The Geometry of Linear Program Compression: An Exact Characterization and Learning Algorithm
Pith reviewed 2026-06-29 20:51 UTC · model grok-4.3
The pith
Linear programs compress exactly into lower-dimensional equivalents that preserve optimality when objectives vary in a low-dimensional decision-relevant subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
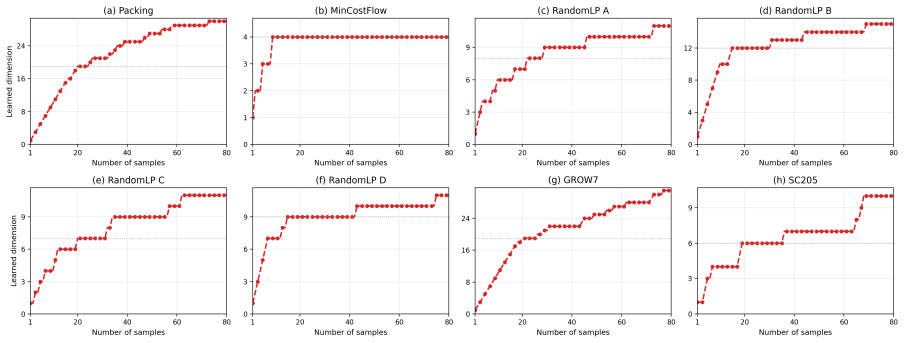
There exists an exact geometric characterization of compressed LPs that are equivalent in optimality to the original for objectives in a given distribution, together with a tractable sample-based algorithm that recovers the decision-relevant subspace and yields the true optimum on an unseen instance with probability at least 1 minus O tilde of d star over n.
What carries the argument
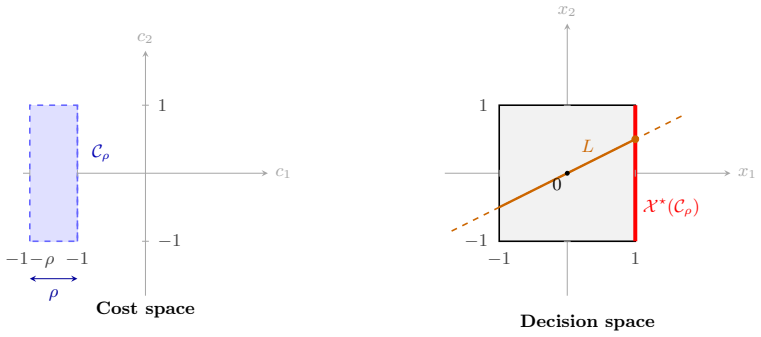
The decision-relevant subspace, the lowest-dimensional linear space containing all objective-function variation that affects the optimal solution, which permits an exact projection of the feasible set while leaving the optimum unchanged.
If this is right
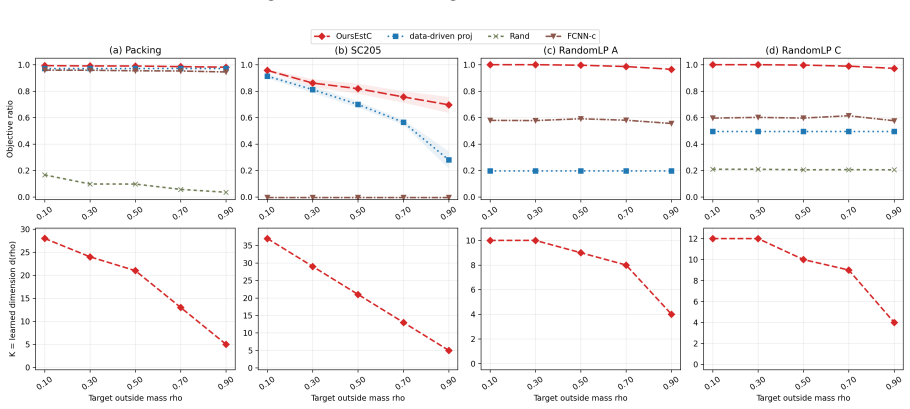
- The dimension of the compressed LP can be chosen to trade off computational speed against the probability of exact recovery on future instances.
- The 1 over n dependence on sample size is strictly faster than the 1 over square root n rates of earlier approximate projection methods.
- Exact preservation of the optimal solution is achieved rather than merely bounding the objective value.
