Beyond the Library: An Agentic Framework for Autoformalizing Research Mathematics
Pith reviewed 2026-07-01 05:52 UTC · model grok-4.3
The pith
An agentic system using general coding LLMs autoformalizes main theorems and proofs from research papers into Lean 4 by dynamically adding and validating new type definitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The agentic autoformalization framework, powered by general coding LLMs and centered on an orchestrator that manages a multi-agent pipeline, successfully formalizes the main theorems and proofs of five STOC papers into Lean 4 after dynamically extending necessary type definitions and validating them via the Auxiliary Lemma technique; the same system also produces formalizations for 32 PutnamBench problems, with all outputs validated by human experts and two STOC proofs using only Lean's kernel axioms.
What carries the argument
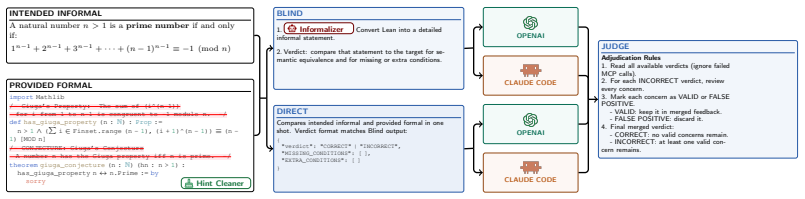
The orchestrator that manages a multi-agent pipeline for autoformalization, using the Auxiliary Lemma technique to validate newly introduced type definitions before formalizing primary theorems.
If this is right
- Research-level theorems in combinatorics, communication complexity, mechanism design, and learning theory can be accompanied by machine-checked Lean proofs.
- Two of the five STOC formalizations require no axioms beyond Lean's kernel, indicating that minimal-axiom proofs are achievable for some results.
- General-purpose coding LLMs can be orchestrated to outperform specialized Lean models on autoformalization of recent papers.
- Putnam-level problems can be turned into machine-checked Lean proofs using the same pipeline.
Where Pith is reading between the lines
- If the Auxiliary Lemma method scales, future papers could be written with an accompanying formalization step that catches errors before submission.
- The framework's success on STOC papers suggests it could be applied to other conference series to build a growing corpus of verified research results.
- Combining this approach with interactive theorem-proving interfaces might let authors iteratively refine both informal and formal versions of their arguments in one workflow.
Load-bearing premise
The Auxiliary Lemma technique reliably validates newly introduced type definitions for concepts outside Mathlib without introducing undetected errors that would invalidate the subsequent formalization of the primary theorems.
What would settle it
A STOC paper where a new type definition passes Auxiliary Lemma validation yet produces a Lean formalization that experts later find contains an undetected logical error in the main theorem.
Figures




read the original abstract
While Large Language Models (LLMs) have demonstrated exceptional capabilities in mathematical reasoning, they frequently produce subtle errors that evade human detection. Formal mathematical languages like Lean 4 offer mechanical proof checking, strongly motivating the need for autoformalization: the automatic translation of natural language mathematics into verifiable code. Recent trends indicate that general-purpose LLMs, heavily optimized for standard programming, now outperform smaller models explicitly fine-tuned for Lean. Leveraging this shift, we introduce an agentic autoformalization framework powered by general coding LLMs. At the core of our system is an orchestrator that manages a multi-agent pipeline tailored for research-level mathematics. Because cutting-edge research frequently relies on concepts outside the scope of existing libraries like Mathlib, our system dynamically extends necessary type definitions and validates them via a novel Auxiliary Lemma technique before formalizing the primary theorems. We applied our approach to PutnamBench, producing machine-checked Lean proofs for a random sample of 32 problems. Furthermore, we evaluate our system on five papers from the ACM Symposium on Theory of Computing (STOC) spanning combinatorics, communication complexity, mechanism design, and learning theory, successfully formalizing their main theorems and validating the generated formalizations with human experts; for all five we also formalize the proofs alongside the statements, and notably two of them are proved with no axioms beyond Lean's kernel. All of our formalizations are available at https://beyondthelibrary.github.io/formal_arxiv .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an agentic multi-LLM framework for autoformalizing research mathematics into Lean 4. Its core contribution is an orchestrator that dynamically extends Mathlib with new type definitions for concepts outside existing libraries and validates them via a novel Auxiliary Lemma technique before formalizing theorems and proofs. The system is evaluated on a random sample of 32 PutnamBench problems and five STOC papers (combinatorics, communication complexity, mechanism design, learning theory), producing machine-checked formalizations of main theorems and proofs; human experts validated the outputs, and two STOC formalizations require no axioms beyond Lean's kernel. All artifacts are released at the provided GitHub site.
