Kinship Verification Using Voice
Pith reviewed 2026-06-28 13:01 UTC · model grok-4.3
The pith
Speaker embeddings encode familial cues that allow kinship verification from voice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
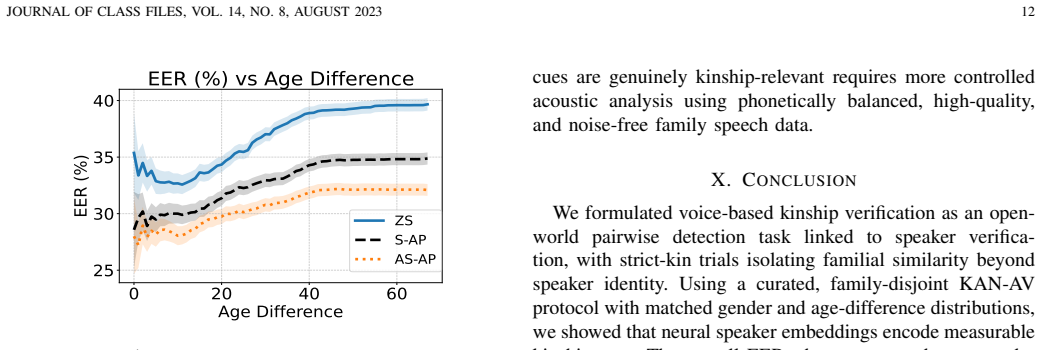
Genealogical similarity of speaker pairs plays opposite roles in speaker verification and kinship verification tasks. Neural speaker embedding extractors applied to speech from the KAN-AV dataset under a revised family-disjoint protocol demonstrate that embeddings carry familial cues, with zero-shot performance reaching 20.8 percent equal error rate when same-speaker trials are included and 39.7 percent when they are excluded; trainable back-ends that process embedding pairs asymmetrically to reduce age effects reach 32.0 percent.
What carries the argument
Neural speaker embedding extractors combined with back-end processors for embedding pairs, evaluated under a family-disjoint train-test split that controls for identity overlap and other confounders.
If this is right
- Existing speaker verification pipelines already contain information usable for kinship decisions without retraining the front-end.
- Back-end designs that treat embedding pairs asymmetrically can offset age-related mismatches in relational tasks.
- Kinship verification becomes feasible in zero-shot settings using models trained only for individual speaker discrimination.
- Strict trial definitions that exclude same-speaker pairs expose the remaining difficulty of pure cross-speaker family detection.
Where Pith is reading between the lines
- Public voice datasets may unintentionally expose family relationships if embedding models are applied without safeguards.
- The same embedding space could be probed for other relational signals such as shared environment or accent inheritance.
- Combining the voice approach with face-based kinship methods might produce higher accuracy through complementary cues.
- Testing the protocol on datasets from different languages or recording environments would check whether the familial cues generalize beyond the current collection.
Load-bearing premise
The audio-visual dataset supplies accurate biological kinship labels and its family-disjoint split plus other controls fully remove age, gender, recording conditions, and speaker identity as alternative explanations for any detected patterns.
What would settle it
Re-running the embedding extractors and back-ends on the same pairs after randomly reassigning the kinship labels while preserving all metadata would show whether detection rates fall to chance.
