STRIDE: Training Data Attribution via Sparse Recovery from Subset Perturbations
Pith reviewed 2026-06-28 07:37 UTC · model grok-4.3
The pith
STRIDE attributes predictions of large language models back to individual training examples by learning steering operators in activation space and solving a sparse recovery problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
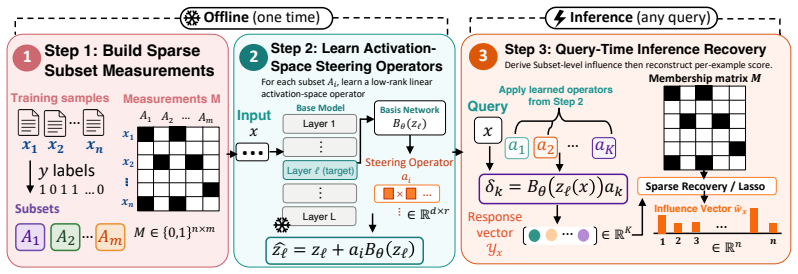
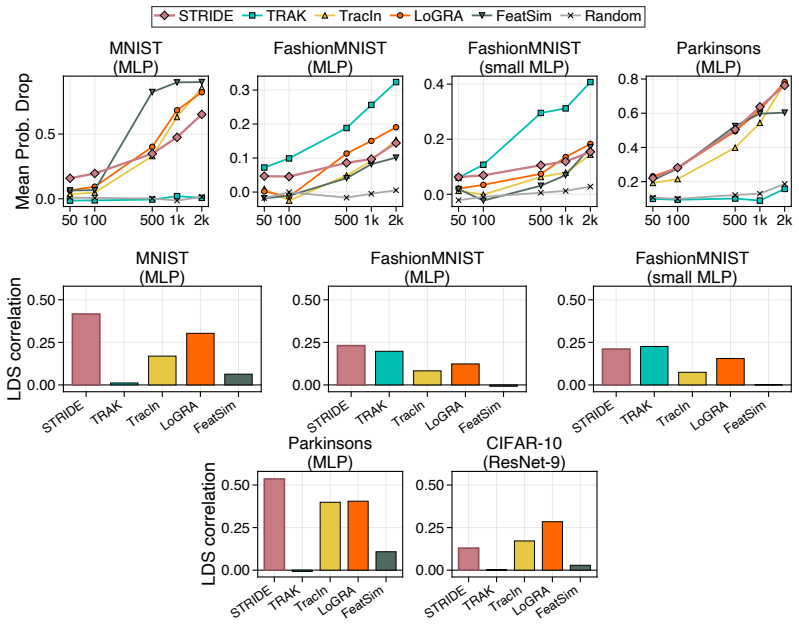
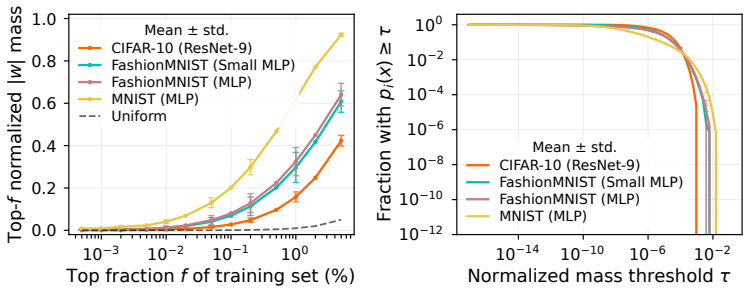
STRIDE formulates training data attribution as a sparse recovery problem in activation space. It learns steering operators that capture the behavioral shift from training on subsets of data. Measuring how these operators affect test predictions allows recovery of individual training example influences through sparse linear decomposition. This yields state-of-the-art performance on LLM pre-training attribution at 13 times the speed of prior methods.
What carries the argument
The steering operators, which are lightweight functions that replicate the effect of training on a data subset when applied to model activations, enabling the sparse decomposition to isolate individual contributions.
