Local Observability and Moving Horizon Estimation-based Training of Feedforward Neural Networks
Pith reviewed 2026-06-29 10:19 UTC · model grok-4.3
The pith
For two-layer ReLU networks with fixed output weights, a sufficient condition makes the weight-state dynamical system locally observable and supplies convergence guarantees for moving-horizon training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the weights of an FNN as the state of a discrete-time dynamical system, the authors obtain a sufficient condition under which the observability rank condition holds for two-layer networks with fixed output weights. The resulting local observability allows construction of persistently exciting inputs that render the state distinguishable from its neighbors and, in turn, guarantees convergence of an MHE-based training algorithm that updates only the observable component of the state using a sliding window of input-output pairs.
What carries the argument
Reformulation of the FNN as a state-space dynamical system whose state is the vector of weights, analyzed via the observability rank condition.
If this is right
- Multi-layer FNNs in general fail to satisfy the observability rank condition.
- A persistently exciting input design renders the weight state distinguishable from neighbors.
- MHE training updates only the projection of the state onto the observable subspace.
- Convergence guarantees hold for the resulting MHE-based training when the observability condition is met.
Where Pith is reading between the lines
- The same observability analysis could be attempted for activation functions other than ReLU if an analogous state-space model can be written.
- The approach suggests that training procedures for networks embedded in feedback loops might inherit stability properties from the underlying estimator.
- Extension to time-varying output weights would require a different state definition and new rank conditions.
Load-bearing premise
The assumption that the feedforward network can be exactly represented as a dynamical system whose state vector is the weight vector and that chosen inputs render that state distinguishable from neighbors.
What would settle it
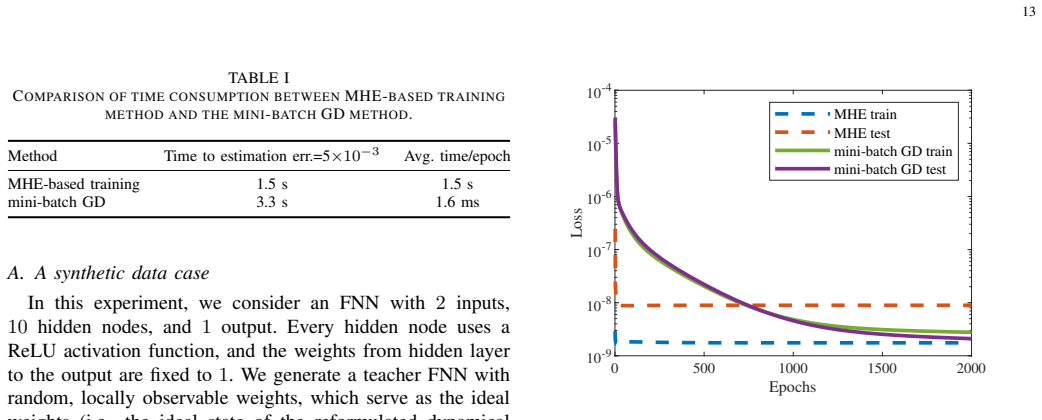
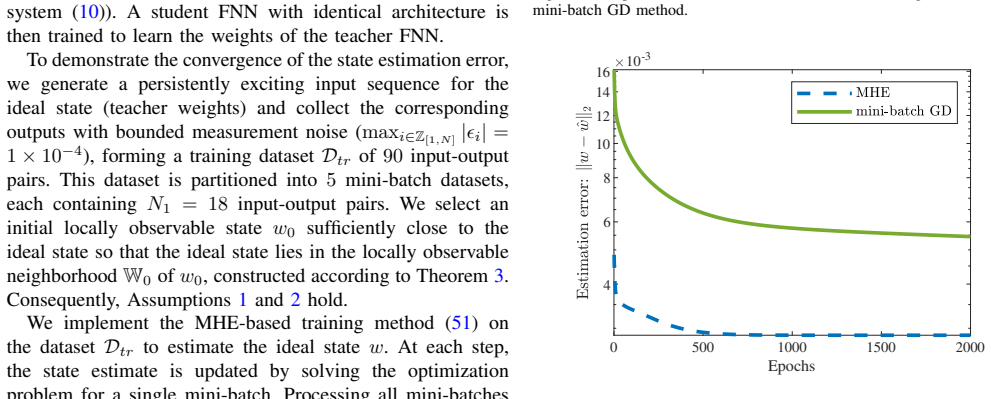
Numerical computation of the observability matrix for a two-layer network satisfying the derived sufficient condition; if its rank falls below the dimension of the observable subspace, or if MHE training on persistently exciting data fails to recover the target weights, the claim is refuted.
