Towards Generalized Image Manipulation Localization via Score-based Model
Pith reviewed 2026-05-19 20:11 UTC · model grok-4.3
The pith
DiffIML approximates the score function of mask distributions to iteratively recover coherent manipulation masks from noise, improving generalization over discriminative methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiffIML introduces score-based generative modeling to image manipulation localization by approximating the score function, which is the gradient of the log-likelihood, to capture the intrinsic geometric topology of mask distributions. Instead of estimating hard decision boundaries directly, the framework uses this score to iteratively recover coherent masks from noise. To make it practical, it employs a lightweight mask-specific VAE for latent-space processing and a decoupled lightweight denoising UNet, along with edge supervision and error prior to stabilize sampling. This approach circumvents the brittleness of discriminative models and demonstrates superior generalization on diverse unse
What carries the argument
DiffIML, a score-based generative framework that approximates the score function of mask distributions in a lightweight latent-space diffusion process with edge supervision and error prior to iteratively recover coherent masks.
If this is right
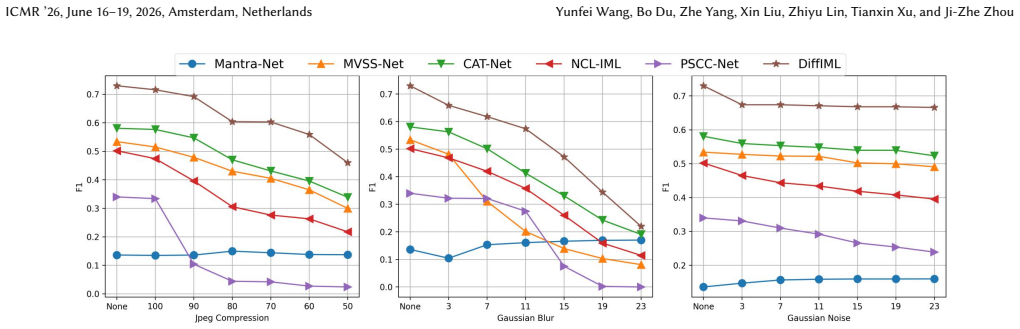
- Outperforms state-of-the-art methods by providing consistent generalization improvements on unseen manipulation types.
- Achieves better results across eight non-generative and three generative benchmarks under two distinct evaluation protocols.
- Enables efficient processing through latent-space diffusion using a lightweight VAE and decoupled denoising UNet.
- Leverages structural priors to construct masks iteratively without relying on fixed decision boundaries.
Where Pith is reading between the lines
- This score-based approach could extend to localizing other forms of image anomalies such as compression artifacts or sensor noise.
- Modeling mask distributions geometrically rather than through boundaries may reduce the need for large labeled datasets in related forensics tasks.
- Optimizing the sampling steps further could support faster verification pipelines in real-world content moderation systems.
Load-bearing premise
The learned score function, combined with edge supervision and error prior in a lightweight latent-space diffusion process, will reliably produce coherent masks without overfitting to training artifacts or requiring extensive per-dataset tuning.
What would settle it
Testing the model on a new dataset containing manipulation types absent from the training data and checking whether the output masks are incoherent or fail to accurately localize the edits.
