DSAA: Dual-Stage Attribute Activation for Fine-grained Open Vocabulary Detection
Pith reviewed 2026-05-20 12:01 UTC · model grok-4.3
The pith
Open-vocabulary detection models bind attributes to the wrong objects when category signals dominate inference, and the DSAA framework corrects this by activating attribute information at two stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
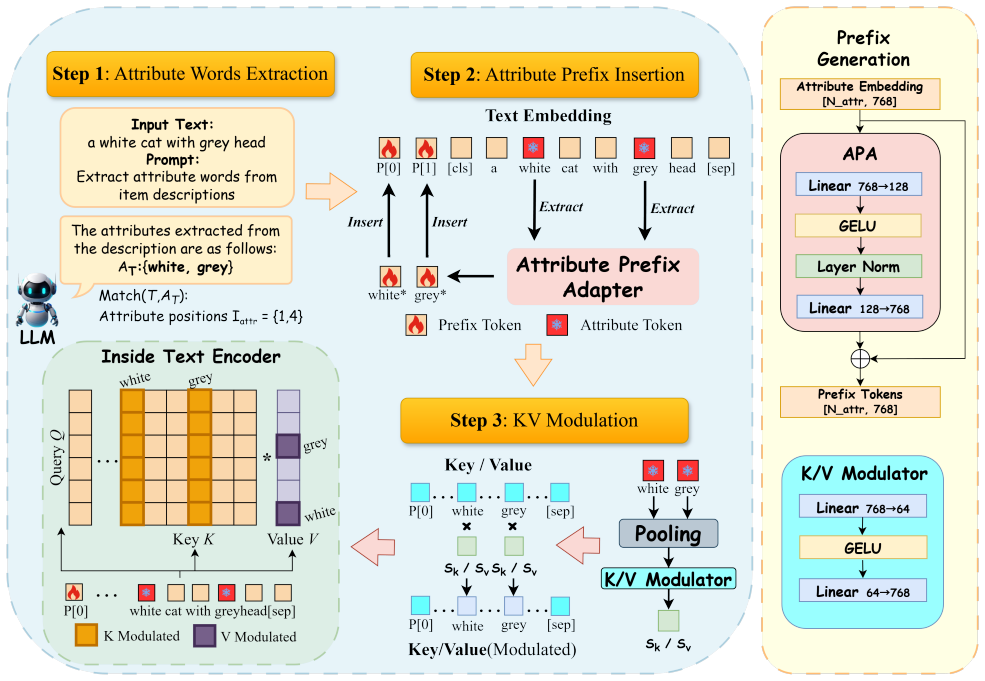
We attribute this performance bottleneck in OVD models to a core issue: when category signals dominate, OVD models tend to marginalize attribute information during inference. This leads to incorrect binding between attributes and target objects. To address this, we propose the Dual-Stage Attribute Activation (DSAA) framework, which enhances fine-grained detection capabilities by strengthening attribute semantics at two critical stages. In the text embedding stage, we employ Attribute Prefix Adapter (APA) module to generate attribute prefixes that inject explicit attribute priors. To further amplify the influence of these attributes, our Key/Value (K/V) Modulator module then intervenes during
What carries the argument
The Dual-Stage Attribute Activation (DSAA) framework, which strengthens attribute semantics by generating explicit attribute prefixes with the Attribute Prefix Adapter in the text embedding stage and selectively enhancing the Key and Value vectors of attribute tokens with the K/V Modulator during BERT encoding, plus an attribute-aware contrastive loss for training discrimination.
If this is right
- Strengthens attribute semantics at the text embedding and BERT encoding stages to improve fine-grained detection.
- Enables better discrimination among same-category instances that differ only in attributes.
- Applies to various mainstream open-vocabulary detection models without changing their core category detection.
- Raises performance on tasks that require identifying specific colors, materials, and textures in unseen categories.
Where Pith is reading between the lines
- The same two-stage activation pattern may help other vision-language models that suffer from weak attribute grounding in captioning or visual question answering.
- Extending the modulator to additional token types could address fine-grained signals beyond attributes, such as spatial relations or actions.
- Testing the framework on datasets with rarer attribute combinations would reveal whether the binding correction scales to long-tail cases.
Load-bearing premise
The performance bottleneck arises specifically because category signals dominate and marginalize attribute information during inference, producing incorrect attribute-object bindings that the APA module, K/V Modulator, and contrastive loss can fix without offsetting errors.
