CDER-SME: A Cross-Device Event-RGB Micro-Expression Dataset under Multi-Level Stress Induction
Pith reviewed 2026-06-27 01:23 UTC · model grok-4.3
The pith
CDER-SME supplies a cross-device Event-RGB dataset of 1963 micro-expression samples gathered under cognitive and social stress, along with an alignment method that works with independent sensors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
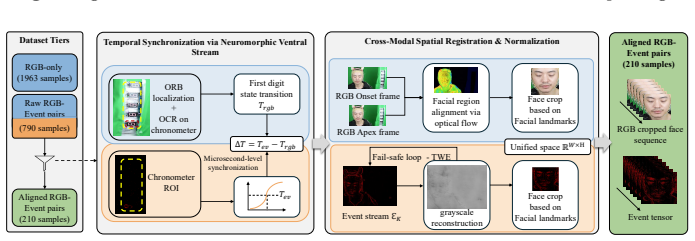
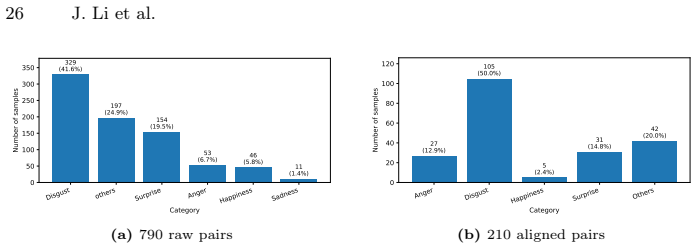
We introduce CDER-SME, a cross-device Event-RGB dataset collected under a multi-level stress induction framework (cognitive and social) to elicit spontaneous emotional leakage. To enable reproducible acquisition with independent, decoupled sensors, we provide a hardware-agnostic alignment pipeline for temporal synchronization and landmark-guided spatial registration. CDER-SME adopts a three-tier structure with 92 subjects and 1,963 expert-annotated samples (Action Units and emotions), including 790 Event-RGB pairs and 210 high-fidelity aligned pairs. We further report a reproducible multimodal baseline, where cross-modal fusion improves performance over single-modality counterparts, supporti
What carries the argument
The hardware-agnostic alignment pipeline that performs temporal synchronization and landmark-guided spatial registration between independent event and RGB sensors.
If this is right
- Cross-modal fusion of event dynamics and RGB cues raises micro-expression recognition performance above either modality used alone.
- The dataset removes the requirement for coaxial calibration, allowing practical cross-device Event-RGB setups.
- The 790 Event-RGB pairs and 210 high-fidelity aligned pairs supply test material for alignment and fusion methods.
- Expert annotations of action units and emotions across 1,963 samples support reproducible multimodal experiments.
Where Pith is reading between the lines
- The alignment pipeline could be tested on other decoupled sensor pairs such as event plus depth cameras for different recognition tasks.
- The cognitive and social stress protocol might be reused or modified to study other low-intensity behaviors in controlled psychology settings.
- Real-world deployment of the dataset approach could support applications like driver monitoring or interview analysis where natural micro-expressions appear.
Load-bearing premise
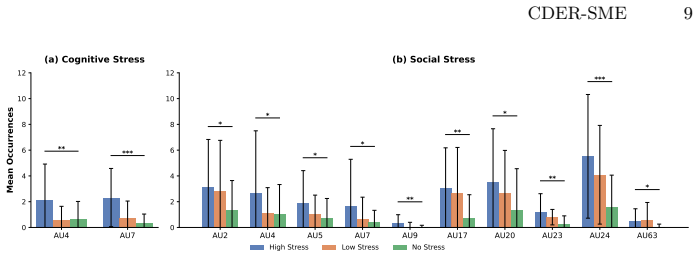
The multi-level stress induction framework reliably produces spontaneous micro-expressions that experts can consistently identify and annotate across the collected samples.
What would settle it
A controlled test in which models using fused event-RGB input show no accuracy gain over single-modality baselines on held-out samples, or in which the alignment pipeline produces visibly mismatched event-frame pairs on new independent hardware.
