MosaicKV: Serving Long-Context LLM with Dynamic Two-D KV Cache Compression
Pith reviewed 2026-07-02 16:10 UTC · model grok-4.3
The pith
MosaicKV applies dynamic two-dimensional compression to the KV cache by selecting important elements per vector and managing compressed segments to cut memory and speed up long-context LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
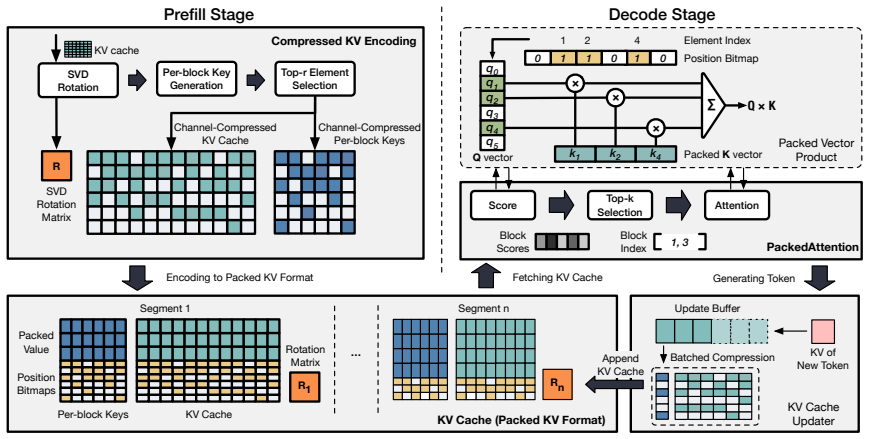
MosaicKV is a serving system that performs dynamic two-D KV cache compression by identifying important elements for each KV vector and selecting compression strategies at the granularity of KV cache segments; it further introduces compressed KV cache management that uses underutilized GPU and CPU resources to maintain the compressed caches and accelerate attention computation, achieving up to 16x attention speedup, 4.8x lower decode latency, 7.3x higher throughput, and 3x lower memory use with 1.76 percent average accuracy loss on LongBench and RULER.
What carries the argument
Dynamic two-D compression with per-KV-vector importance identification and segment-granularity strategy selection, plus compressed KV cache management that offloads maintenance to spare resources.
If this is right
- Attention computation runs up to 16 times faster than the uncompressed baseline.
- Decode latency drops by a factor of 4.8 while throughput rises by a factor of 7.3.
- Memory footprint of the KV cache shrinks by a factor of 3.
- Accuracy loss stays at 1.76 percent on average across LongBench and RULER.
Where Pith is reading between the lines
- The same segment-level selection logic could be tested on other attention variants such as grouped-query attention.
- If the non-uniform distribution holds across model scales, the technique might reduce the hardware needed for context lengths beyond one million tokens.
- Combining the compressed-cache management with existing quantization methods could produce further memory savings without additional accuracy experiments.
Load-bearing premise
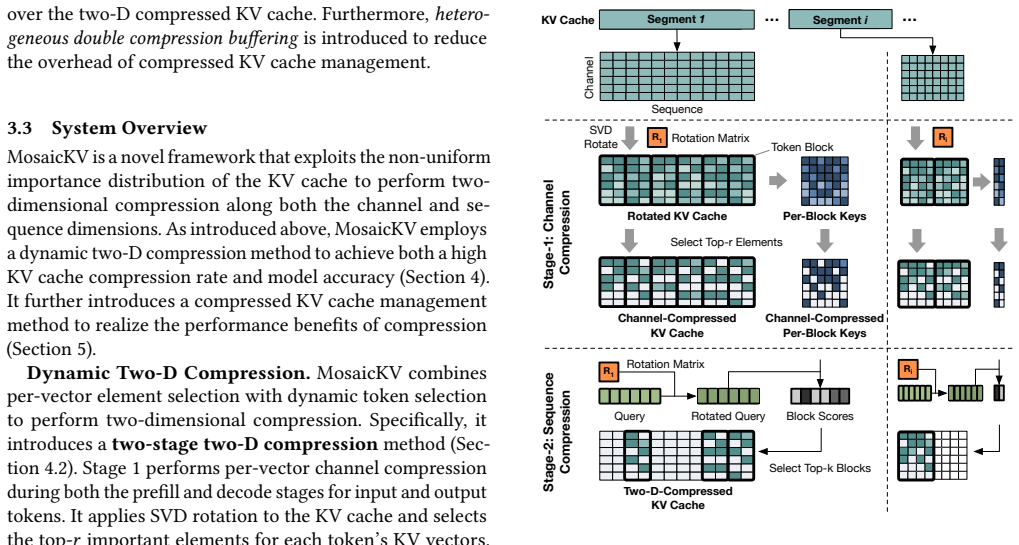
The non-uniform importance distribution of elements within the KV cache allows per-segment dynamic selection of compression strategies that preserve accuracy.