Figures



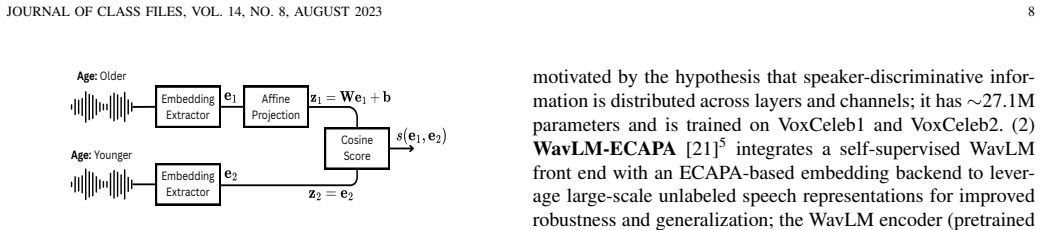

read the original abstract
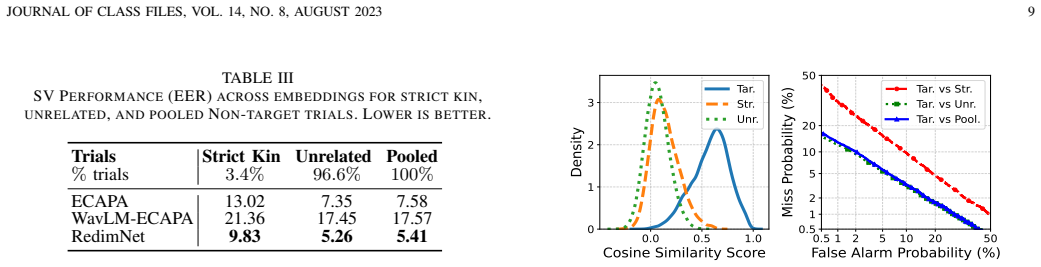
Kinship verification (KV) from voice, the task of determining whether two speakers are biologically related, has received only little attention. Our work establishes a foundational basis for this emerging frontier, contributing to both performance evaluation and detection methodologies. First, leveraging the speech recordings of the large-scale audio-visual dataset, KAN-AV, we propose a revised evaluation protocol that controls for various confounders and adopts a family-disjoint train--test split to address open-set KV. Second, we analyze the close connection between speaker verification and KV, showing that genealogical similarity of speaker pairs plays opposite roles in the two tasks. Third, we tackle KV using three neural speaker embedding extractors (ECAPA-TDNN, WavLM-ECAPA, and ReDimNet) combined with various back-ends. In zero-shot KV including same-speaker target trials, ReDimNet achieves the lowest equal error rate (EER) of $20.8\%$; however, performance degrades to $39.7\%$ under strict kin trials, where same-speaker target trials are excluded. Our best trainable back-end, which applies asymmetric processing of the embedding pair to mitigate age-difference effects, obtains an EER of $32.0\%$ ($18.6\%$ with speaker target trials included). These results highlight the difficulty of KV while showing that speaker embeddings encode familial cues, offering a promising foundation for voice-based kinship analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish a foundational basis for kinship verification (KV) from voice by introducing a revised protocol on the KAN-AV dataset that uses a family-disjoint train-test split and controls for confounders. It analyzes the opposing roles of genealogical similarity in speaker verification versus KV, then evaluates three embedding extractors (ECAPA-TDNN, WavLM-ECAPA, ReDimNet) with multiple back-ends, reporting concrete EERs such as 20.8% (ReDimNet zero-shot including same-speaker trials), 39.7% (strict-kin trials), and 32.0% (best trainable asymmetric back-end).
Significance. If the central empirical results hold after verification that residual confounders have been removed, the work supplies the first substantial set of reproducible EER numbers on multiple extractors and back-ends for an open-set KV task, demonstrating that speaker embeddings encode familial cues while underscoring the task's difficulty relative to speaker verification.
major comments (2)
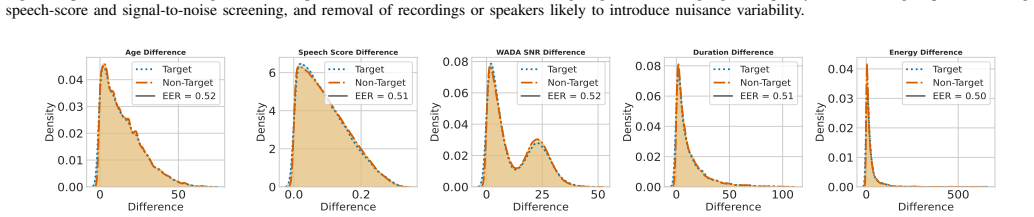
- [Evaluation Protocol] Evaluation Protocol section: the claim that the family-disjoint split plus unspecified controls for age/gender/channel suffice to attribute EERs below 50% to genealogical similarity rather than residual correlations is load-bearing; without explicit checks (e.g., Kolmogorov-Smirnov tests or histograms comparing age-difference distributions between kin and non-kin pairs post-split), the performance gap cannot be interpreted as evidence of familial encoding.