Significance. If the central results hold, the work would be a meaningful step toward research-level autoformalization, particularly by addressing the library-extension barrier that has limited prior systems. The machine-checked proofs on external benchmarks (PutnamBench, STOC papers) with independent human review, plus the release of all formalizations, strengthen the contribution relative to purely informal LLM demonstrations.
major comments (2)
- [Abstract; Auxiliary Lemma technique section] Abstract (paragraph on dynamic extension) and the section describing the Auxiliary Lemma technique: the claim that this technique reliably validates newly introduced type definitions for research concepts is load-bearing for the five STOC results, yet the manuscript supplies neither an independent soundness argument nor an exhaustive enumeration of potential failure modes (e.g., undetected missing axioms or inconsistent type extensions) that could invalidate subsequent kernel-checked proofs.
- [Evaluation on PutnamBench and STOC papers] Evaluation sections on PutnamBench and STOC papers: the reported successes are presented without quantitative error rates, failure-case breakdowns, or ablation results on the multi-agent pipeline components, leaving the strength of empirical support for the framework's reliability moderate despite the external benchmarks and human validation.
minor comments (2)
- [System architecture] The description of the orchestrator's agent roles and hand-off protocols would benefit from a single consolidated diagram or pseudocode listing the exact sequence of LLM calls and validation steps.
- [Introduction / Method] Minor notation inconsistency: the term "Auxiliary Lemma technique" is introduced without a formal definition or pseudocode in the first occurrence, making the subsequent claims harder to parse on first reading.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below, indicating planned revisions where appropriate to strengthen the discussion of our methods and evaluation.
read point-by-point responses
-
Referee: [Abstract; Auxiliary Lemma technique section] Abstract (paragraph on dynamic extension) and the section describing the Auxiliary Lemma technique: the claim that this technique reliably validates newly introduced type definitions for research concepts is load-bearing for the five STOC results, yet the manuscript supplies neither an independent soundness argument nor an exhaustive enumeration of potential failure modes (e.g., undetected missing axioms or inconsistent type extensions) that could invalidate subsequent kernel-checked proofs.
Authors: The Auxiliary Lemma technique validates new type definitions by requiring the generation and kernel-checked proof of lemmas that capture their intended mathematical properties before they are used in theorem statements. This provides an empirical rather than meta-theoretic guarantee, as a formal soundness argument would necessitate reasoning about LLM behavior that lies beyond the paper's scope. We will revise the Auxiliary Lemma section to include an explicit enumeration of potential failure modes (such as undetected missing axioms or inconsistent extensions) and clarify how human expert validation of the final formalizations serves as an additional safeguard. We will also update the abstract to note that validation is empirical and supported by expert review. revision: partial
-
Referee: [Evaluation on PutnamBench and STOC papers] Evaluation sections on PutnamBench and STOC papers: the reported successes are presented without quantitative error rates, failure-case breakdowns, or ablation results on the multi-agent pipeline components, leaving the strength of empirical support for the framework's reliability moderate despite the external benchmarks and human validation.
Authors: The evaluation prioritizes demonstrating successful machine-checked formalizations on external research-level benchmarks (PutnamBench sample and STOC papers), each independently reviewed by human experts, rather than exhaustive error statistics. We agree that additional context on reliability would be beneficial and will add a subsection summarizing observed failure modes encountered during development (e.g., challenges in library extension or proof search) along with any quantitative metrics available from our experimental logs. Full component ablations are resource-intensive given the integrated pipeline and high cost per formalization, but we will discuss the contribution of each agent based on iterative testing. The kernel-checked proofs and expert validation remain the primary evidence of correctness. revision: partial
Circularity Check
No significant circularity; evaluations rely on external benchmarks and human review
full rationale
The paper presents an agentic framework for autoformalization and evaluates it on independent external benchmarks (PutnamBench sample and five STOC papers) with human expert validation of the generated Lean formalizations. The Auxiliary Lemma technique is introduced as a novel method for validating dynamic type extensions, but the central results (successful formalization of main theorems, including two kernel-only proofs) are not derived by fitting parameters to the evaluation data, nor do they reduce to self-citations or self-definitional steps. The derivation chain consists of system design choices justified by performance on held-out research papers rather than any closed loop where outputs are constructed from the same inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption General-purpose coding LLMs can be orchestrated to perform autoformalization of research mathematics
invented entities (1)
-
Auxiliary Lemma technique
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.