Multi-scale Coarse-to-fine Modeling for Test-time Human Motion Control
Pith reviewed 2026-06-30 21:46 UTC · model grok-4.3
The pith
MSCoT uses multi-scale coarse-to-fine token prediction to generate text-controlled human motions with higher quality and tenfold faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
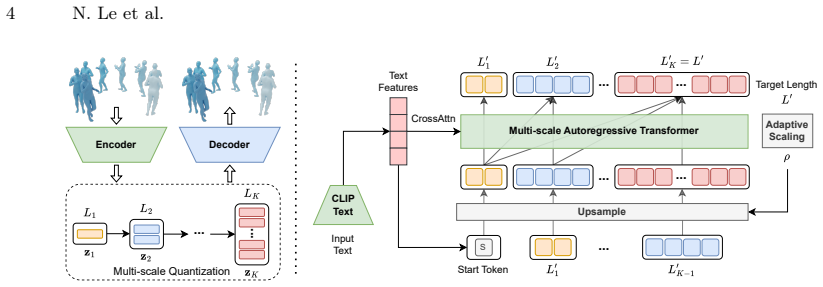
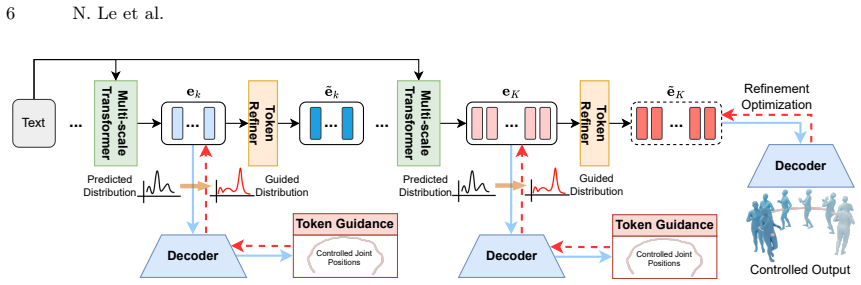
MSCoT discretizes motion into a multi-scale hierarchical representation and predicts the entire token sequence at each temporal scale in a coarse-to-fine fashion. Building on this coarse-to-fine paradigm, an efficient multi-scale token guidance strategy overcomes the challenge of discrete sampling and steers the token distribution towards the control goals, allowing for fast and flexible control. To address the limitations of a discrete codebook, a lightweight token refiner further adds continuous residuals to the discrete token embeddings and allows differentiable test-time refinement optimization to ensure precise alignment with the control objectives, producing quality motions consistent
What carries the argument
multi-scale hierarchical token representation with coarse-to-fine sequence prediction, multi-scale token guidance, and lightweight token refiner for continuous residuals
If this is right
- Produces motions consistent with control constraints at test time without modules tailored to specific signals.
- Achieves 48% improvement in motion quality measured by FID on HumanML3D.
- Reduces average control error by 61% relative to existing baselines.
- Delivers 10 times faster inference speed than diffusion-based methods on the same benchmark.
- Enables controllable text-to-motion generation that maintains naturalness while meeting arbitrary goals.
Where Pith is reading between the lines
- The coarse-to-fine token structure could be tested on longer motion sequences to check whether the speed advantage scales with sequence length.
- Similar guidance and refinement steps might apply to other discrete token tasks such as music generation if the discretization challenges are comparable.
- Real-time interactive control in animation tools becomes more practical if the inference gains hold under varying hardware conditions.
- Combining the refiner with additional loss terms could be explored to handle conflicting control signals without retraining.
Load-bearing premise
The multi-scale token guidance can reliably steer discrete token distributions toward arbitrary control goals without post-hoc dataset-specific tuning or loss of naturalness, and the refiner's continuous residuals suffice to overcome codebook discretization limits.
What would settle it
Evaluating MSCoT on the HumanML3D benchmark and observing no 48% FID improvement, no 61% reduction in average control error, or no 10x inference speedup over baselines while still matching the stated control constraints would falsify the performance claims.