Figures


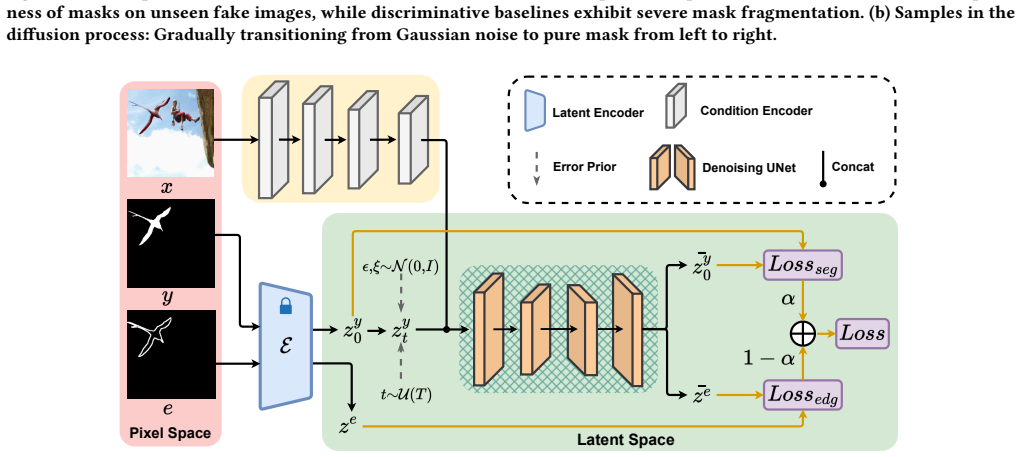
read the original abstract
With the rapid evolution of synthetic media, Image Manipulation Localization (IML) has emerged as a critical component in multimedia forensics for ensuring the integrity of digital content. However, generalization remains a core challenge, as existing discriminative methods typically learn a fixed decision boundary that tends to overfit to specific training artifacts and fails to adapt to unseen manipulation types. To address this, we propose DiffIML, a novel framework that introduces score-based generative modeling to IML. Diverging from the direct estimation of hard boundaries, DiffIML approximates the score function, the gradient of the log-likelihood, to capture the intrinsic geometric topology of mask distributions. This paradigm leverages structural priors to iteratively recover coherent masks from noise, thereby circumventing the brittleness associated with discriminative models. Under this formulation, diffusion models serve as an effective numerical solver for the learned score function.To ensure practicality, we respectively resolve the efficiency and stability bottlenecks of standard diffusion by: (1) utilizing a Lightweight Mask-Specific VAE for fast latent-space process and a decoupled architecture with a lightweight denoising UNet, (2) edge supervision and error prior to mitigate error accumulation during sampling. Extensive experiments of two distinct protocols on eight non-generative and three generative benchmarks demonstrate that DiffIML consistently outperforms state-of-the-art methods, yielding remarkable generalization improvements on diverse unseen datasets. The code will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiffIML, a score-based generative modeling framework for Image Manipulation Localization (IML). It approximates the score function (gradient of the log-likelihood) of mask distributions to iteratively recover coherent masks from noise via diffusion, rather than learning fixed decision boundaries as in discriminative approaches. Practicality is addressed via a lightweight mask-specific VAE for latent-space processing, a decoupled lightweight denoising UNet, edge supervision, and an error prior to stabilize sampling. Experiments under two protocols on eight non-generative and three generative benchmarks report consistent outperformance and improved generalization to unseen manipulation types.
Significance. If the observed gains on diverse unseen datasets are attributable to the score approximation capturing intrinsic mask topology (rather than the introduced architectural priors and supervision), the work could meaningfully advance IML by shifting from brittle discriminative boundaries to generative recovery. Public code release strengthens reproducibility. The central claim remains defensible but requires clearer isolation of the score-matching contribution to establish the paradigm shift.
major comments (2)
- [Abstract] Abstract: The claim that DiffIML 'captures the intrinsic geometric topology of mask distributions' and thereby 'circumvent[s] the brittleness associated with discriminative models' is load-bearing, yet the abstract introduces edge supervision and error prior specifically 'to mitigate error accumulation during sampling' without clarifying whether these are components of the learned score function or auxiliary stabilizers. This distinction must be resolved to confirm that generalization improvements arise from score-based recovery rather than the added priors.
- [Experiments] Experiments (as summarized in abstract): Outperformance is reported across eight non-generative and three generative benchmarks, but no quantitative error bars, ablation studies isolating the error prior, or comparisons of sampling trajectories with/without the score objective are mentioned. These omissions undermine assessment of whether the diffusion-based score approximation is the active ingredient for coherent mask recovery.
minor comments (2)
- [Abstract] Abstract: The term 'remarkable generalization improvements' is imprecise; replace with specific quantitative deltas relative to the strongest baselines.
- [Methods] Methods: Ensure the lightweight VAE latent dimension, UNet capacity, and weighting coefficients for edge supervision and error prior are explicitly listed as free parameters with sensitivity analysis.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments help clarify the core contributions of DiffIML and strengthen the experimental validation. We address each major comment below, proposing targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that DiffIML 'captures the intrinsic geometric topology of mask distributions' and thereby 'circumvent[s] the brittleness associated with discriminative models' is load-bearing, yet the abstract introduces edge supervision and error prior specifically 'to mitigate error accumulation during sampling' without clarifying whether these are components of the learned score function or auxiliary stabilizers. This distinction must be resolved to confirm that generalization improvements arise from score-based recovery rather than the added priors.
