Offline Reinforcement Learning for Plasma Control in Nuclear Fusion: Codebase and Benchmark
Pith reviewed 2026-06-30 18:25 UTC · model grok-4.3
The pith
Offline model-based RL methods achieve the best average performance on most plasma control objectives in a new fusion benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
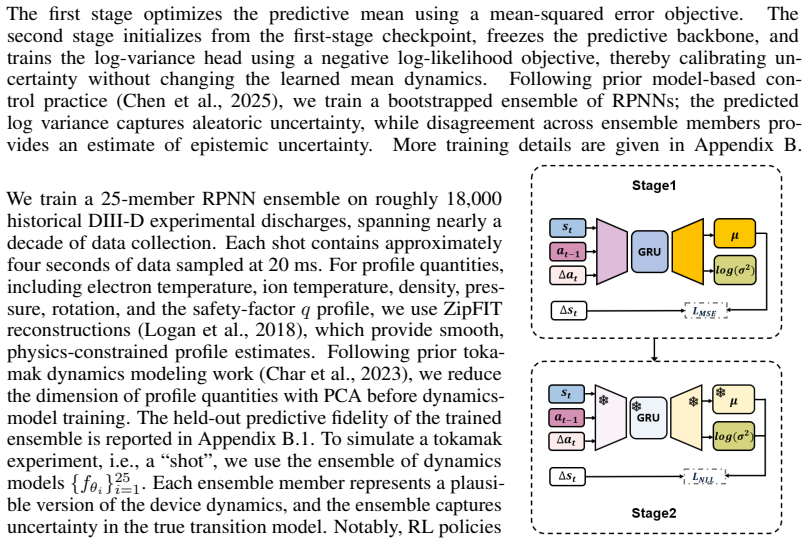
The paper establishes that offline model-based RL methods obtain the best average performance on most objectives, although no single method dominates all tasks, when evaluated on the RL4F benchmark for four full-profile tracking tasks whose dynamics are learned from historical DIII-D discharge data.
What carries the argument
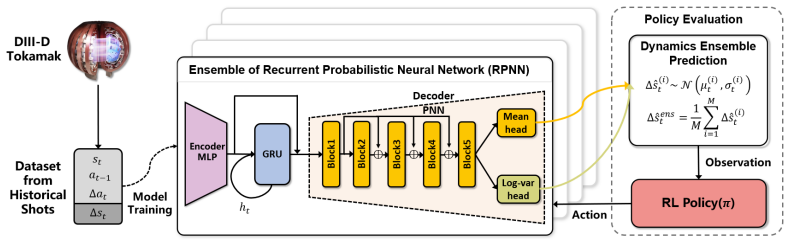
RL4F benchmark consisting of closed-loop simulation environments built from DIII-D historical data for multi-actuator, long-horizon plasma profile control.
If this is right
- Model-based offline RL should be the default starting point for long-horizon plasma control design.
- Explicit dynamics modeling improves reliability when rewards are sparse and horizons are long.
- Algorithm choice must remain task-dependent because no method wins on every profile objective.
- The released environments and datasets create a reproducible testbed for both fusion control and general offline RL research.
Where Pith is reading between the lines
- The benchmark could shorten the path from data to deployable controllers by letting researchers iterate entirely offline before any hardware test.
- Similar data-driven benchmarks might be created for other high-stakes control domains where online trials are prohibitive.
- Extending the environments with uncertainty estimates on the learned dynamics could expose which model-based methods are most robust to model error.
- The four tasks together form a natural multi-objective test suite that could drive development of algorithms that balance competing plasma objectives.
Load-bearing premise
The dynamics model learned from past DIII-D discharges is accurate enough to support valid comparisons among controllers intended for real tokamaks.
What would settle it
Transfer a controller trained inside the RL4F environment to the physical DIII-D device and check whether its measured performance matches the simulated ranking or deviates sharply.
Figures
read the original abstract
Offline reinforcement learning (RL) offers a promising route for developing plasma controllers from historical tokamak data, since online trial-and-error on real devices is costly and risky. However, progress in this direction remains difficult to measure due to the lack of a standardized offline RL benchmark for realistic multi-actuator, long-horizon plasma control problems in nuclear fusion. We introduce RL4F, an Offline Reinforcement Learning Benchmark for Plasma Control in Nuclear Fusion, providing closed-loop evaluation environments and baseline comparisons across four full-profile tracking tasks: rotation, density, temperature, and pressure. The dynamics function underlying the evaluation environment is built from historical discharge data from DIII-D, a real-world Tokamak. We evaluate a broad set of imitation learning and offline RL baselines under a unified protocol. We find that offline model-based RL methods obtain the best average performance on most objectives, although no single method dominates all tasks, highlighting the importance of dynamics modeling in complex, long-horizon plasma control tasks. To foster further research, we open-source the codebase, datasets, and evaluation framework, providing a benchmark not only for the fusion community but also for algorithm development in offline RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RL4F, an offline RL benchmark for plasma control in nuclear fusion. It supplies closed-loop evaluation environments derived from historical DIII-D discharge data for four full-profile tracking tasks (rotation, density, temperature, pressure), evaluates a range of imitation learning and offline RL baselines under a unified protocol, and reports that offline model-based RL methods achieve the best average performance on most objectives. The codebase, datasets, and evaluation framework are open-sourced.
