Multi-Level Analyzation of Imbalance to Resolve Non-IID-Ness in Federated Learning
Pith reviewed 2026-06-27 16:49 UTC · model grok-4.3
The pith
FedBB corrects imbalance at case, class and client levels to reduce non-IID effects in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
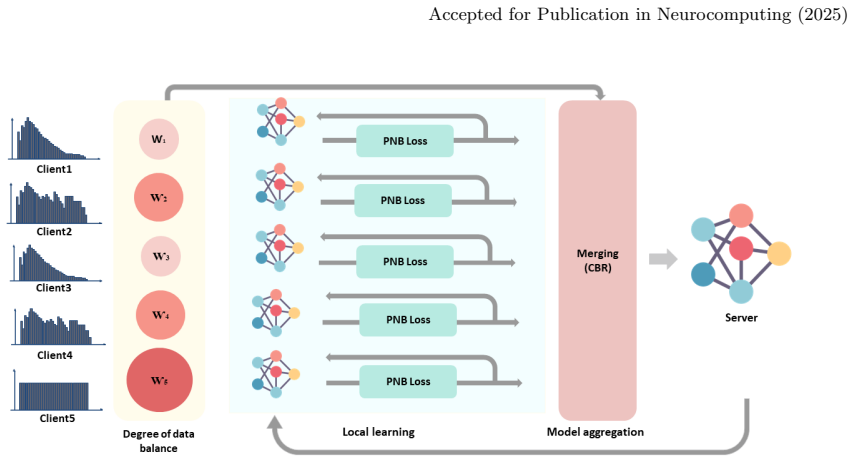
Defining imbalance at the inter-case, inter-class and inter-client levels allows a combination of PNB loss for local training and CBR reweighting for aggregation to produce a global model that accurately classifies all classes on heterogeneous client data.
What carries the argument
Three-level imbalance analysis together with the Positive Negative Balanced loss (which weights minority cases and classes) and Client Balanced Reweighting (which adjusts client influence during aggregation).
If this is right
- Local training becomes more robust to highly skewed client datasets.
- Global aggregation favors models from clients whose data is less skewed.
- Only summary statistics are needed, limiting exposure of raw client data.
- The same components can serve as a baseline for both generic and personalized federated learning.
Where Pith is reading between the lines
- The three-level framing may apply to other modalities such as text or sensor streams that exhibit similar case-class-client skews.
- Reducing reliance on full data sharing could support stricter privacy regulations in medical or financial federated settings.
- A follow-up test could measure whether the method still helps when label noise or feature shift, rather than count imbalance, is the dominant non-IID source.
Load-bearing premise
The three imbalance levels are the main causes of non-IID degradation and PNB loss plus CBR reweighting can be applied without introducing fresh biases on actual client data distributions.
What would settle it
A controlled experiment on client data whose imbalance patterns fall outside the three defined levels, in which FedBB shows no accuracy gain over standard FedAvg.