Authors: We agree that the distinction requires explicit clarification to avoid ambiguity. The approximation of the score function is the primary mechanism through which DiffIML captures the intrinsic geometric topology of mask distributions, enabling iterative recovery of coherent masks from noise and thereby addressing the overfitting issues of fixed decision boundaries in discriminative models. The edge supervision and error prior are auxiliary stabilizers introduced solely to ensure numerical stability and mitigate error accumulation in the practical sampling process; they are not components of the learned score function itself. We will revise the abstract to separate these elements clearly, stating that the generalization gains derive from the score-based generative recovery while the auxiliaries serve only to make the diffusion framework computationally viable. revision: yes
-
Referee: [Experiments] Experiments (as summarized in abstract): Outperformance is reported across eight non-generative and three generative benchmarks, but no quantitative error bars, ablation studies isolating the error prior, or comparisons of sampling trajectories with/without the score objective are mentioned. These omissions undermine assessment of whether the diffusion-based score approximation is the active ingredient for coherent mask recovery.
Authors: We acknowledge that these analyses would provide stronger evidence isolating the contribution of the score approximation. The reported results show consistent gains across the benchmarks, but the manuscript does not currently include error bars or dedicated ablations on the error prior, nor direct trajectory comparisons. To address this, we will add quantitative error bars to the main quantitative tables, include an ablation study that isolates the effect of the error prior, and provide additional figures or metrics comparing mask recovery trajectories with and without the score-matching objective. These revisions will help demonstrate that the coherent mask recovery and improved generalization stem primarily from the diffusion-based score approximation. revision: yes
Circularity Check
No circularity: derivation relies on standard score-matching and task-specific engineering without definitional reduction or self-citation chains.
full rationale
The paper's core chain—from approximating the score function of mask distributions via diffusion to iterative mask recovery—is presented as a direct application of existing score-based generative modeling to IML, with added components (lightweight VAE, decoupled UNet, edge supervision, error prior) explicitly introduced for efficiency and stability rather than derived from the score objective itself. No equations reduce the claimed generalization gains to fitted inputs by construction, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The method remains self-contained against external diffusion literature and benchmark results, with design choices serving as practical adaptations rather than tautological redefinitions of the prediction target.
Axiom & Free-Parameter Ledger
free parameters (2)
- Lightweight Mask-Specific VAE latent dimension and denoising UNet capacity
- Weighting coefficients for edge supervision and error prior
axioms (1)
- domain assumption The score function of realistic mask distributions can be approximated well enough by a neural network to guide coherent mask recovery from noise.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DiffIML approximates the score function, the gradient of the log-likelihood, to capture the intrinsic geometric topology of mask distributions... diffusion models serve as an effective numerical solver
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fan Bao, Chongxuan Li, Jun Zhu, and Bo Zhang. 2022. Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models.arXiv Towards Generalized Image Manipulation Localization via Score-based Model ICMR ’26, June 16–19, 2026, Amsterdam, Netherlands preprint arXiv:2201.06503(2022)
-
[2]
Xinru Chen, Chengbo Dong, Jiaqi Ji, Juan Cao, and Xirong Li. 2021. Image manipulation detection by multi-view multi-scale supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14185–14193
work page 2021
-
[3]
Chengbo Dong, Xinru Chen, Ruohan Hu, Juan Cao, and Xirong Li. 2023. MVSS- Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detec- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 3 (2023), 3539–3553
work page 2023
-
[4]
Jing Dong, Wei Wang, and Tieniu Tan. 2013. CASIA Image Tampering Detection Evaluation Database. In2013 IEEE China summit and international conference on signal and information processing. IEEE, 422–426
work page 2013
-
[5]
Bo Du, Xuekang Zhu, Xiaochen Ma, Chenfan Qu, Kaiwen Feng, Zhe Yang, Chi- Man Pun, Jian Liu, and Ji-Zhe Zhou. 2025. ForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization. InAdvances in Neural Information Processing Systems
work page 2025
-
[6]
Jessica Fridrich and Jan Kodovsky. 2012. Rich models for steganalysis of digital images.IEEE Transactions on information Forensics and Security7, 3 (2012), 868–882
work page 2012
-
[7]
