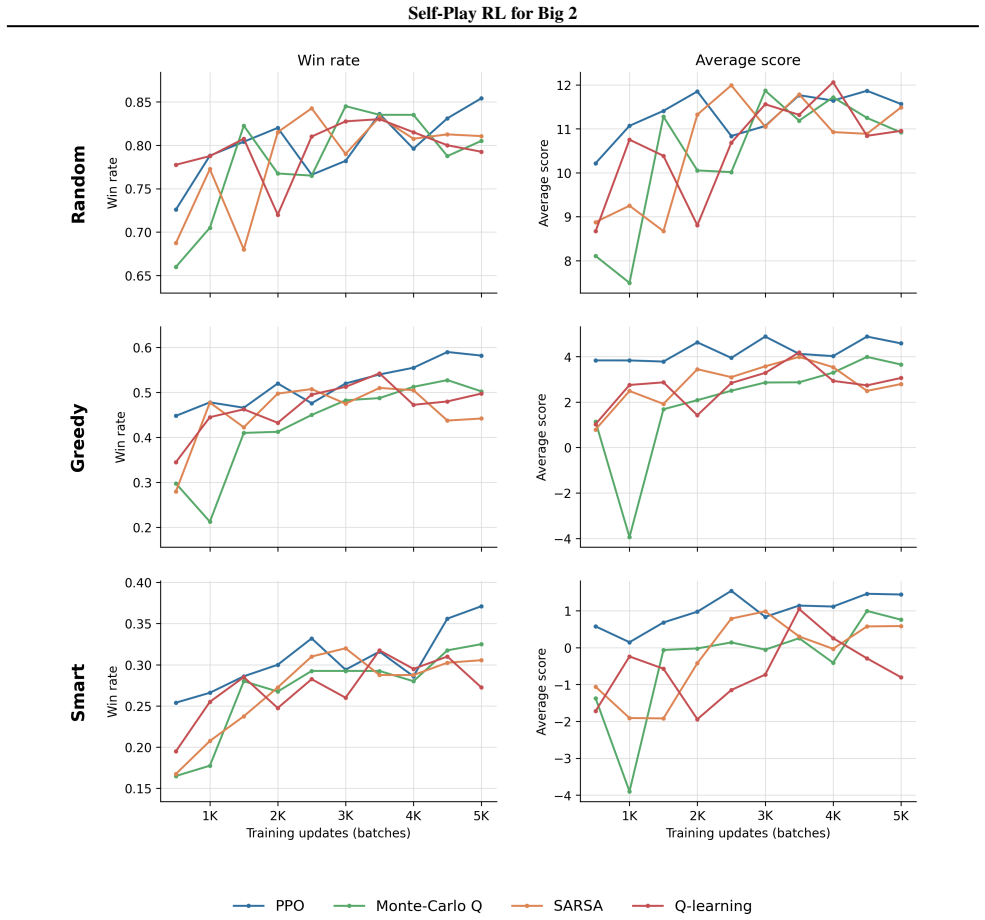
Under identical conditions, PPO outperforms Monte Carlo Q approximation, SARSA, and Q-learning in self-play training for the imperfect-information card game Big 2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a self-play RL framework for Big 2 that enables controlled comparisons between policy-gradient and value-approximating agents. Under a common environment, input representation, training budget, and evaluation protocol, PPO outperforms Monte Carlo Q approximation, SARSA, and Q-learning against random, greedy, and heuristic Big 2 opponents. We further find that moderate entropy regularization improves PPO by preventing the policy from becoming overly deterministic, and that