Veda: Scalable Video Diffusion via Distilled Sparse Attention
Pith reviewed 2026-06-29 07:51 UTC · model grok-4.3
The pith
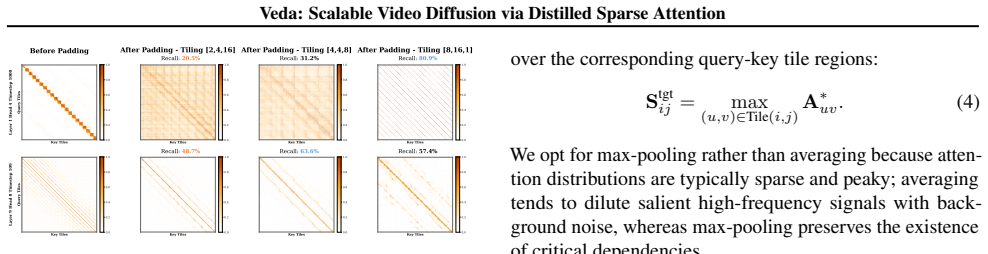
Video diffusion quality holds at high sparsity when the mask aligns with the tile geometry of full attention rather than depending on the sparsity ratio alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
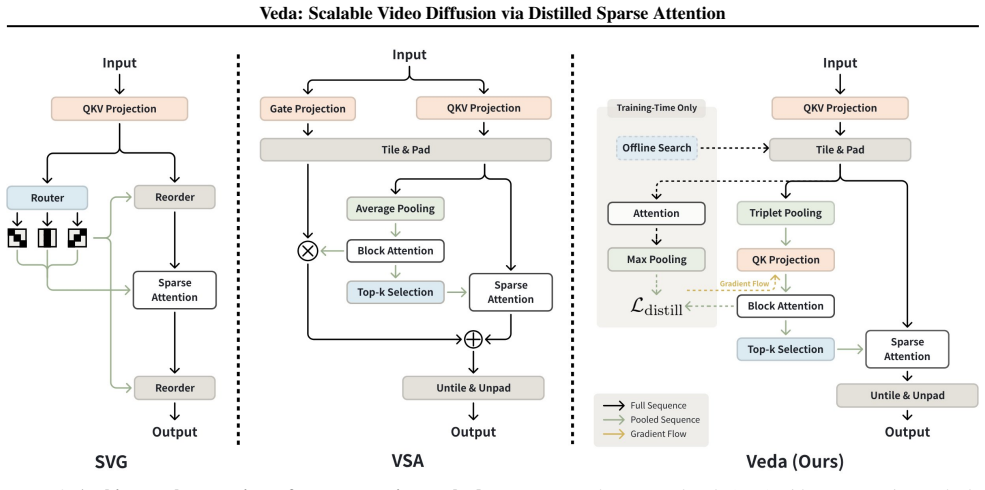
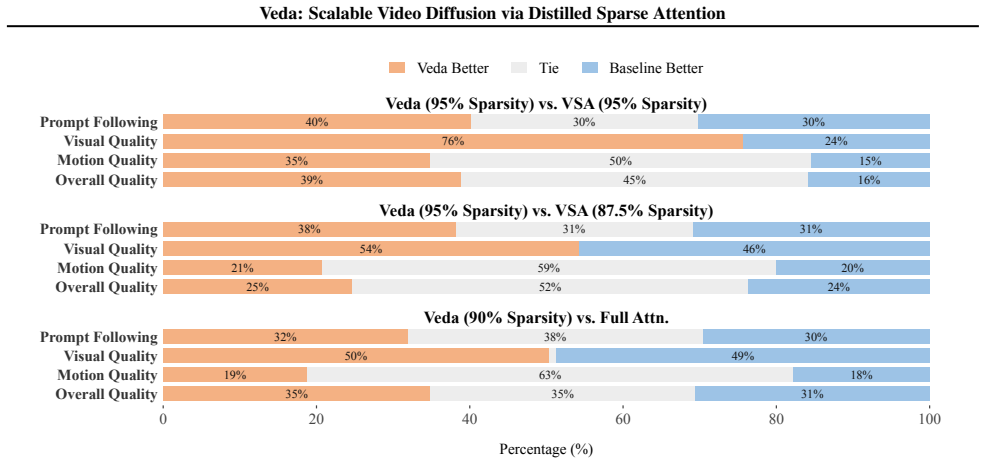
Veda formulates tile selection as an explicit reconstruction problem from full attention, integrates statistics-aware tile scoring with head-aware tiling to reduce estimation error and structural mismatch, and thereby supports aggressive sparsity with no noticeable degradation in generation quality. On Waver-T2V-12B it delivers 5.1 times end-to-end speedup and 10.5 times self-attention speedup for 720P 10-second videos, cutting attention overhead from 92 percent to 50 percent, with larger relative gains at longer sequence lengths.