What would settle it
Measuring accuracy on LongBench and RULER after applying MosaicKV and finding average loss well above 1.76 percent, or measuring decode latency and throughput on an H800 GPU and finding no improvement over the uncompressed baseline.
Figures

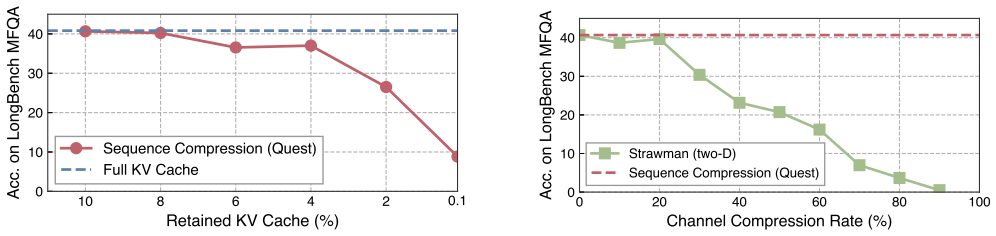
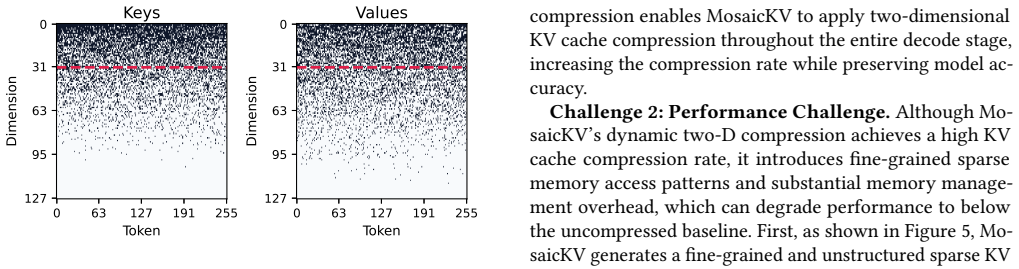
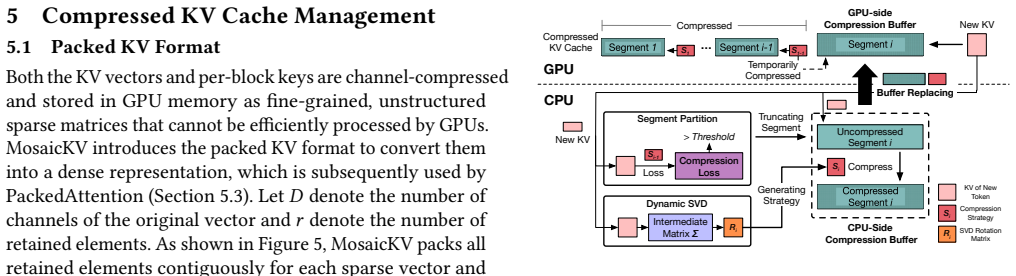



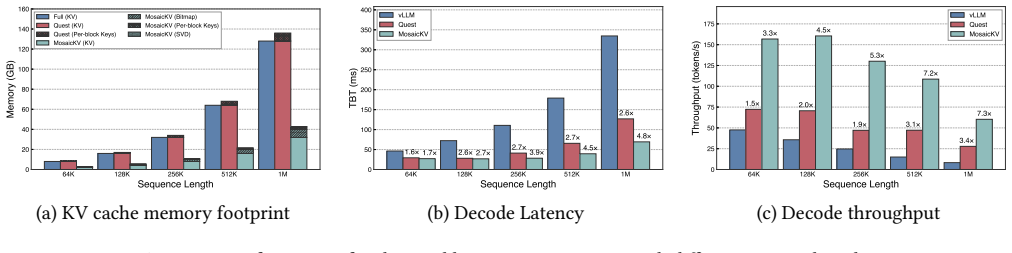
read the original abstract
Long-context LLM services now sustain prompts with hundreds of thousands to millions of tokens, making the key-value (KV) cache a first-order serving cost. Because the cache grows linearly with context length, it can exhaust GPU memory, force smaller batches, and reduce serving throughput. Prior KV cache compression techniques typically target only the sequence dimension or only the channel dimension, which leaves limited headroom as context windows scale. Compressing both dimensions promises higher memory reduction, but applying the two forms of compression directly leads to significant accuracy loss. This paper introduces MosaicKV, a dynamic two-D (dimensional) KV cache compression system for extremely long-context serving. MosaicKV uses dynamic two-D compression to address the accuracy challenge, exploiting the non-uniform importance distribution of elements within the KV cache. Instead of applying one compression pattern globally, MosaicKV identifies important elements for each KV vector and selects compression strategies at the granularity of KV cache segments. To address the performance challenge, where fine-grained sparsity and compression management overhead can offset the gains from compression, MosaicKV introduces compressed KV cache management. This mechanism uses underutilized GPU and CPU resources to maintain compressed KV caches and accelerate attention computation. Evaluation on an H800 GPU with multiple LLMs shows that MosaicKV delivers up to 16x attention speedup, 4.8x lower