Figures



read the original abstract
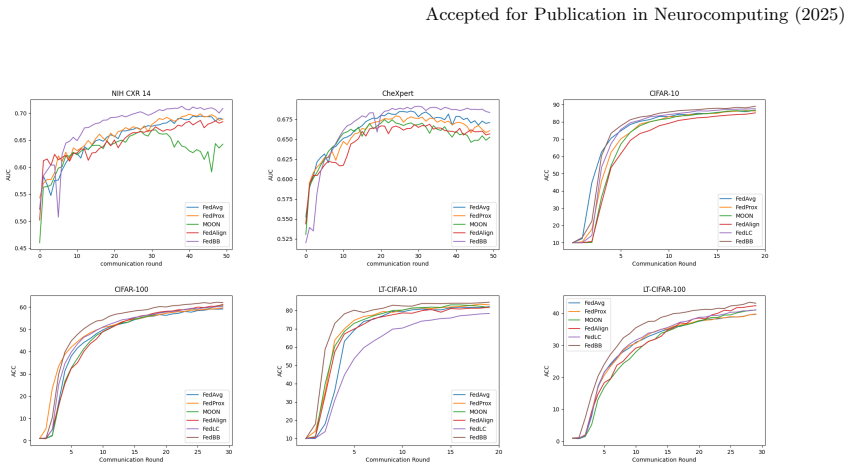
Class imbalance is a common problem in deep learning that severely degrades performance. In federated learning (FL), it is a critical factor contributing to non-identically distributed data (non-IID). Building on several previous attempts, we define and analyze imbalance issues in FL at three levels: inter-case, inter-class, and inter-client. Inter-case imbalance addresses the imbalance in every single class; inter-class imbalance compares the number of data between different classes. Inter-client imbalance represents different skewness of local data between clients. Based on these concepts, we propose FedBB, which consists of two main components: (1) Positive Negative Balanced (PNB) loss function addresses the inter-case and inter-class imbalances in local training, enhancing generalization on highly skewed local client datasets. It optimizes both multi-label and multi-class classifications by assigning higher weights to minority cases or classes. (2) Client Balanced Reweighting (CBR) reweights clients based on inter-client imbalance during model aggregation, giving greater weight to models trained on less skewed datasets. Various experiments on X-ray and natural image datasets demonstrate that FedBB outperforms other algorithms in both performance and efficiency. Additionally, it requires limited statistical information, which is beneficial for privacy protection. Through ablation studies, we proved that PNB loss and CBR independently contribute to performance. As FedBB aims to build a global model that accurately classifies all classes, it can serve as a baseline for the generic and personalized FL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines imbalance in federated learning at three levels (inter-case, inter-class, inter-client) as drivers of non-IID degradation and proposes FedBB, which combines a Positive Negative Balanced (PNB) loss for local training (reweighting minority cases/classes) with Client Balanced Reweighting (CBR) during aggregation (weighting clients by skewness). It claims that experiments on X-ray and natural-image datasets show FedBB outperforming baselines in accuracy and efficiency, that ablation studies demonstrate independent contributions from PNB and CBR, and that the method requires only limited statistical information, aiding privacy. The approach is positioned as a baseline for generic and personalized FL.
Significance. If the empirical claims are substantiated with full metrics and robustness checks, the multi-level imbalance taxonomy offers a structured lens on non-IID sources and the two-component method supplies a lightweight, privacy-preserving mitigation strategy that could be adopted as a reference implementation. The limited-statistics requirement is a concrete practical strength.
major comments (2)
- [Abstract] Abstract and experimental claims: the assertion that 'various experiments demonstrate that FedBB outperforms other algorithms in both performance and efficiency' and that 'ablation studies proved that PNB loss and CBR independently contribute' supplies no quantitative metrics, baseline names, dataset sizes, statistical tests, or cross-validation details. This directly undermines verification of the central outperformance claim.
- [Method / FedBB components] Proposal of PNB+CBR (implicitly in the method section): the claim that these components address the three defined imbalance levels without introducing new biases rests on the untested assumption that count-based skewness fully captures client heterogeneity. No stress tests are described on distributions containing feature skew, label noise, or client-size variation outside pure count statistics, which are common in real FL and could amplify variance under reweighting.
minor comments (2)
- [Title] Title uses 'Analyzation'; standard term is 'Analysis'.
- [PNB loss description] The statement that PNB 'optimizes both multi-label and multi-class classifications' is stated without clarifying whether the same weighting formula applies to both or whether separate formulations are used.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We provide point-by-point responses to the major comments and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental claims: the assertion that 'various experiments demonstrate that FedBB outperforms other algorithms in both performance and efficiency' and that 'ablation studies proved that PNB loss and CBR independently contribute' supplies no quantitative metrics, baseline names, dataset sizes, statistical tests, or cross-validation details. This directly undermines verification of the central outperformance claim.