Figures




read the original abstract
We present MSCoT, a multi-scale, coarse-to-fine model for test-time human motion synthesis and control. Unlike recent approaches that rely on multiple iterative denoising/token-prediction steps, or modules tailored for specific control signals, MSCoT discretizes motion into a multi-scale hierarchical representation and predicts the entire token sequence at each temporal scale in a coarse-to-fine fashion. Building on this coarse-to-fine paradigm, we propose an efficient multi-scale token guidance strategy that overcomes the challenge of discrete sampling and steers the token distribution towards the control goals, allowing for fast and flexible control. To address the limitations of a discrete codebook, a lightweight token refiner further adds continuous residuals to the discrete token embeddings and allows differentiable test-time refinement optimization to ensure precise alignment with the control objectives. MSCoT is able to produce quality motions, consistent with the control constraints, while offering substantially faster sampling than diffusion-based approaches. Experiments on popular benchmarks demonstrate state-of-the-art controllable text-to-motion generation performance of MSCoT over existing baselines, with better motion quality (48% FID improvement), higher control accuracy (-61% avg error), and $10 \times$ faster inference speed on HumanML3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MSCoT, a multi-scale coarse-to-fine model for test-time human motion synthesis and control. Motion is discretized into a hierarchical multi-scale token representation that is predicted coarse-to-fine. A multi-scale token guidance strategy steers the discrete token distribution toward control goals, and a lightweight token refiner adds continuous residuals to the embeddings to enable differentiable test-time optimization. On the HumanML3D benchmark the method is reported to achieve state-of-the-art controllable text-to-motion performance, with a 48% FID improvement, 61% reduction in average control error, and 10× faster inference relative to existing baselines.
Significance. If the reported gains are reproducible, the work would constitute a meaningful advance in efficient test-time controllable motion generation. Replacing iterative denoising with a single-pass hierarchical token prediction plus guidance yields substantial speed-ups while improving both quality and control accuracy; the combination of discrete tokens with continuous residual refinement offers a practical route around codebook discretization limits that may transfer to other discrete generative settings in computer vision.
minor comments (2)
- [Abstract] Abstract: quantitative claims (48% FID, -61% error, 10× speed) are presented without cross-references to the tables or sections that contain the supporting numbers, baseline descriptions, or error bars; adding such pointers would improve readability.
- The manuscript would benefit from an explicit statement of the exact set of baselines used for the SOTA claim and whether they were re-implemented or taken from prior reports.
Simulated Author's Rebuttal
We thank the referee for their summary, which correctly captures the core ideas and reported results of MSCoT. The positive assessment of the potential advance is appreciated. No specific major comments appear in the provided report, so we have no individual points to rebut or revise.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description frame MSCoT as an empirical architecture for multi-scale token-based motion control, with performance claims resting on benchmark results (FID, control error, inference speed) rather than any closed-form derivation or prediction step. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the text; the method is presented as a set of design choices (hierarchical discretization, token guidance, lightweight refiner) validated externally on HumanML3D and similar datasets. The central claims are therefore falsifiable via independent replication and do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Interna- tional conference on 3D vision (3DV)