Significance. If the empirical results hold, the work supplies a much-needed standardized benchmark for offline RL on realistic, long-horizon, multi-actuator control problems drawn from a high-stakes physical domain. The explicit open-sourcing of code, data, and environments is a concrete strength that supports reproducibility and further algorithm development.
major comments (2)
- [Abstract / Evaluation Environment] Abstract and Evaluation Environment description: the central claim that model-based offline RL methods obtain the best average performance rests on the learned dynamics function being a faithful proxy for real tokamak behavior, yet no multi-step prediction error, held-out trajectory validation, or comparison against an independent physics simulator is reported; this leaves open the possibility that reported gains arise from exploitation of model errors rather than genuine control improvement.
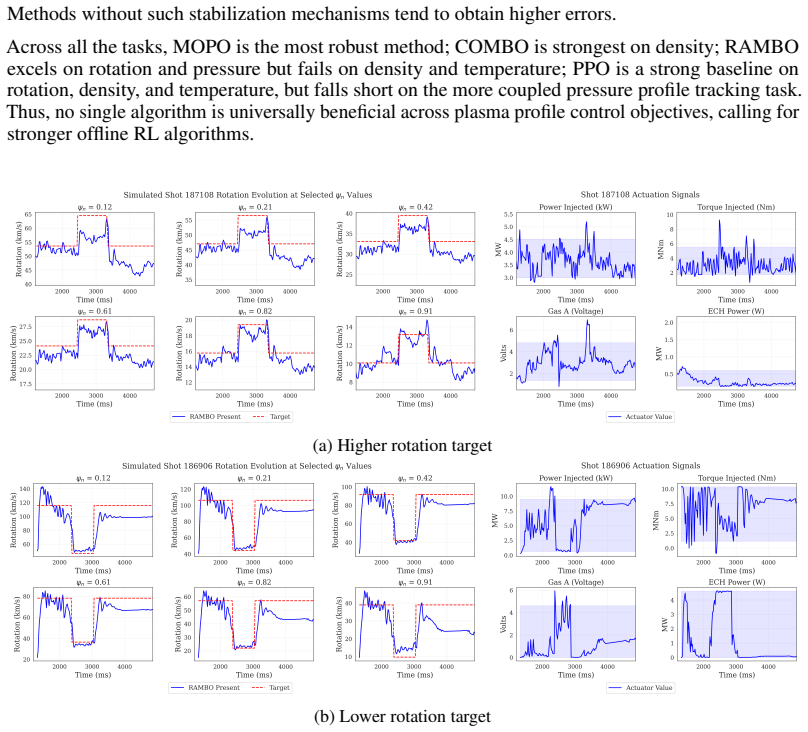
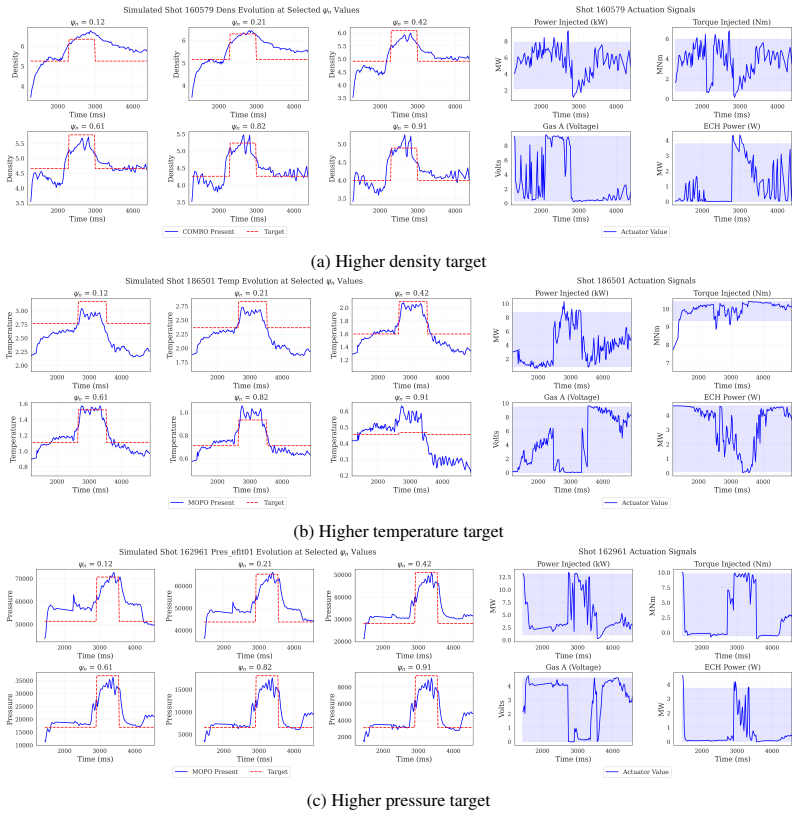
- [Results] Results section (comparative tables): performance differences are presented as averages without reported statistical significance tests, confidence intervals, or variance across random seeds, making it difficult to determine whether model-based methods reliably outperform baselines on the stated tasks.
