A Diffusive Classification Loss for Learning Energy-based Generative Models
Pith reviewed 2026-05-22 12:03 UTC · model grok-4.3
The pith
A classification loss across noise levels trains energy-based models more effectively than score matching alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the Diffusive Classification objective reframes EBM learning as a supervised classification problem across noise levels, yielding higher-fidelity energy estimates that remain computationally tractable and can be combined with score-based objectives, thereby supporting more reliable use in compositional sampling and Boltzmann Generator Monte Carlo methods.
What carries the argument
The Diffusive Classification (DiffCLF) objective, which converts time-dependent energy estimation into a binary classification task distinguishing data from noise at each diffusion step.
If this is right
- EBMs trained with DiffCLF produce energy estimates closer to ground truth on Gaussian mixtures than score-matching baselines.
- The resulting models support accurate compositional sampling of multiple distributions.
- Monte Carlo sampling within Boltzmann Generators becomes more reliable when using the learned energies.
- The loss integrates with existing score-based training without extra bias or prohibitive cost.
Where Pith is reading between the lines
- The same classification framing might be adapted to train energy functions outside the diffusion setting.
- Better energy estimates could improve downstream tasks that rely on explicit likelihoods rather than samples alone.
- Scaling tests on image or molecular datasets would clarify whether the gains hold in high-dimensional regimes.
Load-bearing premise
That reframing EBM learning as supervised classification across noise levels avoids mode blindness and combines with score-based objectives without introducing new biases or computational problems.
What would settle it
If the energies learned on analytic Gaussian mixtures deviate substantially from the known ground-truth energies or if composed models fail to generate samples consistent with the product distribution.
Figures







read the original abstract
Score-based generative models have recently achieved remarkable success. While they are usually parameterized by the score, an alternative way is to use a series of time-dependent energy-based models (EBMs), where the score is obtained from the negative input-gradient of the energy. Crucially, EBMs can be leveraged not only for generation, but also for tasks such as compositional sampling or building Boltzmann Generators via Monte Carlo methods. However, training EBMs remains challenging. Direct maximum likelihood is computationally prohibitive due to the need for nested sampling, while score matching, though efficient, suffers from mode blindness. To address these issues, we introduce the Diffusive Classification (DiffCLF) objective, a simple method that avoids blindness while remaining computationally efficient. DiffCLF reframes EBM learning as a supervised classification problem across noise levels, and can be seamlessly combined with standard score-based objectives. We validate the effectiveness of DiffCLF by comparing the estimated energies against ground truth in analytical Gaussian mixture cases, and by applying the trained models to tasks such as model composition and Boltzmann Generator sampling. Our results show that DiffCLF enables EBMs with higher fidelity and broader applicability than existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Diffusive Classification (DiffCLF) objective for training time-dependent energy-based models (EBMs) whose scores are obtained via input gradients. DiffCLF reframes EBM learning as supervised classification across noise levels, is claimed to avoid the mode-blindness of score matching, remains computationally efficient, and can be combined with standard score-based objectives. Validation consists of energy matching against ground truth on analytical low-dimensional Gaussian mixtures together with qualitative demonstrations on compositional sampling and Boltzmann-generator tasks.
Significance. If the central claims hold, DiffCLF would supply a practical route to training EBMs that retain explicit energy functions while mitigating a known weakness of pure score matching. This could improve fidelity and applicability in downstream tasks that exploit the energy directly, such as composition and MCMC-based sampling.