Figures





read the original abstract
Micro-expression recognition (MER) in realistic scenarios demands high temporal sensitivity and ecological validity, yet existing benchmarks are largely constrained to laboratory-controlled settings and rigid hardware-coupled sensing. We introduce CDER-SME, a cross-device Event-RGB dataset collected under a multi-level stress induction framework (cognitive and social) to elicit spontaneous emotional leakage. To enable reproducible acquisition with independent, decoupled sensors, we provide a hardware-agnostic alignment pipeline for temporal synchronization and landmark-guided spatial registration. CDER-SME adopts a three-tier structure with 92 subjects and 1,963 expert-annotated samples (Action Units and emotions), including 790 Event-RGB pairs and 210 high-fidelity aligned pairs. We further report a reproducible multimodal baseline, where cross-modal fusion improves performance over single-modality counterparts, supporting the complementarity of event dynamics and RGB cues. By removing the need for coaxial calibration, CDER-SME offers a practical benchmark for cross-device alignment and deployable Event-RGB MER in real-world affective intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CDER-SME, a cross-device Event-RGB micro-expression dataset collected from 92 subjects under a multi-level stress induction framework (cognitive and social) to elicit spontaneous emotional leakage. It comprises 1,963 expert-annotated samples (Action Units and emotions), including 790 Event-RGB pairs and 210 high-fidelity aligned pairs. The authors provide a hardware-agnostic alignment pipeline for temporal synchronization and landmark-guided spatial registration, and report a reproducible multimodal baseline in which cross-modal fusion improves performance over single-modality counterparts.
Significance. If the stress induction, synchronization, and annotation procedures are shown to be reliable, the dataset would offer a valuable benchmark for Event-RGB MER that removes the requirement for coaxial hardware calibration. This could support more ecologically valid and deployable affective computing systems. The alignment pipeline and baseline results, if quantitatively detailed, would strengthen reproducibility claims in the field.
major comments (3)
- [Dataset Collection and Stress Induction] The central claim that the multi-level stress induction reliably elicits spontaneous micro-expressions across the 1,963 samples is load-bearing for ecological validity, yet the manuscript provides no details on the specific task protocols, induction durations, or any corroborating measures (e.g., physiological signals or self-report validation) to support this.
- [Baseline Evaluation] The assertion that cross-modal fusion improves performance is central to the complementarity argument, but the provided text contains no quantitative baseline metrics (accuracy, F1, or statistical comparisons), tables, or error analysis, preventing evaluation of the reported gains.
- [Annotation Process] Expert annotation of Action Units and emotions for 1,963 samples requires reporting of inter-annotator agreement (e.g., Cohen's kappa or percentage agreement) to establish reliability; this is not addressed.
minor comments (2)
- The abstract would be strengthened by inclusion of at least one key quantitative result from the baseline (e.g., fusion accuracy delta).
- Clarify the exact number of subjects per stress level and any exclusion criteria applied to the 92 participants.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity, reproducibility, and validation that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Dataset Collection and Stress Induction] The central claim that the multi-level stress induction reliably elicits spontaneous micro-expressions across the 1,963 samples is load-bearing for ecological validity, yet the manuscript provides no details on the specific task protocols, induction durations, or any corroborating measures (e.g., physiological signals or self-report validation) to support this.
Authors: We agree that additional protocol details are necessary to substantiate the ecological validity of the stress induction. The current manuscript provides a high-level description of the cognitive and social stress framework but lacks granular information. In the revised version, we will expand the Dataset Collection section with specific task protocols, induction durations, and self-report validation measures where available. Physiological signals were not collected, as the experimental design prioritized decoupled cross-device Event-RGB capture without additional sensors; we will explicitly state this design choice and its implications as a limitation. revision: yes
-
Referee: [Baseline Evaluation] The assertion that cross-modal fusion improves performance is central to the complementarity argument, but the provided text contains no quantitative baseline metrics (accuracy, F1, or statistical comparisons), tables, or error analysis, preventing evaluation of the reported gains.
Authors: We acknowledge the referee's point that quantitative results are essential for evaluating the fusion gains. Although the abstract references the multimodal baseline, the main text does not present the metrics in sufficient detail. We will revise the Experiments section to include a dedicated table reporting accuracy, F1 scores, statistical comparisons (e.g., significance tests), and error analysis comparing single-modality and cross-modal fusion approaches. revision: yes
-
Referee: [Annotation Process] Expert annotation of Action Units and emotions for 1,963 samples requires reporting of inter-annotator agreement (e.g., Cohen's kappa or percentage agreement) to establish reliability; this is not addressed.
