LARK: Learnability-Grounded Trajectory Selection for Efficient Reasoning Distillation
Pith reviewed 2026-06-29 08:14 UTC · model grok-4.3
The pith
LARK selects reasoning trajectories by estimating how quickly a student model's loss decreases, using a proxy and chi-squared regularization to balance learnability with full distribution coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LARK defines the learnability factor rho as the rate at which student training loss decreases on a given trajectory. It estimates rho via a learnability proxy whose estimation error is theoretically bounded, then applies a chi-squared regularized selection policy that trades off this learnability against distributional coverage, again with error guarantees. The resulting trajectories produce faster supervised fine-tuning loss reduction while preserving generalization, outperforming heuristic baselines across base models and tasks.
What carries the argument
The learnability factor rho, estimated by a learnability proxy and combined with a chi-squared regularized selection policy that enforces coverage of the full training distribution.
If this is right
- LARK-selected trajectories induce faster loss reduction during the student's supervised fine-tuning phase.
- The LARK score serves as a predictor of a trajectory's downstream training utility.
- The method yields consistent gains over data selection baselines on multiple base models and reasoning tasks.
- Both the proxy estimation and the regularized policy come with explicit bounds on approximation error.
Where Pith is reading between the lines
- The same proxy idea might allow skipping low-learnability examples in other supervised stages such as instruction tuning.
- If the chi-squared term successfully prevents collapse to narrow subsets, similar regularization could stabilize selection in reinforcement learning from AI feedback loops.
- Diagnostic checks that correlate the proxy score with actual loss curves could become a lightweight way to audit training data quality before full runs.
Load-bearing premise
The learnability proxy can accurately estimate the true rate of student loss decrease on each trajectory without requiring complete training runs on every candidate.
What would settle it
Run full supervised fine-tuning on trajectories chosen by LARK versus those chosen by quality or confidence heuristics and check whether the LARK set produces measurably slower loss decrease or worse final accuracy on held-out reasoning problems.
Figures


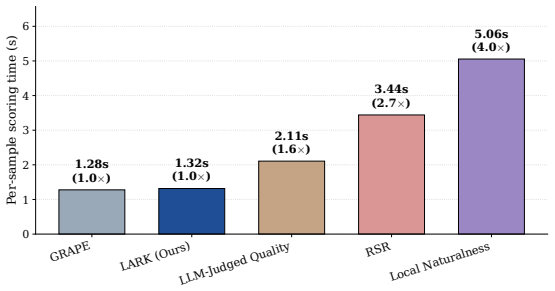

read the original abstract
We study trajectory selection for reasoning distillation, where teacher-generated reasoning trajectories are selectively used as supervision for a student model. Existing methods rely on heuristics such as trajectory quality or model confidence, but they often overlook whether a trajectory is learnable by the student. In this paper, we present LARK, a learnability-grounded method for reasoning trajectory selection. LARK selects trajectories that the student can learn efficiently while preserving the generalization of the full training distribution. At the core of LARK is a learnability factor $\rho$, which characterizes the rate at which the student's training loss decreases. To estimate this rate efficiently and maintain generalization, we introduce a learnability proxy and a $\chi^2$-regularized selection policy that balances learnability and distributional coverage, both with strong theoretical guarantees on their estimation error. Empirically, LARK consistently outperforms data selection baselines across multiple base models and reasoning tasks. Diagnostic analyses show that the LARK score predicts downstream training utility and that LARK-selected trajectories induce faster supervised fine-tuning loss reduction. Our code is available at https://github.com/Tianrun-Yu/LARK.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LARK, a method for selecting teacher-generated reasoning trajectories for efficient distillation into a student model. It defines a learnability factor ρ characterizing the rate of decrease in the student's training loss, estimates ρ via a learnability proxy, and employs a χ²-regularized selection policy to balance learnability against distributional coverage. The paper claims strong theoretical guarantees on the estimation error of both the proxy and the policy, and reports that LARK consistently outperforms heuristic baselines across base models and reasoning tasks, with diagnostics showing that the LARK score predicts downstream utility and induces faster SFT loss reduction.