Authors: We acknowledge that the abstract lacks specific quantitative details. The full paper includes these in the experiments section (Section 4), with comparisons to baselines such as FedAvg and others on datasets like Chest X-ray and natural image datasets, showing outperformance in accuracy and efficiency. To address this, we will revise the abstract to include key metrics from our results, specific baseline names, dataset sizes, and mention of the evaluation methodology. This will make the claims more verifiable directly from the abstract. revision: yes
-
Referee: [Method / FedBB components] Proposal of PNB+CBR (implicitly in the method section): the claim that these components address the three defined imbalance levels without introducing new biases rests on the untested assumption that count-based skewness fully captures client heterogeneity. No stress tests are described on distributions containing feature skew, label noise, or client-size variation outside pure count statistics, which are common in real FL and could amplify variance under reweighting.
Authors: Our definitions and method focus explicitly on the three levels of count-based imbalance (inter-case, inter-class, inter-client) as introduced in the paper. The PNB loss and CBR are designed to mitigate these without assuming they capture all possible heterogeneity. We agree that additional heterogeneities like feature skew or label noise are not tested in our experiments, which are limited to the defined imbalances on the X-ray and natural image datasets. We will revise the manuscript to include a limitations subsection discussing these aspects and the potential for variance amplification, while maintaining that within the paper's scope, no new biases are introduced as reweighting uses only aggregate counts. revision: partial
Circularity Check
No circularity: empirical proposal with external dataset validation and no self-referential derivations
full rationale
The paper defines three imbalance levels (inter-case, inter-class, inter-client) as conceptual categories and proposes PNB loss plus CBR reweighting as an empirical method. It reports performance on X-ray and natural image datasets plus ablation studies showing independent contributions. No equations, fitted parameters, or predictions are presented that reduce by construction to quantities defined from the same data or prior self-citations. The central claims rest on experimental outcomes rather than any load-bearing self-citation chain or definitional equivalence. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Ar- cas. Communication-efficient learning of deep networks from decentralized data. InArtifi- cial intelligence and statistics, pages 1273–1282. PMLR, 2017
2017
-
[2]
The future of digital health with federated learning.NPJ digital medicine, 3(1):119, 2020
Nicola Rieke, Jonny Hancox, Wenqi Li, Fausto Milletari, Holger R Roth, Shadi Albarqouni, Spyridon Bakas, Mathieu N Galtier, Bennett A Landman, Klaus Maier-Hein, et al. The future of digital health with federated learning.NPJ digital medicine, 3(1):119, 2020
2020
-
[3]
Secure, privacy-preserving and federated machine learning in medical imaging.Nature Machine Intelligence, 2(6):305–311, 2020
Georgios A Kaissis, Marcus R Makowski, Daniel R¨ uckert, and Rickmer F Braren. Secure, privacy-preserving and federated machine learning in medical imaging.Nature Machine Intelligence, 2(6):305–311, 2020
2020
-
[4]
Advances and open problems in federated learning.Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aur´ elien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cum- mings, et al. Advances and open problems in federated learning.Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021
2021
-
[5]
Federated learning: collaborative machine learning without centralized training data
Abhishek V A, Binny S2, Johan T R, Nithin Raj, and Vishal Thomas. Federated learning: collaborative machine learning without centralized training data. volume 6, page 355, 2022
2022
-
[6]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Measuring the effects of non-identical data distribution for federated visual classification.arXiv preprint arXiv:1909.06335, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[7]
Scaffold: Stochastic controlled averaging for federated learn- ing
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learn- ing. InInternational conference on machine learning, pages 5132–5143. PMLR, 2020