- [Experiments] Experiments section, results tables: the reported EER values (20.8%, 39.7%, 32.0%) lack error bars, bootstrap intervals, or multiple-run statistics, so the reliability of the ReDimNet and asymmetric back-end claims cannot be assessed.
minor comments (2)
- [Abstract] Abstract and Experiments: the asymmetric back-end is described as mitigating age-difference effects, yet no ablation isolating this component versus a symmetric baseline is shown.
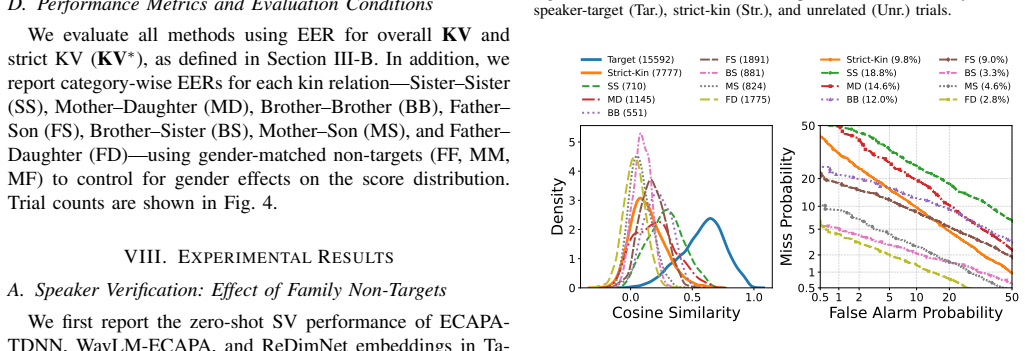
- [Experiments] Notation and tables: the distinction between 'zero-shot KV including same-speaker target trials' and 'strict kin trials' is used throughout but would benefit from an explicit definition table or equation clarifying trial composition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Evaluation Protocol] Evaluation Protocol section: the claim that the family-disjoint split plus unspecified controls for age/gender/channel suffice to attribute EERs below 50% to genealogical similarity rather than residual correlations is load-bearing; without explicit checks (e.g., Kolmogorov-Smirnov tests or histograms comparing age-difference distributions between kin and non-kin pairs post-split), the performance gap cannot be interpreted as evidence of familial encoding.
Authors: We agree that explicit verification of the controls is necessary to support the attribution of performance to genealogical similarity. The manuscript describes the family-disjoint split and controls for age, gender, and channel, but does not include statistical confirmation of balance. In the revised version, we will add Kolmogorov-Smirnov tests and histograms comparing age-difference distributions (and similarly for gender and channel where applicable) between kin and non-kin pairs after the split. revision: yes
-
Referee: [Experiments] Experiments section, results tables: the reported EER values (20.8%, 39.7%, 32.0%) lack error bars, bootstrap intervals, or multiple-run statistics, so the reliability of the ReDimNet and asymmetric back-end claims cannot be assessed.
