FllumaOne: A Code-Native Multimodal CAD Dataset with Executable Programs and Kernel-Validated Feature Histories
Pith reviewed 2026-06-27 00:57 UTC · model grok-4.3
The pith
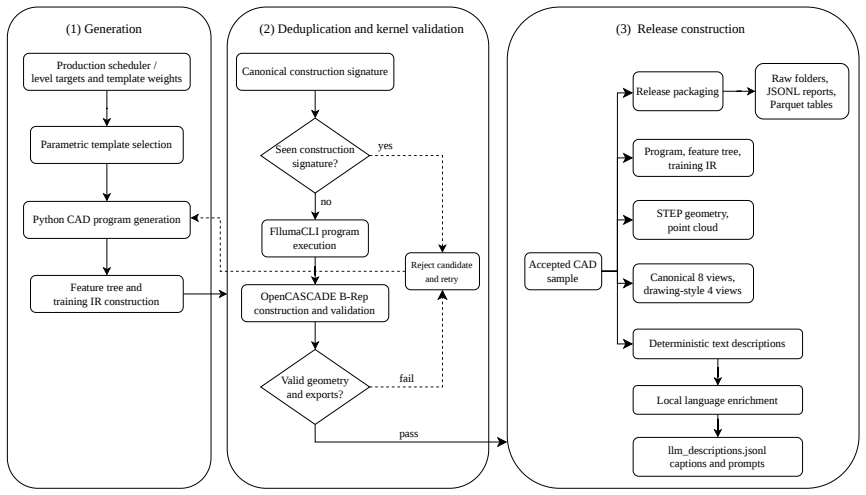
FllumaOne supplies 100,000 kernel-validated parametric CAD models as executable Python programs with aligned feature histories and geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
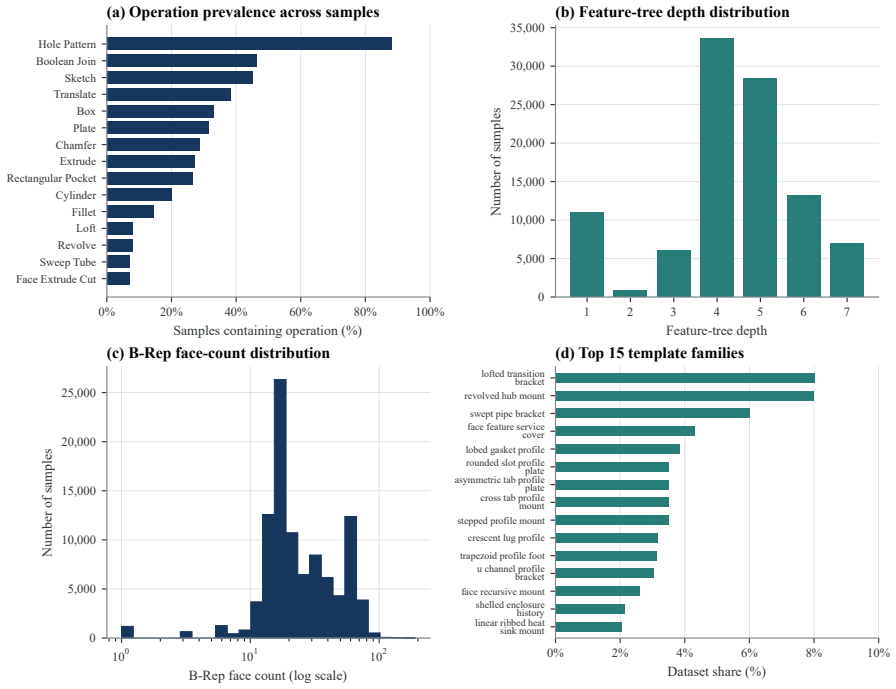
FllumaOne-100K contains 100,000 accepted samples generated across four template-level complexity regimes. Programs are executed and kept only after kernel geometry, solid validity, and export checks succeed; each retained sample aligns its Python program with a structured feature tree, training-oriented intermediate representation, STEP file, surface point cloud, natural-language description, metadata, and eight canonical visible-edge renderings. On the 10,000-sample test split a Qwen2.5-Coder-1.5B LoRA model achieves 99.98 percent Python syntax validity, 99.97 percent Flluma build success, and 99.14 percent STEP-export validity, with mean normalized Chamfer distance 0.002124 on 9,909 point-
What carries the argument
Executable Python programs in the Flluma CAD system that produce models together with kernel-level validation filters that enforce geometry correctness, solid validity, and successful export.