What carries the argument
The distilled sparse attention mechanism that solves tile selection as reconstruction from full attention using statistics-aware scoring and head-aware tiling.
If this is right
- Aggressive sparsity becomes usable in production video models without retraining or quality tuning.
- End-to-end inference time drops by factors of five or more on current hardware while attention overhead halves.
- Speedup ratios increase as spatiotemporal resolution grows, favoring future higher-resolution workloads.
- The same reconstruction-based tile selection can be applied to other large diffusion transformers such as Wan2.1.
Where Pith is reading between the lines
- The alignment principle could be tested on image or 3-D diffusion backbones where attention also dominates compute.
- If the reconstruction objective is made differentiable, the sparse mask might be learned jointly with the diffusion model rather than distilled after the fact.
- Hardware kernels for other sparse patterns could be derived from the same tile-scoring logic to widen the set of supported accelerators.
Load-bearing premise
The assumption that the scoring and tiling choices will keep the sparse mask aligned with full attention geometry across models, datasets, and sequence lengths without quality losses the experiments missed.
What would settle it
Running the same sparsity level on a different diffusion transformer or on substantially longer videos and observing measurable drops in generation metrics such as FID or human preference scores would falsify the claim.
Figures






read the original abstract
Scaling Diffusion Transformers to generate high-resolution, long videos is constrained by the quadratic cost of self-attention, and existing sparse attention methods degrade under high sparsity. We show empirically that generation quality is determined not by the sparsity ratio itself, but by how well the sparse mask aligns with the tile-wise geometry of full attention. Based on this insight, we propose Veda, a distilled sparse attention framework that formulates tile selection as an explicit reconstruction problem from full attention. Veda integrates statistics-aware tile scoring with head-aware tiling to reduce estimation error and structural mismatch, enabling aggressive sparsity. A hardware-efficient tile-skipping kernel converts theoretical sparsity into practical wall-clock speedups. Experiments on large video diffusion models, including Waver and Wan2.1, demonstrate substantial acceleration with no noticeable degradation in generation quality. To generate 720P 10-second videos on Waver-T2V-12B, Veda achieves a 5.1$\times$ end-to-end speedup and a 10.5$\times$ self-attention speedup, reducing attention overhead from 92% to 50%. Notably, the gains increase with sequence length, indicating that Veda scales favorably with spatiotemporal resolution across models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that video diffusion transformer scaling is limited by quadratic self-attention and that existing sparse methods degrade at high sparsity. It empirically observes that quality depends on alignment between the sparse mask and the tile-wise geometry of full attention rather than the sparsity ratio. Veda formulates tile selection as an explicit reconstruction problem from full attention, integrates statistics-aware tile scoring with head-aware tiling to reduce error and mismatch, and adds a hardware-efficient tile-skipping kernel. On models including Waver and Wan2.1, it reports 5.1× end-to-end and 10.5× attention speedups for 720P 10-second videos with no noticeable quality degradation, with gains increasing at longer sequences.
