Semantic Code Clone Detection: Are We There Yet?
Pith reviewed 2026-06-25 20:47 UTC · model grok-4.3
The pith
Semantic code clone detectors rely on lexical shortcuts and degrade sharply on distribution-shifted but equivalent code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
State-of-the-art semantic code clone detectors exhibit substantial performance degradation on distribution-shifted Type-4 clone instances generated by eight transformation operators from Type-2 and Type-3 variations, even though the instances remain semantically equivalent; further analysis shows the detectors depend on shortcut learning from lexical and structural cues instead of robust semantic understanding.
What carries the argument
The clone operator framework of eight transformation operators derived from Type-2 and Type-3 clone variations, which produces distribution-shifted yet semantically equivalent Type-4 instances for testing generalizability.
If this is right
- Benchmark scores alone cannot certify that a detector has learned semantic equivalence.
- Detectors must be retested on transformed data to expose reliance on surface cues.
- Real-world deployment of current detectors risks missing clones that differ in naming or structure.
- Research should prioritize methods that remain stable under lexical and structural variation.
- Existing evaluation practices may systematically overestimate practical effectiveness.
Where Pith is reading between the lines
- Similar shortcut problems likely appear in other code-analysis tasks such as defect prediction or refactoring recommendation.
- New benchmarks could be built by systematically applying these operators to multiple source corpora.
- Adversarial or distribution-shift testing may become a standard requirement for claims of semantic capability in program analysis.
Load-bearing premise
The eight transformation operators produce distribution-shifted instances that remain semantically equivalent to the originals and representative of real-world code variations.
What would settle it
Apply the same eight operators to a fresh, large code corpus not used in the original benchmarks and measure whether the performance drop disappears or persists across multiple detectors.