Figures


read the original abstract
In this paper, we propose a moving horizon estimation (MHE)-based training method for feedforward neural networks (FNNs) with rectified linear unit (ReLU) activation functions to determine their ideal weights from a control-theoretic perspective. This allows for a rigorous theoretical analysis of the trained network. First, we reformulate the FNN as a dynamical system with the weights as states. Then, we investigate the local observability of such a system. For two-layer FNNs with fixed output weights, we derive a sufficient condition under which the observability rank condition holds, ensuring a locally observable state. We also show that multi-layer FNNs in general fail to satisfy the observability rank condition. Based on this analysis, we develop a persistently exciting (PE) input design method, which renders a state distinguishable from its neighbors. The resulting local observability provides convergence guarantees for the proposed MHE-based training, where only the projection of the state onto the observable subspace is updated using a fixed-length window of input-output data. The effectiveness of the approach is illustrated via numerical examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates two-layer ReLU feedforward neural networks as discrete-time dynamical systems whose state is the vector of weights, derives a sufficient condition under which the observability rank condition holds when output weights are fixed (ensuring local observability), shows that multi-layer FNNs generally fail this condition, designs persistently exciting inputs to make states distinguishable, and uses the resulting local observability to provide convergence guarantees for an MHE-based training procedure that updates only the observable subspace projection from finite input-output windows.
Significance. If the observability analysis and convergence claims hold, the work supplies a control-theoretic foundation with explicit guarantees for training a restricted class of ReLU networks, which is a substantive contribution at the intersection of nonlinear systems theory and neural network training. The explicit PE input design and the negative result for multi-layer networks are useful technical contributions.
major comments (2)
- [observability analysis for two-layer FNNs (section deriving the sufficient condition)] The central claim that a sufficient condition exists under which the observability rank condition holds (abstract and the paragraph on two-layer FNNs) relies on the standard nonlinear observability rank condition, which requires the output map to be at least C^1. The output equation is y(k) = W2 · ReLU(W1 u(k) + b); ReLU is only piecewise differentiable and its Jacobian is undefined wherever any hidden pre-activation is exactly zero. The manuscript must specify whether the rank condition is evaluated using Clarke subdifferentials, one-sided derivatives, or by restricting to open sets away from the kink set, and whether the derived sufficient condition remains valid on a positive-measure set of states and inputs.
- [MHE training and convergence guarantees section] The convergence guarantees for the MHE-based training rest on local observability of the weight-state system. If the rank condition derivation does not rigorously handle the non-differentiable points, the local observability claim (and therefore the MHE convergence statement) is not established for generic data; the paper should provide an explicit statement of the set of (u, x) on which the guarantees apply.
minor comments (1)
- [abstract and multi-layer discussion] The abstract states that multi-layer FNNs 'in general fail to satisfy the observability rank condition'; a brief remark on whether this holds only for the standard Lie-derivative formulation or also for generalized notions would clarify the scope.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the differentiability assumptions underlying the observability analysis. We address each major comment below and will revise the manuscript to improve technical precision.
read point-by-point responses
-
Referee: [observability analysis for two-layer FNNs] The central claim that a sufficient condition exists under which the observability rank condition holds relies on the standard nonlinear observability rank condition, which requires the output map to be at least C^1. The output equation is y(k) = W2 · ReLU(W1 u(k) + b); ReLU is only piecewise differentiable and its Jacobian is undefined wherever any hidden pre-activation is exactly zero. The manuscript must specify whether the rank condition is evaluated using Clarke subdifferentials, one-sided derivatives, or by restricting to open sets away from the kink set, and whether the derived sufficient condition remains valid on a positive-measure set of states and inputs.