major comments (2)
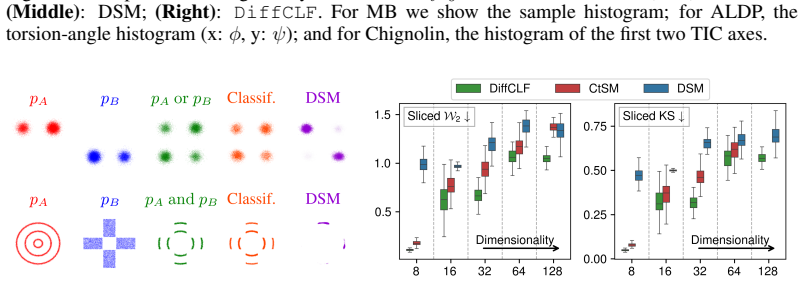
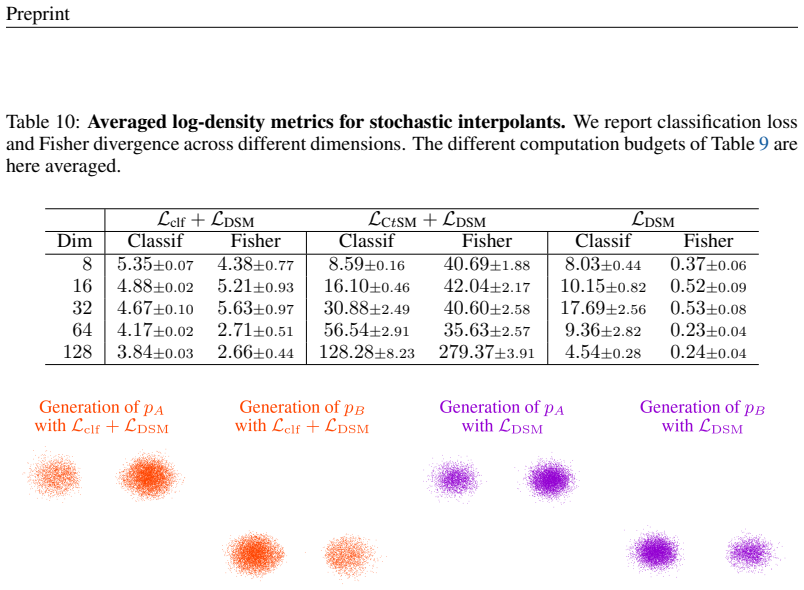
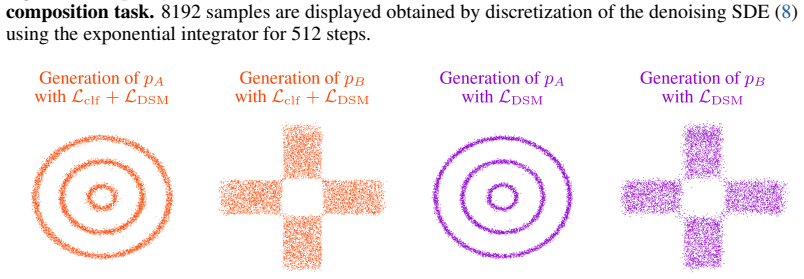
- [§4] §4 (Experiments) and the associated figures/tables: validation is confined to 2-D/3-D analytic Gaussian mixtures. These are precisely the regimes in which score matching already recovers modes; the manuscript provides no quantitative mode-recovery metric (recovered-mode count, Wasserstein distance to the full mixture, or effective sample size under MCMC) against a score-matching baseline on deliberately higher-dimensional or non-analytic multi-modal targets. This leaves the central claim that DiffCLF “avoids blindness” without direct support.
- [§3] §3 (Method): the claim that DiffCLF recovers the correct energy (hence the score) and can be “seamlessly combined” with score-based objectives is asserted but not accompanied by an explicit derivation or bias analysis showing that the classification loss does not re-introduce new mode-selection biases or alter the fixed point of the combined objective.
minor comments (2)
- [§2] Notation for the noise schedule and the classification labels should be introduced once in §2 and used consistently thereafter; several symbols are redefined inline.
- [Abstract] The abstract states “higher fidelity” without reporting any numerical improvement (e.g., energy MSE or log-likelihood gap) relative to the score-matching baseline even on the analytic GMMs.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our results and derivations.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the associated figures/tables: validation is confined to 2-D/3-D analytic Gaussian mixtures. These are precisely the regimes in which score matching already recovers modes; the manuscript provides no quantitative mode-recovery metric (recovered-mode count, Wasserstein distance to the full mixture, or effective sample size under MCMC) against a score-matching baseline on deliberately higher-dimensional or non-analytic multi-modal targets. This leaves the central claim that DiffCLF “avoids blindness” without direct support.