decode latency, and 7.3x higher throughput than the uncompressed baseline. At the same time, it reduces memory usage by 3x and incurs only 1.76% average accuracy loss on LongBench and RULER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MosaicKV, a dynamic two-D KV cache compression system for long-context LLM serving. It exploits non-uniform element importance within KV caches to select per-segment compression strategies (addressing accuracy loss from joint sequence/channel compression) and adds a compressed KV cache management layer that leverages underutilized GPU/CPU resources to reduce overhead. On H800 GPUs across multiple LLMs, it reports up to 16x attention speedup, 4.8x lower decode latency, 7.3x higher throughput, 3x memory reduction, and 1.76% average accuracy loss on LongBench and RULER.
Significance. If the empirical results hold under reproduction, the work provides a practical systems contribution that directly tackles the linear growth of KV cache as a first-order cost in long-context serving. The dynamic per-KV-vector selection mechanism and the management layer that overlaps compression with attention computation are concrete engineering advances that could be adopted in production inference stacks.
minor comments (3)
- [§4] §4 (Evaluation): the abstract and results tables report aggregate speedups and accuracy deltas but do not state the number of independent runs, standard deviations, or the precise set of baseline implementations (e.g., whether H2O, StreamingLLM, or exact FlashAttention variants were re-implemented under identical conditions). Adding these details would strengthen the 16x/4.8x/7.3x claims.
- [§3.2] §3.2 (Dynamic selection algorithm): the description of how importance scores are computed for each KV vector and how the per-segment strategy is chosen is high-level; pseudocode or a small worked example would clarify the exact decision rule and its computational cost relative to the reported gains.