Authors: We acknowledge that the absence of uncertainty estimates limits assessment of result reliability. We will compute and report bootstrap confidence intervals for the EER values (or statistics from multiple independent runs where feasible) in the revised experiments section and tables. revision: yes
Circularity Check
No circularity: empirical EER measurements on held-out family-disjoint data
full rationale
The paper reports direct experimental results from applying existing embedding extractors (ECAPA-TDNN, WavLM-ECAPA, ReDimNet) and back-ends to the KAN-AV dataset under a family-disjoint protocol. No equations, predictions, or uniqueness claims are presented that reduce by construction to fitted inputs, self-citations, or ansatzes. All reported EER figures (20.8%, 39.7%, 32.0%) are measured outcomes on test pairs, not derived quantities. The work is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption KAN-AV dataset contains accurate biological kinship labels for speaker pairs
- domain assumption Family-disjoint train-test split plus other controls remove identity, age, gender and recording confounders
Reference graph
Works this paper leans on
-
[1]
What is kinship about,
D. Schneider, “What is kinship about,”Kinship studies in the Morgan centennial, 1972
1972
-
[2]
How to estimate kinship,
J. Goudet, T. Kay, and B. S. Weir, “How to estimate kinship,”Molecular ecology, vol. 27, no. 20, pp. 4121–4135, 2018
2018
-
[3]
Kinship studies in late twentieth-century anthropology,
M. G. Peletz, “Kinship studies in late twentieth-century anthropology,” Annual review of anthropology, vol. 24, no. 1, pp. 343–372, 1995
1995
-
[4]
A survey on kinship verification,
W. Wang, S. You, S. Karaoglu, and T. Gevers, “A survey on kinship verification,”Neurocomputing, vol. 525, pp. 1–28, 2023
2023
-
[5]
Human ability to detect kinship in strangers’ faces: effects of the degree of relatedness,
G. Kaminski, S. Dridi, C. Graff, and E. Gentaz, “Human ability to detect kinship in strangers’ faces: effects of the degree of relatedness,” Proceedings of the Royal Society B: Biological Sciences, vol. 276, no. 1670, pp. 3193–3200, 2009
2009
-
[6]
Kan-av dataset for audio-visual face and speech analysis in the wild,
T. Kefalas, E. Fotiadou, M. Georgopoulos, Y . Panagakis, P. Ma, S. Petridis, T. Stafylakis, and M. Pantic, “Kan-av dataset for audio-visual face and speech analysis in the wild,”Image and Vision Computing, vol. 140, p. 104839, 2023
2023
-
[7]
Families in wild multimedia: A multimodal database for recognizing kinship,
J. P. Robinson, Z. Khan, Y . Yin, M. Shao, and Y . Fu, “Families in wild multimedia: A multimodal database for recognizing kinship,”IEEE Transactions on Multimedia, vol. 24, pp. 3582–3594, 2021
2021
-
[8]
Perceptual and acoustic similarities between the voices of family members: an approach to synthesize a voice based on family- shared f0 characteristics,
E. Rykova, “Perceptual and acoustic similarities between the voices of family members: an approach to synthesize a voice based on family- shared f0 characteristics,” Master’s thesis, University of Eastern Finland, Joensuu, Finland, 2018
2018
-
[9]
Language of kin relations and relationlessness,
C. Ball, “Language of kin relations and relationlessness,”Annual Review of Anthropology, vol. 47, no. 1, pp. 47–60, 2018
2018
-
[10]
Language in the constitution of kinship,
I. Keen, “Language in the constitution of kinship,”Anthropological Linguistics, vol. 56, no. 1, pp. 1–53, 2014
2014
-
[11]
T. F. Quatieri,Discrete-time speech signal processing: principles and practice. Pearson Education India, 2002
2002
-
[12]
Nolan,The Phonetic Bases of Speaker Recognition
F. Nolan,The Phonetic Bases of Speaker Recognition. Cambridge University Press, Oct. 1983
1983
-
[13]
Automatic speaker recognition of identical twins,
H. J. K ¨unzel, “Automatic speaker recognition of identical twins,”Inter- national Journal of Speech Language and The Law, vol. 17, pp. 251– 277, 2011