minor comments (1)
- [§3] The notation for the four profile-tracking objectives could be introduced with explicit mathematical definitions earlier in the manuscript to improve readability for readers outside the fusion community.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the presentation of our benchmark. We address each major comment below and commit to revisions that improve the manuscript's rigor without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract / Evaluation Environment] Abstract and Evaluation Environment description: the central claim that model-based offline RL methods obtain the best average performance rests on the learned dynamics function being a faithful proxy for real tokamak behavior, yet no multi-step prediction error, held-out trajectory validation, or comparison against an independent physics simulator is reported; this leaves open the possibility that reported gains arise from exploitation of model errors rather than genuine control improvement.
Authors: We appreciate this observation on the need for explicit validation of the learned dynamics. The evaluation environments are constructed from real DIII-D discharge data to create a standardized benchmark for offline RL, but we agree that reporting model fidelity metrics would address concerns about potential exploitation of model inaccuracies. In the revised manuscript we will add multi-step prediction errors evaluated on held-out trajectories. A direct comparison against an independent physics simulator is outside the scope of this work, which focuses on data-driven benchmarks rather than hybrid physics-ML validation; we will note this explicitly as a limitation and avenue for future research. revision: partial
-
Referee: [Results] Results section (comparative tables): performance differences are presented as averages without reported statistical significance tests, confidence intervals, or variance across random seeds, making it difficult to determine whether model-based methods reliably outperform baselines on the stated tasks.
Authors: We concur that statistical reporting is necessary to support claims of performance differences. In the revised manuscript we will rerun all baseline evaluations across multiple random seeds, report means with standard deviations and 95% confidence intervals in the tables, and include statistical significance tests (such as paired t-tests with appropriate corrections) to quantify whether observed differences are reliable. revision: yes
Circularity Check
Empirical benchmark release with no derivations or self-referential predictions
full rationale
The paper presents RL4F as an open benchmark for offline RL on plasma control tasks, built from historical DIII-D discharge data. It evaluates imitation learning and offline RL baselines under a unified protocol and reports that model-based methods obtain the best average performance on most objectives. No mathematical derivations, first-principles predictions, or equations are claimed; the central result is an empirical comparison of algorithm performance on fixed evaluation environments. No self-citations, fitted parameters renamed as predictions, or ansatzes appear in the load-bearing steps. The work is self-contained as a dataset and codebase release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical discharge data from DIII-D can be used to construct a dynamics model suitable for closed-loop simulation and controller evaluation.
Reference graph
Works this paper leans on
-
[1]
T., Tassa, Y ., Munos, R., Heess, N., and Riedmiller, M
Abdolmaleki, A., Springenberg, J. T., Tassa, Y ., Munos, R., Heess, N., and Riedmiller, M. (2018). Maximum a posteriori policy optimisation. InInternational Conference on Learning Representa- tions
2018
-
[2]
An, G., Moon, S., Kim, J.-H., and Song, H. O. (2021). Uncertainty-based offline reinforcement learning with diversified Q-ensemble. InAdvances in Neural Information Processing Systems, volume 34, pages 7436–7447. Curran Associates, Inc
2021
-
[3]
E., Wehner, W
Barton, J. E., Wehner, W. P., Schuster, E., Felici, F., and Sauter, O. (2015). Simultaneous closed-loop control of the current profile and the electron temperature profile in the tcv tokamak. In2015 American Control Conference (ACC), pages 3316–3321
2015
-
[4]
(2021).Development of free-boundary equilibrium and transport solvers for simulation and real-time interpretation of tokamak experiments
Carpanese, F. (2021).Development of free-boundary equilibrium and transport solvers for simulation and real-time interpretation of tokamak experiments. PhD thesis, EPFL, Lausanne
2021
-
[5]
R., Görler, T., and contributors, J
Chapman-Oplopoiou, B., Walker, J., Hatch, D. R., Görler, T., and contributors, J. (2025). Composition of electron temperature gradient driven plasma turbulence in jet-ilw tokamak plasmas.Phys. Rev. Res., 7:L012004
2025
-
[6]
Char, I., Abbate, J., Bardoczi, L., Boyer, M., Chung, Y ., Conlin, R., Erickson, K., Mehta, V ., Richner, N., Kolemen, E., and Schneider, J. (2023). Offline model-based reinforcement learning for tokamak control. In Matni, N., Morari, M., and Pappas, G. J., editors,Proceedings of The 5th Annual Learning for Dynamics and Control Conference, volume 211 ofPr...