Ahuja, C., Morency, L.P.: Language2pose: Natural language grounded pose forecasting. In: Interna- tional conference on 3D vision (3DV). pp. 719–728. IEEE (2019)
2019
-
[2]
In: International Conference on 3D Vision (3DV)
Aksan, E., Kaufmann, M., Cao, P., Hilliges, O.: A spatio-temporal transformer for 3d human motion prediction. In: International Conference on 3D Vision (3DV). pp. 565–574. IEEE (2021)
2021
-
[3]
In: ICLR (2024)
Bansal, A., Chu, H.M., Schwarzschild, A., Sengupta, R., Goldblum, M., Geiping, J., Goldstein, T.: Universal guidance for diffusion models. In: ICLR (2024)
2024
-
[4]
In: CVPR
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing your commands via motion diffusion in latent space. In: CVPR. pp. 18000–18010 (2023)
2023
-
[5]
In: CVPR
Dabral, R., Mughal, M.H., Golyanik, V., Theobalt, C.: Mofusion: A framework for denoising-diffusion- based motion synthesis. In: CVPR. pp. 9760–9770 (2023)
2023
-
[6]
In: ECCV
Dai, W., Chen, L.H., Wang, J., Liu, J., Dai, B., Tang, Y.: Motionlcm: Real-time controllable motion generation via latent consistency model. In: ECCV. pp. 390–408. Springer (2024)
2024
-
[7]
In: NeurIPS (2021)
Dhariwal, P., Nichol, A.Q.: Diffusion models beat GANs on image synthesis. In: NeurIPS (2021)
2021
-
[8]
In: CVPR
Diller, C., Dai, A.: Cg-hoi: Contact-guided 3d human-object interaction generation. In: CVPR. pp. 19888–19901 (2024)
2024
-
[9]
In: CVPR
Diomataris, M., Athanasiou, N., Taheri, O., Wang, X., Hilliges, O., Black, M.J.: Wandr: Intention- guided human motion generation. In: CVPR. pp. 927–936 (2024)
2024
-
[10]
In: CVPR
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: CVPR. pp. 12873–12883 (2021)
2021
-
[11]
In: CVPR
Feng, Y., Lin, J., Dwivedi, S.K., Sun, Y., Patel, P., Black, M.J.: Chatpose: Chatting about 3d human pose. In: CVPR. pp. 2093–2103 (2024)
2093
-
[12]
In: ICCV
Fragkiadaki, K., Levine, S., Felsen, P., Malik, J.: Recurrent network models for human dynamics. In: ICCV. pp. 4346–4354 (2015)
2015
-
[13]
arXiv preprint arXiv:2507.09122 , year=
Guo, C., Hwang, I., Wang, J., Zhou, B.: Snapmogen: Human motion generation from expressive texts. arXiv preprint arXiv:2507.09122 (2025)
-
[14]
In: CVPR
Guo, C., Mu, Y., Javed, M.G., Wang, S., Cheng, L.: Momask: Generative masked modeling of 3d human motions. In: CVPR. pp. 1900–1910 (2024)
1900
-
[15]
In: ICLR (2024)
Guo, C., Mu, Y., Zuo, X., Dai, P., Yan, Y., Lu, J., Cheng, L.: Generative human motion stylization in latent space. In: ICLR (2024)
2024
-
[16]
In: CVPR
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating diverse and natural 3d human motions from text. In: CVPR. pp. 5152–5161 (2022)
2022
-
[17]
In: ECCV
Guo, C., Zuo, X., Wang, S., Cheng, L.: Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts. In: ECCV. pp. 580–597. Springer (2022)
2022
-
[19]
In: ACM International Conference on Multimedia
Guo, C., Zuo, X., Wang, S., Zou, S., Sun, Q., Deng, A., Gong, M., Cheng, L.: Action2motion: Con- ditioned generation of 3d human motions. In: ACM International Conference on Multimedia. pp. 2021–2029 (2020)
2021
-
[20]
In: ICCV
Guo, Z., Hu, Z., Soh, D.W., Zhao, N.: Motionlab: Unified human motion generation and editing via the motion-condition-motion paradigm. In: ICCV. pp. 13869–13879 (2025)