If this is right
- Models can be trained to synthesize executable programs from natural-language descriptions or partial geometry.
- Feature-tree prediction and B-Rep analysis tasks become directly supervised by the aligned intermediate representations.
- Conditioned CAD reconstruction can produce outputs that remain editable because the full construction history is recovered.
- Design completion and editable reverse-engineering pipelines can operate on the same validated multimodal samples.
Where Pith is reading between the lines
- If the templates capture the most frequent parametric patterns, fine-tuned models could transfer to editing workflows in other CAD kernels after operation mapping.
- The validation pipeline itself could serve as a filter for future synthetic CAD generators to guarantee export-ready solids.
- Point-cloud predictions at the reported Chamfer distance level suggest that downstream tasks requiring geometric fidelity are already within reach of current language models.
Load-bearing premise
The four template regimes generate a distribution of models that matches real-world parametric CAD practice and that the kernel validation steps do not systematically exclude important design classes.
What would settle it
A test set of industry CAD files drawn from commercial software that cannot be expressed by any Flluma template or that fail the kernel checks at rates far above the reported 0.03 percent would show the dataset distribution is not representative.
Figures


read the original abstract
Parametric computer-aided design records both final geometry and the ordered construction history that determines how a part can be edited. Datasets for editable CAD research should therefore expose modeling operations, parameters, and feature dependencies together with validated geometry. We introduce FllumaOne, a code-native multimodal CAD dataset whose models are generated by executable Python programs in Flluma, a Qt/C++ OpenCASCADE-based CAD system. Each sample aligns its program with a structured feature tree, a training-oriented intermediate representation, STEP geometry, a surface point cloud, natural-language descriptions, metadata, and eight canonical visible-edge renderings. The primary release, FllumaOne-100K, contains 100,000 accepted samples across four template-level complexity regimes. Programs are executed and retained only after kernel geometry, solid validity, and export checks; release reports also record modality completeness and split-level duplicate tests. A Qwen2.5-Coder-1.5B LoRA baseline trained on 80,000 samples achieves 99.98% Python syntax validity, 99.97% Flluma build success, and 99.14% STEP-export validity on the held-out 10,000-sample test split. For the 9,909 predictions converted to surface point clouds, the mean normalized Chamfer Distance is 0.002124. The dataset supports conditioned CAD reconstruction, executable program synthesis, feature-tree prediction, B-Rep analysis, retrieval, design completion, and editable reverse engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FllumaOne, a code-native multimodal CAD dataset of 100,000 samples generated from executable Python programs in the Flluma (OpenCASCADE-based) system. Each sample aligns the program with a feature tree, STEP geometry, point cloud, natural-language descriptions, metadata, and renderings. Samples are retained only after kernel geometry, solid-validity, and export checks across four template-level complexity regimes. A Qwen2.5-Coder-1.5B LoRA baseline achieves 99.98% Python syntax validity, 99.97% Flluma build success, 99.14% STEP-export validity, and mean normalized Chamfer Distance 0.002124 on the held-out test split.
Significance. If the retained distribution is representative of parametric CAD, the dataset would be a useful contribution by supplying aligned executable programs, validated B-Reps, and multiple modalities for tasks such as program synthesis, feature-tree prediction, and editable reverse engineering. The explicit kernel validation and high baseline validity rates are concrete strengths that support reproducibility and immediate usability for model training.
major comments (2)
- [Abstract] Abstract: The central claim that FllumaOne supports research on 'real parametric CAD usage' and 'editable reverse engineering' rests on the assumption that the four template-level complexity regimes plus kernel filters produce a distribution representative of production CAD; no quantitative comparison to real-world feature-interaction graphs, parameter ranges, or topological variety is provided, leaving open the possibility that validity filters systematically exclude important design classes.