Significance. If the empirical results and generalization hold, the work offers a practical route to higher-resolution, longer video generation by converting theoretical sparsity into wall-clock gains while preserving output quality. The mask-alignment insight and the hardware kernel are concrete strengths. The distillation approach, however, ties training cost to full-attention supervision, which directly affects whether the method truly scales to the spatiotemporal regimes where the reported inference benefits are largest.
major comments (2)
- [§3] §3 (Distillation procedure): the method formulates tile selection as reconstruction from full attention maps and derives statistics-aware scoring from those maps. For sequences longer than those where full attention fits in memory, obtaining the supervision signal during training either requires computing the full maps (contradicting the scalability target) or introduces an approximation the paper claims to avoid. This is load-bearing for the central claim that Veda scales favorably with sequence length.
- [§4] §4 (Experiments): all reported speedups and quality results are measured at inference. No training-time memory or compute figures are given for the distillation stage on the long-sequence, high-resolution cases where inference gains are largest. Without this, the claim that gains increase with sequence length cannot be fully evaluated.
minor comments (2)
- [Abstract and §4] The phrase 'no noticeable degradation' should be supported by quantitative metrics (e.g., FVD, CLIP score deltas) with error bars rather than qualitative statements alone.
- [§3] Notation for tile scoring and head-aware tiling should be defined with explicit equations before the experimental claims that rely on them.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the mask-alignment insight and hardware kernel. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (Distillation procedure): the method formulates tile selection as reconstruction from full attention maps and derives statistics-aware scoring from those maps. For sequences longer than those where full attention fits in memory, obtaining the supervision signal during training either requires computing the full maps (contradicting the scalability target) or introduces an approximation the paper claims to avoid. This is load-bearing for the central claim that Veda scales favorably with sequence length.
Authors: We agree this point is important. The distillation procedure is performed offline as a one-time training step on sequence lengths where full attention maps fit in memory using standard implementations. The learned scorer is then applied directly at inference on longer sequences. We will revise §3 to explicitly state the training sequence lengths employed and add a short discussion of how the scorer generalizes to longer inference lengths without requiring full attention at test time. revision: yes
-
Referee: [§4] §4 (Experiments): all reported speedups and quality results are measured at inference. No training-time memory or compute figures are given for the distillation stage on the long-sequence, high-resolution cases where inference gains are largest. Without this, the claim that gains increase with sequence length cannot be fully evaluated.
Authors: We concur that training-time figures would give a fuller picture. The distillation cost is incurred only once and does not recur at inference; the reported scaling refers to inference wall-clock time. We did not record detailed memory and compute numbers for the distillation stage on the longest sequences. In revision we will add the available training cost data for the lengths actually used and clarify that the increasing gains are measured at inference. revision: partial
- Precise training-time memory and compute figures for the distillation stage on the longest high-resolution sequences, because these measurements were not collected in the original experiments.
Circularity Check
No circularity: empirical reconstruction objective with external validation
full rationale