2025
-
[21]
In: AAAI
Han, B., Peng, H., Dong, M., Ren, Y., Shen, Y., Xu, C.: Amd: Autoregressive motion diffusion. In: AAAI. vol. 38, pp. 2022–2030 (2024)
2022
-
[22]
In: ICLR (2024)
Han, I., Jayaram, R., Karbasi, A., Mirrokni, V., Woodruff, D., Zandieh, A.: Hyperattention: Long- context attention in near-linear time. In: ICLR (2024)
2024
-
[23]
ACM Transactions on Graphics (ToG)35(4), 1–11 (2016)
Holden, D., Saito, J., Komura, T.: A deep learning framework for character motion synthesis and editing. ACM Transactions on Graphics (ToG)35(4), 1–11 (2016)
2016
-
[24]
In: CVPR
Hong, S., Kim, C., Yoon, S., Nam, J., Cha, S., Noh, J.: Salad: Skeleton-aware latent diffusion for text-driven motion generation and editing. In: CVPR. pp. 7158–7168 (2025) Multi-scale Coarse-to-fine Modeling for Test-time Human Motion Control 15
2025
-
[25]
In: CVPR
Huang, S., Wang, Z., Li, P., Jia, B., Liu, T., Zhu, Y., Liang, W., Zhu, S.C.: Diffusion-based generation, optimization, and planning in 3d scenes. In: CVPR. pp. 16750–16761 (2023)
2023
-
[26]
In: ECCV
Huang, Y., Wan, W., Yang, Y., Callison-Burch, C., Yatskar, M., Liu, L.: Como: Controllable motion generation through language guided pose code editing. In: ECCV. pp. 180–196. Springer (2024)
2024
-
[27]
In: CVPR
Ji, B., Pan, Y., Liu, Z., Tan, S., Jin, X., Yang, X.: Pomp: Physics-consistent motion generative model through phase manifolds. In: CVPR. pp. 22690–22701 (2025)
2025
-
[28]
In: NeurIPS (2023)
Jiang, B.,Chen,X.,Liu,W.,Yu,J.,Yu,G., Chen,T.:Motiongpt:Humanmotionasaforeignlanguage. In: NeurIPS (2023)
2023
-
[29]
arXiv preprint arXiv:2501.19083 (2025)
Jiang, L., Wei, Y., Ni, H.: Motionpcm: Real-time motion synthesis with phased consistency model. arXiv preprint arXiv:2501.19083 (2025)
-
[30]
In: CVPR
Jiang, N., Zhang, Z., Li, H., Ma, X., Wang, Z., Chen, Y., Liu, T., Zhu, Y., Huang, S.: Scaling up dynamic human-scene interaction modeling. In: CVPR. pp. 1737–1747 (2024)
2024
-
[31]
In: CVPR
Kanazawa, A., Zhang, J.Y., Felsen, P., Malik, J.: Learning 3d human dynamics from video. In: CVPR. pp. 5614–5623 (2019)
2019
-
[32]
In: ICLR (2018)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of GANs for improved quality, sta- bility, and variation. In: ICLR (2018)
2018
-
[33]
In: CVPR
Karunratanakul, K., Preechakul, K., Aksan, E., Beeler, T., Suwajanakorn, S., Tang, S.: Optimizing diffusion noise can serve as universal motion priors. In: CVPR. pp. 1334–1345 (2024)
2024
-
[34]
In: ICCV
Karunratanakul, K., Preechakul, K., Suwajanakorn, S., Tang, S.: Guided motion diffusion for control- lable human motion synthesis. In: ICCV. pp. 2151–2162 (2023)
2023
-
[35]
In: CVPR
Kim, B., Jeong, H.I., Sung, J., Cheng, Y., Lee, J., Chang, J.Y., Choi, S.I., Choi, Y., Shin, S., Kim, J., et al.: Personabooth: Personalized text-to-motion generation. In: CVPR. pp. 22756–22765 (2025)
2025
-
[36]
In: ICCV
Kong, H., Gong, K., Lian, D., Mi, M.B., Wang, X.: Priority-centric human motion generation in discrete latent space. In: ICCV. pp. 14806–14816 (2023)
2023
-
[37]
In: CVPR
Kulkarni, N., Rempe, D., Genova, K., Kundu, A., Johnson, J., Fouhey, D., Guibas, L.: Nifty: Neural object interaction fields for guided human motion synthesis. In: CVPR. pp. 947–957 (2024)
2024
-
[38]
In: CVPR
Lee, D., Kim, C., Kim, S., Cho, M., Han, W.S.: Autoregressive image generation using residual quan- tization. In: CVPR. pp. 11523–11532 (2022)
2022
-
[39]
In: ECCV
Li, J., Clegg, A., Mottaghi, R., Wu, J., Puig, X., Liu, C.K.: Controllable human-object interaction synthesis. In: ECCV. pp. 54–72. Springer (2024)
2024
-
[40]
In: ICCV