What would settle it
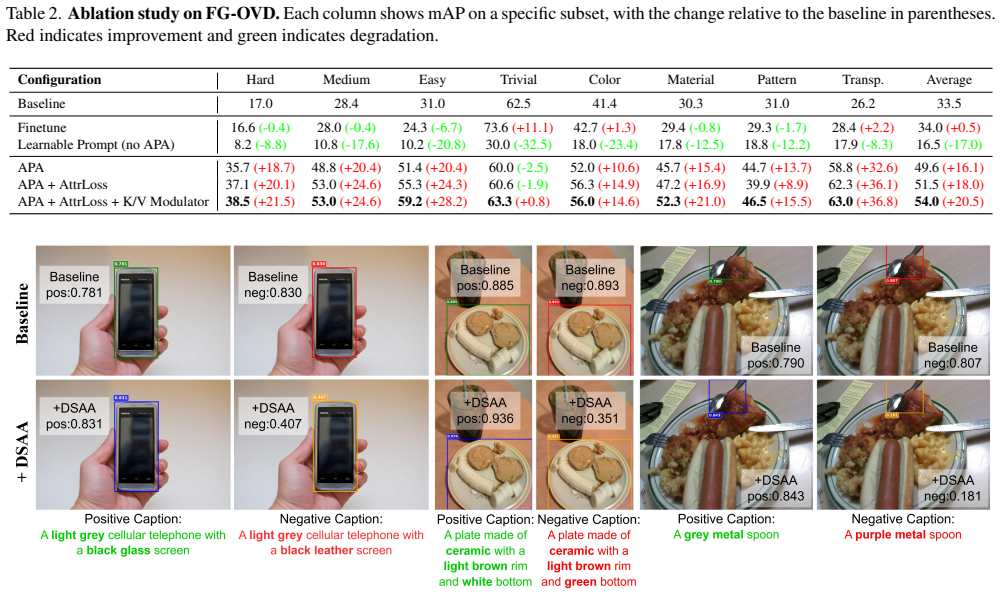
Running the DSAA modules on the FG-OVD benchmark and finding no gain in fine-grained attribute detection accuracy or a drop in standard category-level performance would show the central claim does not hold.
Figures




read the original abstract
Open-Vocabulary Object Detection (OVD) models break the limitations of closed-set detection, enabling the identification of unseen categories through natural language prompts. However, they exhibit notable limitations in fine-grained detection tasks involving attributes like color, material, and texture. We attribute this performance bottleneck in OVD models to a core issue: when category signals dominate, OVD models tend to marginalize attribute information during inference. This leads to incorrect binding between attributes and target objects. To address this, we propose the Dual-Stage Attribute Activation (DSAA) framework, which enhances fine-grained detection capabilities by strengthening attribute semantics at two critical stages. In the text embedding stage, we employ Attribute Prefix Adapter (APA) module to generate attribute prefixes that inject explicit attribute priors. To further amplify the influence of these attributes, our Key/Value (K/V) Modulator module then intervenes during the BERT encoding phase, selectively enhancing the Key and Value vectors of the corresponding attribute tokens. In addition, we introduce an attribute-aware contrastive loss to improve discrimination among same-category instances with different attributes during training. Experimental results on the FG-OVD benchmark demonstrate the effectiveness of our method across various mainstream open-vocabulary models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Dual-Stage Attribute Activation (DSAA) framework to improve fine-grained open-vocabulary object detection (OVD). It attributes the performance bottleneck to category signals dominating and marginalizing attribute information during inference, which causes incorrect attribute-object binding. DSAA addresses this via an Attribute Prefix Adapter (APA) module that injects explicit attribute priors in the text embedding stage, a Key/Value (K/V) Modulator that selectively enhances attribute token vectors during BERT encoding, and an attribute-aware contrastive loss to improve discrimination among same-category instances with differing attributes. Experiments on the FG-OVD benchmark are reported to demonstrate effectiveness across mainstream OVD models.