Figures


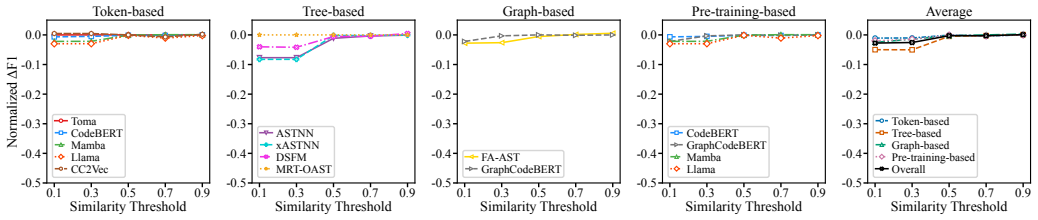
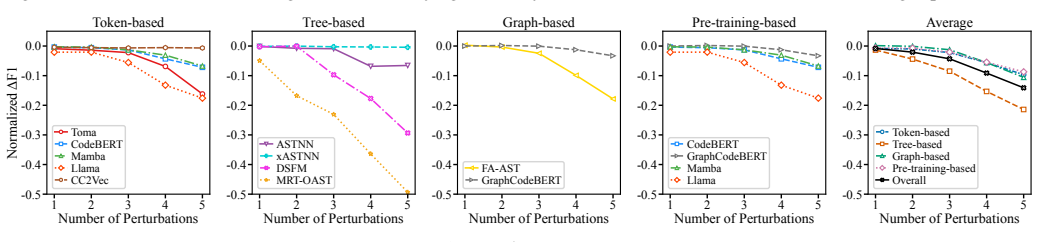


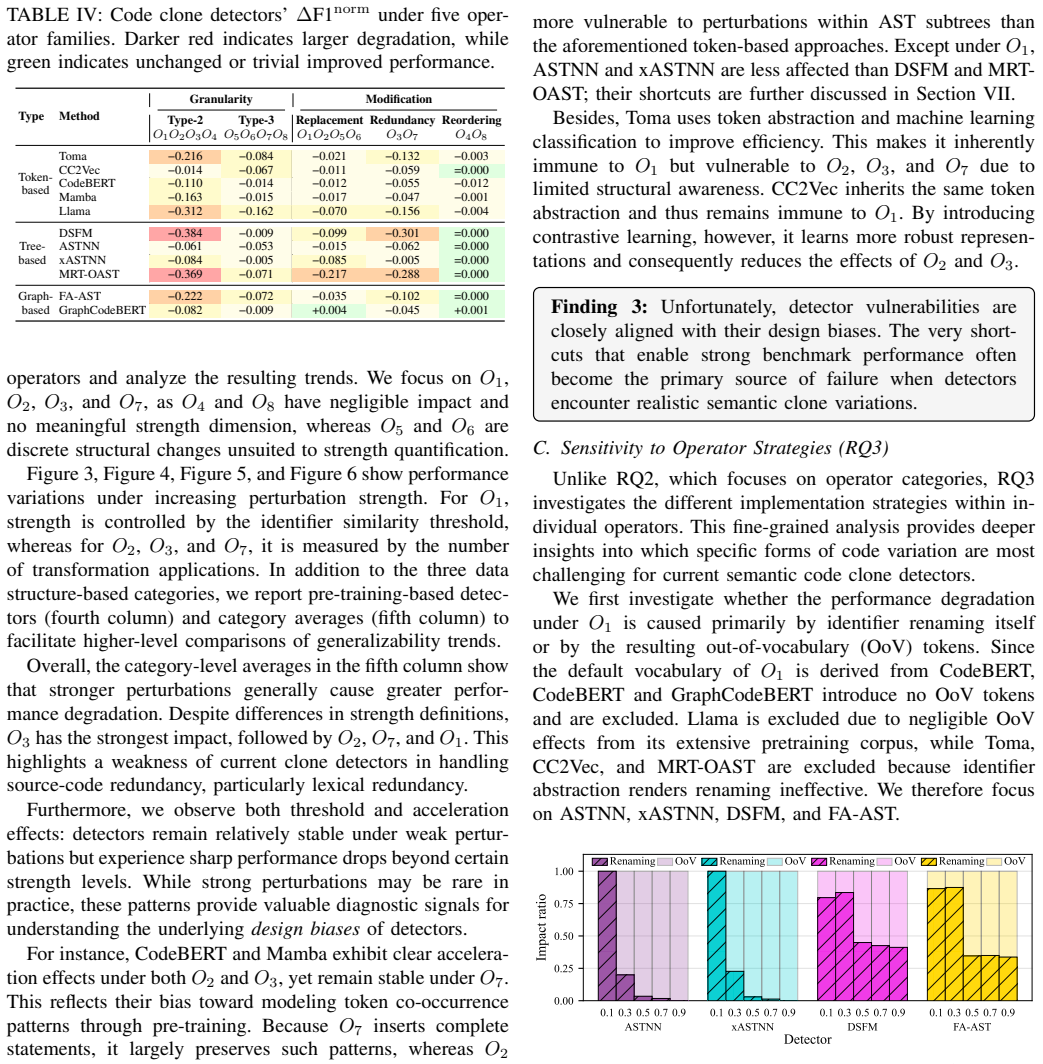

read the original abstract
Code clone detection has been extensively studied for decades, and recent approaches have begun reporting remarkably high performance for semantic (Type-4) clones on benchmark datasets. However, it remains unclear whether these results reflect a genuine ability to capture semantic equivalence between programs, or simply an ability to exploit dataset-specific patterns. In this paper, we present the first systematic empirical study investigating the generalizability of state-of-the-art (SOTA) semantic code clone detectors beyond benchmark evaluation settings. Inspired by the inherent inclusion relationship among clone types, we propose a clone operator framework consisting of eight transformation operators derived from Type-2 and Type-3 clone variations. Using these operators, we construct distribution-shifted yet semantically equivalent Type-4 clone instances and evaluate 11 representative detectors spanning token-based, tree-based, and graph-based paradigms on the real-world BigCloneBench dataset. Our results reveal substantial performance degradation across all evaluated approaches, despite their strong benchmark performance. Further analyses show that existing detectors heavily rely on shortcut learning based on lexical and structural cues rather than robust semantic understanding. Our findings suggest that current SOTA semantic code clone detectors exhibit limited generalizability in real-world scenarios, highlighting important avenues for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that despite strong reported performance on benchmarks, 11 state-of-the-art semantic (Type-4) code clone detectors exhibit substantial degradation when tested on distribution-shifted instances generated by a proposed clone operator framework of eight transformations derived from Type-2 and Type-3 variations; applied to BigCloneBench, the results indicate reliance on lexical/structural shortcuts rather than robust semantic understanding, implying limited real-world generalizability.