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Ai choreographer: Music conditioned 3d dance generation with aist++. In: ICCV. pp. 13401–13412 (2021)
2021
-
[41]
In: ICLR (2025)
Li, Z., Yuan, W., HE, Y., Qiu, L., Zhu, S., Gu, X., Shen, W., Dong, Y., Dong, Z., Yang, L.T.: LaMP: Language-motion pretraining for motion generation, retrieval, and captioning. In: ICLR (2025)
2025
-
[42]
In: ICCV
Li, Z., Luo, M., Hou, R., Zhao, X., Liu, H., Chang, H., Liu, Z., Li, C.: Morph: A motion-free physics optimization framework for human motion generation. In: ICCV. pp. 14580–14589 (2025)
2025
-
[43]
In: CVPR
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: CVPR. pp. 2117–2125 (2017)
2017
-
[44]
In: CVPR
Liu, H., Zhan, X., Huang, S., Mu, T.J., Shan, Y.: Programmable motion generation for open-set motion control tasks. In: CVPR. pp. 1399–1408 (2024)
2024
-
[45]
In: ICLR (2019),https : / / openreview.net/forum?id=Bkg6RiCqY7
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019),https : / / openreview.net/forum?id=Bkg6RiCqY7
2019
-
[46]
In: CVPR
Lu, S., Wang, J., Lu, Z., Chen, L.H., Dai, W., Dong, J., Dou, Z., Dai, B., Zhang, R.: Scamo: Exploring the scaling law in autoregressive motion generation model. In: CVPR. pp. 27872–27882 (2025)
2025
-
[47]
In: ECCV
Lucas, T., Baradel, F., Weinzaepfel, P., Rogez, G.: Posegpt: Quantization-based 3d human motion generation and forecasting. In: ECCV. pp. 417–435. Springer (2022)
2022
-
[48]
In: ICCV
Luo, Z., Cao, J., Kitani, K., Xu, W., et al.: Perpetual humanoid control for real-time simulated avatars. In: ICCV. pp. 10895–10904 (2023)
2023
-
[49]
Journal of Machine Learning Research 9(86), 2579–2605 (2008) 16 N
van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Research 9(86), 2579–2605 (2008) 16 N. Le et al
2008
-
[50]
In: ICCV
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: Archive of motion capture as surface shapes. In: ICCV. pp. 5442–5451 (2019)
2019
-
[51]
In: ICCV
Mao, W., Liu, M., Salzmann, M., Li, H.: Learning trajectory dependencies for human motion predic- tion. In: ICCV. pp. 9489–9497 (2019)
2019
-
[52]
In: CVPR
Meng, Z., Xie, Y., Peng, X., Han, Z., Jiang, H.: Rethinking diffusion for text-driven human motion generation: Redundant representations, evaluation, and masked autoregression. In: CVPR. pp. 27859– 27871 (2025)
2025
-
[53]
In: ICLR (2024)
Mentzer, F., Minnen, D., Agustsson, E., Tschannen, M.: Finite scalar quantization: VQ-VAE made simple. In: ICLR (2024)
2024
-
[54]
ACM Transactions On Graphics (TOG)37(4), 1–14 (2018)
Peng, X.B., Abbeel, P., Levine, S., Van de Panne, M.: Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Transactions On Graphics (TOG)37(4), 1–14 (2018)
2018
-
[55]
ACM Transactions on Graphics (ToG)40(4), 1–20 (2021)
Peng, X.B., Ma, Z., Abbeel, P., Levine, S., Kanazawa, A.: Amp: Adversarial motion priors for stylized physics-based character control. ACM Transactions on Graphics (ToG)40(4), 1–20 (2021)
2021
-
[56]
In: ICCV
Petrovich, M., Black, M.J., Varol, G.: Action-conditioned 3d human motion synthesis with transformer vae. In: ICCV. pp. 10985–10995 (2021)
2021
-
[57]
In: ECCV
Petrovich, M., Black, M.J., Varol, G.: Temos: Generating diverse human motions from textual de- scriptions. In: ECCV. pp. 480–497. Springer (2022)
2022
-
[58]
In: ICCV
Pinyoanuntapong, E., Saleem, M., Karunratanakul, K., Wang, P., Xue, H., Chen, C., Guo, C., Cao, J., Ren, J., Tulyakov, S.: Maskcontrol: Spatio-temporal control for masked motion synthesis. In: ICCV. pp. 9955–9965 (2025)
2025
-
[59]
In: CVPR
Pinyoanuntapong, E., Wang, P., Lee, M., Chen, C.: Mmm: Generative masked motion model. In: CVPR. pp. 1546–1555 (2024)
2024
-
[60]
Big data4(4), 236–252 (2016)
Plappert, M., Mandery, C., Asfour, T.: The kit motion-language dataset. Big data4(4), 236–252 (2016)