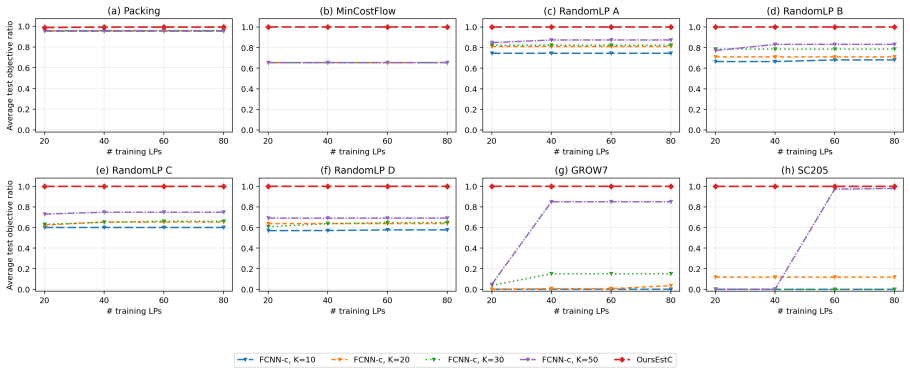
- Repeated LP solves become faster with no degradation in solution quality once the subspace is learned.
Where Pith is reading between the lines
- The same geometric approach might extend to other convex problems if an analogous decision-relevant subspace can be defined.
- A user with a fixed number of historical LPs could select the highest allowable dimension that still meets a target recovery probability.
- Empirical checks on large-scale repeated optimization tasks could measure the practical gap between the derived probability bound and observed recovery rates.
Load-bearing premise
Historical LP samples are drawn i.i.d. from a distribution over objective functions that admits a low-dimensional decision-relevant subspace recoverable from the samples.
What would settle it
A sequence of new i.i.d. test LPs drawn from the same distribution on which the learned compressed LP returns a different optimal solution more often than the stated O tilde d star over n probability bound would falsify the exact characterization or the algorithm's guarantee.
Figures
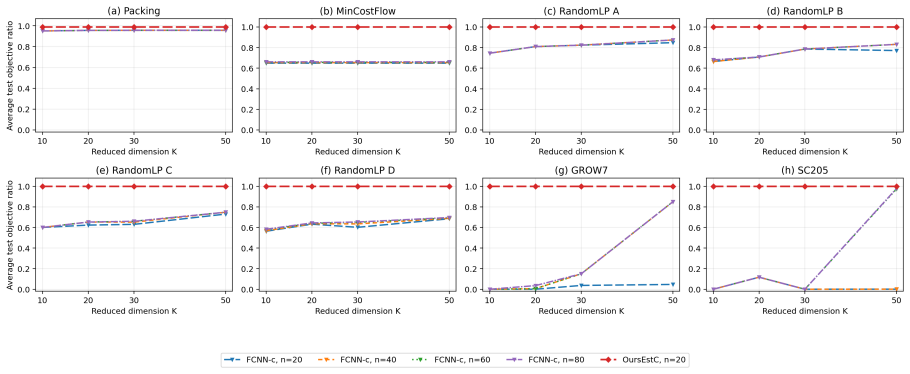
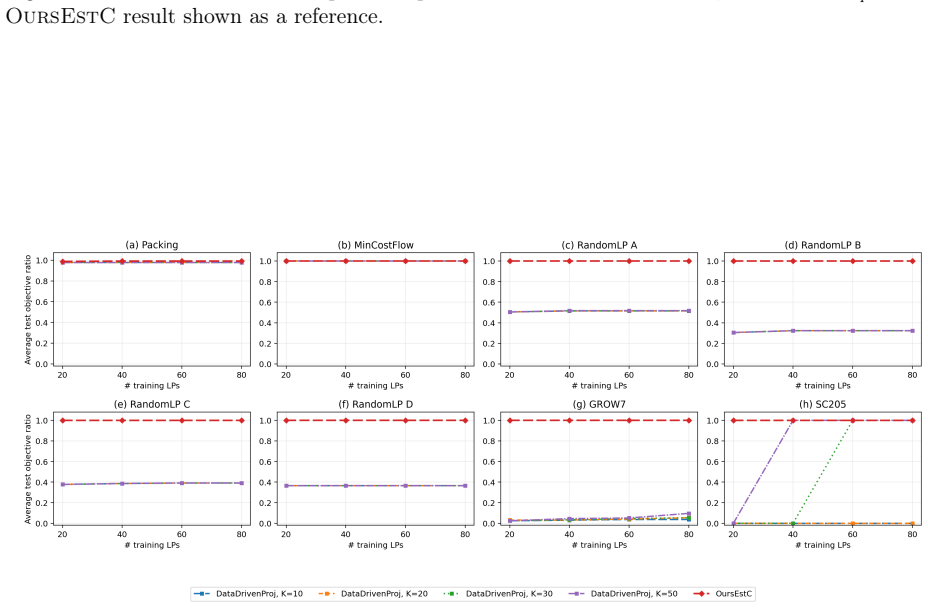

read the original abstract
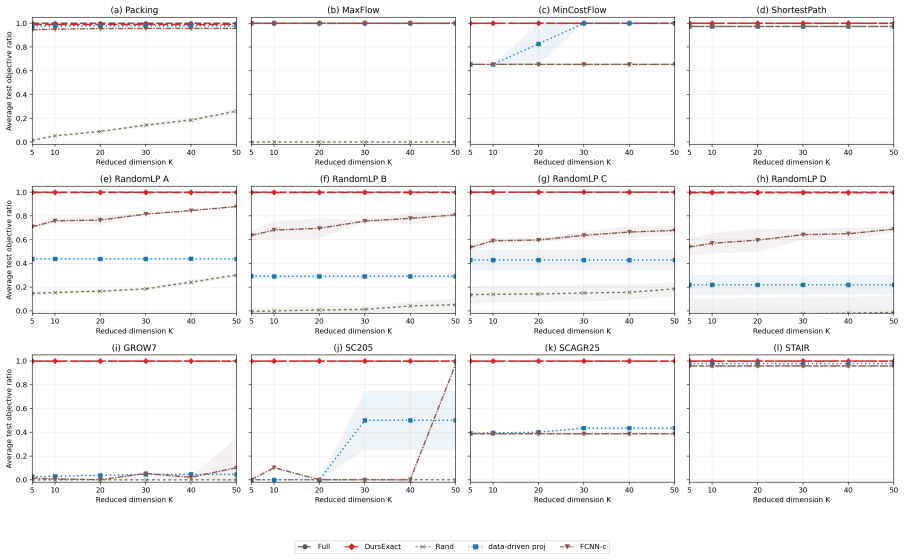
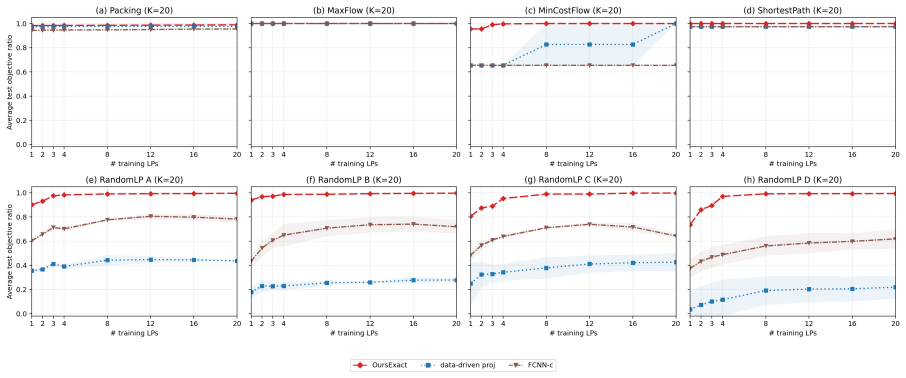
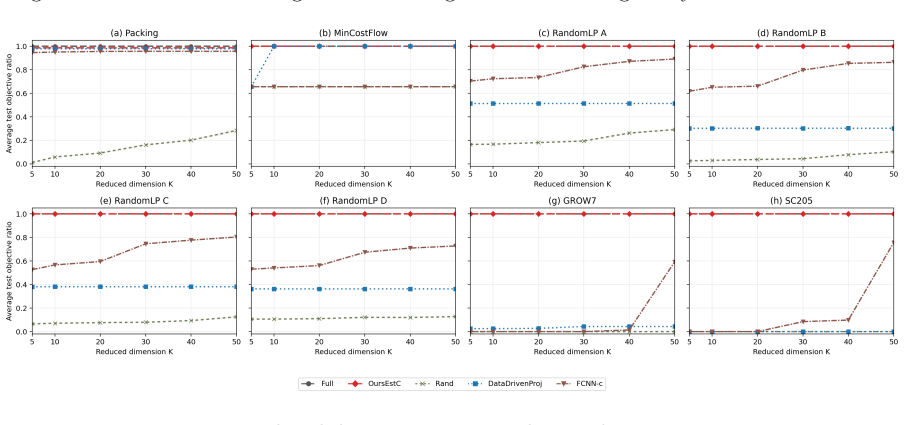
We study how much a linear program (LP) can be compressed when solved repeatedly, given prior knowledge about its objective function. Existing data-driven projection methods learn low-dimensional surrogate LPs with approximate objective-value guarantees, but cannot provably identify the optimal projection for a prescribed compression budget. We instead ask a sharper question: how far can an LP be compressed into a lower-dimensional equivalent while \emph{exactly} preserving optimality, enabling faster repeated solves with no loss in solution quality? We provide an exact geometric characterization of such compressed LPs, together with a tractable sample-based learning algorithm that comes with fast-rate guarantees: the compressed LP recovers the optimal solution of an unseen instance with probability at least $1-\widetilde O(d^\star/n)$, where $d^\star$ is the dimension of the decision-relevant subspace, and $n$ is the number of available historical LP samples. This $1/n$ dependence is sharper than the $\widetilde O(1/\sqrt n)$ uniform-convergence rates of approximate projection methods. Our framework further exposes a tunable tradeoff between the dimension of the compressed LP and the probability of recovering the optimal solution, allowing the user to trade compression for accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript provides an exact geometric characterization of compressed linear programs that exactly preserve optimality for objective functions drawn from a distribution admitting a low-dimensional decision-relevant subspace. It further develops a tractable sample-based learning algorithm that recovers the optimal solution of an unseen instance with probability at least 1−Õ(d∗/n), where d∗ denotes the dimension of the decision-relevant subspace and n the number of historical samples. The framework also exposes a tunable tradeoff between the dimension of the compressed LP and the recovery probability.
Significance. If the central claims hold, the work offers a meaningful advance in data-driven optimization by replacing approximate objective-value guarantees with exact optimality preservation and by achieving a fast 1/n rate that improves on the Õ(1/√n) uniform-convergence rates of prior projection methods. The explicit geometric characterization, the sample-based algorithm, and the dimension-probability tradeoff are concrete strengths that could inform practical repeated LP solving.
minor comments (3)
- [Abstract] Abstract, line beginning 'the compressed LP recovers...': the probability bound is stated without an accompanying sentence that recalls the i.i.d. sampling assumption or the recoverability of the subspace; adding one clause would improve readability for readers who encounter only the abstract.
- The notation ilde O is used for the probability term but is not defined in the provided abstract or claim summary; a brief parenthetical or footnote in the introduction would remove ambiguity.
- [Introduction] The abstract refers to 'historical LP samples' without specifying whether the constraint matrix is fixed or also varies; a single clarifying sentence in §1 would prevent misinterpretation.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript and for recommending minor revision. No major comments appear in the report, which we interpret as an indication that the central claims, geometric characterization, sample-based algorithm, and 1/n-rate guarantees are viewed as sound. We are prepared to incorporate any minor editorial suggestions that may arise during the revision process.