Significance. If the constructed instances are shown to be valid semantically equivalent Type-4 shifts that are representative of real-world variations, the systematic evaluation across token-, tree-, and graph-based detectors would be a useful contribution highlighting the gap between benchmark scores and generalization; the empirical scope on multiple paradigms is a strength that could inform future detector design and evaluation practices.
major comments (3)
- [Clone operator framework] Clone operator framework (described in the methods): the eight operators are derived from Type-2/3 syntactic variations (identifier renaming, formatting, control-flow reordering, statement permutation); this raises a correctness risk for the central claim because the generated pairs may remain closer to Type-2/3 than to genuine Type-4 algorithmic differences. A concrete test would be to report syntactic similarity metrics (e.g., token overlap or AST edit distance) of the transformed pairs versus known Type-4 pairs in BigCloneBench.
- [Experiments and results] Evaluation results (reported in the experiments section): substantial performance degradation is claimed across all 11 detectors, but the manuscript provides no details on statistical significance testing of the observed drops or confidence intervals, which is load-bearing for interpreting the degradation as evidence against semantic understanding.
- [Shortcut learning analyses] Shortcut learning analyses (post-hoc section): the claim that detectors rely on lexical and structural cues rather than semantics requires explicit description of the analysis methods (e.g., feature ablation or attention visualization) to confirm they support the conclusion; without this, the interpretation remains plausible but unverified.
minor comments (2)
- [Abstract] Ensure the abstract states the number of detectors and the dataset explicitly for clarity.
- [Results tables] Verify that all tables reporting performance metrics include baseline comparisons and exact definitions of the metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the three major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Clone operator framework] Clone operator framework (described in the methods): the eight operators are derived from Type-2/3 syntactic variations (identifier renaming, formatting, control-flow reordering, statement permutation); this raises a correctness risk for the central claim because the generated pairs may remain closer to Type-2/3 than to genuine Type-4 algorithmic differences. A concrete test would be to report syntactic similarity metrics (e.g., token overlap or AST edit distance) of the transformed pairs versus known Type-4 pairs in BigCloneBench.
Authors: We agree that explicitly quantifying the syntactic distance introduced by the operators would help substantiate that the shifts qualify as distribution shifts for Type-4 clones. The operators are intentionally drawn from Type-2/3 variations precisely because these represent common real-world syntactic changes that preserve semantics; applying them to BigCloneBench Type-4 pairs creates the desired distribution shift while keeping semantic equivalence. In the revision we will add a table reporting token overlap, normalized AST edit distance, and other syntactic similarity metrics comparing our transformed pairs against both the original BigCloneBench Type-4 pairs and a sample of known Type-2/3 pairs, thereby providing the requested concrete test. revision: yes
-
Referee: [Experiments and results] Evaluation results (reported in the experiments section): substantial performance degradation is claimed across all 11 detectors, but the manuscript provides no details on statistical significance testing of the observed drops or confidence intervals, which is load-bearing for interpreting the degradation as evidence against semantic understanding.
Authors: We concur that statistical rigor is necessary to support claims of substantial degradation. The current manuscript reports raw performance drops but omits formal testing. In the revised version we will include paired statistical tests (Wilcoxon signed-rank or McNemar as appropriate) together with 95% confidence intervals computed via bootstrap resampling for each detector and each transformation, allowing readers to assess the reliability of the observed drops. revision: yes
-
Referee: [Shortcut learning analyses] Shortcut learning analyses (post-hoc section): the claim that detectors rely on lexical and structural cues rather than semantics requires explicit description of the analysis methods (e.g., feature ablation or attention visualization) to confirm they support the conclusion; without this, the interpretation remains plausible but unverified.