If this is right
- Practical attribution becomes feasible for large-scale LLM pre-training without repeated retraining.
- Downstream tasks such as selecting high-influence data or detecting contamination can be performed efficiently.
- Qualitative analysis of which training examples drive specific model behaviors becomes scalable.
- Gradient-free attribution reduces computational cost by avoiding tracking across billions of parameters.
Where Pith is reading between the lines
- If the method generalizes, it could reduce reliance on gradient-based approximations in other model analysis tasks.
- Applying similar sparse recovery in activation space might help in continual learning scenarios where data influences need tracking over time.
- Validation on smaller models with exact leave-one-out retraining could confirm the accuracy of the steering operator approximation.
Load-bearing premise
The behavioral changes induced by training on data subsets are well-approximated by simple steering operators applied in the model's activation space.
What would settle it
A direct comparison showing that the influences recovered by STRIDE do not correlate with the actual changes in model output when retraining on the same subsets for a model small enough to retrain repeatedly.
Figures




read the original abstract
Training Data Attribution (TDA) seeks to trace a model's predictions back to its training data. The gold standard for TDA relies on causal interventions, observing how a model changes when data is added or removed, but repeated retraining is computationally challenging for Large Language Models (LLMs). Consequently, most approaches approximate this effect in the parameter space using gradients. However, tracking gradients across billions of parameters is not only prohibitively expensive but relies on local approximations. In this work, we propose a shift: rather than estimating parameter changes, we model the functional effect of training data in the activation space. We introduce STRIDE (Steering-based Training Data Influence Decomposition), a framework that formulates TDA as a sparse recovery problem in the spirit of compressive sensing. STRIDE learns lightweight "steering operators" that mimic the behavioral shift caused by training on data subsets. By measuring how these operators perturb test predictions, we recover individual training example influences via sparse linear decomposition. STRIDE achieves state-of-the-art for LLM pre-training attribution while being an order of magnitude ($13\times$) faster than previous art. We further validate its practical utility through downstream applications including data selection, data contamination, and qualitative analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STRIDE (Steering-based Training Data Influence Decomposition) for training data attribution (TDA) in LLMs. Instead of parameter-space gradient approximations or repeated retraining, it learns lightweight steering operators in activation space to model behavioral shifts induced by training on data subsets, then recovers per-example influences via sparse linear decomposition in the style of compressive sensing. The abstract claims state-of-the-art attribution performance for LLM pre-training together with a 13× speedup over prior art, plus downstream uses in data selection, contamination detection, and qualitative analysis.
Significance. If the core approximation holds and the empirical claims are substantiated, STRIDE would offer a practical, scalable route to causal-style TDA for models too large for leave-one-out retraining or full gradient tracking, potentially enabling new data-centric analyses at pre-training scale.
major comments (2)
- [Abstract] Abstract: the central claims of SOTA performance and 13× speedup are stated without any reported metrics, baselines, datasets, or experimental protocol. Because these performance numbers are the primary evidence offered for the method’s utility, their absence prevents assessment of whether the sparse-recovery formulation actually delivers the advertised attribution quality or efficiency.
- [Abstract (method description)] The method’s validity rests on the unstated assumption that the effect of training on a data subset is well-approximated by a lightweight linear steering operator acting in a chosen activation subspace. No analysis or ablation is referenced that quantifies how much variance in downstream behavior remains unexplained by this low-rank operator; if higher-order or distributed effects dominate, the recovered sparse coefficients will not correspond to true causal influences even if the compressive-sensing solver converges.
minor comments (1)
- [Abstract] The abstract introduces the term “steering operators” without a concise mathematical definition or reference to the precise layer and dimension at which they are learned.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address each major comment below and indicate the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of SOTA performance and 13× speedup are stated without any reported metrics, baselines, datasets, or experimental protocol. Because these performance numbers are the primary evidence offered for the method’s utility, their absence prevents assessment of whether the sparse-recovery formulation actually delivers the advertised attribution quality or efficiency.