The paper's central claim rests on an empirical observation that mask alignment with full-attention geometry determines quality, followed by an explicit reconstruction formulation for tile selection plus statistics-aware scoring. This is validated through experiments on external models (Waver, Wan2.1) showing speedups without quality loss. No equations reduce by construction to inputs, no self-citation chains are load-bearing, and the distillation step is a standard supervised objective rather than a self-referential loop. The method is self-contained against reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, P., Zeng, X., Zhao, M., Ye, P., Shen, M., Cheng, W., Yu, G., and Chen, T. Sparse-vdit: Unleashing the power of sparse attention to accelerate video diffusion transformers.arXiv preprint arXiv:2506.03065,
-
[2]
DeepSeekTeam. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2025a. DeepSeekTeam. Deepseek-v3.2: Pushing the fron- tier of open large language models.arXiv preprint arXiv:2512.02556, 2025b. Fan, Z., Wang, Z., and Zhang, W. Taocache: Structure- maintained video generation acceleration.arXiv preprint arXiv:2508.08978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Fu, T., Huang, H., Ning, X., Zhang, G., Chen, B., Wu, T., Wang, H., Huang, Z., Li, S., Yan, S., Dai, G., Yang, H., and Wang, Y . Mixture of attention spans: Optimizing llm inference efficiency with heterogeneous sliding-window lengths.arXiv preprint arXiv:2406.14909,
-
[4]
K.-H., Cao, T., Yang, F., and Yang, M
Gao, Y ., Zeng, Z., Du, D., Cao, S., Zhou, P., Qi, J., Lai, J., So, H. K.-H., Cao, T., Yang, F., and Yang, M. Seerat- tention: Learning intrinsic sparse attention in your llms. arXiv preprint arXiv:2410.13276,
-
[5]
HunyuanVideo 1.5 Technical Report
HunyuanTeam. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
H., Li, D., Gao, J., Yang, Y ., et al
Li, Y ., Jiang, H., Zhang, C., Wu, Q., Luo, X., Ahn, S., Abdi, A. H., Li, D., Gao, J., Yang, Y ., et al. Mmin- ference: Accelerating pre-filling for long-context vlms via modality-aware permutation sparse attention.arXiv preprint arXiv:2504.16083,
-
[7]
Open-Sora Plan: Open-Source Large Video Generation Model
Lin, B., Ge, Y ., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y ., Yuan, S., Chen, L., Jia, T., Zhang, J., Tang, Z., Pang, Y ., She, B., Yan, C., Hu, Z., Dong, X., Chen, L., Pan, Z., Zhou, X., Dong, S., Tian, Y ., and Yuan, L. Open- sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Litman, E. Scaled-dot-product attention as one- sided entropic optimal transport.arXiv preprint arXiv:2508.08369,
-
[9]
MoBA: Mixture of Block Attention for Long-Context LLMs
Lu, E., Jiang, Z., Liu, J., Du, Y ., Jiang, T., Hong, C., Liu, S., He, W., Yuan, E., Wang, Y ., Huang, Z., Yuan, H., Xu, S., Xu, X., Lai, G., Chen, Y ., Zheng, H., Yan, J., Su, J., Wu, Y ., Zhang, N. Y ., Yang, Z., Zhou, X., Zhang, M., and Qiu, J. Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi: 10.1109/ipdpsw.2018.00091. Peebles, W. and Xie, S. Scalable Diffusion Models with Transformers . In2023 IEEE/CVF International Confer- ence on Computer Vision (ICCV), pp. 4172–4182, Los Alamitos, CA, USA, October
-
[11]
IEEE Computer So- ciety. doi: 10.1109/ICCV51070.2023.00387. QwenTeam. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
-
[12]
Hopfield Networks is All You Need
Ramsauer, H., Sch ¨afl, B., Lehner, J., Seidl, P., Widrich, M., Adler, T., Gruber, L., Holzleitner, M., Pavlovi´c, M., Sandve, G. K., Greiff, V ., Kreil, D., Kopp, M., Klambauer, G., Brandstetter, J., and Hochreiter, S. Hopfield networks is all you need.arXiv preprint arXiv:2008.02217,
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[13]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Shah, J., Bikshandi, G., Zhang, Y ., Thakkar, V ., Ramani, P., and Dao, T. Flashattention-3: Fast and accurate atten- tion with asynchrony and low-precision.arXiv preprint arXiv:2407.08608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
F., Arora, S., Singhal, A., Fu, D
Spector, B. F., Arora, S., Singhal, A., Fu, D. Y ., and R ´e, C. Thunderkittens: Simple, fast, and adorable ai kernels. arXiv preprint arXiv:2410.20399,
-
[15]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
StepVideoTeam. Step-video-t2v technical report: The prac- tice, challenges, and future of video foundation model. arXiv preprint arXiv:2502.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
