Robust Synthesis of Adversarial Visual Examples Using a Deep Image Prior
Pith reviewed 2026-05-25 10:23 UTC · model grok-4.3
The pith
Reconstructing images via a deep image prior under adversarial constraints yields perturbations robust to affine deformations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimizing the weights of a randomly initialized convolutional network to match a target image while also driving a target classifier toward a wrong label produces an output image whose difference from the original is more resilient to affine transforms than direct adversarial perturbations, yet remains imperceptible.
What carries the argument
The deep image prior: a convolutional network whose fixed architecture acts as an implicit prior during per-image optimization to synthesize or reconstruct images.
If this is right
- Adversarial examples generated this way remain effective after common geometric image manipulations.
- The method extends directly to producing small, localized adversarial patches.
- The resulting perturbations stay visually imperceptible across many object classes.
- The approach works without requiring a separate training dataset for the prior.
Where Pith is reading between the lines
- Convolutional inductive biases may systematically produce more structured, lower-frequency adversarial signals than gradient-based pixel attacks.
- This reconstruction route could be combined with other image priors to further increase geometric robustness.
- Defenses might need to account for the specific frequency and structural properties of DIP-style perturbations rather than generic noise.
Load-bearing premise
The convolutional network structure and its optimization trajectory naturally favor perturbations that survive affine deformations better than high-frequency noise does.
What would settle it
Generate both DIP and standard adversarial examples for the same ImageNet images, apply a set of random affine transforms to each, and measure whether the DIP versions retain higher attack success rate; equal or lower success would falsify the robustness claim.
Figures




read the original abstract
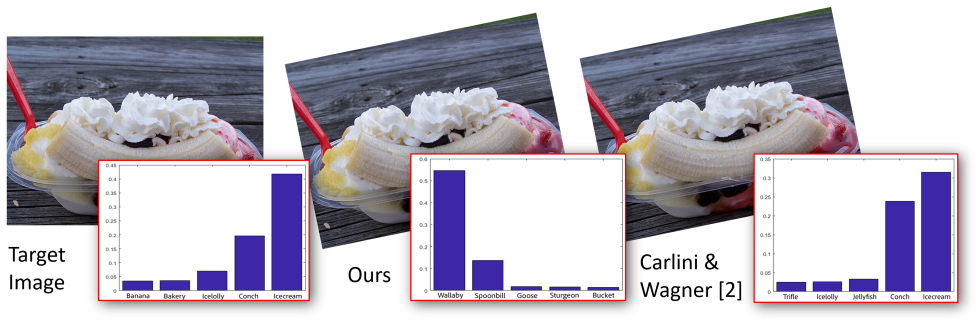
We present a novel method for generating robust adversarial image examples building upon the recent `deep image prior' (DIP) that exploits convolutional network architectures to enforce plausible texture in image synthesis. Adversarial images are commonly generated by perturbing images to introduce high frequency noise that induces image misclassification, but that is fragile to subsequent digital manipulation of the image. We show that using DIP to reconstruct an image under adversarial constraint induces perturbations that are more robust to affine deformation, whilst remaining visually imperceptible. Furthermore we show that our DIP approach can also be adapted to produce local adversarial patches (`adversarial stickers'). We demonstrate robust adversarial examples over a broad gamut of images and object classes drawn from the ImageNet dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a method for synthesizing robust adversarial examples by leveraging the Deep Image Prior (DIP) to reconstruct images subject to an adversarial constraint. This produces perturbations that remain effective under affine deformations (unlike standard high-frequency adversarial noise) while staying visually imperceptible; the approach is further adapted to generate local adversarial patches, with demonstrations across ImageNet images and classes.
Significance. If the empirical claims are supported by detailed quantitative evaluation, the work would be significant for adversarial machine learning: it shows that the convolutional inductive bias encoded in DIP can yield structured perturbations with greater robustness to common transformations than unstructured noise, offering a new route to more realistic attack generation and potentially deeper insight into why certain perturbations generalize across deformations.
major comments (2)
- [Abstract] Abstract and experimental sections: the central claim of superior robustness to affine deformation is asserted but the provided material contains no quantitative metrics (e.g., attack success rates before/after deformation, comparison tables against PGD or other baselines, or error bars), which is load-bearing for validating the empirical contribution.
- [Method] Method description: the precise formulation of the adversarial constraint inside the DIP optimization (e.g., how the classification loss is balanced against the DIP reconstruction objective) is not stated with sufficient detail to allow reproduction or to confirm that the robustness arises from the prior rather than from hyper-parameter choices.
minor comments (2)
- The manuscript should include a clear statement of the DIP network architecture, random seed handling, and optimization hyperparameters used for all reported results.
- Figure captions and legends should explicitly define the deformation parameters (rotation angle range, translation, scaling) applied in the robustness tests.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying key areas where the manuscript can be strengthened. We address each major comment below and will revise the paper accordingly to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental sections: the central claim of superior robustness to affine deformation is asserted but the provided material contains no quantitative metrics (e.g., attack success rates before/after deformation, comparison tables against PGD or other baselines, or error bars), which is load-bearing for validating the empirical contribution.