2020
-
[8]
Continual local training for better initialization of federated models
Xin Yao and Lifeng Sun. Continual local training for better initialization of federated models. In2020 IEEE International Conference on Image Processing (ICIP), pages 1736–
-
[9]
Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
2020
-
[10]
Local learning matters: Rethinking data heterogeneity in federated learning
Matias Mendieta, Taojiannan Yang, Pu Wang, Minwoo Lee, Zhengming Ding, and Chen Chen. Local learning matters: Rethinking data heterogeneity in federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8397–8406, 2022. 16 Accepted for Publication in Neurocomputing (2025)
2022
-
[11]
Fedmd: Heterogenous federated learning via model distillation,
Daliang Li and Junpu Wang. Fedmd: Heterogenous federated learning via model distilla- tion.arXiv preprint arXiv:1910.03581, 2019
-
[12]
Ensemble attention distillation for privacy-preserving fed- erated learning
Xuan Gong, Abhishek Sharma, Srikrishna Karanam, Ziyan Wu, Terrence Chen, David Doermann, and Arun Innanje. Ensemble attention distillation for privacy-preserving fed- erated learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15076–15086, 2021
2021
-
[13]
Fine-tuning global model via data-free knowledge distillation for non-iid federated learning
Lin Zhang, Li Shen, Liang Ding, Dacheng Tao, and Ling-Yu Duan. Fine-tuning global model via data-free knowledge distillation for non-iid federated learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10174–10183, 2022
2022
-
[14]
Reliable and inter- pretable personalized federated learning
Zixuan Qin, Liu Yang, Qilong Wang, Yahong Han, and Qinghua Hu. Reliable and inter- pretable personalized federated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20422–20431, 2023
2023
-
[15]
Pa- rameterized knowledge transfer for personalized federated learning.Advances in Neural Information Processing Systems, 34:10092–10104, 2021
Jie Zhang, Song Guo, Xiaosong Ma, Haozhao Wang, Wenchao Xu, and Feijie Wu. Pa- rameterized knowledge transfer for personalized federated learning.Advances in Neural Information Processing Systems, 34:10092–10104, 2021
2021
-
[16]
Layer-wised model aggregation for personalized federated learning
Xiaosong Ma, Jie Zhang, Song Guo, and Wenchao Xu. Layer-wised model aggregation for personalized federated learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10092–10101, 2022
2022
-
[17]
Neel Guha, Ameet Talwalkar, and Virginia Smith. One-shot federated learning.arXiv preprint arXiv:1902.11175, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[18]
Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach.Advances in Neural Information Processing Systems, 33:3557–3568, 2020
Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach.Advances in Neural Information Processing Systems, 33:3557–3568, 2020
2020
-
[19]
Federated learning with data-agnostic distribution fusion
Jian-hui Duan, Wenzhong Li, Derun Zou, Ruichen Li, and Sanglu Lu. Federated learning with data-agnostic distribution fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8074–8083, 2023
2023
-
[20]
Addressing class imbalance in federated learning
Lixu Wang, Shichao Xu, Xiao Wang, and Qi Zhu. Addressing class imbalance in federated learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10165–10173, 2021
2021
-
[21]
Federated visual classification with real-world data distribution
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Federated visual classification with real-world data distribution. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part X 16, pages 76–92. Springer, 2020
2020
-
[22]
Hong-You Chen and Wei-Lun Chao. On bridging generic and personalized federated learn- ing for image classification.arXiv preprint arXiv:2107.00778, 2021
-
[23]
A review of methods for imbalanced multi-label classification.Pattern Recognition, 118:107965, 2021
Adane Nega Tarekegn, Mario Giacobini, and Krzysztof Michalak. A review of methods for imbalanced multi-label classification.Pattern Recognition, 118:107965, 2021
2021
-
[24]
Elisa Ferrari and Davide Bacciu. Addressing fairness, bias and class imbalance in machine learning: the fbi-loss.arXiv preprint arXiv:2105.06345, 2021
-
[25]
Handling inter-class and intra-class imbalance in class-imbalanced learning
Zhining Liu, Pengfei Wei, Zhepei Wei, Boyang Yu, Jing Jiang, Wei Cao, Jiang Bian, and Yi Chang. Handling inter-class and intra-class imbalance in class-imbalanced learning. arXiv preprint arXiv:2111.12791, 2021. 17 Accepted for Publication in Neurocomputing (2025)