Authors: We agree that reporting inter-annotator agreement is required to demonstrate annotation reliability. The 1,963 samples were annotated by multiple experts following a standardized protocol. In the revision, we will add a subsection under Annotation Process that reports the agreement metrics, including Cohen's kappa for both Action Units and emotion labels. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a dataset introduction and baseline report with no mathematical derivations, fitted parameters, predictions, or self-citation chains. The central claims concern data collection under stress induction, a hardware-agnostic alignment pipeline, and empirical multimodal fusion results. These are presented as empirical contributions without any reduction to self-defined inputs or prior author work invoked as uniqueness theorems. The work is self-contained against external benchmarks as a new resource release.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: International Confer- ence on Pattern Recognition
Adra, M., Mirabet-Herranz, N., Dugelay, J.L.: Beyond RGB: Tri-modal microex- pression recognition with rgb, thermal, and event data. In: International Confer- ence on Pattern Recognition. pp. 311–324. Springer (2024)
2024
-
[2]
In: European Con- ference on Computer Vision
Becattini, F., Cultrera, L., Berlincioni, L., Ferrari, C., Leonardo, A., Del Bimbo, A.: Neuromorphic facial analysis with cross-modal supervision. In: European Con- ference on Computer Vision. pp. 205–223. Springer (2024)
2024
-
[3]
Ben, X., Ren, Y., Zhang, J., Wang, S.J., Kpalma, K., Meng, W., Liu, Y.J.: Video- Based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Al- gorithms. IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 5826–5846 (2022).https://doi.org/10.1109/TPAMI.2021.3067464
-
[4]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR) Workshops
Berlincioni, L., et al.: Neuromorphic event-based facial expression recognition. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR) Workshops. pp. 4109–4119 (2023)
2023
-
[5]
IEEE Transactions on Multimedia25, 1345–1358 (2022)
Chen, B., Liu, K.H., Xu, Y., Wu, Q.Q., Yao, J.F.: Block division convolutional network with implicit deep features augmentation for micro-expression recognition. IEEE Transactions on Multimedia25, 1345–1358 (2022)
2022
-
[6]
Davison, A.K., Lansley, C., Costen, N., Tan, K., Yap, M.H.: SAMM: A Spon- taneous Micro-Facial Movement Dataset. IEEE Transactions on Affective Com- puting9(1), 116–129 (2018).https://doi.org/10.1109/TAFFC.2016.2573832, https://ieeexplore.ieee.org/document/7492264/?arnumber=7492264
-
[7]
Journal of imaging4(10), 119 (2018)
Davison, A.K., Merghani, W., Yap, M.H.: Objective classes for micro-facial expres- sion recognition. Journal of imaging4(10), 119 (2018)
2018
-
[8]
Dickerson, S.S., Kemeny, M.E.: Acute stressors and cortisol responses: a theoretical integrationandsynthesisoflaboratoryresearch.Psychologicalbulletin130(3), 355 (2004)
2004
-
[9]
Frontiers in Psychology12, 784834 (2022)
Dong, Z., Wang, G., Lu, S., Li, J., Yan, W., Wang, S.J.: Spontaneous facial expres- sions and micro-expressions coding: from brain to face. Frontiers in Psychology12, 784834 (2022)
2022
-
[10]
The philosophy of deception1(2), 5 (2009)
Ekman, P.: Lie catching and microexpressions. The philosophy of deception1(2), 5 (2009)
2009
-
[11]
WW Norton & Company (2009) 16 J
Ekman, P.: Telling lies: Clues to deceit in the marketplace politics and marriage. WW Norton & Company (2009) 16 J. Li et al
2009
-
[12]
Environmental Psychology & Nonverbal Behavior (1978)
Ekman, P., Friesen, W.V.: Facial action coding system. Environmental Psychology & Nonverbal Behavior (1978)
1978
-
[13]
IEEE transactions on pattern analysis and machine intelligence 44(1), 154–180 (2020)
Gallego, G., Delbrück, T., Orchard, G., Bartolozzi, C., Taba, B., Censi, A., Leutenegger, S., Davison, A.J., Conradt, J., Daniilidis, K., et al.: Event-based vision: A survey. IEEE transactions on pattern analysis and machine intelligence 44(1), 154–180 (2020)