Authors: We agree that quantitative metrics are essential to substantiate the robustness claims. The current manuscript emphasizes qualitative visual results and demonstrations across ImageNet classes, but this is insufficient for rigorous validation. In the revised version we will add tables reporting attack success rates before and after affine transformations, direct comparisons against PGD and other baselines, and error bars computed over multiple random seeds and image instances. revision: yes
-
Referee: [Method] Method description: the precise formulation of the adversarial constraint inside the DIP optimization (e.g., how the classification loss is balanced against the DIP reconstruction objective) is not stated with sufficient detail to allow reproduction or to confirm that the robustness arises from the prior rather than from hyper-parameter choices.
Authors: We acknowledge that the exact optimization objective and balancing of terms were not presented with sufficient mathematical detail. The revised method section will explicitly state the full objective function, including the weighting hyper-parameter between the DIP reconstruction loss and the adversarial classification loss, along with all other optimization parameters, to enable reproduction and to clarify the role of the convolutional prior. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical optimization procedure that applies the existing deep image prior (DIP) architecture under an added adversarial loss term to synthesize perturbations. No derivation chain, equation, or uniqueness theorem is presented that reduces the claimed robustness property to a fitted parameter, self-citation, or input by construction. The central result is an observed outcome of the optimization evaluated on external ImageNet images and affine deformation tests, with no load-bearing self-citation or ansatz smuggling required for the method statement itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The deep image prior convolutional architecture enforces plausible image texture during synthesis
Reference graph
Works this paper leans on
-
[1]
T. Brown, D. Mané, A. Roy, M. Abadi, and J. Gilmer. Adver- sarial patch. arXiv preprint arXiv:1712.09665, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
N. Carlini and D. Wagner. Towards evaluating the robustness of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP), pages 39–57. IEEE, 2017
work page 2017
-
[3]
ShapeShifter: Robust physical adversarial attack on faster r-CNN object detector
Shang-Tse Chen, Cory Cornelius, Jason Martin, and Duen Horng Chau. ShapeShifter: Robust physical adversarial attack on faster r-CNN object detector. In Machine Learn- ing and Knowledge Discovery in Databases , pages 52–68. Springer International Publishing, 2019
work page 2019
-
[4]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei. ImageNet: A Large-Scale Hierarchical Image Database. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009
work page 2009
-
[5]
Boosting adversarial at- tacks with momentum
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial at- tacks with momentum. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, jun 2018
work page 2018
-
[6]
Note on Attacking Object Detectors with Adversarial Stickers
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Dawn Song, Tadayoshi Kohno, Amir Rahmati, Atul Prakash, and Florian Tramer. Note on attacking object detectors with adversarial stickers. arXiv preprint arXiv:1712.08062, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
R. Feng and B. Prabhakaran. Facilitating fashion camouflage art. In Proc. ACM Multimedia, pages 793–802, 2013
work page 2013
-
[8]
D. Glasner, S. Bagon, and M. Irani. Super-resolution from a single image. In Intl. Conference on Computer Vision (ICCV), 2009
work page 2009
-
[9]
Explaining and Harnessing Adversarial Examples
I. Goodfellow, J. Shlens, and C. Szegedy. Explain- ing and harnessing adversarial examples. arXiv preprint arXiv:1412.6572v3, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[10]
A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classifi- cation with deep convolutional neural networks. Communica- tions of the ACM, 60(6):84–90, 2017
work page 2017
-
[11]
Adversarial examples in the physical world
Alexey Kurakin, Ian Goodfellow, and Samy Bengio. Ad- versarial examples in the physical world. arXiv preprint arXiv:1607.02533, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi. Photo-realistic single image super-resolution using a generative adversarial network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 105–114, 2017
work page 2017
-
[13]
J. Lu, H. Sibai, E. Fabry, and D. Forsyth. No need to worry about adversarial examples in object detection in autonomous vehicles. arXiv preprint arXiv:1707.03501, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
A. Mahendran and A. Vedaldi. Understanding deep image representations by inverting them. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015
work page 2015
-
[15]
S.-M. Moosavi-Dezfooli, A. Fawzi, and P. Frossard. Deepfool: a simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2574–2582, 2016
work page 2016
-
[16]
N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. Celik, and A. Swami. The limitations of deep learning in adversarial settings. In Security and Privacy (EuroS&P), 2016 IEEE European Symposium on, pages 372–387. IEEE, 2016
work page 2016
-
[17]
Foolbox: A Python toolbox to benchmark the robustness of machine learning models
J. Rauber, W. Brendel, and M. Bethge. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv preprint arXiv:1707.04131, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [18]
-
[19]
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015
work page 2015
-
[20]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
S. Thys, W. Van Ranst, and T. Goedeme. Fooling automated surveillance cameras: adversarial patches to attack person detection. arXiv preprint arXiv:1904.08653, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[22]
D. Ulyanov, A. Vedaldi, and V . Lempitsky. Deep image prior. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018. 8
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.