current-policy self-play provides a stronger finite-budget curriculum than checkpoint self-play or fixed-opponent training. Together, these results show that Big 2 is a useful controlled setting for studying deep
What carries the argument
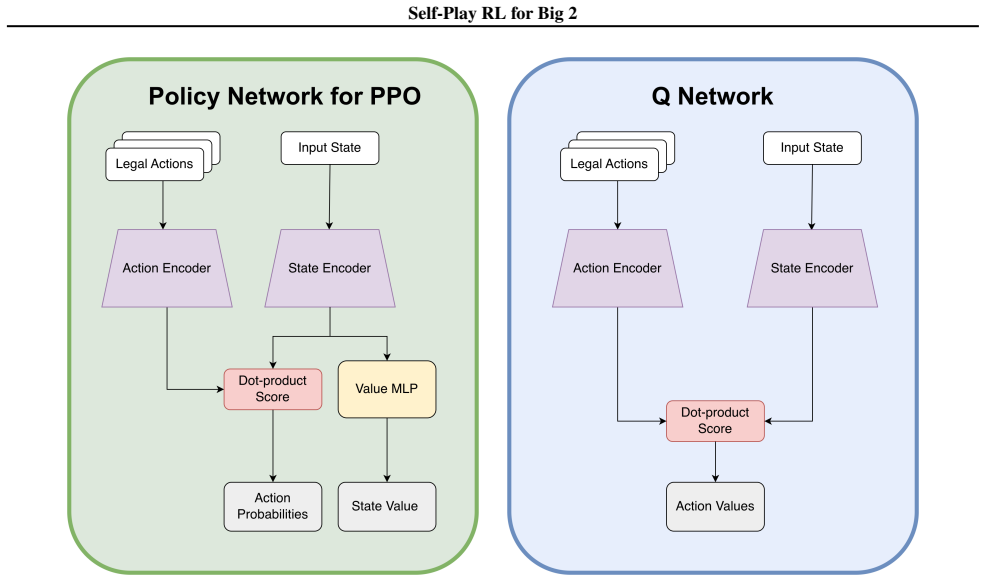
self-play RL framework that standardizes environment, input representation, training budget, and evaluation protocol for comparing PPO against value-based methods in Big 2
If this is right
- PPO records higher win rates than the tested value-based methods against random, greedy, and heuristic opponents in Big 2.
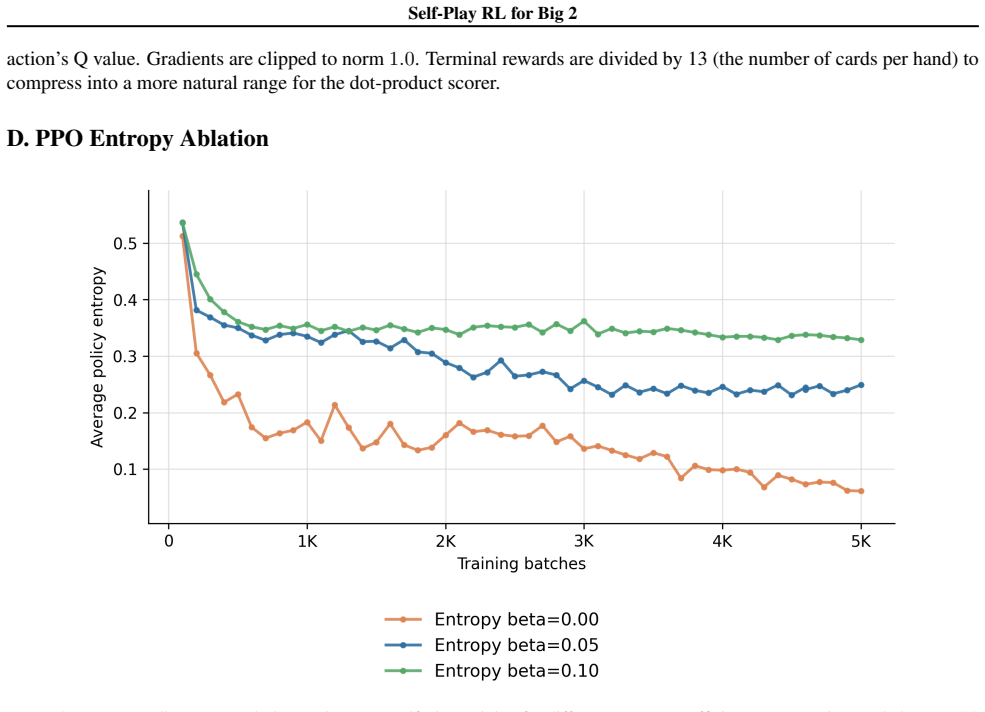
- Moderate entropy regularization reduces premature convergence to deterministic policies during PPO training.