Authors: We agree that the abstract would benefit from including key quantitative results to support the claims. Although space is limited, we will revise the abstract to briefly report the main metrics (e.g., attribution accuracy on specific benchmarks), the baselines compared against, and the datasets used, while keeping the full experimental protocol in the body of the paper. This will allow readers to better assess the claims at a glance. revision: yes
-
Referee: [Abstract (method description)] The method’s validity rests on the unstated assumption that the effect of training on a data subset is well-approximated by a lightweight linear steering operator acting in a chosen activation subspace. No analysis or ablation is referenced that quantifies how much variance in downstream behavior remains unexplained by this low-rank operator; if higher-order or distributed effects dominate, the recovered sparse coefficients will not correspond to true causal influences even if the compressive-sensing solver converges.
Authors: The linear steering operator is a core modeling choice, motivated by the need for efficiency in high-dimensional activation spaces and supported by the success of the sparse recovery. We provide empirical evidence through the overall attribution performance matching or exceeding prior methods. To directly address the concern about unexplained variance, we will add an ablation study in the revised manuscript that measures the approximation error of the steering operators on validation sets, quantifying the residual behavioral shifts not captured by the linear model. This will help validate the assumption or highlight its limitations. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents STRIDE as an algorithmic framework that learns steering operators from subset perturbations and applies sparse recovery for TDA. No equations or steps in the provided abstract reduce a claimed prediction or result to a fitted quantity defined by the method itself, nor do they rely on self-citation chains or imported uniqueness theorems that bear the central load. The approach is self-contained as a proposed method using standard compressive sensing ideas applied to activation-space perturbations, without any self-definitional loops or renaming of known results as novel derivations.
Axiom & Free-Parameter Ledger
invented entities (1)
-
steering operators
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020
2020
-
[2]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
2022
-
[3]
Datamodels: Understanding predictions with data and data with predictions
Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Aleksander Madry. Datamodels: Understanding predictions with data and data with predictions. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, edi- tors,Proceedings of the 39th International Conference on Machine Learning, volume 162 of Procee...
2022
-
[4]
Understanding black-box predictions via influence functions, 2020
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions, 2020
2020
-
[5]
Does learning require memorization? a short tale about a long tail, 2021
Vitaly Feldman. Does learning require memorization? a short tale about a long tail, 2021
2021
-
[6]
Representer point selection for explaining deep neural networks.Advances in neural information processing systems, 31, 2018
Chih-Kuan Yeh, Joon Kim, Ian En-Hsu Yen, and Pradeep K Ravikumar. Representer point selection for explaining deep neural networks.Advances in neural information processing systems, 31, 2018
2018
-
[7]
The fineweb datasets: Decanting the web for the finest text data at scale, 2024
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024
2024
-
[8]
Frank R. Hampel. The influence curve and its role in robust estimation.Journal of the American Statistical Association, 69(346):383–393, 1974
1974
-
[9]
Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, Evan Hubinger, Kamil ˙e Lukoši¯ut˙e, Karina Nguyen, Nicholas Joseph, Sam McCandlish, Jared Kaplan, and Samuel R. Bowman. Studying large language model generalization with influence functions, 2023
2023
-
[10]
What is your data worth to gpt? llm-scale data valuation with influence functions, 2024
Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, Jeff Schneider, Eduard Hovy, Roger Grosse, and Eric Xing. What is your data worth to gpt? llm-scale data valuation with influence functions, 2024
2024
-
[11]
Influence functions in deep learning are fragile
Samyadeep Basu, Phil Pope, and Soheil Feizi. Influence functions in deep learning are fragile. InInternational Conference on Learning Representations, 2021