- [Figure 3] Figure 3 / Table 2: axis labels and legend entries use abbreviations (e.g., “D2C”, “CKV-Mgmt”) that are defined only later in the text; moving the definitions to the figure captions would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We appreciate the recognition of MosaicKV's practical systems contributions to long-context LLM serving.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical systems contribution for dynamic two-dimensional KV cache compression in long-context LLMs. All central claims (speedup, latency, throughput, memory reduction, and accuracy) rest on direct experimental measurements against baselines on H800 GPUs using LongBench and RULER. No equations, parameter-fitting steps presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or described method; the non-uniform importance premise functions as an empirical design motivation rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Non-uniform importance distribution of elements within the KV cache
Reference graph
Works this paper leans on
-
[1]
Introducing Llama 3.1: Our most capable models to date.https: //ai.meta.com/blog/meta-llama-3-1/
2024. Introducing Llama 3.1: Our most capable models to date.https: //ai.meta.com/blog/meta-llama-3-1/
2024
-
[2]
The Llama 4 herd: The beginning of a new era of natively multi- modal AI innovation.https://ai.meta.com/blog/llama-4-multimodal- intelligence/
2025. The Llama 4 herd: The beginning of a new era of natively multi- modal AI innovation.https://ai.meta.com/blog/llama-4-multimodal- intelligence/
2025
-
[3]
A new era of intelligence with Gemini 3.https://blog.google/ products-and-platforms/products/gemini/gemini-3/
2025. A new era of intelligence with Gemini 3.https://blog.google/ products-and-platforms/products/gemini/gemini-3/
2025
-
[4]
Claude Code docs.https://code.claude.com/docs/en/overview
2026. Claude Code docs.https://code.claude.com/docs/en/overview
2026
-
[5]
cuSPARSE Documentation.https://developer.nvidia.com/ cusparse
2026. cuSPARSE Documentation.https://developer.nvidia.com/ cusparse
2026
-
[6]
Introducing GPT-5.4 | OpenAI.https://openai.com/index/ introducing-gpt-5-4/
2026. Introducing GPT-5.4 | OpenAI.https://openai.com/index/ introducing-gpt-5-4/
2026
-
[7]
LLMs with largest context windows.https://codingscape.com/ blog/llms-with-largest-context-windows
2026. LLMs with largest context windows.https://codingscape.com/ blog/llms-with-largest-context-windows
2026
-
[8]
OpenClaw — Personal AI Assistant.https://openclaw.ai/
2026. OpenClaw — Personal AI Assistant.https://openclaw.ai/
2026
-
[9]
What’s New in Claude 4.6.https://platform.claude.com/docs/ en/about-claude/models/whats-new-claude-4-6
2026. What’s New in Claude 4.6.https://platform.claude.com/docs/ en/about-claude/models/whats-new-claude-4-6
2026
-
[10]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 117–134.https://www.usenix...
2024
-
[11]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. 2023. GQA: Training General- ized Multi-Query Transformer Models from Multi-Head Checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for C...
2023
-
[12]
doi:10.18653/v1/2023.emnlp-main.298
-
[13]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhid- ian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Paper...
-
[14]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The Long-Document Transformer. doi:10.48550/arXiv.2004.05150 arXiv:2004.05150 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2004.05150 2020
-
[15]
Abdelfattah, and Kai-Chiang Wu
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu- Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S. Abdelfattah, and Kai-Chiang Wu. 2025. Palu: KV-Cache Compression with Low-Rank Projection. InThe Thirteenth International Confer- ence on Learning Representations.https://openreview.net/forum?id= LWMS4pk2vK
2025
-
[16]
Yaoqi Chen, Jinkai Zhang, Baotong Lu, Qianxi Zhang, Chengruidong Zhang, Jingjia Luo, Di Liu, Huiqiang Jiang, Qi Chen, Jing Liu, Bailu Ding, Xiao Yan, Jiawei Jiang, Chen Chen, Mingxing Zhang, Yuqing Yang, Fan Yang, and Mao Yang. 2025. RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference. arXiv:2505.02922 [cs.LG]https://arxiv.org/ab...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, and Beidi Chen. 2025. MagicPIG: LSH Sampling for Efficient LLM Generation. InThe Thirteenth International Conference on Learn- ing Representations.https://openreview.net/forum?id=ALzTQUgW8a
2025
-
[18]
Rong Cheng, Jinyi Liu, Yan Zheng, Fei Ni, Jiazhen Du, Hangyu Mao, Fuzheng Zhang, Bo Wang, and Jianye Hao. 2025. DualRAG: A Dual- Process Approach to Integrate Reasoning and Retrieval for Multi- Hop Question Answering. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), Wanxiang Che, Joyce Na...