Authors: We agree that quantitative mode-recovery metrics on higher-dimensional non-analytic targets would provide stronger evidence. Our experiments emphasize analytic cases to enable direct ground-truth energy comparisons, which are unavailable in most high-dimensional settings. In the revised manuscript we have added effective sample size results for the Boltzmann generator task (a higher-dimensional application) and a discussion clarifying why low-dimensional analytic validation is informative for energy fidelity. Full new benchmarks on complex high-dimensional targets remain computationally demanding and are noted as future work, resulting in a partial revision. revision: partial
-
Referee: [§3] §3 (Method): the claim that DiffCLF recovers the correct energy (hence the score) and can be “seamlessly combined” with score-based objectives is asserted but not accompanied by an explicit derivation or bias analysis showing that the classification loss does not re-introduce new mode-selection biases or alter the fixed point of the combined objective.
Authors: We thank the referee for this observation. The revised manuscript now includes an explicit derivation in Section 3 demonstrating that the DiffCLF objective is minimized precisely when the learned energy equals the true energy up to an additive constant (which leaves the score unchanged). We further show that the stationary points of the combined objective coincide with those of score matching alone and that the classification term introduces no additional mode-selection bias, as its contribution to the gradient vanishes at the correct fixed point. revision: yes
Circularity Check
No circularity: DiffCLF objective is independently formulated and validated
full rationale
The paper defines DiffCLF as a new supervised classification loss reframing EBM training across noise levels, then validates it by direct energy matching to ground truth on analytic GMMs plus downstream tasks. No quoted derivation step reduces the claimed energy recovery or mode-recovery property to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior work by the same authors. The central claim therefore rests on the explicit construction of the classification objective and its empirical behavior rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions underlying score-based generative models and energy functions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DiffCLF reframes EBM learning as a supervised classification problem across noise levels... L_clf(θ; t_1:N) = −1/N ∑ E_{p_ti} [log p_θ_ti(Yi) / ∑ p_θ_tj(Yi)]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 2 (Uniqueness): the unique minimizer for the joint objective L_DSM + L_clf is attained by p_θ* = p_t
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yilun Du, Shuang Li, Joshua Tenenbaum, and Igor Mordatch
URLhttps://proceedings.neurips.cc/paper_files/paper/2019/ file/378a063b8fdb1db941e34f4bde584c7d-Paper.pdf. Yilun Du, Shuang Li, Joshua Tenenbaum, and Igor Mordatch. Improved contrastive divergence training of energy-based models. In Marina Meila and Tong Zhang (eds.),Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProcee...
-
[2]
URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ file/f0d629a734b56a642701bba7bc8bb3ed-Paper-Conference.pdf. Will Grathwohl, Kuan-Chieh Wang, Joern-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, and Kevin Swersky. Your classifier is secretly an energy based model and you should treat it like one. InInternational Conference on Learning Represe...
-
[3]
Frank P Kelly.Reversibility and stochastic networks
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/ file/a98846e9d9cc01cfb87eb694d946ce6b-Paper-Conference.pdf. Frank P Kelly.Reversibility and stochastic networks. Cambridge University Press, 2011. Taesup Kim and Yoshua Bengio. Deep directed generative models with energy-based probability estimation. InFifth International Conference on Machine Lear...
work page 2022
-
[4]
URLhttps://openreview.net/forum?id=NnMEadcdyD. John G Kirkwood. Statistical mechanics of fluid mixtures.The Journal of chemical physics, 3(5): 300–313, 1935. Yann LeCun, Sumit Chopra, Raia Hadsell, M Ranzato, and F Huang. A tutorial on energy-based learning.Predicting structured data, 1(0), 2006. Hankook Lee, Jongheon Jeong, Sejun Park, and Jinwoo Shin. G...