Authors: We agree that the standard observability rank condition assumes a C^1 map. Our derivation applies the rank condition only on open sets where all hidden pre-activations are nonzero, rendering ReLU locally affine (hence C^infty) and the output map differentiable. The sufficient condition is stated for generic weights and inputs that place the trajectory in such regions. These open sets have positive Lebesgue measure. We will revise Section 3 to explicitly note that the analysis is restricted to the complement of the kink set and that the condition holds on a positive-measure set. revision: yes
-
Referee: [MHE training and convergence guarantees section] The convergence guarantees for the MHE-based training rest on local observability of the weight-state system. If the rank condition derivation does not rigorously handle the non-differentiable points, the local observability claim (and therefore the MHE convergence statement) is not established for generic data; the paper should provide an explicit statement of the set of (u, x) on which the guarantees apply.
Authors: We concur that an explicit characterization is required. The local observability (and therefore the MHE convergence guarantees) holds on the open set of (u, x) pairs for which no hidden pre-activation is zero, i.e., the complement of the kink set. This set is open and dense for generic data. We will add a precise statement of this domain in the MHE convergence theorem and the associated discussion. revision: yes
Circularity Check
No circularity; derivation uses standard nonlinear observability rank condition
full rationale
The paper reformulates the two-layer ReLU FNN as the autonomous system x(k+1)=x(k), y(k)=W2·ReLU(W1 u(k)+b) with weights as state, then derives a sufficient condition under which the observability rank condition holds. This step invokes the standard Lie-derivative or Jacobian-based rank test from nonlinear systems theory (external to the paper) and does not reduce any claimed guarantee to a fitted parameter, self-citation chain, or redefinition of the target quantity. The subsequent PE input design and MHE convergence statement follow directly from that rank condition without circular closure. No load-bearing step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A feedforward neural network with ReLU activations can be exactly recast as a discrete-time dynamical system whose state vector contains the network weights.
- standard math The observability rank condition is a valid test for local observability of the resulting nonlinear state-space model.
Reference graph
Works this paper leans on
-
[1]
On recurrent neural networks for learning-based control: recent results and ideas for future developments,
F. Bonassi, M. Farina, J. Xie, and R. Scattolini, “On recurrent neural networks for learning-based control: recent results and ideas for future developments,”Journal of Process Control, vol. 114, pp. 92–104, 2022
2022
-
[2]
Neural networks for control systems—a survey,
K. J. Hunt, D. Sbarbaro, R. ˙Zbikowski, and P. J. Gawthrop, “Neural networks for control systems—a survey,”Automatica, vol. 28, no. 6, pp. 1083–1112, 1992
1992
-
[3]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017
2017
-
[4]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[5]
Approximate non- linear model predictive control with safety-augmented neural networks,
H. Hose, J. K ¨ohler, M. N. Zeilinger, and S. Trimpe, “Approximate non- linear model predictive control with safety-augmented neural networks,” IEEE Transactions on Control Systems Technology, vol. 33, no. 6, pp. 2490–2497, 2025
2025
-
[6]
Safe and efficient model predictive control using neural networks: An interior point approach,