-
[19]
Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Par- allelism and Work Partitioning. arXiv:2307.08691 [cs.LG]https: //arxiv.org/abs/2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Tri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher Re
-
[21]
InAdvances in Neural Information Processing Systems, Alice H
FlashAttention: Fast and Memory-Efficient Exact Attention with IO -Awareness. InAdvances in Neural Information Processing Systems, Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (Eds.).https://openreview.net/forum?id=H4DqfPSibmx
-
[22]
DeepSeek-AI, Aixin Liu, Bei Feng, et al . 2024. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434 [cs.CL]https://arxiv.org/abs/2405.04434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961 [cs.LG]https://arxiv.org/abs/2101.03961
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Jitai Hao, Yuke Zhu, Tian Wang, Jun Yu, Xin Xin, Bo Zheng, Zhaochun Ren, and Sheng Guo. 2025. OmniKV: Dynamic Context Selection for Efficient Long-Context LLMs. InThe Thirteenth International Confer- ence on Learning Representations.https://openreview.net/forum?id= ulCAPXYXfa
2025
-
[25]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: towards 10 million context length LLM inference with KV cache quantization. InProceedings of the 38th International Conference on Neural Information Processing Systems (NIPS ’24, Vol. 37). Curran Associates Inc., Red Hook, ...
2024
-
[26]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models?. InFirst Conference on Language Modeling.https://openreview.net/forum?id= kIoBbc76Sy
2024
-
[27]
Donghyeon Joo, Helya Hosseini, Ramyad Hadidi, and Bahar Asgari
-
[28]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum? id=C69741fMFX
MUSTAFAR: Promoting Unstructured Sparsity for KV Cache Pruning in LLM Inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum? id=C69741fMFX
- [29]
-
[30]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[31]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). Association for Computing Machinery, New York, NY, USA, 611–626. doi:10.1145/3600006.3613165
-
[32]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Asso- ciation, Santa Clara, CA, 155–172.https://www.usenix.org/conference/ osdi24/presentation/lee
2024
-
[33]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Lo- catelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. SnapKV: LLM knows what you are looking for before generation. In Proceedings of the 38th International Conference on Neural Information Processing Systems (NIPS ’24, Vol. 37). Curran Associates Inc., Red Hook, NY, USA, 2...
2024
-
[34]
Yubo Li, Xiaobin Shen, Xinyu Yao, Xueying Ding, Yidi Miao, Ramayya Krishnan, and Rema Padman. 2026. Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models. doi:10.48550/ arXiv.2504.04717arXiv:2504.04717 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [35]
-
[36]
Liu, Kartik Khandelwal, Sandeep Subramanian, et al
Alexander H. Liu, Kartik Khandelwal, Sandeep Subramanian, et al
-
[37]
Ministral 3.https://arxiv.org/abs/2601.08584v1
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, and Lili Qiu. 2025. RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openrevi...
2025
-
[39]
Zichang Liu, View Profile, Aditya Desai, View Profile, Fangshuo Liao, View Profile, Weitao Wang, View Profile, Victor Xie, View Profile, Zhaozhuo Xu, View Profile, Anastasios Kyrillidis, View Profile, Anshu- mali Shrivastava, and View Profile. 2023. Scissorhands. InProceedings of the 37th International Conference on Neural Information Processing Systems. ...
-
[40]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen (Henry) Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: a tuning- free asymmetric 2bit quantization for KV cache. InProceedings of the 41st International Conference on Machine Learning (ICML’24, Vol. 235). JMLR.org, Vienna, Austria, 32332–32344
2024
-
[41]
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, et al
-
[42]
In The Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum?id=RlqYCpTu1P
MoBA: Mixture of Block Attention for Long-Context LLMs. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum?id=RlqYCpTu1P
- [43]
-
[44]
2019.PyTorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Brad- bury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019.PyTorch: an imperative style, high-p...
2019
-
[45]
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, and Douglas Orr. 2024. SparQ attention: bandwidth- efficient LLM inference. InProceedings of the 41st International Con- ference on Machine Learning (ICML’24, Vol. 235). JMLR.org, Vienna, Austria, 42558–42583
2024
-
[46]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. FlashAttention-3: Fast and Accurate At- tention with Asynchrony and Low-precision. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 68658–6...