2020
-
[14]
In: Proceedings of the 3rd Workshop on Facial Micro- Expression (FME ’23)
Guo, C., Huang, H.: GLEFFN: A global-local event feature fusion network for micro-expression recognition. In: Proceedings of the 3rd Workshop on Facial Micro- Expression (FME ’23). p. 8. ACM (2023)
2023
-
[15]
Pattern Recognition Letters163, 57–64 (2022)
He, Y., Xu, Z., Ma, L., Li, H.: Micro-expression spotting based on optical flow features. Pattern Recognition Letters163, 57–64 (2022)
2022
-
[16]
in the wild
Husák, P., Cech, J., Matas, J.: Spotting facial micro-expressions “in the wild”. In: 22nd Computer Vision Winter Workshop (Retz). pp. 1–9 (2017)
2017
-
[17]
Neuropsychobiology28(1-2), 76–81 (1993)
Kirschbaum, C., Pirke, K.M., Hellhammer, D.H.: The ‘trier social stress test’– a tool for investigating psychobiological stress responses in a laboratory setting. Neuropsychobiology28(1-2), 76–81 (1993)
1993
-
[18]
arXiv preprint arXiv:2201.05297 (2022)
Li, H., Sui, M., Zhu, Z., Zhao, F.: Mmnet: Muscle motion-guided network for micro-expression recognition. arXiv preprint arXiv:2201.05297 (2022)
arXiv 2022
-
[19]
IEEE Transactions on Pat- tern Analysis and Machine Intelligence45(3), 2782–2800 (2022)
Li, J., Dong, Z., Lu, S., Wang, S.J., Yan, W.J., Ma, Y., Liu, Y., Huang, C., Fu, X.: CAS(ME)3: A Third Generation Facial Spontaneous Micro-Expression Database With Depth Information and High Ecological Validity. IEEE Transactions on Pat- tern Analysis and Machine Intelligence45(3), 2782–2800 (2022)
2022
-
[20]
IEEE Transactions on Affective Computing16(4), 2959–2974 (2025).https://doi.org/10.1109/TAFFC
Li, J., Lu, S., Wang, Y., Dong, Z., Wang, S.J., Fu, X.: Could micro-expressions be quantified? electromyography gives affirmative evidence. IEEE Transactions on Affective Computing16(4), 2959–2974 (2025).https://doi.org/10.1109/TAFFC. 2025.3575127
-
[21]
IEEE Transactions on Affective Computing14(4), 3031–3047 (2023).https://doi
Li, X., Cheng, S., Li, Y., Behzad, M., Shen, J., Zafeiriou, S., Pantic, M., Zhao, G.: 4DME: A Spontaneous 4D Micro-Expression Dataset With Multimodalities. IEEE Transactions on Affective Computing14(4), 3031–3047 (2023).https://doi. org/10.1109/TAFFC.2022.3182342,https://ieeexplore.ieee.org/document/ 9796028/?arnumber=9796028
-
[22]
Li, X., Pfister, T., Huang, X., Zhao, G., Pietikäinen, M.: A Spontaneous Micro- expression Database: Inducement, collection and baseline. In: 2013 10th IEEE In- ternational Conference and Workshops on Automatic Face and Gesture Recogni- tion (FG). pp. 1–6 (2013).https://doi.org/10.1109/FG.2013.6553717
-
[23]
IEEE Transactions on Affective Computing13(4), 2028– 2046 (2022)
Li, Y., Wei, J., Liu, Y., Kauttonen, J., Zhao, G.: Deep learning for micro-expression recognition: A survey. IEEE Transactions on Affective Computing13(4), 2028– 2046 (2022)
2028
-
[24]
In: European Conference on Computer Vi- sion
Lin, S., Ma, Y., Guo, Z., Wen, B.: Dvs-voltmeter: Stochastic process-based event simulator for dynamic vision sensors. In: European Conference on Computer Vi- sion. pp. 578–593. Springer (2022)
2022
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Mastropasqua, N., Bugueno-Cordova, I., Verschae, R., Acevedo, D., Negri, P., Buemi, M.E.: Exploring spatial-temporal dynamics in event-based facial micro- expression analysis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4723–4732 (2025)
2025
-
[26]
In: Proceedings of the 13th annual ACM international conference on Multimedia
Pantic,M.,Sebe,N.,Cohn,J.F.,Huang,T.:Affectivemultimodalhuman-computer interaction. In: Proceedings of the 13th annual ACM international conference on Multimedia. pp. 669–676 (2005)
2005
-
[27]
MIT press (1997) CDER-SME 17
Picard, R.W.: Affective computing. MIT press (1997) CDER-SME 17
1997
-
[28]
In: 3rd international conference on imaging for crime detection and prevention (ICDP 2009)