work page 1935
-
[5]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
URLhttps://openreview.net/forum?id=CZmHHj9MgkP. Tony Leli`evre, Mathias Rousset, and Gabriel Stoltz.Free Energy Computations. IMPERIAL COL- LEGE PRESS, 2010. doi: 10.1142/p579. URLhttps://www.worldscientific.com/ doi/abs/10.1142/p579. Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1142/p579 2010
-
[6]
Hugo Senetaire, Paul Jeha, Pierre-Alexandre Mattei, and Jes Frellsen
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/ file/8e176ef071f00f1b233461c5ad5e1b24-Paper-Conference.pdf. Hugo Senetaire, Paul Jeha, Pierre-Alexandre Mattei, and Jes Frellsen. Learning energy-based models by self-normalising the likelihood, 2025. URLhttps://arxiv.org/abs/2503. 07021. Neta Shaul, Itai Gat, Marton Havasi, Daniel Severo, Anuroop ...
work page 2023
-
[7]
Zhekun Shi, Longlin Yu, Tianyu Xie, and Cheng Zhang
URLhttps://openreview.net/forum?id=tcvMzR2NrP. Zhekun Shi, Longlin Yu, Tianyu Xie, and Cheng Zhang. Diffusion-PINN sampler, 2024. URL https://arxiv.org/abs/2410.15336. Michael R. Shirts and John D. Chodera. Statistically optimal analysis of samples from multiple equilibrium states.The Journal of Chemical Physics, 129(12), September 2008. ISSN 1089-
-
[8]
URLhttp://dx.doi.org/10.1063/1.2978177
doi: 10.1063/1.2978177. URLhttp://dx.doi.org/10.1063/1.2978177. Marta Skreta, Tara Akhound-Sadegh, Viktor Ohanesian, Roberto Bondesan, Alan Aspuru-Guzik, Arnaud Doucet, Rob Brekelmans, Alexander Tong, and Kirill Neklyudov. Feynman-kac correc- tors in diffusion: Annealing, guidance, and product of experts. InForty-second International Conference on Machine...
-
[9]
propose enforcing its self-consistency by optimizing the following objective LFPE(θ) =E t[LFPE(θ;t)],L FPE(θ;t) =E pt h ∂t logp θ t (Yt)− F t(pθ t )(Yt) 2i .(31) Although Shi et al. (2024) claim that this approach overcomes the blindness of score matching, we demonstrate in Appendix C that it remains susceptible to the same issue. The objective can also b...
work page 2024
-
[10]
∇2 θ log pθ i (y(m) i ) PN j=1 pθ j(y(m) i ) θ=θ⋆ # =− 1 N NX i=1 1 M MX m=1
train models such that their time derivatives match the ground-truth ones, which is termed Time Score Matching (tSM) (Choi et al., 2022). Jointly training with DSM, the optimality yields ∇logp θ t =∇logp t and∂ t logp θ t =∂ t logp t. However, it is not sufficient to reach the optimality of log density, i.e.logp θ t = logp t, especially when the modes are...
work page 2022
-
[11]
p1 PN j=1 pj , ..., pN PN j=1 pj # andg=
could be utilized to generalize this density-ratio estimation framework. E.1 BREGMANDIVERGENCE The Bregman divergence (Bregman, 1967) between two functionalsf:R d →R m andg:R d → Rm within an underlying measureµis defined as Dµ ϕ(f, g) =E µ [ϕ(f)−ϕ(g)− ∇ϕ(g)·(f−g)],(81) whereϕ:R m →Ris a strightly convexgeneratorand∇ϕ(g)refers to∇ gϕ(g). In the following ...
work page 1967
-
[12]
running AIS betweenρandp k,
-
[13]
resampling particles to matchp k using the previous AIS approximation, and
-
[14]
This resampling step prevents degeneracy and improves stability
running AIS betweenp k andπ. This resampling step prevents degeneracy and improves stability. While early methods performed resampling at every step, modern implementations use adaptive criteria to trigger resampling only when needed (Chopin & Papaspiliopoulos, 2020). The algorithm is presented in Algorithm 1 in the classic case where the forward and back...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.