-
[47]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538 [cs.LG]https://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang
-
[49]
InProceedings of the 40th Interna- tional Conference on Machine Learning (ICML ’23)
FlexGen: High-Throughput Generative Inference of Large Lan- guage Models with a Single GPU. InProceedings of the 40th Interna- tional Conference on Machine Learning (ICML ’23)
-
[50]
Hanshi Sun, Li-Wen Chang, Wenlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. 2025. ShadowKV: KV Cache in Shadows for High-Throughput Long -Context LLM Inference. InProceedings of the 42nd International Conference on Machine Learning. PMLR, 57355–57373.https://proceedings.mlr.press/v267/sun25b.html
2025
-
[51]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. QUEST: query-aware sparsity for efficient long- context LLM inference. InProceedings of the 41st International Con- ference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, 14 Article 1955, 11 pages
2024
-
[52]
Rossi, Alexa Siu, Ruiyi Zhang, and Tyler Derr
Yu Wang, Nedim Lipka, Ryan A. Rossi, Alexa Siu, Ruiyi Zhang, and Tyler Derr. 2024. Knowledge Graph Prompting for Multi-Document Question Answering.Proceedings of the AAAI Conference on Artificial Intelligence38, 17 (March 2024), 19206–19214. doi:10.1609/aaai.v38i17. 29889
-
[53]
Zhepei Wei, Wenlin Yao, Yao Liu, Weizhi Zhang, Qin Lu, Liang Qiu, Changlong Yu, Puyang Xu, Chao Zhang, Bing Yin, Hyokun Yun, and Lihong Li. 2025. WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy ...
-
[54]
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, and Maosong Sun. 2024. InfLLM: training-free long-context extrapolation for LLMs with an efficient context memory. InProceedings of the 38th International Conference on Neural Information Processing Systems (NIPS ’24, Vol. 37). Curran Associates Inc., Red Hook, NY...
2024
-
[55]
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. 2024. DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads. arXiv:2410.10819 [cs.CL]https://arxiv.org/abs/2410.10819
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InThe Twelfth International Conference on Learning Representa- tions.https://openreview.net/forum?id=NG7sS51zVF
2024
-
[57]
Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Ao- jun Zhou, Amrita Saha, Caiming Xiong, and Doyen Sahoo. 2025. ThinK: Thinner Key Cache by Query-Driven Pruning. InThe Thir- teenth International Conference on Learning Representations.https: //openreview.net/forum?id=n0OtGl6VGb
2025
-
[58]
An Yang, Anfeng Li, Baosong Yang, et al . 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL]https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [59]
-
[60]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and Cus- tomizable Attention Engine for LLM Inference Serving. InEighth Conference on Machine Learning and Systems.https://openreview.net/ forum?id=RXPofAsL8F
2025
-
[61]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. 2025. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. InProceedings of the 63rd Annual Meeting of the Association for Computa...
-
[62]
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big bird: transformers for longer sequences. InProceedings of the 34th International Conference on Neural Information Processing Systems (NIPS ’20). Curran Associates Inc., Red Hook, NY, USA...
-
[63]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association...
2023
-
[64]
doi:10.18653/v1/2023.emnlp-main.151
-
[65]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. 2024. CodeAgent: Enhancing Code Generation with Tool- Integrated Agent Systems for Real-World Repo-level Coding Challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Associat...
-
[66]
Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John C. S. Lui, and Haibo Chen. 2025. DiffKV: Differentiated Memory Management for Large Language Models with Parallel KV Compaction. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles(Lotte Hotel World, Seoul, Republic of Korea)(SOSP ’25). Association for Computing Machinery, New York, NY, ...
-
[67]
Zhenyu Zhang, View Profile, Ying Sheng, View Profile , Tianyi Zhou, View Profile, Tianlong Chen, View Profile, Lianmin Zheng, View Pro- file, Ruisi Cai, View Profile, Zhao Song, View Profile, Yuandong Tian, View Profile, Christopher Ré, View Profile, Clark Barrett, View Profile, Zhangyang Wang, View Profile, Beidi Chen, and View Profile. 2023. H2o. InProc...
-
[68]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-Bit Quantization for Efficient and Ac- curate LLM Serving. InProceedings of Machine Learning and Sys- tems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 196–209.https://proceedings.mlsys.org/pape...
2024
-
[69]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: efficient execution of structured language model programs. InPro- ceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC,...
2024
-
[70]
Ningxin Zheng, Huiqiang Jiang, Quanlu Zhang, Zhenhua Han, Lingx- iao Ma, Yuqing Yang, Fan Yang, Chengruidong Zhang, Lili Qiu, Mao Yang, and Lidong Zhou. 2023. PIT: Optimization of Dynamic Sparse Deep Learning Models via Permutation Invariant Transformation. In Proceedings of the 29th Symposium on Operating Systems Principles (Koblenz, Germany)(SOSP ’23). ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.