2023
-
[7]
Chen, J., Xu, L., Chen, W., and Schneider, J. (2026). Bayes adaptive monte carlo tree search for offline model-based reinforcement learning. InInternational Conference on Learning Representations. Poster
2026
-
[8]
Chen, J., Xu, L., Venugopal, A., and Schneider, J. (2025). Policy-driven world model adaptation for robust offline model-based reinforcement learning
2025
-
[9]
Chua, K., Calandra, R., McAllister, R., and Levine, S. (2018). Deep reinforcement learning in a handful of trials using probabilistic dynamics models
2018
-
[10]
Citrin, J., Goodfellow, I., Raju, A., Chen, J., Degrave, J., Donner, C., Felici, F., Hamel, P., Huber, A., Nikulin, D., Pfau, D., Tracey, B., Riedmiller, M., and Kohli, P. (2024). TORAX: A fast and differentiable tokamak transport simulator in JAX
2024
-
[11]
Riedmiller, M. (2022). Magnetic control of tokamak plasmas through deep reinforcement learning. Nature, 602(7897):414–419
2022
-
[12]
Ding, Y ., Florensa, C., Abbeel, P., and Phielipp, M. (2019). Goal-conditioned imitation learning. InAdvances in Neural Information Processing Systems, volume 32, pages 15298–15309. Curran
2019
-
[13]
Emdee, E., Horvath, L., Bortolon, A., and Wilkie, G. (2024). The influence of rotation and sol drifts on poloidal asymmetries of pedestal fueling. InAPS Division of Plasma Physics Meeting Abstracts, volume 2024, pages GO06–014
2024
-
[14]
P., Goodman, T
Felici, F., Sauter, O., Coda, S., Duval, B. P., Goodman, T. P., Moret, J.-M., and Paley, J. I. (2011). Real-time physics-model-based simulation of the current density profile in tokamak plasmas. Nuclear Fusion, 51(8):083052. 10
2011
-
[15]
and Gu, S
Fujimoto, S. and Gu, S. S. (2021). A minimalist approach to offline reinforcement learning. In Advances in Neural Information Processing Systems, volume 34, pages 20132–20145. Curran
2021
-
[16]
Gi, K., Sano, F., Akimoto, K., Hiwatari, R., and Tobita, K. (2020). Potential contribution of fusion power generation to low-carbon development under the paris agreement and associated uncertainties.Energy Strategy Reviews, 27:100432
2020
-
[17]
Greenwald, M. (2002). Density limits in toroidal plasmas.Plasma Physics and Controlled Fusion, 44(8):R27–R53
2002
-
[18]
J., Paduraru, C., Dulac-Arnold, G., Li, J., Norouzi, M., Hoffman, M., Heess, N., and de Freitas, N
Mankowitz, D. J., Paduraru, C., Dulac-Arnold, G., Li, J., Norouzi, M., Hoffman, M., Heess, N., and de Freitas, N. (2020). Rl unplugged: A suite of benchmarks for offline reinforcement learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H., editors,Advances in Neural Information Processing Systems, volume 33, pages 7248–7259. Curran...