2021
-
[12]
Theoretical and prac- tical perspectives on what influence functions do
Andrea Schioppa, Katja Filippova, Ivan Titov, and Polina Zablotskaia. Theoretical and prac- tical perspectives on what influence functions do. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[13]
Evaluation of similarity-based explanations
Kazuaki Hanawa, Sho Yokoi, Satoshi Hara, and Kentaro Inui. Evaluation of similarity-based explanations. InInternational Conference on Learning Representations, 2021
2021
-
[14]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric, 2018
2018
-
[15]
Enhancing training data attribution with representational optimization, 2025
Weiwei Sun, Haokun Liu, Nikhil Kandpal, Colin Raffel, and Yiming Yang. Enhancing training data attribution with representational optimization, 2025
2025
-
[16]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 11
Pith/arXiv arXiv 2023
-
[17]
Activation addition: Steering language models without optimization
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. 2024
2024
-
[18]
Compressive sensing [lecture notes].IEEE signal processing magazine, 24(4):118–121, 2007
Richard G Baraniuk. Compressive sensing [lecture notes].IEEE signal processing magazine, 24(4):118–121, 2007
2007
-
[19]
Datainf: Efficiently estimating data influence in loRA-tuned LLMs and diffusion models
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. Datainf: Efficiently estimating data influence in loRA-tuned LLMs and diffusion models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[20]
Scaling up influence functions, 2021
Andrea Schioppa, Polina Zablotskaia, David Vilar, and Artem Sokolov. Scaling up influence functions, 2021
2021
-
[21]
Estimating training data influence by tracing gradient descent, 2020
Garima Pruthi, Frederick Liu, Mukund Sundararajan, and Satyen Kale. Estimating training data influence by tracing gradient descent, 2020
2020
-
[22]
First is better than last for language data influence
Chih-Kuan Yeh, Ankur Taly, Mukund Sundararajan, Frederick Liu, and Pradeep Ravikumar. First is better than last for language data influence. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc
2022
-
[23]
Less: Selecting influential data for targeted instruction tuning, 2024
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: Selecting influential data for targeted instruction tuning, 2024
2024
-
[24]
Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney
Tyler A. Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney. Scalable influence and fact tracing for large language model pretraining, 2024
2024
-
[25]
Lorif: Low-rank influence functions for scalable training data attribution, 2026
Shuangqi Li, Hieu Le, Jingyi Xu, and Mathieu Salzmann. Lorif: Low-rank influence functions for scalable training data attribution, 2026
2026
-
[26]
Pingbang Hu, Joseph Melkonian, Weijing Tang, Han Zhao, and Jiaqi W. Ma. Grass: Scalable data attribution with gradient sparsification and sparse projection, 2025
2025
-
[27]
Relatif: Identifying explanatory training samples via relative influence
Elnaz Barshan, Marc-Etienne Brunet, and Gintare Karolina Dziugaite. Relatif: Identifying explanatory training samples via relative influence. In Silvia Chiappa and Roberto Calandra, editors,Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 1899–1...
1909
-
[28]
Trak: Attributing model behavior at scale, 2023
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale, 2023
2023
-
[29]
Dsdm: Model-aware dataset selection with datamodels, 2024
Logan Engstrom, Axel Feldmann, and Aleksander Madry. Dsdm: Model-aware dataset selection with datamodels, 2024
2024
-
[30]
Wang, Dawn Song, James Zou, Prateek Mittal, and Ruoxi Jia
Jiachen T. Wang, Dawn Song, James Zou, Prateek Mittal, and Ruoxi Jia. Capturing the temporal dependence of training data influence, 2024
2024
-
[31]
If influence functions are the answer, then what is the question?, 2022
Juhan Bae, Nathan Ng, Alston Lo, Marzyeh Ghassemi, and Roger Grosse. If influence functions are the answer, then what is the question?, 2022
2022
-
[32]
Data selection for language models via importance resampling
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[33]
Towards tracing knowledge in language models back to the training data
Ekin Akyurek, Tolga Bolukbasi, Frederick Liu, Binbin Xiong, Ian Tenney, Jacob Andreas, and Kelvin Guu. Towards tracing knowledge in language models back to the training data. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2429–2446, Abu Dhabi, United Arab Emirates, D...