Authors: The post-hoc section presents correlation analyses between detector predictions and surface-level features (token n-grams, AST node frequencies, control-flow patterns) as well as ablation experiments that mask lexical or structural cues. To address the request for explicit method description, we will expand this section with a dedicated subsection detailing the feature sets used, the ablation procedure, the correlation metrics, and any visualization techniques employed, thereby making the evidence for shortcut reliance fully reproducible and verifiable. revision: yes
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper performs an empirical evaluation by constructing test instances via eight transformation operators and measuring detector performance degradation on BigCloneBench. No equations, fitted parameters, derivations, or predictions are present that reduce to inputs by construction. Central claims rest on direct observations of performance numbers rather than any self-referential or fitted logic. The operators are presented as a methodological choice derived from clone-type relationships, but this is an explicit design decision, not a circular reduction. Self-citations, if any, are not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clone types exhibit an inclusion relationship that allows Type-4 instances to be derived from Type-2 and Type-3 variations via eight transformation operators.
invented entities (1)
-
Clone operator framework with eight transformation operators
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Code clone detection—a systematic review,
G. Shobha, A. Rana, V . Kansal, and S. Tanwar, “Code clone detection—a systematic review,”Emerging Technologies in Data Mining and Infor- mation Security: Proceedings of IEMIS 2020, Volume 2, pp. 645–655, 2021
2020
-
[2]
Survey of research on software clones,
R. Koschke, “Survey of research on software clones,” 2007
2007
-
[3]
Do code clones matter?
E. Juergens, F. Deissenboeck, B. Hummel, and S. Wagner, “Do code clones matter?” in2009 IEEE 31st International Conference on Software Engineering. IEEE, 2009, pp. 485–495
2009
-
[4]
Cp-miner: Finding copy-paste and related bugs in large-scale software code,
Z. Li, S. Lu, S. Myagmar, and Y . Zhou, “Cp-miner: Finding copy-paste and related bugs in large-scale software code,”IEEE Transactions on software Engineering, vol. 32, no. 3, pp. 176–192, 2006
2006
-
[5]
Dsfm: Enhancing functional code clone detection with deep subtree interactions,
Z. Xu, S. Qiang, D. Song, M. Zhou, H. Wan, X. Zhao, P. Luo, and H. Zhang, “Dsfm: Enhancing functional code clone detection with deep subtree interactions,” inProceedings of the IEEE/ACM 46th Interna- tional Conference on Software Engineering, 2024, pp. 1–12
2024
-
[6]
Machine learning is all you need: A simple token-based approach for effective code clone detection,
S. Feng, W. Suo, Y . Wu, D. Zou, Y . Liu, and H. Jin, “Machine learning is all you need: A simple token-based approach for effective code clone detection,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[7]
Cc2vec: Combining typed tokens with contrastive learning for effective code clone detection,
S. Dou, Y . Wu, H. Jia, Y . Zhou, Y . Liu, and Y . Liu, “Cc2vec: Combining typed tokens with contrastive learning for effective code clone detection,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 1564–1584, 2024
2024
-
[8]
Codebert: A pre-trained model for programming and natural languages,
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jianget al., “Codebert: A pre-trained model for programming and natural languages,” inFindings of the association for computational linguistics: EMNLP 2020, 2020, pp. 1536–1547
2020
-
[9]
Can mamba be better? an experimental evaluation of mamba in code intelligence,
S. Liu, J. Keung, Z. Yang, Z. Mao, and Y . Sun, “Can mamba be better? an experimental evaluation of mamba in code intelligence,” in 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 1856–1868
2025
-
[10]
Llama: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[11]
A novel neural source code representation based on abstract syntax tree,
J. Zhang, X. Wang, H. Zhang, H. Sun, K. Wang, and X. Liu, “A novel neural source code representation based on abstract syntax tree,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 2019, pp. 783–794
2019
-
[12]
xastnn: Improved code representations for industrial practice,
Z. Xu, M. Zhou, X. Zhao, Y . Chen, X. Cheng, and H. Zhang, “xastnn: Improved code representations for industrial practice,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2023, pp. 1727–1738