V orta: Efficient video diffusion via routing sparse attention.arXiv preprint arXiv:2505.18809,
Sun, W., Tu, R.-C., Ding, Y ., Jin, Z., Liao, J., Liu, S., and Tao, D. V orta: Efficient video diffusion via routing sparse attention.arXiv preprint arXiv:2505.18809,
-
[17]
L., Cai, X., Huang, Q., Kang, Z., Li, H., Liang, S., Ma, L., Ren, S., Wei, X., Xie, R., and Zhang, T
Team, M. L., Cai, X., Huang, Q., Kang, Z., Li, H., Liang, S., Ma, L., Ren, S., Wei, X., Xie, R., and Zhang, T. Longcat- video technical report.arXiv preprint arXiv:2510.22200,
-
[18]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lam- ple, G. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Curran Associates Inc. ISBN 9781510860964. Wang, L., Cheng, Y ., Shi, Y ., Tang, Z., Mo, Z., Xie, W., Ma, L., Xia, Y ., Xue, J., Yang, F., et al. Tilelang: A com- posable tiled programming model for ai systems.arXiv preprint arXiv:2504.17577,
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
WanTeam. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Vmoba: Mixture-of-block attention for video diffusion models.arXiv preprint arXiv:2506.23858,
Wu, J., Hou, L., Yang, H., Tao, X., Tian, Y ., Wan, P., Zhang, D., and Tong, Y . Vmoba: Mixture-of-block attention for video diffusion models.arXiv preprint arXiv:2506.23858,
-
[22]
Xi, H., Yang, S., Zhao, Y ., Xu, C., Li, M., Li, X., Lin, Y ., Cai, H., Zhang, J., Li, D., Chen, J., Stoica, I., Keutzer, K., and Han, S. Sparse videogen: Accelerating video diffu- sion transformers with spatial-temporal sparsity.arXiv preprint arXiv:2502.01776,
-
[23]
Efficient Streaming Language Models with Attention Sinks
10 Veda: Scalable Video Diffusion via Distilled Sparse Attention Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Cogvideox: Text-to-video diffusion models with an expert transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y ., Hong, W., Zhang, X., Feng, G., Yin, D., Zhang, Y ., Wang, W., Cheng, Y ., Bin, X., Gu, X., Dong, Y ., and Tang, J. Cogvideox: Text-to-video diffusion models with an expert transformer. In Yue, Y ., Garg, A., Peng, N., Sha, F., and Yu, R. (eds.),International Conference on Learning Repr...
2025
-
[25]
T., Durand, F., Shechtman, E., and Huang, X
Yin, T., Zhang, Q., Zhang, R., Freeman, W. T., Durand, F., Shechtman, E., and Huang, X. From slow bidirectional to fast autoregressive video diffusion models.arXiv preprint arXiv:2412.07772,
-
[26]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y . X., Wang, L., Xiao, Z., Wang, Y ., Ruan, C., Zhang, M., Liang, W., and Zeng, W. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Zhang, J., Xiang, C., Huang, H., Wei, J., Xi, H., Zhu, J., and Chen, J. Spargeattention: Accurate and training-free sparse attention accelerating any model inference.arXiv preprint arXiv:2502.18137, 2025a. Zhang, P., Chen, Y ., Huang, H., Lin, W., Liu, Z., Stoica, I., Xing, E., and Zhang, H. VSA: Faster Video Diffu- sion with Trainable Sparse Attention.ar...
-
[28]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Zheng, K., Wang, Y ., Ma, Q., Chen, H., Zhang, J., Balaji, Y ., Chen, J., Liu, M.-Y ., Zhu, J., and Zhang, Q. Large scale diffusion distillation via score-regularized continuous- time consistency.arXiv preprint arXiv:2510.08431,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
11 Veda: Scalable Video Diffusion via Distilled Sparse Attention A. Theoretical Framework for Veda In this section, we establish the theoretical foundations of our approach and provide deeper algorithmic and mathematical insights into the nature of sparse attention. A.1. The Necessity of Accurate Oracle Masks The self-attention mechanism can be formally v...
2021
-
[30]
This implies that tokens within a tile should lie on a local low-dimensional manifold with minimal variance
Corollary A.5(Clustering Condition).A sufficient condition for the sparse approximation to be robust (i.e., E→0 ) is σq →0 or σk →0 , and reducing both variances tightens the bound. This implies that tokens within a tile should lie on a local low-dimensional manifold with minimal variance. If tiles contain diverse tokens (high σ), the uncertainty bound of...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.