2022
-
[34]
DEFT-UCS: Data efficient fine-tuning for pre-trained language models via unsupervised core-set selection for text-editing
Devleena Das and Vivek Khetan. DEFT-UCS: Data efficient fine-tuning for pre-trained language models via unsupervised core-set selection for text-editing. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20296–20312, Miami, Florida, USA, November 2024...
2024
-
[35]
Explaining and improving model behavior with k nearest neighbor representations, 2020
Nazneen Fatema Rajani, Ben Krause, Wengpeng Yin, Tong Niu, Richard Socher, and Caiming Xiong. Explaining and improving model behavior with k nearest neighbor representations, 2020
2020
-
[36]
Data shapley: Equitable valuation of data for machine learning
Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learning. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2242–2251. PMLR, 09–15 Jun 2019
2019
-
[37]
Wang and Ruoxi Jia
Jiachen T. Wang and Ruoxi Jia. Data banzhaf: A robust data valuation framework for machine learning, 2023
2023
-
[38]
Simfluence: Modeling the influence of individual training examples by simulating training runs, 2023
Kelvin Guu, Albert Webson, Ellie Pavlick, Lucas Dixon, Ian Tenney, and Tolga Bolukbasi. Simfluence: Modeling the influence of individual training examples by simulating training runs, 2023
2023
-
[39]
Efficient compressive sensing with deterministic guarantees using expander graphs
Weiyu Xu and Babak Hassibi. Efficient compressive sensing with deterministic guarantees using expander graphs. In2007 IEEE Information Theory Workshop, pages 414–419. IEEE, 2007
2007
-
[40]
Combining geometry and combinatorics: A unified approach to sparse signal recovery
Radu Berinde, Anna C Gilbert, Piotr Indyk, Howard Karloff, and Martin J Strauss. Combining geometry and combinatorics: A unified approach to sparse signal recovery. In2008 46th Annual Allerton Conference on Communication, Control, and Computing, pages 798–805. IEEE, 2008
2008
-
[41]
Randomness conduc- tors and constant-degree lossless expanders
Michael Capalbo, Omer Reingold, Salil Vadhan, and Avi Wigderson. Randomness conduc- tors and constant-degree lossless expanders. InProceedings of the thiry-fourth annual ACM symposium on Theory of computing, pages 659–668, 2002
2002
-
[42]
nanochat: The best chatgpt that $100 can buy, 2025
Andrej Karpathy. nanochat: The best chatgpt that $100 can buy, 2025
2025
-
[43]
Climb: Clustering-based iterative data mixture bootstrapping for language model pre-training
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, Mostofa Patwary, Celine Lin, Jan Kautz, and Pavlo Molchanov. Climb: Clustering-based iterative data mixture bootstrapping for language model pre-training. arXiv preprint, 2025
2025
-
[44]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[45]
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning.arXiv preprint arXiv:2301.13688, 2023
Pith/arXiv arXiv 2023
-
[46]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[47]
How far can camels go? exploring the state of instruction tuning on open resources
Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Chandu, David Wadden, Kelsey MacMillan, Noah Smith, Iz Beltagy, and Hannaneh Hajishirzi. How far can camels go? exploring the state of instruction tuning on open resources. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Inform...
2023
-
[48]
Safe rlhf: Safe reinforcement learning from human feedback, 2023
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback, 2023
2023
-
[49]
Openwebtext corpus
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019. 13
2019
-
[50]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[51]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bha- gia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Allyson Ettinger, Michal Guerquin, David Heineman, Hamish Ivison, Pang Wei Koh, ...