2011
-
[14]
Identical twins, different voices,
F. Nolan and T. Oh, “Identical twins, different voices,”The International Journal of Speech, Language and the Law, vol. 3, no. 1, pp. 39–49, June 1996
1996
-
[15]
Measurement of the impact of identical twin voices on automatic speaker recognition,
S. B. Sabatier, M. R. Trester, and J. M. Dawson, “Measurement of the impact of identical twin voices on automatic speaker recognition,” Measurement, vol. 134, pp. 385–389, 2019
2019
-
[16]
Effect of identical twins on deep speaker embeddings based forensic voice comparison,
M. H. Alsalihi and D. Sztah ´o, “Effect of identical twins on deep speaker embeddings based forensic voice comparison,”Int. J. Speech Technol., vol. 27, no. 2, p. 341–351, Jun. 2024. JOURNAL OF CLASS FILES, VOL. 14, NO. 8, AUGUST 2023 13
2024
-
[17]
Principles of linguistic change. volume 2: Social factors,
L. William, “Principles of linguistic change. volume 2: Social factors,” 2001
2001
-
[18]
Two decades of speaker recognition evaluation at the national institute of standards and technology,
C. S. Greenberg, L. P. Mason, S. O. Sadjadi, and D. A. Reynolds, “Two decades of speaker recognition evaluation at the national institute of standards and technology,”Computer Speech and Language, vol. 60, p. 101032, 2020
2020
-
[19]
Speaker recognition—identifying people by their voices,
G. R. Doddington, “Speaker recognition—identifying people by their voices,”Proceedings of the IEEE, vol. 73, pp. 1651–1664, 1985
1985
-
[20]
Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,” inProc. Interspeech 2020, 2020, pp. 3830–3834
2020
-
[21]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen and et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[22]
Reshape Dimensions Network for Speaker Recognition,
I. Yakovlev, R. Makarov, A. Balykin, P. Malov, A. Okhotnikov, and N. Torgashov, “Reshape Dimensions Network for Speaker Recognition,” inInterspeech 2024, 2024, pp. 3235–3239
2024
-
[23]
Identification of correlation between blood relations using speech signal,
P. Padmini, S. Tripathi, and K. Bhowmick, “Identification of correlation between blood relations using speech signal,” in2017 IEEE Interna- tional Conference on Signal Processing, Informatics, Communication and Energy Systems (SPICES). IEEE, 2017, pp. 1–6
2017
-
[24]
Audio- visual kinship verification in the wild,
X. Wu, E. Granger, T. H. Kinnunen, X. Feng, and A. Hadid, “Audio- visual kinship verification in the wild,” in2019 international conference on biometrics (ICB). IEEE, 2019, pp. 1–8
2019
-
[25]
Audio-visual kinship verification: a new dataset and a unified adaptive adversarial multimodal learning approach,
X. Wu, X. Zhang, X. Feng, M. B. Lopez, and L. Liu, “Audio-visual kinship verification: a new dataset and a unified adaptive adversarial multimodal learning approach,”IEEE Transactions on Cybernetics, vol. 54, no. 3, pp. 1523–1536, 2022
2022
-
[26]
Audio- based kinship verification using age domain conversion,
Q. Sun, A. Akman, X. Jing, M. Milling, and B. W. Schuller, “Audio- based kinship verification using age domain conversion,”IEEE Signal Processing Letters, 2024
2024
-
[27]
Front- end factor analysis for speaker verification,
N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front- end factor analysis for speaker verification,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2010
2010
-
[28]
V oxceleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,” inInterspeech 2018, 2018, pp. 1086–1090
2018
-
[29]
Pyannote. audio: neu- ral building blocks for speaker diarization,
H. Bredin, R. Yin, J. M. Coria, G. Gelly, P. Korshunov, M. Lavechin, D. Fustes, H. Titeux, W. Bouaziz, and M.-P. Gill, “Pyannote. audio: neu- ral building blocks for speaker diarization,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7124–7128
2020
-
[30]
X- vectors: Robust dnn embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X- vectors: Robust dnn embeddings for speaker recognition,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333