D. Tabas and B. Zhang, “Safe and efficient model predictive control using neural networks: An interior point approach,” in2022 IEEE 61st Conference on Decision and Control (CDC), 2022, pp. 1142–1147
2022
-
[7]
Using stochastic programming to train neural network approximation of nonlinear MPC laws,
Y . Li, K. Hua, and Y . Cao, “Using stochastic programming to train neural network approximation of nonlinear MPC laws,”Automatica, vol. 146, p. 110665, 2022
2022
-
[8]
Deep learning in neural networks: an overview,
J. Schmidhuber, “Deep learning in neural networks: an overview,” Neural Networks, vol. 61, pp. 85–117, 2015
2015
-
[9]
Convergence analysis of two-layer neural networks with ReLU activation,
Y . Li and Y . Yuan, “Convergence analysis of two-layer neural networks with ReLU activation,” inProceedings of the 31st International Confer- ence on Neural Information Processing Systems, 2017, pp. 597–607
2017
-
[10]
Training multilayer perceptrons with the ex- tended Kalman algorithm,
S. Singhal and L. Wu, “Training multilayer perceptrons with the ex- tended Kalman algorithm,” inProceedings of the 2nd International Con- ference on Neural Information Processing Systems, 1988, p. 133–140
1988
-
[11]
Recurrent neural network training with convex loss and regularization functions by extended Kalman filtering,
A. Bemporad, “Recurrent neural network training with convex loss and regularization functions by extended Kalman filtering,”IEEE Transac- tions on Automatic Control, vol. 68, no. 9, pp. 5661–5668, 2022
2022
-
[12]
A Lyapunov function for robust stability of moving horizon estimation,
J. D. Schiller, S. Muntwiler, J. K ¨ohler, M. N. Zeilinger, and M. A. M¨uller, “A Lyapunov function for robust stability of moving horizon estimation,”IEEE Transactions on Automatic Control, vol. 68, no. 12, pp. 7466–7481, 2023
2023
-
[13]
Towards lifelong learning of recurrent neural networks for control design,
F. Bonassi, J. Xie, M. Farina, and R. Scattolini, “Towards lifelong learning of recurrent neural networks for control design,” in2022 European control conference (ECC). IEEE, 2022, pp. 2018–2023
2022
-
[14]
An alternative view: when does SGD escape local minima?
B. Kleinberg, Y . Li, and Y . Yuan, “An alternative view: when does SGD escape local minima?” inInternational Conference on Machine Learning. PMLR, 2018, pp. 2698–2707
2018
-
[15]
Uniqueness of weights for neural networks,
F. Albertini, E. D. Sontag, and V . Maillot, “Uniqueness of weights for neural networks,” inArtificial Neural Networks for Speech and Vision, 1993
1993
-
[16]
Parameter identifia- bility of a deep feedforward ReLU neural network,
J. Bona-Pellissier, F. Bachoc, and F. Malgouyres, “Parameter identifia- bility of a deep feedforward ReLU neural network,”Machine Learning, vol. 112, no. 11, pp. 4431–4493, 2023
2023
-
[17]
Nonlinear controllability and observability,
R. Hermann and A. Krener, “Nonlinear controllability and observability,” IEEE Transactions on Automatic Control, vol. 22, no. 5, pp. 728–740, 1977
1977
-
[18]
Observability of autonomous discrete time non-linear sys- tems: a geometric approach,
H. Nijmeijer, “Observability of autonomous discrete time non-linear sys- tems: a geometric approach,”International Journal of Control, vol. 36, no. 5, pp. 867–874, 1982
1982
-
[19]
Remarks on the observability of nonlinear discrete time systems,
F. Albertini and D. D’Alessandro, “Remarks on the observability of nonlinear discrete time systems,” inSystem Modelling and Optimiza- tion: Proceedings of the Seventeenth IFIP TC7 Conference on System Modelling and Optimization, 1995. Springer, 1996, pp. 155–162
1995
-
[20]
A concept of local observability,
E. D. Sontag, “A concept of local observability,”Systems & Control Letters, vol. 5, no. 1, pp. 41–47, 1984