2023
-
[13]
A multiple representation transformer with optimized abstract syntax tree for efficient code clone detection,
T. Yu, L. Yuan, L. Lin, and H. He, “A multiple representation transformer with optimized abstract syntax tree for efficient code clone detection,” in2025 IEEE/ACM 47th International Conference on Software Engi- neering (ICSE). IEEE, 2025, pp. 281–293
2025
-
[14]
Detecting code clones with graph neural network and flow-augmented abstract syntax tree,
W. Wang, G. Li, B. Ma, X. Xia, and Z. Jin, “Detecting code clones with graph neural network and flow-augmented abstract syntax tree,” in2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2020, pp. 261–271
2020
-
[15]
Graphcodebert: Pre-training code repre- sentations with data flow,
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fuet al., “Graphcodebert: Pre-training code repre- sentations with data flow,”arXiv preprint arXiv:2009.08366, 2020
Pith/arXiv arXiv 2009
-
[16]
Oreo: Detection of clones in the twilight zone,
V . Saini, F. Farmahinifarahani, Y . Lu, P. Baldi, and C. V . Lopes, “Oreo: Detection of clones in the twilight zone,” inProceedings of the 2018 26th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering, 2018, pp. 354–365
2018
-
[17]
Sourcerercc: Scaling code clone detection to big-code,
H. Sajnani, V . Saini, J. Svajlenko, C. K. Roy, and C. V . Lopes, “Sourcerercc: Scaling code clone detection to big-code,” inProceedings of the 38th international conference on software engineering, 2016, pp. 1157–1168
2016
-
[18]
Ccaligner: a token based large-gap clone detector,
P. Wang, J. Svajlenko, Y . Wu, Y . Xu, and C. K. Roy, “Ccaligner: a token based large-gap clone detector,” inProceedings of the 40th International Conference on Software Engineering, 2018, pp. 1066–1077
2018
-
[19]
Ccgraph: a pdg-based code clone detector with approximate graph matching,
Y . Zou, B. Ban, Y . Xue, and Y . Xu, “Ccgraph: a pdg-based code clone detector with approximate graph matching,” inProceedings of the 35th IEEE/ACM international conference on automated software engineering, 2020, pp. 931–942
2020
-
[20]
Towards a big data curated benchmark of inter-project code clones,
J. Svajlenko, J. F. Islam, I. Keivanloo, C. K. Roy, and M. M. Mia, “Towards a big data curated benchmark of inter-project code clones,” in2014 IEEE international conference on software maintenance and evolution. IEEE, 2014, pp. 476–480
2014
-
[21]
Comparison and evaluation of clone detection techniques with different code representa- tions,
Y . Wang, Y . Ye, Y . Wu, W. Zhang, Y . Xue, and Y . Liu, “Comparison and evaluation of clone detection techniques with different code representa- tions,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 332–344
2023
-
[22]
Shortcut learning in deep neural networks,
R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann, “Shortcut learning in deep neural networks,”Nature Machine Intelligence, vol. 2, no. 11, pp. 665–673, 2020
2020
-
[23]
Ccfinder: A multilinguistic token-based code clone detection system for large scale source code,
T. Kamiya, S. Kusumoto, and K. Inoue, “Ccfinder: A multilinguistic token-based code clone detection system for large scale source code,” IEEE transactions on software engineering, vol. 28, no. 7, pp. 654–670, 2002
2002
-
[24]
Deckard: Scalable and accurate tree-based detection of code clones,
L. Jiang, G. Misherghi, Z. Su, and S. Glondu, “Deckard: Scalable and accurate tree-based detection of code clones,” in29th International Conference on Software Engineering (ICSE’07). IEEE, 2007, pp. 96– 105
2007
-
[25]
Deep learning code fragments for code clone detection,
M. White, M. Tufano, C. Vendome, and D. Poshyvanyk, “Deep learning code fragments for code clone detection,” inProceedings of the 31st IEEE/ACM international conference on automated software engineering, 2016, pp. 87–98
2016
-
[26]
Supervised deep features for software functional clone detection by exploiting lexical and syntactical information in source code
H. Wei and M. Li, “Supervised deep features for software functional clone detection by exploiting lexical and syntactical information in source code.” inIjcai, 2017, pp. 3034–3040
2017
-
[27]
Deepsim: deep learning code functional simi- larity,
G. Zhao and J. Huang, “Deepsim: deep learning code functional simi- larity,” inProceedings of the 2018 26th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering, 2018, pp. 141–151
2018
-
[28]
Neural detection of semantic code clones via tree-based convolution,