-
[26]
Towards personalized federated learning.IEEE Transactions on Neural Networks and Learning Systems, 2022
Alysa Ziying Tan, Han Yu, Lizhen Cui, and Qiang Yang. Towards personalized federated learning.IEEE Transactions on Neural Networks and Learning Systems, 2022
2022
-
[27]
Ditto: Fair and robust feder- ated learning through personalization
Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. Ditto: Fair and robust feder- ated learning through personalization. InInternational Conference on Machine Learning, pages 6357–6368. PMLR, 2021
2021
-
[28]
Model-contrastive federated learning
Qinbin Li, Bingsheng He, and Dawn Song. Model-contrastive federated learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10713–10722, 2021
2021
-
[29]
Gradaug: A new regularization method for deep neural networks.Advances in Neural Information Processing Systems, 33:14207– 14218, 2020
Taojiannan Yang, Sijie Zhu, and Chen Chen. Gradaug: A new regularization method for deep neural networks.Advances in Neural Information Processing Systems, 33:14207– 14218, 2020
2020
-
[30]
Isfl: Federated learning for non-iid data with local importance sampling.IEEE Internet of Things Journal, 2024
Zheqi Zhu, Yuchen Shi, Pingyi Fan, Chenghui Peng, and Khaled B Letaief. Isfl: Federated learning for non-iid data with local importance sampling.IEEE Internet of Things Journal, 2024
2024
-
[31]
Robust federated learning with noisy and heterogeneous clients
Xiuwen Fang and Mang Ye. Robust federated learning with noisy and heterogeneous clients. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10072–10081, 2022
2022
-
[32]
Fair resource allocation in federated learning.arXiv preprint arXiv:1905.10497, 2019
Tian Li, Maziar Sanjabi, Ahmad Beirami, and Virginia Smith. Fair resource allocation in federated learning.arXiv preprint arXiv:1905.10497, 2019
-
[33]
Tackling the objective inconsistency problem in heterogeneous federated optimization.Advances in neural information processing systems, 33:7611–7623, 2020
Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H Vincent Poor. Tackling the objective inconsistency problem in heterogeneous federated optimization.Advances in neural information processing systems, 33:7611–7623, 2020
2020
-
[34]
Fedopt: Towards communication efficiency and privacy preservation in federated learning.Applied Sciences, 10(8):2864, 2020
Muhammad Asad, Ahmed Moustafa, and Takayuki Ito. Fedopt: Towards communication efficiency and privacy preservation in federated learning.Applied Sciences, 10(8):2864, 2020
2020
-
[35]
An agnostic approach to federated learning with class imbalance
Zebang Shen, Juan Cervino, Hamed Hassani, and Alejandro Ribeiro. An agnostic approach to federated learning with class imbalance. InInternational Conference on Learning Rep- resentations, 2021
2021
-
[36]
Federated learning with label distribution skew via logits calibration
Jie Zhang, Zhiqi Li, Bo Li, Jianghe Xu, Shuang Wu, Shouhong Ding, and Chao Wu. Federated learning with label distribution skew via logits calibration. InInternational Conference on Machine Learning, pages 26311–26329. PMLR, 2022
2022
-
[37]
Xinting Liao, Weiming Liu, Chaochao Chen, Pengyang Zhou, Huabin Zhu, Yanchao Tan, Jun Wang, and Yue Qi. Hyperfed: hyperbolic prototypes exploration with consistent aggregation for non-iid data in federated learning.arXiv preprint arXiv:2307.14384, 2023
-
[38]
Joint local relational augmentation and global nash equilibrium for federated learning with non-iid data
Xinting Liao, Chaochao Chen, Weiming Liu, Pengyang Zhou, Huabin Zhu, Shuheng Shen, Weiqiang Wang, Mengling Hu, Yanchao Tan, and Xiaolin Zheng. Joint local relational augmentation and global nash equilibrium for federated learning with non-iid data. In Proceedings of the 31st ACM International Conference on Multimedia, pages 1536–1545, 2023
2023
-
[39]
Federated probabilistic preference distribution modelling with compactness co-clustering for privacy-preserving multi-domain recommendation
Weiming Liu, Chaochao Chen, Xinting Liao, Mengling Hu, Jianwei Yin, Yanchao Tan, and Longfei Zheng. Federated probabilistic preference distribution modelling with compactness co-clustering for privacy-preserving multi-domain recommendation. InProceedings of the 32rd International Joint Conference on Artificial Intelligence (IJCAI), pages 2206–2214, 2023. ...