1984
-
[21]
Measures of unobservability,
A. J. Krener and K. Ide, “Measures of unobservability,” inProceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference, 2009, pp. 6401–6406
2009
-
[22]
Empirical observability Gramian rank condition for weak observability of nonlinear systems with control,
N. D. Powel and K. A. Morgansen, “Empirical observability Gramian rank condition for weak observability of nonlinear systems with control,” in2015 54th IEEE Conference on Decision and Control (CDC), 2015, pp. 6342–6348
2015
-
[23]
Local identifiability of fully-connected feed-forward networks with nonlinear node dynamics,
M. Vanelli and J. M. Hendrickx, “Local identifiability of fully-connected feed-forward networks with nonlinear node dynamics,” in2025 Euro- pean Control Conference (ECC). IEEE, 2025, pp. 825–830
2025
-
[24]
Local observability of a class of feedforward neural networks,
Y . Yang, V . G. Lopez, and M. A. M ¨uller, “Local observability of a class of feedforward neural networks,” in2025 IEEE 64th Conference on Decision and Control (CDC). IEEE, 2025, pp. 90–95
2025
-
[25]
A sagemath package for elementary and sign vectors with applications to chemical reac- tion networks,
M. S. Aichmayr, S. M ¨uller, and G. Regensburger, “A sagemath package for elementary and sign vectors with applications to chemical reac- tion networks,” inInternational Congress on Mathematical Software. Springer, 2024, pp. 155–164
2024
-
[26]
The elementary vectors of a subspace ofR n,
R. T. Rockafellar, “The elementary vectors of a subspace ofR n,” in Combinatorial Mathematics and Its Applications. University of North Carolina Press, 1969, pp. 104–127
1969
-
[27]
The sparse basis problem and multilinear algebra,
R. A. Brualdi, S. Friedland, and A. Pothen, “The sparse basis problem and multilinear algebra,”SIAM Journal on Matrix Analysis and Appli- cations, vol. 16, no. 1, pp. 1–20, 1995
1995
-
[28]
Approximation by superpositions of a sigmoidal function,
G. Cybenko, “Approximation by superpositions of a sigmoidal function,” Mathematics of Control, Signals and Systems, vol. 2, no. 4, pp. 303–314, 1989
1989
-
[29]
Some applications of the pseudoinverse of a matrix,
T. Greville, “Some applications of the pseudoinverse of a matrix,”SIAM Review, vol. 2, no. 1, pp. 15–22, 1960
1960
-
[30]
Abraham, J
R. Abraham, J. E. Marsden, and T. Ratiu,Manifolds, tensor analysis, and applications. Springer Science & Business Media, 2012, vol. 75
2012
-
[31]
Strong convergence of infinite products of orthogonal pro- jections in Hilbert space,
M. Sakai, “Strong convergence of infinite products of orthogonal pro- jections in Hilbert space,”Applicable Analysis, vol. 59, no. 1-4, pp. 109–120, 1995
1995
-
[32]
R. A. Horn and C. R. Johnson,Matrix analysis. Cambridge university press, 2012
2012
-
[33]
UCI machine learning repository,
A. Asuncion, D. Newmanet al., “UCI machine learning repository,” 2007. 15
2007
-
[34]
CasADi: a software framework for nonlinear optimization and optimal control,
J. A. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl, “CasADi: a software framework for nonlinear optimization and optimal control,”Mathematical Programming Computation, vol. 11, no. 1, pp. 1–36, 2019
2019
-
[35]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
Noisy natural gra- dient as variational inference,
G. Zhang, S. Sun, D. Duvenaud, and R. Grosse, “Noisy natural gra- dient as variational inference,” inInternational conference on machine learning. PMLR, 2018, pp. 5852–5861. Yi Yangreceived both the B.Eng. and the M.Sc. degrees in control science and engineering from Beijing Institute of Technology, China, in 2021 and 2024, respectively. He is currently w...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.