- Current-policy self-play yields stronger learning progress than checkpoint self-play or fixed-opponent training under limited budgets.
- Big 2 functions as a repeatable benchmark for RL methods that must handle imperfect information, multiplayer non-stationarity, and variable action sets.
Where Pith is reading between the lines
- The same standardized comparison setup could be reused to test newer RL algorithms on Big 2 without re-deriving the environment.
- Results may indicate that policy gradients handle sparse rewards and hidden information more readily than value approximation when action spaces change per state.
- Longer training runs or different opponent curricula could be tested to check whether value-based methods close the gap once the policy stabilizes.
Load-bearing premise
The shared environment, input representation, training budget, and evaluation protocol contain no hidden implementation choices that systematically favor policy-gradient methods over value-based ones.
What would settle it
An independent reimplementation of the same framework and protocol that finds value-based methods matching or exceeding PPO win rates against the same opponent classes when only random seeds or minor encoding details are altered.
Figures
read the original abstract
Imperfect-information multiplayer games test whether agents can act under hidden information, sparse rewards, and non-stationary opponents. We study these challenges in Big 2, a four-player imperfect-information card game. We develop a self-play RL framework for Big 2 that enables controlled comparisons between policy-gradient and value-approximating agents. Under a common environment, input representation, training budget, and evaluation protocol, PPO outperforms Monte Carlo Q approximation, SARSA, and Q-learning against random, greedy, and heuristic Big 2 opponents. We further find that moderate entropy regularization improves PPO by preventing the policy from becoming overly deterministic, and that current-policy self-play provides a stronger finite-budget curriculum than checkpoint self-play or fixed-opponent training. Together, these results show that Big 2 is a useful controlled setting for studying deep RL under imperfect information, multiplayer interaction, delayed rewards, and variable action sets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a self-play RL framework for the four-player imperfect-information card game Big 2. It performs controlled comparisons between PPO and value-based methods (Monte Carlo Q approximation, SARSA, Q-learning) under a common environment, input representation, training budget, and evaluation protocol. The results indicate that PPO outperforms the other methods against random, greedy, and heuristic opponents. Additional findings include benefits from moderate entropy regularization in PPO and the superiority of current-policy self-play over checkpoint self-play or fixed-opponent training.
Significance. If the experimental controls are as described, this work provides a valuable controlled testbed for studying deep RL challenges in imperfect information, multiplayer, sparse reward settings. The identification of PPO's advantages and the effects of entropy and self-play curricula could inform algorithm design in similar domains. The use of a standard game like Big 2 with variable action sets is a positive aspect for reproducibility and comparability.
major comments (2)
- [Abstract] Abstract: the claim that PPO outperforms Monte Carlo Q approximation, SARSA, and Q-learning is stated without any numerical win rates, margins, variance estimates, or statistical tests. This makes the magnitude and reliability of the central comparative result impossible to assess from the provided text.
- The central claim requires literally identical environment dynamics, state encoding, action masking, reward scaling, training steps, and opponent sampling across PPO and the value-based agents. No pseudocode, hyperparameter tables, or implementation notes are supplied to confirm equivalent exploration mechanisms or curricula, rendering the outperformance claim unverifiable and load-bearing for the paper's conclusions.
minor comments (2)
- Add explicit variance estimates or confidence intervals to all reported performance comparisons.
- Clarify the precise form of the input representation and any action masking used for all agents.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight the need for quantitative support in the abstract and greater transparency in the experimental protocol. We agree that both points require revision and will incorporate the requested details in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that PPO outperforms Monte Carlo Q approximation, SARSA, and Q-learning is stated without any numerical win rates, margins, variance estimates, or statistical tests. This makes the magnitude and reliability of the central comparative result impossible to assess from the provided text.