2020
-
[19]
Kostrikov, I., Nair, A., and Levine, S. (2022). Offline reinforcement learning with implicit Q-learning. InInternational Conference on Learning Representations
2022
-
[20]
Kumar, A., Zhou, A., Tucker, G., and Levine, S. (2020). Conservative Q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 33, pages 1179–1191. Curran Associates, Inc
2020
-
[21]
Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline reinforcement learning: Tutorial, review, and perspectives on open problems
2020
-
[22]
P., Hunt, J
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y ., Silver, D., and Wierstra, D. (2016). Continuous control with deep reinforcement learning. InInternational Conference on Learning Representations
2016
-
[23]
Liu, Z., Guo, Z., Lin, H., Yao, Y ., Zhu, J., Cen, Z., Hu, H., Yu, W., Zhang, T., Tan, J., and Zhao, D. (2023). Datasets and benchmarks for offline safe reinforcement learning
2023
-
[24]
C., Grierson, B
Logan, N. C., Grierson, B. A., Haskey, S. R., Smith, S. P., Meneghini, O., and Eldon, D. (2018). OMFIT tokamak profile data fitting and physics analysis.Fusion Science and Technology, 74(1- 2):125–134
2018
-
[25]
Lyu, J., Ma, X., Li, X., and Lu, Z. (2022). Mildly conservative Q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 35, pages 1711–1724. Curran Associates, Inc
2022
-
[26]
Real-time control of the q-profile in jet for steady state advanced tokamak operation.Nuclear Fusion, 43(9):870