2016
-
[61]
In: CVPR
Raab, S., Leibovitch, I., Li, P., Aberman, K., Sorkine-Hornung, O., Cohen-Or, D.: Modi: Unconditional motion synthesis from diverse data. In: CVPR. pp. 13873–13883 (2023)
2023
-
[62]
In: ICML
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML. pp. 8748–8763 (2021)
2021
-
[63]
In: ICCV
Rempe, D., Birdal, T., Hertzmann, A., Yang, J., Sridhar, S., Guibas, L.J.: Humor: 3d human motion model for robust pose estimation. In: ICCV. pp. 11488–11499 (2021)
2021
-
[64]
In: CVPR
Rempe, D., Luo, Z., Bin Peng, X., Yuan, Y., Kitani, K., Kreis, K., Fidler, S., Litany, O.: Trace and pace: Controllable pedestrian animation via guided trajectory diffusion. In: CVPR. pp. 13756–13766 (2023)
2023
-
[65]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmenta- tion. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 234–241. Springer (2015)
2015
-
[66]
An overview of gradient descent optimization algorithms
Ruder, S.: An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[67]
In: ICLR (2024)
Shafir, Y., Tevet, G., Kapon, R., Bermano, A.H.: Human motion diffusion as a generative prior. In: ICLR (2024)
2024
-
[68]
In: ICCV
Shi, M., Starke, S., Ye, Y., Komura, T., Won, J.: Phasemp: Robust 3d pose estimation via phase- conditioned human motion prior. In: ICCV. pp. 14725–14737 (2023)
2023
-
[69]
ACM Transactions on Graphics (TOG)43(4), 1–14 (2024)
Shi, Y., Wang, J., Jiang, X., Lin, B., Dai, B., Peng, X.B.: Interactive character control with auto- regressive motion diffusion models. ACM Transactions on Graphics (TOG)43(4), 1–14 (2024)
2024
-
[70]
In: CVPR
Siyao,L.,Yu,W.,Gu,T.,Lin,C.,Wang,Q.,Qian,C.,Loy,C.C.,Liu,Z.:Bailando:3ddancegeneration by actor-critic gpt with choreographic memory. In: CVPR. pp. 11050–11059 (2022)
2022
-
[71]
In: CVPR
Song, W., Jin, X., Li, S., Chen, C., Hao, A., Hou, X., Li, N., Qin, H.: Arbitrary motion style transfer with multi-condition motion latent diffusion model. In: CVPR. pp. 821–830 (2024)
2024
-
[72]
In: CVPR
Taheri, O., Choutas, V., Black, M.J., Tzionas, D.: Goal: Generating 4d whole-body motion for hand- object grasping. In: CVPR. pp. 13263–13273 (2022) Multi-scale Coarse-to-fine Modeling for Test-time Human Motion Control 17
2022
-
[73]
In: ICLR (2025)
Tan, W., Li, B., Jin, C., Huang, W., Wang, X., Song, R.: Think then react: Towards unconstrained action-to-reaction motion generation. In: ICLR (2025)
2025
-
[74]
In: ICLR (2025)
Tevet, G., Raab, S., Cohan, S., Reda, D., Luo, Z., Peng, X.B., Bermano, A.H., van de Panne, M.: CLoSD: Closing the loop between simulation and diffusion for multi-task character control. In: ICLR (2025)
2025
-
[75]
In: ICLR (2023)
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. In: ICLR (2023)
2023
-
[76]
NeurIPS37, 84839–84865 (2024)
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalable image generation via next-scale prediction. NeurIPS37, 84839–84865 (2024)
2024
-
[77]
In: CVPR
Tseng, J., Castellon, R., Liu, K.: Edge: Editable dance generation from music. In: CVPR. pp. 448–458 (2023)
2023
-
[78]
In: NeurIPS (2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. In: NeurIPS (2017)
2017
-
[79]
In: NeurIPS (2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: NeurIPS (2017)
2017
-
[80]
Foundations and Trends in Machine Learning1(1-2), 1–305 (2008)
Wainwright, M.J., Jordan, M.I.: Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning1(1-2), 1–305 (2008)
2008
-
[81]
In: ECCV
Wan, W., Dou, Z., Komura, T., Wang, W., Jayaraman, D., Liu, L.: Tlcontrol: Trajectory and language control for human motion synthesis. In: ECCV. pp. 37–54. Springer (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.