Polikovsky, S., Kameda, Y., Ohta, Y.: Facial micro-expressions recognition using high speed camera and 3d-gradient descriptor. In: 3rd international conference on imaging for crime detection and prevention (ICDP 2009). pp. 1–6. IET (2009)
2009
-
[29]
Psychological science19(5), 508– 514 (2008)
Porter, S., Ten Brinke, L.: Reading between the lies: Identifying concealed and falsified emotions in universal facial expressions. Psychological science19(5), 508– 514 (2008)
2008
-
[30]
IEEE Transactions on Affective Computing9(4), 424–436 (2018).https://doi
Qu, F., Wang, S.J., Yan, W.J., Li, H., Wu, S., Fu, X.: CAS(ME)2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Recognition. IEEE Transactions on Affective Computing9(4), 424–436 (2018).https://doi. org/10.1109/TAFFC.2017.2654440,https://ieeexplore.ieee.org/document/ 7820164/
-
[31]
IEEE transactions on pattern analysis and machine intelligence43(6), 1964–1980 (2019)
Rebecq, H., Ranftl, R., Koltun, V., Scaramuzza, D.: High speed and high dynamic range video with an event camera. IEEE transactions on pattern analysis and machine intelligence43(6), 1964–1980 (2019)
1964
-
[32]
In: 2011 IEEE international conference on automatic face & gesture recognition (FG)
Shreve, M., Godavarthy, S., Goldgof, D., Sarkar, S.: Macro-and micro-expression spotting in long videos using spatio-temporal strain. In: 2011 IEEE international conference on automatic face & gesture recognition (FG). pp. 51–56. IEEE (2011)
2011
-
[33]
Journal of experi- mental psychology18(6), 643 (1935)
Stroop, J.R.: Studies of interference in serial verbal reactions. Journal of experi- mental psychology18(6), 643 (1935)
1935
-
[34]
Neurocomputing602, 128196 (2024)
Wang, Z., Zhang, K., Luo, W., Sankaranarayana, R.: Htnet for micro-expression recognition. Neurocomputing602, 128196 (2024)
2024
-
[35]
Wen-Jing Yan, Wu, Q., Yong-Jin Liu, Su-Jing Wang, Fu, X.: CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces. In: 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). pp. 1–7. IEEE (2013).https://doi.org/10.1109/FG. 2013.6553799,http://ieeexplore.ieee.org/document/6553799/
work page doi:10.1109/fg 2013
-
[36]
In: IEEE International Conference on Multimedia and Expo (ICME)
Xiao, P., et al.: ESTME: Event-driven spatio-temporal motion enhancement for micro-expression recognition. In: IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6 (2024)
2024
-
[37]
PLoS ONE9(1), e86041 (2014-01-27).https://doi.org/10.1371/journal.pone
Yan, W.J., Li, X., Wang, S.J., Zhao, G., Liu, Y.J., Chen, Y.H., Fu, X.: CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE9(1), e86041 (2014-01-27).https://doi.org/10.1371/journal.pone. 0086041,https://dx.plos.org/10.1371/journal.pone.0086041
-
[38]
Zhao, S., Tang, H., Mao, X., Liu, S., Zhang, Y., Wang, H., Xu, T., Chen, E.: DFME: A New Benchmark for Dynamic Facial Micro-Expression Recognition. IEEE Transactions on Affective Computing15(3), 1371–1386 (2024).https: //doi.org/10.1109/TAFFC.2023.3341918 18 J. Li et al. Supplementary Materials A Dataset Release Protocol and Data Card To facilitate commun...
-
[39]
raw RGB videos and raw event streams in their original formats
-
[40]
temporal annotations including onset, apex, and offset
-
[41]
AU annotations and AU laterality labels
-
[42]
derived objective emotion labels based on AU rules
-
[43]
stress-condition labels indicating the corresponding induction setting
-
[44]
alignment metadata including estimated cross-device temporal offset, face- crop information
-
[45]
whitening
official split files, evaluation scripts, and reference-baseline code. This release design follows the benchmark plan stated in the main paper and aims to support transparent and reproducible downstream comparisons. In practice, we recommend Tier-1 for large-scale RGB-only learning, Tier-2 for robust cross-device or weakly synchronized multimodal research...
1944
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.