Zastrow, K., and contributors to the EFDA-JET Workprogramme (2003). Real-time control of the q-profile in jet for steady state advanced tokamak operation.Nuclear Fusion, 43(9):870
2003
-
[27]
Park, S., Frans, K., Eysenbach, B., and Levine, S. (2025). OGBench: Benchmarking offline goal- conditioned RL. InThe Thirteenth International Conference on Learning Representations
2025
-
[28]
Qin, R.-J., Zhang, X., Gao, S., Chen, X.-H., Li, Z., Zhang, W., and Yu, Y . (2022). Neorl: A near real-world benchmark for offline reinforcement learning. In Koyejo, S., Mohamed, S., Agarwal, A.,
2022
-
[29]
Richner, N., Bardóczi, L., Callen, J., La Haye, R., Logan, N., and Strait, E. (2024). Use of differential plasma rotation to prevent disruptive tearing mode onset from 3-wave coupling.Nuclear Fusion, 64(10):106036. 11
2024
-
[30]
Rigter, M., Lacerda, B., and Hawes, N. (2022). RAMBO-RL: Robust adversarial model-based offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 35, pages 16082–16097. Curran Associates, Inc
2022
-
[31]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms
2017
-
[32]
Seo, J., Kim, S., Jalalvand, A., Conlin, R., Rothstein, A., Abbate, J., Erickson, K., Wai, J., Shousha, R., and Kolemen, E. (2024). Avoiding fusion plasma tearing instability with deep reinforcement learning.Nature, 626(8000):746–751
2024
-
[33]
Sonker, R., Capone, A., Rothstein, A., Kaga, H. J. F., Kolemen, E., and Schneider, J. (2025). Multi-timescale dynamics model bayesian optimization for plasma stabilization in tokamaks. In F orty-second International Conference on Machine Learning