- [Abstract] Abstract (baseline paragraph): The reported 99.14% STEP-export validity and 0.002124 mean CD are measured on 9,909 predictions from the held-out split, yet the generation templates and exact exclusion criteria are not detailed; without these, it is impossible to determine whether the metrics reflect robust synthesis capability or an artifact of the bounded support induced by template-driven sampling and validity pruning.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the strengths of the kernel validation pipeline and the reported baseline metrics. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that FllumaOne supports research on 'real parametric CAD usage' and 'editable reverse engineering' rests on the assumption that the four template-level complexity regimes plus kernel filters produce a distribution representative of production CAD; no quantitative comparison to real-world feature-interaction graphs, parameter ranges, or topological variety is provided, leaving open the possibility that validity filters systematically exclude important design classes.
Authors: We agree that FllumaOne is generated from four template-level complexity regimes and that no quantitative comparison to real-world CAD feature graphs or parameter distributions is provided. The manuscript frames the dataset as a resource supplying aligned executable programs, feature trees, and validated B-Reps to support research on tasks such as editable reverse engineering, rather than asserting statistical representativeness of production CAD. In revision we will (1) rephrase the abstract to avoid implying broad representativeness and (2) add an explicit limitations paragraph discussing the template-driven construction and the possibility that validity filters exclude certain design classes. revision: partial
-
Referee: [Abstract] Abstract (baseline paragraph): The reported 99.14% STEP-export validity and 0.002124 mean CD are measured on 9,909 predictions from the held-out split, yet the generation templates and exact exclusion criteria are not detailed; without these, it is impossible to determine whether the metrics reflect robust synthesis capability or an artifact of the bounded support induced by template-driven sampling and validity pruning.
Authors: Section 3 of the manuscript describes the four template families and their parameter ranges; Section 4 details the kernel geometry, solid-validity, and export checks together with the exact retention criteria. The figure of 9,909 reflects the subset of the 10,000-sample test split for which surface point clouds could be generated for Chamfer Distance evaluation. We will revise the abstract to reference these sections explicitly and will include additional template pseudocode in the supplementary material so that the bounded support is transparent. revision: yes
Circularity Check
No circularity; dataset construction and external validation are independent
full rationale
The manuscript presents a dataset generated from templates, filtered by external kernel geometry/solid/export checks, and a standard supervised baseline evaluated on a held-out test split. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the provided text. All reported metrics (syntax validity, build success, STEP validity, Chamfer distance) are computed directly on independent test samples after training, with no reduction of any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L. Zhang, B. Le, N. Akhtar, S.-K. Lam, D. Ngo, Large Language Models for Computer-Aided Design: A survey, ACM Computing Surveys 58 (9) (Feb. 2026). doi:10.1145/3787499
-
[2]
A. X. Chang, T. A. Funkhouser, L. J. Guibas, P. Hanrahan, Q.-X. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, F. Yu, ShapeNet: An information-rich 3D model repository (2015).arXiv:1512.03012. URLhttps://arxiv.org/abs/1512.03012
Pith/arXiv arXiv 2015
-
[3]
S. Koch, A. Matveev, Z. Jiang, F. Williams, A. Artemov, E. Burnaev, M. Alexa, D. Zorin, D. Panozzo, ABC: A big CAD model dataset for geometric deep learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 9601–9611