2018
-
[31]
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram Con- version,
T. Kaneko, H. Kameoka, K. Tanaka, and N. Hojo, “CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram Con- version,” inInterspeech 2020, 2020, pp. 2017–2021
2020
-
[32]
NIST 2024 speaker recognition evaluation plan,
National Institute of Standards and Technology, “NIST 2024 speaker recognition evaluation plan,” National Institute of Standards and Technology, Gaithersburg, MD, USA, Evaluation Plan, 2024, accessed: 2026-05-25. [Online]. Available: https://www.nist.gov/itl/iad/ mig/speaker-recognition
2024
-
[33]
Speaker identification and verification using gaussian mixture speaker models,
D. A. Reynolds, “Speaker identification and verification using gaussian mixture speaker models,”Speech Communication, vol. 17, no. 1, pp. 91–108, 1995
1995
-
[34]
Technical forensic speaker recognition: Evaluation, types and testing of evidence,
P. Rose, “Technical forensic speaker recognition: Evaluation, types and testing of evidence,”Computer Speech and Language, vol. 20, no. 2, pp. 159–191, 2006, odyssey 2004: The speaker and Language Recognition Workshop
2006
-
[35]
Consensus on validation of forensic voice comparison,
G. S. Morrison, E. Enzinger, V . Hughes, M. Jessen, D. Meuwly, C. Neumann, S. Planting, W. C. Thompson, D. van der Vloed, R. J. Ypma, C. Zhang, A. Anonymous, and B. Anonymous, “Consensus on validation of forensic voice comparison,”Science and Justice, vol. 61, no. 3, pp. 299–309, 2021
2021
-
[36]
The relevant population in forensic voice comparison: Effects of varying delimitations of social class and age,
V . Hughes and P. Foulkes, “The relevant population in forensic voice comparison: Effects of varying delimitations of social class and age,” Speech Communication, vol. 66, pp. 218–230, 2015
2015
-
[37]
Automatic speaker recognition of Spanish siblings: (monozygotic and dizygotic) twins and non-twin brothers,
E. S. Segundo and H. K ¨unzel, “Automatic speaker recognition of Spanish siblings: (monozygotic and dizygotic) twins and non-twin brothers,” Loquens, vol. 2, no. 2, July 2015
2015
-
[38]
Euclidean distances as measures of speaker similarity including identical twin pairs: A forensic investigation using source and filter voice characteristics,
E. San Segundo, A. Tsanas, and P. G ´omez-Vilda, “Euclidean distances as measures of speaker similarity including identical twin pairs: A forensic investigation using source and filter voice characteristics,”Forensic Science International, vol. 270, pp. 25–38, 2017
2017
-
[39]
Discrimination of voices of twins and siblings for speaker verification,
M. M. Homayounpour and G. Chollet, “Discrimination of voices of twins and siblings for speaker verification,” in4th European Conference on Speech Communication and Technology (Eurospeech 1995), 1995, pp. 345–348
1995
-
[40]
A test of the effectiveness of speaker verification for differentiating between identical twins,
A. Ariyaeeinia, C. Morrison, A. Malegaonkar, and S. Black, “A test of the effectiveness of speaker verification for differentiating between identical twins,”Science and Justice, vol. 48, no. 4, pp. 182–186, 2008
2008
-
[41]
Shortcut learning in deep neural networks,
R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann, “Shortcut learning in deep neural networks,”Nature Machine Intelligence, vol. 2, no. 11, pp. 665–673, 2020
2020
-
[42]
Pearl,Causality: Models, Reasoning, and Inference, 2nd ed
J. Pearl,Causality: Models, Reasoning, and Inference, 2nd ed. Cam- bridge: Cambridge University Press, 2009
2009
-
[43]
M. A. Hern ´an and J. M. Robins,Causal Inference: What If. Boca Raton, FL: Chapman and Hall/CRC, 2020, available at https://www. hsph.harvard.edu/miguel-hernan/causal-inference-book/
2020
-
[44]
Investigating bias in deep face analysis: The kanface dataset and empirical study,