2025
-
[34]
Sonker, R., Kaga, H. J. F., Chen, J., Rothstein, A., Char, I., Shousha, R., Kolemen, E., and Schneider, J. (2026). Offline reinforcement learning for rotation profile control in tokamaks
2026
-
[35]
Strait, E. (1994). Stability of high beta tokamak plasmas.Physics of Plasmas, 1(5):1415–1431
1994
-
[36]
Sun, Y ., Zhang, J., Jia, C., Lin, H., Ye, J., and Yu, Y . (2023). Model-Bellman inconsistency for model-based offline reinforcement learning. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B.,
2023
-
[37]
J., Riedmiller, M., and The TCV Team (2024)
Donner, C., Galperti, C., Buchli, J., Neunert, M., Huber, A., Evens, J., Kurylowicz, P., Mankowitz, D. J., Riedmiller, M., and The TCV Team (2024). Towards practical reinforcement learning for tokamak magnetic control.Fusion Engineering and Design, 200:114161
2024
-
[38]
Walker, M. L. and Humphreys, D. A. (2006). Valid coordinate systems for linearized plasma shape response models in tokamaks.Fusion Science and Technology, 50(4):473–489
2006
-
[39]
M., Rea, C., So, O., Dawson, C., Garnier, D
Wang, A. M., Rea, C., So, O., Dawson, C., Garnier, D. T., and Fan, C. (2025). Active ramp-down control and trajectory design for tokamaks with neural differential equations and reinforcement learning.Communications Physics, 8(1):231
2025
-
[40]