Authors: We agree that the abstract should report concrete performance numbers. In the revised manuscript we will add the observed win rates (with standard deviations across independent runs) against each opponent type, the performance margins relative to the value-based baselines, and a brief statement on the statistical significance of the differences. revision: yes
-
Referee: [—] The central claim requires literally identical environment dynamics, state encoding, action masking, reward scaling, training steps, and opponent sampling across PPO and the value-based agents. No pseudocode, hyperparameter tables, or implementation notes are supplied to confirm equivalent exploration mechanisms or curricula, rendering the outperformance claim unverifiable and load-bearing for the paper's conclusions.
Authors: The manuscript asserts a common environment and training budget, but we accept that the current text does not supply sufficient implementation artifacts to allow independent verification. We will add (i) a hyperparameter table listing learning rates, entropy coefficients, network architectures, and training step counts for all algorithms, (ii) pseudocode for the self-play loop and opponent sampling procedure, and (iii) explicit statements confirming that state encoding, action masking, and reward scaling were held identical across agents. These additions will make the controlled comparison reproducible. revision: yes
Circularity Check
No circularity: purely empirical performance comparisons
full rationale
The paper reports direct experimental results comparing PPO, Monte Carlo Q, SARSA, and Q-learning in a shared Big 2 environment. No equations, derivations, or predictions are present that reduce reported win rates or performance metrics to quantities defined by fitted parameters within the paper. The central claims rest on empirical measurements against fixed opponent types rather than any self-referential construction, self-citation load-bearing argument, or ansatz smuggled via prior work. This is the expected outcome for an empirical RL benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Application of Self-Play Reinforcement Learning to a Four-Player Game of Imperfect Information
URL https://arxiv.org/ abs/1808.10442. Chen, L.-W. and Lu, Y .-R. Challenging artificial intelligence with multiopponent and multimovement prediction for the card game Big2.IEEE Access, 10:40661–40676,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
doi: 10.1109/ACCESS.2022.3166932. Chen, L.-W. and Lu, Y .-R. Markov decision process-based artificial intelligence with card-playing strategy and free- playing right exploration for four-player card game Big2. IEEE Transactions on Games, 17(2):267–281,
-
[3]
doi: 10.1109/TG.2024.3424431. Heinrich, J. and Silver, D. Deep reinforcement learning from self-play in imperfect-information games,
-
[4]
Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
URL https://arxiv.org/abs/1603.01121. Li, B., Fang, Z., and Huang, L. RL-CFR: Improving ac- tion abstraction for imperfect information extensive-form games with reinforcement learning. InProceedings of the 41st International Conference on Machine Learning, vol- ume 235 ofProceedings of Machine Learning Research, pp. 27752–27770. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Liu, M., Farina, G., and Ozdaglar, A
URLhttps://arxiv.org/abs/2003.13590. Liu, M., Farina, G., and Ozdaglar, A. E. A policy-gradient approach to solving imperfect-information games with best-iterate convergence. InInternational Conference on Learning Representations,
-
[6]
doi: 10.1016/j.asoc.2024.111545. Moravcik, M., Schmid, M., Burch, N., Lisy, V ., Morrill, D., Bard, N., Davis, T., Waugh, K., Johanson, M., and Bowl- ing, M. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker.Science, 356(6337):508–513,
-
[7]
doi: 10.1126/science.add4679. Schmid, M., Moravcik, M., Burch, N., Kadlec, R., David- son, J., Waugh, K., Bard, N., Timbers, F., Lanctot, M., Holland, G. Z., Davoodi, E., Christianson, A., and Bowling, M. Student of games: A unified learning algorithm for both perfect and imperfect information games.Science Advances, 9(46):eadg3256,
-
[8]
doi: 10.1126/sciadv.adg3256. Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., Lillicrap, T., and Silver, D. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.