Haiying Guan, Mark Kozak, Eric Robertson, Yooyoung Lee, Amy N Yates, Andrew Delgado, Daniel Zhou, Timothee Kheyrkhah, Jeff Smith, and Jonathan Fiscus
-
[8]
In2019 IEEE Winter Applications of Computer Vision Workshops (W ACVW)
MFC datasets: Large-scale benchmark datasets for media forensic chal- lenge evaluation. In2019 IEEE Winter Applications of Computer Vision Workshops (W ACVW). IEEE, 63–72
-
[9]
Fabrizio Guillaro, Davide Cozzolino, Avneesh Sud, Nicholas Dufour, and Luisa Verdoliva. 2023. TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20606–20615
work page 2023
-
[10]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
work page 2016
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
work page 2020
-
[12]
J Hsu and SF Chang. 2006. Columbia uncompressed image splicing detection evaluation dataset.Columbia DVMM Research Lab6 (2006)
work page 2006
-
[13]
Xuefeng Hu, Zhihan Zhang, Zhenye Jiang, Syomantak Chaudhuri, Zhenheng Yang, and Ram Nevatia. 2020. SPAN: Spatial pyramid attention network for image manipulation localization. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer, 312–328
work page 2020
-
[14]
Shan Jia, Mingzhen Huang, Zhou Zhou, Yan Ju, Jialing Cai, and Siwei Lyu. 2023. Autosplice: A text-prompt manipulated image dataset for media forensics. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 893–903
work page 2023
-
[15]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
Vladimir V Kniaz, Vladimir Knyaz, and Fabio Remondino. 2019. The point where reality meets fantasy: Mixed adversarial generators for image splice detection. In Advances in Neural Information Processing Systems, Vol. 32. 215–226
work page 2019
- [17]
-
[18]
Myung-Joon Kwon, Seung-Hun Nam, In-Jae Yu, Heung-Kyu Lee, and Changick Kim. 2022. Learning JPEG compression artifacts for image manipulation detection and localization.International Journal of Computer Vision130, 8 (2022), 1875– 1895
work page 2022
-
[19]
Ilya Loshchilov and Frank Hutter. 2016. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [21]
-
[22]
Xiaochen Ma, Xuekang Zhu, Lei Su, Bo Du, Zhuohang Jiang, Bingkui Tong, Zeyu Lei, Xinyu Yang, Chi-Man Pun, Jiancheng Lv, et al . 2025. Imdl-benco: A comprehensive benchmark and codebase for image manipulation detection & localization.Advances in Neural Information Processing Systems37 (2025), 134591–134613
work page 2025
-
[23]
Adam Novozamsky, Babak Mahdian, and Stanislav Saic. 2020. IMD2020: A Large- Scale Annotated Dataset Tailored for Detecting Manipulated Images. In2020 IEEE Winter Applications of Computer Vision Workshops (W ACVW). IEEE, 71–80
work page 2020
-
[24]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
work page 2019
-
[25]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. InInternational conference on machine learning. Pmlr, 8821–8831
work page 2021
-
[26]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695
work page 2022
-
[27]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolu- tional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 234–241
work page 2015
-
[28]
Ronald Salloum, Yuzhuo Ren, and C-C Jay Kuo. 2018. Image splicing localiza- tion using a multi-task fully convolutional network (MFCN).Journal of Visual Communication and Image Representation51 (2018), 201–209
work page 2018
-
[29]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems32 (2019)
work page 2019
-
[31]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
Junke Wang, Zuxuan Wu, Jingjing Chen, Xintong Han, Abhinav Shrivastava, Ser-Nam Lim, and Yu-Gang Jiang. 2022. Objectformer for image manipulation detection and localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2364–2373
work page 2022
-
[33]
Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, Yongpeng Zhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, Dayong Ding, et al . 2021. Learn to segment retinal lesions and beyond. In2020 25th International conference on pattern recognition (ICPR). IEEE, 7403–7410
work page 2021
-
[34]
Bihan Wen, Ye Zhu, Ramanathan Subramanian, Tian-Tsong Ng, Xuanjing Shen, and Stefan Winkler. 2016. COVERAGE—A novel database for copy-move forgery detection. In2016 IEEE international conference on image processing (ICIP). IEEE, 161–165
work page 2016
-
[35]
Yue Wu, Wael AbdAlmageed, and Premkumar Natarajan. 2019. Mantra-Net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9543–9552
work page 2019
-
[36]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. 2021. SegFormer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems34 (2021), 12077–12090
work page 2021
-
[37]
Jizhe Zhou, Xiaochen Ma, Xia Du, Ahmed Y Alhammadi, and Wentao Feng
-
[38]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Pre-training-free Image Manipulation Localization through Non-Mutually Exclusive Contrastive Learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22346–22356
-
[39]
Peng Zhou, Xintong Han, Vlad I Morariu, and Larry S Davis. 2018. Learning rich features for image manipulation detection. InProceedings of the IEEE conference on computer vision and pattern recognition. 1053–1061
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.