Wang, Z., Wang, H., Schuster, E., Luo, Z., Huang, Y ., Yuan, Q., Xiao, B., and Humphreys, D. (2021). Optimal shaping of the safety factor profile in the east tokamak. In2021 IEEE Conference on Control Technology and Applications (CCTA), pages 63–68
2021
-
[41]
M., Horvath, L., Chang, C
Wilkie, G., Laggner, F., Hager, R., Rosenthal, A., Ku, S.-H., Churchill, R. M., Horvath, L., Chang, C. S., and Bortolon, A. (2024). Reconstruction and interpretation of ionization asymmetry in magnetic confinement via synthetic diagnostics.Nuclear Fusion, 64(8):086028
2024
-
[42]
Yu, T., Kumar, A., Rafailov, R., Rajeswaran, A., Levine, S., and Finn, C. (2021). COMBO: Conser- vative offline model-based policy optimization. InAdvances in Neural Information Processing Systems, volume 34, pages 28954–28967. Curran Associates, Inc
2021
-
[43]
Y ., Levine, S., Finn, C., and Ma, T
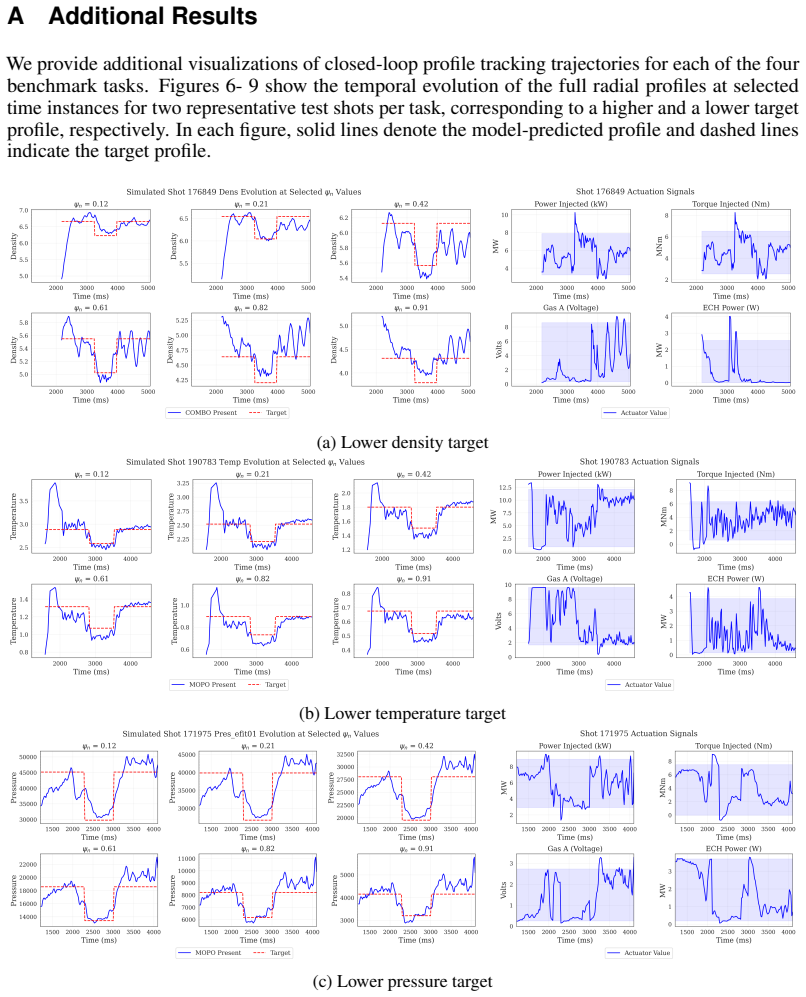
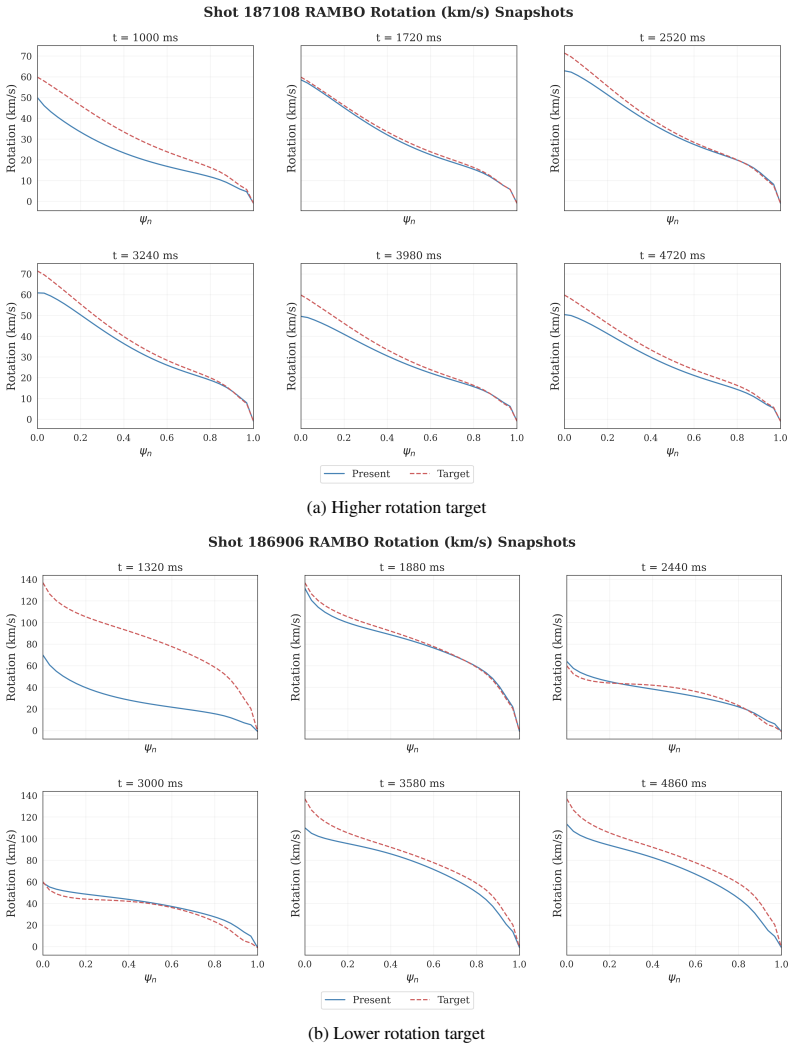
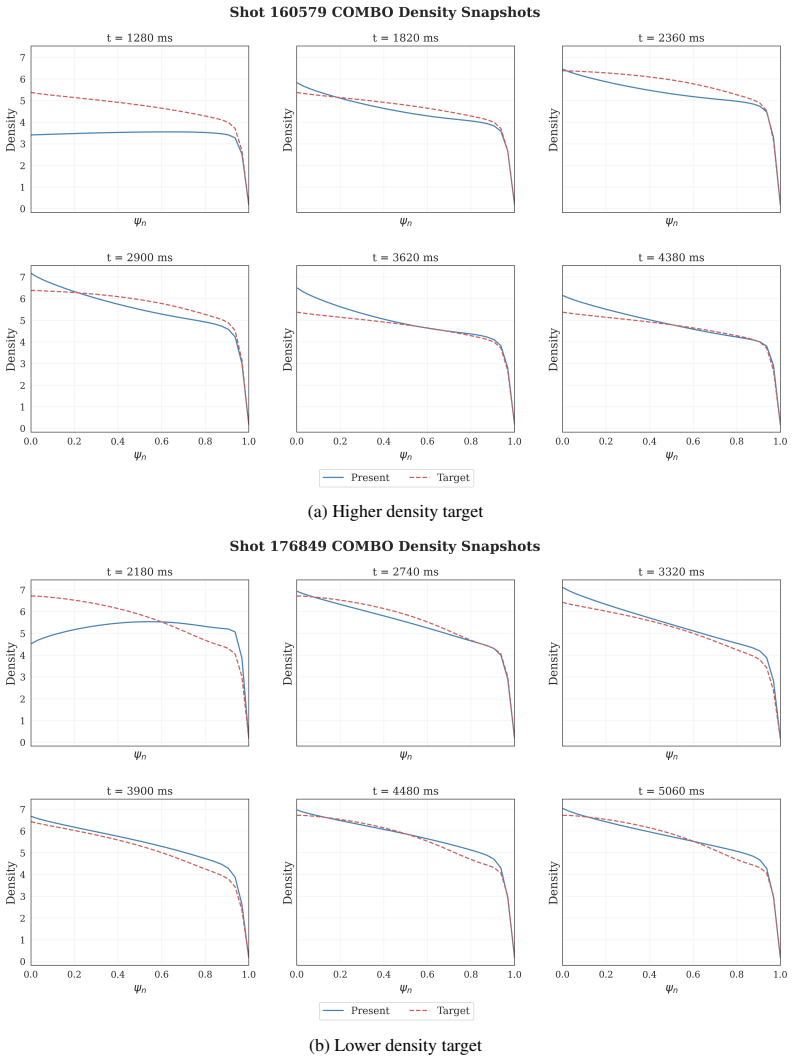
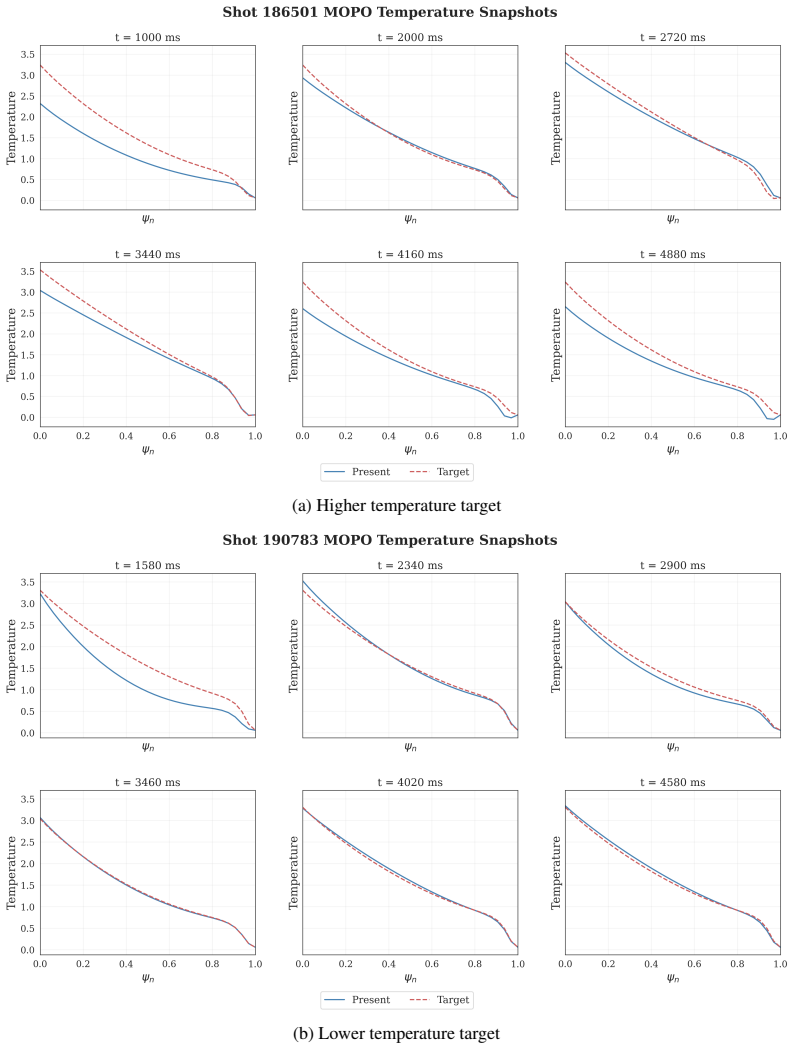
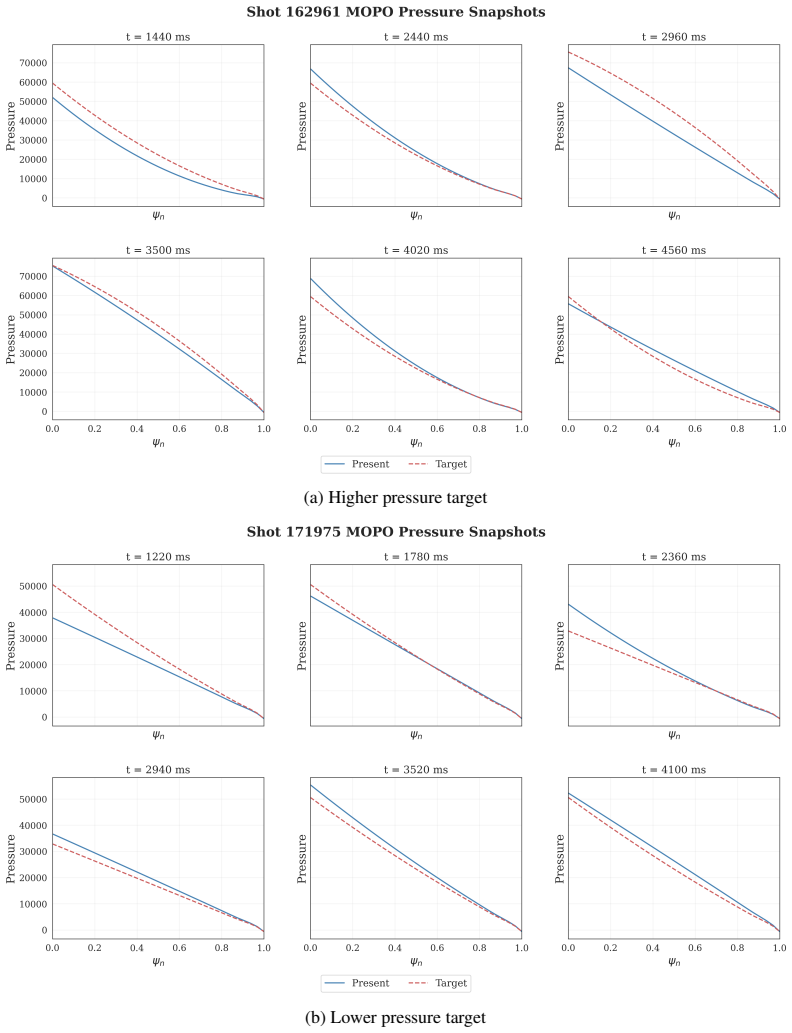
Yu, T., Thomas, G., Yu, L., Ermon, S., Zou, J. Y ., Levine, S., Finn, C., and Ma, T. (2020). MOPO: Model-based offline policy optimization. InAdvances in Neural Information Processing Systems, volume 33, pages 14129–14142. Curran Associates, Inc. 12 A Additional Results We provide additional visualizations of closed-loop profile tracking trajectories for ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.