Circularity Check
No significant circularity identified
full rationale
The paper's central contribution is an exact geometric characterization of compressed LPs that exactly preserve optimality for instances drawn from a distribution admitting a low-dimensional decision-relevant subspace, together with a sample-based learning algorithm. The stated recovery probability 1−O~(d*/n) is presented as a fast-rate guarantee derived from the subspace structure and i.i.d. sampling assumption; it does not reduce by construction to a fitted parameter or self-citation. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the abstract or claim structure. The argument is self-contained once the subspace existence and recoverability are granted as modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of a low-dimensional decision-relevant subspace for the family of objective functions
- domain assumption Historical LP samples are drawn i.i.d. from the distribution over objectives
Reference graph
Works this paper leans on
-
[2]
Dimitris Bertsimas and Bartolomeo Stellato
URLhttps: //arxiv.org/abs/2602.15365. Dimitris Bertsimas and Bartolomeo Stellato. The voice of optimization.Machine Learning, 110(2): 249–277,
-
[3]
Elmachtoub, Paul Grigas, and Ambuj Tewari
Othman El Balghiti, Adam N. Elmachtoub, Paul Grigas, and Ambuj Tewari. Generalization bounds in the predict-then-optimize framework.Mathematics of Operations Research, 48(4):2043–2065,
2043
-
[4]
Learning Decision-Sufficient Representations for Linear Optimization
Yuhan Ye, Saurabh Amin, and Asuman E. Ozdaglar. Learning decision-sufficient representations for linear optimization.arXiv preprint arXiv:2603.18551,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Choose an extreme optimal solution of the corresponding auxiliary LP overG(c)
Hence either max x∈G(c) a⊤ j (x−x 0)>0ormin x∈G(c) a⊤ j (x−x 0)<0. Choose an extreme optimal solution of the corresponding auxiliary LP overG(c). Since G(c)is a face of the polytopeX, every extreme point ofG(c)is an extreme point ofX. The chosen point therefore belongs toG(c) ∩ X ∠ and has nonzero projection along someaj ∈S ⊥, so x−x 0 /∈S. The next three...