2019
-
[4]
A. Seff, Y. Ovadia, W. Zhou, R. P. Adams, SketchGraphs: A large-scale dataset for modeling relational geometry in Computer-Aided Design (2020).arXiv:2007.08506. URLhttps://arxiv.org/abs/2007.08506
arXiv 2020
-
[5]
K. D. D. Willis, Y. Pu, J. Luo, H. Chu, T. Du, J. G. Lambourne, A. Solar-Lezama, W. Matusik, Fusion 360 Gallery: A dataset and environment for programmatic CAD construction from human design sequences, ACM Transactions on Graphics 40 (4) (Jul. 2021).doi:10.1145/3450626.3459818. 21
-
[6]
R. Wu, C. Xiao, C. Zheng, DeepCAD: A deep generative network for Computer- Aided Design models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 6772–6782
2021
-
[7]
C. Lv, J. Bao, CADInstruct: A multimodal dataset for natural language-guided CAD program synthesis, Computer-Aided Design 188 (2025) 103926.doi:10.1016/ j.cad.2025.103926
arXiv 2025
-
[8]
X. Dong, C. Li, P. Zheng, C. Han, J. Jing, H. Shen, Y. Song, Z. Yang, HistCAD: A constraint-aware parametric history-based CAD representation, dataset, and bench- mark with industrial complexity (2026).arXiv:2602.19171. URLhttps://arxiv.org/abs/2602.19171
Pith/arXiv arXiv 2026
-
[9]
V. Pyatov, G. Bobrovskikh, S. Galochkin, N. Boldyrev, O. Voynov, A. Filip- pov, G. Ferrer, P. Wonka, E. Burnaev, CADFS: A big CAD program dataset and framework for Computer-Aided Design with Large Language Models (2026). arXiv:2605.01925. URLhttps://arxiv.org/abs/2605.01925
Pith/arXiv arXiv 2026
-
[10]
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, J. Xiao, 3D ShapeNets: A deep representation for volumetric shapes, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1912–1920
2015
-
[11]
Q. Zhou, A. Jacobson, Thingi10K: A dataset of 10,000 3D-printing models (2016). arXiv:1605.04797. URLhttps://arxiv.org/abs/1605.04797
Pith/arXiv arXiv 2016
-
[12]
C. Lin, H. Liu, Q. Lin, Z. Bright, S. Tang, Y. He, M. Liu, L. Zhu, C. Le, Obja- verse++: Curated 3D object dataset with quality annotations, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025, pp. 6872–6881
2025
-
[13]
H. Slim, X. Li, Y. Li, M. Ahmed, M. Ayman, U. Upadhyay, A. Abdelreheem, A. Prajapati, S. Pothigara, P. Wonka, M. Elhoseiny, 3DCoMPaT++: An im- proved large-scale 3D vision dataset for compositional recognition, IEEE Transac- tions on Pattern Analysis and Machine Intelligence 47 (12) (2025) 11431–11445. doi:10.1109/TPAMI.2025.3597476
-
[14]
P. K. Jayaraman, A. Sanghi, J. G. Lambourne, K. D. D. Willis, T. Davies, H. Shayani, N. Morris, UV-Net: Learning from boundary representations, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 11703–11712
2021
-
[15]
P. K. Jayaraman, J. G. Lambourne, N. Desai, K. D. D. Willis, A. Sanghi, N. J. W. Morris, SolidGen: An autoregressive model for direct B-rep synthesis (2023).arXiv: 2203.13944. URLhttps://arxiv.org/abs/2203.13944
arXiv 2023
-
[16]
X. Xu, J. Lambourne, P. Jayaraman, Z. Wang, K. Willis, Y. Furukawa, BrepGen: A B-rep generative diffusion model with structured latent geometry, ACM Transactions on Graphics 43 (4) (Jul. 2024).doi:10.1145/3658129. 22
-
[17]
M. Lee, D. Zhang, C. Jambon, Y. M. Kim, BrepDiff: Single-stage B-rep diffusion model, in: Proceedings of the Special Interest Group on Computer Graphics and In- teractive Techniques Conference Conference Papers, SIGGRAPH Conference Papers ’25, Association for Computing Machinery, 2025.doi:10.1145/3721238.3730698
-
[18]
E. Dupont, K. Cherenkova, A. Kacem, S. A. Ali, I. Arzhannikov, G. Gusev, D. Aouada, CADOps-Net: Jointly learning CAD operation types and steps from boundary-representations, in: 2022 International Conference on 3D Vision (3DV), IEEE, 2022, pp. 114–123.doi:10.1109/3DV57658.2022.00024
-
[19]
C. Zhang, A. Polette, R. Pinqui´ e, G. Carasi, H. De Charnace, J.-P. Pernot, eCAD- Net: Editable parametric CAD models reconstruction from dumb B-rep models using deep neural networks, Computer-Aided Design 178 (2025) 103806.doi:10.1016/j. cad.2024.103806