2023
-
[40]
Fediic: Towards robust federated learning for class-imbalanced medical image classification
Nannan Wu, Li Yu, Xin Yang, Kwang-Ting Cheng, and Zengqiang Yan. Fediic: Towards robust federated learning for class-imbalanced medical image classification. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 692–
-
[41]
Xinyi Shang, Yang Lu, Gang Huang, and Hanzi Wang. Federated learning on heteroge- neous and long-tailed data via classifier re-training with federated features.arXiv preprint arXiv:2204.13399, 2022
-
[42]
Xiaolin Zheng, Mengling Hu, Weiming Liu, Chaochao Chen, and Xinting Liao. Robust representation learning with reliable pseudo-labels generation via self-adaptive optimal transport for short text clustering.arXiv preprint arXiv:2305.16335, 2023
-
[43]
Clip- guided federated learning on heterogeneity and long-tailed data
Jiangming Shi, Shanshan Zheng, Xiangbo Yin, Yang Lu, Yuan Xie, and Yanyun Qu. Clip- guided federated learning on heterogeneity and long-tailed data. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14955–14963, 2024
2024
-
[44]
Learning to model the tail.Advances in neural information processing systems, 30, 2017
Yu-Xiong Wang, Deva Ramanan, and Martial Hebert. Learning to model the tail.Advances in neural information processing systems, 30, 2017
2017
-
[45]
Sharing representations for long tail computer vision problems
Samy Bengio. Sharing representations for long tail computer vision problems. InProceed- ings of the 2015 ACM on International Conference on Multimodal Interaction, pages 1–1, 2015
2015
-
[46]
Factors in finetuning deep model for object detection with long-tail distribution
Wanli Ouyang, Xiaogang Wang, Cong Zhang, and Xiaokang Yang. Factors in finetuning deep model for object detection with long-tail distribution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 864–873, 2016
2016
-
[48]
The Devil is in the Tails: Fine-grained Classification in the Wild
Grant Van Horn and Pietro Perona. The devil is in the tails: Fine-grained classification in the wild.arXiv preprint arXiv:1709.01450, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Deep Active Learning over the Long Tail
Yonatan Geifman and Ran El-Yaniv. Deep active learning over the long tail.arXiv preprint arXiv:1711.00941, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Range loss for deep face recognition with long-tailed training data
Xiao Zhang, Zhiyuan Fang, Yandong Wen, Zhifeng Li, and Yu Qiao. Range loss for deep face recognition with long-tailed training data. InProceedings of the IEEE International Conference on Computer Vision, pages 5409–5418, 2017
2017
-
[51]
Xi Yin, Xiang Yu, Kihyuk Sohn, Xiaoming Liu, and Manmohan Chandraker. Feature transfer learning for deep face recognition with under-represented data.arXiv preprint arXiv:1803.09014, 2018
-
[52]
A learning method for the class imbalance problem with medical data sets.Computers in biology and medicine, 40(5):509–518, 2010
Der-Chiang Li, Chiao-Wen Liu, and Susan C Hu. A learning method for the class imbalance problem with medical data sets.Computers in biology and medicine, 40(5):509–518, 2010
2010
-
[53]
A review on imbalanced data handling using undersampling and oversampling technique.Int
Mayuri S Shelke, Prashant R Deshmukh, and Vijaya K Shandilya. A review on imbalanced data handling using undersampling and oversampling technique.Int. J. Recent Trends Eng. Res, 3(4):444–449, 2017
2017
-
[54]
Imbalanced adversarial training with reweighting
Wentao Wang, Han Xu, Xiaorui Liu, Yaxin Li, Bhavani Thuraisingham, and Jiliang Tang. Imbalanced adversarial training with reweighting. In2022 IEEE International Conference on Data Mining (ICDM), pages 1209–1214. IEEE, 2022. 19 Accepted for Publication in Neurocomputing (2025)