M. Georgopoulos, Y . Panagakis, and M. Pantic, “Investigating bias in deep face analysis: The kanface dataset and empirical study,”Image and vision computing, vol. 102, p. 103954, 2020
2020
-
[45]
pyannote. audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe,
H. Bredin, “pyannote. audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe,” in24th INTERSPEECH Conference (INTER- SPEECH 2023). ISCA, 2023, pp. 1983–1987
2023
-
[46]
Ast: Audio spectrogram trans- former,
Y . Gong, Y .-A. Chung, and J. Glass, “Ast: Audio spectrogram trans- former,” inInterspeech 2021, 2021, pp. 571–575
2021
-
[47]
Robust signal-to-noise ratio estimation based on waveform amplitude distribution analysis,
C. Kim and R. M. Stern, “Robust signal-to-noise ratio estimation based on waveform amplitude distribution analysis,” inInterspeech 2008, 2008, pp. 2598–2601
2008
-
[48]
Shortcut learning in binary classifier black boxes: Applications to voice anti-spoofing and biometrics,
M. Sahidullah, H.-j. Shim, R. G. Hautam ¨aki, and T. H. Kinnunen, “Shortcut learning in binary classifier black boxes: Applications to voice anti-spoofing and biometrics,”IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[49]
rvad: An unsupervised segment-based robust voice activity detection method,
Z.-H. Tan, N. Dehaket al., “rvad: An unsupervised segment-based robust voice activity detection method,”Computer speech and language, vol. 59, pp. 1–21, 2020
2020
-
[50]
Overview of speaker modeling and its applications: From the lens of deep speaker representation learning,
S. Wang, Z. Chen, K. A. Lee, Y . Qian, and H. Li, “Overview of speaker modeling and its applications: From the lens of deep speaker representation learning,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 4971–4998, 2024
2024
-
[51]
Deep learning on small datasets without pre- training using cosine loss,
B. Barz and J. Denzler, “Deep learning on small datasets without pre- training using cosine loss,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2020, pp. 1371–1380
2020
-
[52]
Dimensionality reduction by learning an invariant mapping,
R. Hadsell, S. Chopra, and Y . LeCun, “Dimensionality reduction by learning an invariant mapping,” in2006 IEEE computer society con- ference on computer vision and pattern recognition (CVPR’06), vol. 2. IEEE, 2006, pp. 1735–1742
2006
-
[53]
Metric learning: A survey,
B. Kulis, “Metric learning: A survey,”Foundations and Trends® in Machine Learning, vol. 5, no. 4, pp. 287–364, 2013
2013
-
[54]
Information- theoretic metric learning,
J. V . Davis, B. Kulis, P. Jain, S. Sra, and I. S. Dhillon, “Information- theoretic metric learning,” inProceedings of the 24th international conference on Machine learning, 2007, pp. 209–216
2007
-
[55]
V oxceleb: Large- scale speaker verification in the wild,
A. Nagrani, J. S. Chung, W. Xie, and A. Zisserman, “V oxceleb: Large- scale speaker verification in the wild,”Computer Speech and Language, vol. 60, p. 101027, 2020
2020
-
[56]
Speaker verification using adapted gaussian mixture models,
D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, “Speaker verification using adapted gaussian mixture models,”Digital signal processing, vol. 10, no. 1-3, pp. 19–41, 2000
2000
-
[57]
Phoneme recognition using time-delay neural networks,
A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural networks,”IEEE Trans- actions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328–339, 1989
1989
-
[58]
Reshape Dimensions Network for Speaker Recognition,
I. Yakovlev, R. Makarov, A. Balykin, P. Malov, A. Okhotnikov, and N. Torgashov, “Reshape Dimensions Network for Speaker Recognition,” inProc. Interspeech 2024, 2024, pp. 3235–3239
2024
-
[59]
A statistical significance test for person authentication,
S. Bengio and J. Mari ´ethoz, “A statistical significance test for person authentication,” inProceedings of Odyssey 2004: The Speaker and Language Recognition Workshop, Toledo, Spain, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.