Significance. If the proxy is shown to be a reliable low-bias surrogate for true ρ obtained from full SFT and the concentration bounds apply under the non-convex dynamics of LLM fine-tuning, the work would supply a principled, theoretically grounded alternative to quality- or confidence-based selection heuristics. This could reduce the computational cost of reasoning distillation while preserving generalization, and the public code release supports direct reproducibility checks.
major comments (1)
- [Abstract] Abstract (and the theory section deriving the proxy): the central claim that the learnability proxy yields an estimate of ρ whose error is controlled tightly enough for the χ²-regularized policy to both prefer high-ρ trajectories and preserve generalization rests on the unverified assumption that the proxy functional form is an unbiased or low-bias surrogate for the true ρ obtained by running full supervised fine-tuning on each trajectory. The provided concentration bounds are derived under this surrogate relationship; if the short-horizon or linearized proxy fails to track the actual non-convex loss trajectory, the selection policy can systematically favor trajectories whose apparent ρ is high while actual downstream loss reduction is not, directly undermining both the efficiency and generalization guarantees.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for isolating the key assumption underlying the proxy and its theoretical guarantees. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the theory section deriving the proxy): the central claim that the learnability proxy yields an estimate of ρ whose error is controlled tightly enough for the χ²-regularized policy to both prefer high-ρ trajectories and preserve generalization rests on the unverified assumption that the proxy functional form is an unbiased or low-bias surrogate for the true ρ obtained by running full supervised fine-tuning on each trajectory. The provided concentration bounds are derived under this surrogate relationship; if the short-horizon or linearized proxy fails to track the actual non-convex loss trajectory, the selection policy can systematically favor trajectories whose apparent ρ is high while actual downstream loss reduction is not, directly undermining both the efficiency and generalization guarantees.
Authors: We agree that the concentration bounds are formally conditional on the proxy being a reasonable surrogate for the true ρ obtained from full SFT. The manuscript does not claim a general theoretical proof that the short-horizon proxy is unbiased under arbitrary non-convex LLM dynamics. Instead, it supplies (i) finite-sample error bounds on the proxy estimator itself (given the surrogate relationship) and (ii) a χ²-regularized policy whose guarantees hold once the proxy estimates are in hand. The practical validity of the surrogate is addressed empirically: Section 5.3 and the associated diagnostics show that the LARK score (derived from the proxy) strongly predicts downstream utility and that trajectories selected by LARK produce measurably faster SFT loss reduction than heuristic baselines across multiple models and tasks. These results indicate that, at least for the reasoning-distillation regimes studied, the proxy tracks actual loss trajectories sufficiently well for the selection policy to improve both efficiency and generalization. A complete non-convex analysis of the proxy bias remains an open question and is outside the scope of the present work. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines learnability factor ρ directly from the observed rate of student loss decrease and introduces a separate proxy estimator plus χ²-regularized policy, each accompanied by claimed concentration bounds on estimation error. No equations or steps are shown that reduce the final selection policy or performance claims back to the definition of ρ by construction, nor is there load-bearing self-citation or an ansatz smuggled via prior work. The derivation therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Template-shared, numerically perturbed.Same algebraic template, different constants or signs, leading to a different polynomial and a different answer. The highest-similarity case (MATH-L2 #11, J= 0.869 ) asks for the smallest n such that all roots of z4 +z 2 + 1 = 0 are n-th roots of unity, while the closest training problem asks the same question forz 4...
-
[2]
Template-shared, different question on the same setup.Same physical or geometric setup, but a different quantity is asked, with no derivable relation between the two answers. For example, MATH-L5 #46 (J= 0.693 ) describes a hot-air balloon held by four ropes anchored at points A, B, C, D; the training problem on the same setup asks for the length of OH, w...
-
[3]
MATH-L4 #38 (J= 0.664 ) asks to rewrite x2 + 2.6x+ 3.6 in the form (x+b) 2 +c , while the training problem performs the same operation on x2 −20x+ 36
Surface-level template variation.Same problem stem with different numerical inputs (e.g., coefficients in a quadratic completion task). MATH-L4 #38 (J= 0.664 ) asks to rewrite x2 + 2.6x+ 3.6 in the form (x+b) 2 +c , while the training problem performs the same operation on x2 −20x+ 36. The procedure is identical but the inputs and outputs differ. 38 In no...
2024
-
[4]
We need findb·c
Also c−a−2b= 3(a×b) . We need findb·c. Step: First, note: ∥a+b∥ 2 = (a+b) 2 =a 2 + 2a·b+b 2 = 1 + 2 cosθ+ 1 = 2 + 2 cosθ= 3 . So 2 + 2 cosθ= 3⇒cosθ= 1/2soa·b= 1/2. Now, note: a×b is perpendicular to both a and b. So it is orthogonal to a, b. Then, c=a+ 2b+ 3(a×b) . Dotting with b: b·c=b·a+ 2b·b+ 3b·(a×b) =a·b+ 2·1 + 3·0 = 1/2 + 2 = 5/2 . So answer: 5/2. 4...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.