work page doi:10.1016/j 2025
-
[20]
M. S. Khan, S. Sinha, T. U. Sheikh, D. Stricker, S. A. Ali, M. Z. Afzal, Text2CAD: Generating sequential CAD designs from beginner-to-expert level text prompts, in: Advances in Neural Information Processing Systems, Vol. 37, Curran Associates, Inc., 2024, pp. 7552–7579.doi:10.52202/079017-0242
-
[21]
F. Qin, S. Lu, J. Hou, C. Wang, M. Fang, L. Liu, Drawing2CAD: Sequence-to- sequence learning for CAD generation from vector drawings, in: Proceedings of the 33rd ACM International Conference on Multimedia, MM ’25, Association for Com- puting Machinery, 2025, pp. 10573–10582.doi:10.1145/3746027.3755782
-
[22]
X. Yin, X. Lu, J. Shen, J. Ni, H. Li, R. Tong, M. Tang, P. Du, RLCAD: Reinforcement learning training gym for revolution involved CAD command sequence generation, Computer-Aided Design 192 (2026) 104027.doi:10.1016/j.cad.2025.104027
-
[23]
Rukhovich, E
D. Rukhovich, E. Dupont, D. Mallis, K. Cherenkova, A. Kacem, D. Aouada, CAD- Recode: Reverse engineering CAD code from point clouds, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 9801– 9811
2025
-
[24]
M. Ataei, F. Askari, K. R. Malekshan, P. K. Jayaraman, Zero-to-CAD: Agentic synthesis of interpretable CAD programs at million-scale without real data (2026). arXiv:2604.24479. URLhttps://arxiv.org/abs/2604.24479
Pith/arXiv arXiv 2026
-
[25]
Y. Guan, X. Wang, X. Xing, J. Zhang, D. Xu, Q. Yu, CAD-Coder: Text-to-CAD generation with chain-of-thought and geometric reward, in: Advances in Neural Infor- mation Processing Systems, Vol. 38, Curran Associates, Inc., 2025, pp. 59765–59789
2025
-
[26]
J. Li, Q. Zhang, Q. Chen, G. Qiu, Y. Lou, X. Zhou, Towards high-fidelity CAD gener- ation via LLM-driven program generation and text-based B-rep primitive grounding (2026).arXiv:2603.11831. URLhttps://arxiv.org/abs/2603.11831
Pith/arXiv arXiv 2026
-
[27]
M. F. Alam, F. Ahmed, GenCAD: Image-conditioned Computer-Aided Design gener- ation with transformer-based contrastive representation and diffusion priors (2025). arXiv:2409.16294. URLhttps://arxiv.org/abs/2409.16294 23
arXiv 2025
-
[28]
D. Gao, D. Rozenberszki, S. Leutenegger, A. Dai, DiffCAD: Weakly-supervised prob- abilistic CAD model retrieval and alignment from an RGB image, ACM Transactions on Graphics 43 (4) (Jul. 2024).doi:10.1145/3658236
-
[29]
S. Wang, C. Chen, X. Le, Q. Xu, L. Xu, Y. Zhang, J. Yang, CAD-GPT: Synthesising CAD construction sequence with spatial reasoning-enhanced multimodal LLMs, Pro- ceedings of the AAAI Conference on Artificial Intelligence 39 (8) (2025) 7880–7888. doi:10.1609/aaai.v39i8.32849. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/32849
-
[30]
R. Wang, Y. Yuan, S. Sun, J. Bian, Text-to-CAD generation through infusing visual feedback in Large Language Models (2025).arXiv:2501.19054. URLhttps://arxiv.org/abs/2501.19054
arXiv 2025
-
[31]
J. Xu, C. Wang, Z. Zhao, W. Liu, Y. Ma, S. Gao, CAD-MLLM: Unifying multimodality-conditioned CAD generation with MLLM (2025).arXiv:2411.04954. URLhttps://arxiv.org/abs/2411.04954
arXiv 2025
-
[32]
R. Li, S. Li, Y. Mu, M. Ding, SldprtNet: A large-scale multimodal dataset for CAD generation in language-driven 3D design (2026).arXiv:2603.13098. URLhttps://arxiv.org/abs/2603.13098
arXiv 2026
-
[33]
A. R. Colligan, T. T. Robinson, D. C. Nolan, Y. Hua, W. Cao, Hierarchical CADNet: Learning from B-Reps for machining feature recognition, Computer-Aided Design 147 (2022) 103226.doi:10.1016/j.cad.2022.103226. URLhttps://www.sciencedirect.com/science/article/pii/ S0010448522000240
-
[34]
S. Zhang, Z. Guan, H. Jiang, X. Wang, P. Tan, BrepMFR: Enhancing ma- chining feature recognition in B-rep models through deep learning and do- main adaptation, Computer Aided Geometric Design 111 (2024) 102318. doi:10.1016/j.cagd.2024.102318. URLhttps://www.sciencedirect.com/science/article/pii/ S0167839624000529
-
[35]
Qwen Team, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, Z. ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.