2022
-
[56]
Addressing the class imbalance problem in medical image segmentation via accelerated tversky loss function
Nikhil Nasalwai, Narinder Singh Punn, Sanjay Kumar Sonbhadra, and Sonali Agarwal. Addressing the class imbalance problem in medical image segmentation via accelerated tversky loss function. InPacific-Asia conference on knowledge discovery and data mining, pages 390–402. Springer, 2021
2021
-
[57]
Distributional robustness loss for long-tail learning
Dvir Samuel and Gal Chechik. Distributional robustness loss for long-tail learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9495– 9504, 2021
2021
-
[58]
Learning deep representation for imbalanced classification
Chen Huang, Yining Li, Chen Change Loy, and Xiaoou Tang. Learning deep representation for imbalanced classification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5375–5384, 2016
2016
-
[59]
Class-balanced loss based on effective number of samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9268–9277, 2019
2019
-
[60]
https://www.kaggle.com/code/redwankarims- ony/nih-chest-x-ray8-classifier-cnn- visualization
SONY. https://www.kaggle.com/code/redwankarims- ony/nih-chest-x-ray8-classifier-cnn- visualization. 2020
2020
-
[61]
Git re-basin: Merging models modulo permutation symmetries, 2022.URL https://arxiv
Samuel K Ainsworth, Jonathan Hayase, and Srinivasa. Git re-basin: Merging models modulo permutation symmetries, 2022.URL https://arxiv. org/abs/2209.04836, 2022
-
[62]
On the convergence of fedavg on non-iid data.arXiv preprint arXiv:1907.02189, 2019
Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of fedavg on non-iid data.arXiv preprint arXiv:1907.02189, 2019
-
[63]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceed- ings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019
2019
-
[64]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[65]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhi- heng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. InInternational journal of computer vision, volume 115, pages 211–252. Springer, 2015
2015
-
[66]
A state-of-the-art survey on solving non-iid data in federated learning.Future Generation Computer Systems, 135:244–258, 2022
Xiaodong Ma, Jia Zhu, Zhihao Lin, Shanxuan Chen, and Yangjie Qin. A state-of-the-art survey on solving non-iid data in federated learning.Future Generation Computer Systems, 135:244–258, 2022
2022
-
[67]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[68]
A survey on addressing high-class imbalance in big data
JL Leevy, TM Khoshgoftaar, RA Bauder, and N Seliya. A survey on addressing high-class imbalance in big data. j big data 5 (1): 42. 2018
2018
-
[69]
Bridging the gap be- tween natural and medical images through deep colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, and Tatiana Tommasi. Bridging the gap be- tween natural and medical images through deep colorization. In2020 25th International Conference on Pattern Recognition (ICPR), pages 835–842. IEEE, 2021. 20 Accepted for Publication in Neurocomputing (2025) Appendix A Foreword This section includes several detailed explan...
2021
-
[70]
E||▽Fk(wk t , ξ)−▽F k(wk t )||2 ≤σ 2 k (16) This means that when we train the local model, the loss value has an upper bound
assumes that the stochastic gradient has a limit and this value impacts the overall convergence result bound. E||▽Fk(wk t , ξ)−▽F k(wk t )||2 ≤σ 2 k (16) This means that when we train the local model, the loss value has an upper bound. In the case in which data are highly skewed, it is well known that the average loss value of the minority class is higher...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.