2025
-
[52]
A statistical interpretation of term specificity and its application in retrieval
Karen Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11–21, 1972
1972
-
[53]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023
Pith/arXiv arXiv 2023
-
[54]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
2002
-
[55]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
2017
-
[56]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[57]
Prajit Ramachandran, Barret Zoph, and Quoc V . Le. Searching for activation functions, 2017
2017
-
[58]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024
2024
-
[59]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[60]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017
2017
-
[61]
Combining geometry and combinatorics: A unified approach to sparse signal recovery
Radu Berinde, Anna Gilbert, Piotr Indyk, Howard Karloff, and Martin Strauss. Combining geometry and combinatorics: A unified approach to sparse signal recovery. InAllerton, 2008
2008
-
[62]
Sparse recovery using sparse random matrices
Radu Berinde and Piotr Indyk. Sparse recovery using sparse random matrices. Technical report, MIT-CSAIL, 2008
2008
-
[63]
Efficient compressive sensing with deterministic guarantees using expander graphs
Wei Xu and Babak Hassibi. Efficient compressive sensing with deterministic guarantees using expander graphs. 2007
2007
-
[64]
Sparse recovery using sparse random matrices.preprint, 2008
Radu Berinde and Piotr Indyk. Sparse recovery using sparse random matrices.preprint, 2008
2008
-
[65]
Sparse recovery using sparse random matrices, 2008
Radu Berinde and Piotr Indyk. Sparse recovery using sparse random matrices, 2008. https: //people.csail.mit.edu/indyk/report.pdf
2008
-
[66]
Resolving training biases via influence- based data relabeling
Shuming Kong, Yanyan Shen, and Linpeng Huang. Resolving training biases via influence- based data relabeling. InInternational Conference on Learning Representations, 2022
2022
-
[67]
Influence function based data poisoning attacks to top-n recommender systems, 2020
Minghong Fang, Neil Zhenqiang Gong, and Jia Liu. Influence function based data poisoning attacks to top-n recommender systems, 2020
2020
-
[68]
Subpopulation data poisoning attacks, 2021
Matthew Jagielski, Giorgio Severi, Niklas Pousette Harger, and Alina Oprea. Subpopulation data poisoning attacks, 2021
2021
-
[69]
Extracting training data from large language models, 2021
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models, 2021. 14
2021
-
[70]
Rossi, and Srijan Kumar
Sejoon Oh, Sungchul Kim, Ryan A. Rossi, and Srijan Kumar. Influence-guided data augmenta- tion for neural tensor completion. InProceedings of the 30th ACM International Conference on Information & Knowledge Management, CIKM ’21, page 1386–1395. ACM, Oct 2021
2021
-
[71]
Donghoon Lee, Hyunsin Park, Trung Pham, and Chang D. Yoo. Learning augmentation network via influence functions. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10958–10967, June 2020
2020
-
[72]
Procedural knowledge in pretraining drives reasoning in large language models, 2025
Laura Ruis, Maximilian Mozes, Juhan Bae, Siddhartha Rao Kamalakara, Dwarak Talupuru, Acyr Locatelli, Robert Kirk, Tim Rocktäschel, Edward Grefenstette, and Max Bartolo. Procedural knowledge in pretraining drives reasoning in large language models, 2025
2025
-
[73]
Mates: Model-aware data selection for efficient pretraining with data influence models, 2024
Zichun Yu, Spandan Das, and Chenyan Xiong. Mates: Model-aware data selection for efficient pretraining with data influence models, 2024
2024
-
[74]
Selectllm: Can llms select important instructions to annotate?, 2024
Ritik Sachin Parkar, Jaehyung Kim, Jong Inn Park, and Dongyeop Kang. Selectllm: Can llms select important instructions to annotate?, 2024
2024
-
[75]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021
2021
-
[76]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 3045–3059, 2021
2021
-
[77]
Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
2023
-
[78]
Li, Arnab Sen Sharma, Aaron Mueller, Byron C
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. Function vectors in large language models, 2024
2024
-
[79]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets, 2024
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets, 2024
2024
-
[80]
Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.