H. Yu, W. Lam, L. Chen, G. Li, T. Xie, and Q. Wang, “Neural detection of semantic code clones via tree-based convolution,” in2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC). IEEE, 2019, pp. 70–80
2019
-
[29]
Detecting semantic clones of unseen functionality,
K. Kitsios, F. Sovrano, E. T. Barr, and A. Bacchelli, “Detecting semantic clones of unseen functionality,” in2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 1312–1324
2025
-
[30]
An empirical study of llm-based code clone detection,
W. Zhu, N. Yoshida, E. Choi, Y . Matsubara, and H. Takada, “An empirical study of llm-based code clone detection,”arXiv preprint arXiv:2511.01176, 2025
arXiv 2025
-
[31]
Towards understanding the capability of large language models on code clone detection: A survey,
S. Dou, J. Shan, H. Jia, W. Deng, Z. Xi, W. He, Y . Wu, T. Gui, Y . Liu, and X. Huang, “Towards understanding the capability of large language models on code clone detection: A survey,”arXiv preprint arXiv:2308.01191, 2023
arXiv 2023
-
[32]
An empirical study of code clones from commercial ai code generators,
W. Wu, H. Hu, Z. Fan, Y . Qiao, Y . Huang, Y . Li, Z. Zheng, and M. Lyu, “An empirical study of code clones from commercial ai code generators,” Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 2874–2896, 2025
2025
-
[33]
The struggles of llms in cross-lingual code clone detection,
M. B. Moumoula, A. K. Kabor ´e, J. Klein, and T. F. Bissyand ´e, “The struggles of llms in cross-lingual code clone detection,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 1023–1045, 2025
2025
-
[34]
Suggesting accurate method and class names,
M. Allamanis, E. T. Barr, C. Bird, and C. Sutton, “Suggesting accurate method and class names,” inProceedings of the 2015 10th joint meeting on foundations of software engineering, 2015, pp. 38–49
2015
-
[35]
Tree-sitter: An incremental parsing system for programming tools,
M. B. Azzopardi, “Tree-sitter: An incremental parsing system for programming tools,” 2024. [Online]. Available: https://tree-sitter.github. io/tree-sitter/
2024
-
[36]
javalang: Pure python java parser and ast,
C2nes, “javalang: Pure python java parser and ast,” https://github.com/ c2nes/javalang, 2024, accessed: 2026-05-29. 11
2024
-
[37]
Wordnet: a lexical database for english,
G. A. Miller, “Wordnet: a lexical database for english,”Communications of the ACM, vol. 38, no. 11, pp. 39–41, 1995
1995
-
[38]
Whitening sentence representations for better semantics and faster retrieval,
J. Su, J. Cao, W. Liu, and Y . Ou, “Whitening sentence representations for better semantics and faster retrieval,”arXiv preprint arXiv:2103.15316, 2021
arXiv 2021
-
[39]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[40]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[41]
Google code jam,
“Google code jam,” https://code.google.com/codejam/contests.html, 2016, Note: Google Code Jam was officially discontinued in 2023
2016
-
[42]
Convolutional neural networks over tree structures for programming language processing,
L. Mou, G. Li, L. Zhang, T. Wang, and Z. Jin, “Convolutional neural networks over tree structures for programming language processing,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2016, pp. 1287–1293
2016
-
[43]
Prism: Decomposing program semantics for code clone detection through compilation,
H. Li, S. Wang, W. Quan, X. Gong, H. Su, and J. Zhang, “Prism: Decomposing program semantics for code clone detection through compilation,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[44]
Scdetector: Software functional clone detection based on semantic tokens analysis,
Y . Wu, D. Zou, S. Dou, S. Yang, W. Yang, F. Cheng, H. Liang, and H. Jin, “Scdetector: Software functional clone detection based on semantic tokens analysis,” inProceedings of the 35th IEEE/ACM international conference on automated software engineering, 2020, pp. 821–833
2020
-
[45]
Modeling functional similarity in source code with graph-based siamese networks,
N. Mehrotra, N. Agarwal, P. Gupta, S. Anand, D. Lo, and R. Purandare, “Modeling functional similarity in source code with graph-based siamese networks,”IEEE Transactions on Software Engineering, vol. 48, no. 10, pp. 3771–3789, 2021
2021
-
[46]
Java code clone detec- tion by exploiting semantic and syntax information from intermediate code-based graph,
D. Yuan, S. Fang, T. Zhang, Z. Xu, and X. Luo, “Java code clone detec- tion by exploiting semantic and syntax information from intermediate code-based graph,”IEEE Transactions on Reliability, vol. 72, no. 2, pp. 511–526, 2022. 12
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.