Significance. If the empirical gains on FG-OVD hold and arise specifically from improved attribute binding rather than generic capacity or supervision effects, the work could offer a practical, targeted enhancement for fine-grained OVD. The dual-stage design and attribute-aware loss provide concrete architectural interventions, and the explicit introduction of APA and K/V Modulator modules supplies a reproducible recipe for strengthening attribute semantics.
major comments (2)
- [Introduction] Introduction (core premise paragraph): The claim that category signals dominate and marginalize attribute information (leading to incorrect binding) is presented as the central bottleneck but lacks direct supporting diagnostics such as attention weight comparisons between attribute and category tokens, embedding cosine distances, or failure-case visualizations conditioned on the presence of both signals. Without this evidence, it remains unclear whether the proposed APA and K/V Modulator specifically correct the hypothesized mechanism or whether gains arise from other factors.
- [Method] Method section (DSAA framework and K/V Modulator description): No ablation or analysis is provided showing that the modulation of Key/Value vectors for attribute tokens restores correct binding without offsetting degradation on category-level detection. If the modules or contrastive loss term affect overall performance, the claim that DSAA strengthens attribute semantics at the two critical stages without trade-offs requires targeted validation (e.g., separate category-only and attribute-only metrics).
minor comments (2)
- [Abstract] Abstract: The statement that results 'demonstrate the effectiveness of our method across various mainstream open-vocabulary models' would be strengthened by naming the specific models and reporting at least one key quantitative delta (e.g., mAP improvement on FG-OVD).
- [Method] Notation and equations: The definition of the modulation scale and how it is applied to the Key and Value vectors in the K/V Modulator should be given explicitly (e.g., as an equation) to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying our approach and committing to targeted revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Introduction] Introduction (core premise paragraph): The claim that category signals dominate and marginalize attribute information (leading to incorrect binding) is presented as the central bottleneck but lacks direct supporting diagnostics such as attention weight comparisons between attribute and category tokens, embedding cosine distances, or failure-case visualizations conditioned on the presence of both signals. Without this evidence, it remains unclear whether the proposed APA and K/V Modulator specifically correct the hypothesized mechanism or whether gains arise from other factors.
Authors: We acknowledge that the introduction relies on the observed performance gains on FG-OVD to support the category-dominance hypothesis rather than providing explicit diagnostics such as attention maps or cosine similarities. While these gains across multiple OVD backbones are consistent with improved attribute binding, we agree that direct evidence would more rigorously isolate the mechanism. In the revised manuscript we will add attention weight comparisons between attribute and category tokens along with conditioned failure-case visualizations to demonstrate the binding issue in baselines and its alleviation by DSAA. revision: yes
-
Referee: [Method] Method section (DSAA framework and K/V Modulator description): No ablation or analysis is provided showing that the modulation of Key/Value vectors for attribute tokens restores correct binding without offsetting degradation on category-level detection. If the modules or contrastive loss term affect overall performance, the claim that DSAA strengthens attribute semantics at the two critical stages without trade-offs requires targeted validation (e.g., separate category-only and attribute-only metrics).
Authors: We note that our reported results show net improvements on fine-grained metrics without degradation on standard OVD benchmarks, indicating that the K/V modulator and contrastive loss do not introduce obvious category-level trade-offs. Nevertheless, to supply the requested targeted validation we will include new ablations that separately report category-only and attribute-specific metrics. These additions will confirm that attribute semantics are strengthened at both stages without compromising category detection performance. revision: yes
Circularity Check
No significant circularity in DSAA framework derivation
full rationale
The paper proposes new modules (Attribute Prefix Adapter, K/V Modulator) and an attribute-aware contrastive loss to strengthen attribute semantics in OVD models. These are presented as architectural interventions with empirical validation on FG-OVD benchmark; no equations or steps reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central premise on category dominance is an interpretive attribution rather than a tautological derivation, and the method remains self-contained against external benchmarks without load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Module-specific hyperparameters (prefix length, modulation scale, loss weight)
axioms (1)
- domain assumption Category signals dominate and marginalize attribute information during OVD inference, producing incorrect attribute-object binding
invented entities (2)
-
Attribute Prefix Adapter (APA)
no independent evidence
-
Key/Value (K/V) Modulator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We attribute this performance bottleneck in OVD models to a core issue: when category signals dominate, OVD models tend to marginalize attribute information during inference. This leads to incorrect binding between attributes and target objects. ... Attribute Prefix Adapter (APA) ... Key/Value (K/V) Modulator ... attribute-aware contrastive loss
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DSAA ... non-invasive framework that mitigates attribute marginalization ... +20.5 mAP on Grounding DINO
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.