2021
-
[6]
It remains to prove the out-of-sample certificate (5). Sample-compression background.Sample compression is a classical way to prove distribution- free generalization: rather than controlling the complexity of an entire hypothesis class, one shows that the learned predictor can be reconstructed from a small subset of the training sample. This idea goes bac...
1984
-
[7]
sampleSof sizen, R(ρ(κ(S)))≤ 4 n 6|κ(S)|+ log e δ , where R(·)is the true0–1risk and |κ(S)| is the realized compression size
imply that, with probability at least1−δ over an i.i.d. sampleSof sizen, R(ρ(κ(S)))≤ 4 n 6|κ(S)|+ log e δ , where R(·)is the true0–1risk and |κ(S)| is the realized compression size. This fast1/n rate is specific to the realizable stable regime; in agnostic compression settings, such fast rates are not available in general (Hanneke and Kontorovich, 2019). ...
2019
-
[8]
Since all labels are identically zero, we suppress them in the notation; equivalently,κ stores the labeled examples(ci, 0)i∈Tn
Define the compression map κby κ(S) := (ci)i∈Tn, where the subsequence is stored in its original order. Since all labels are identically zero, we suppress them in the notation; equivalently,κ stores the labeled examples(ci, 0)i∈Tn. Define the reconstruction map ρ by rerunning Algorithm 1 on any supplied subsequenceS′ using the same fixed anchorx0 and the ...
2021
-
[9]
Since Lemma 10 gives at mostd⋆ total appends, the number of containment checks is at most n + d⋆
There is one final containment check for each of then samples and one additional check for each append. Since Lemma 10 gives at mostd⋆ total appends, the number of containment checks is at most n + d⋆. Each check solves only a polynomial number of LPs overX or over the optimal face of X obtained by adding the equalityc⊤ i x = v(ci), and the required ortho...
1941
-
[10]
Its calibrated estimated prior is an ellipsoid
computed with a ridge covariance estimate; the ridge term makes the inverse well-defined and stabilizes high-dimensional covariance estimation (Ledoit and Wolf, 2004). Its calibrated estimated prior is an ellipsoid. Proof of Proposition 13.Condition on the fitting sampleDfit, so the scoresbθ is fixed. Let S = sbθ(c) for an independent fresh drawc∼P c, and...
2004
-
[11]
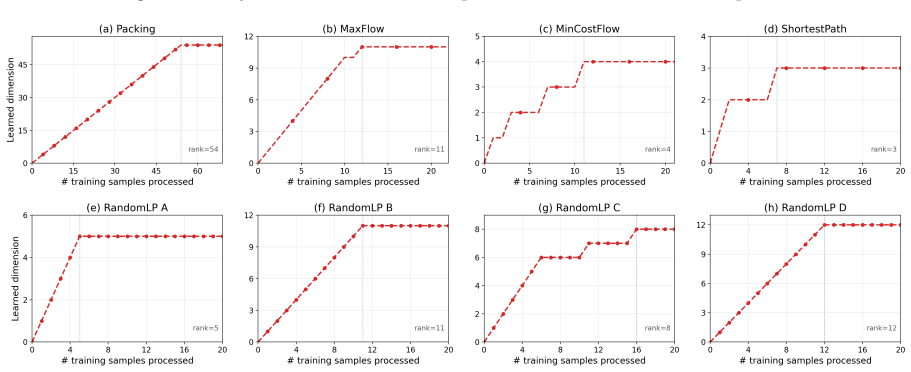
For synthetic instances, d is the original decision dimension
21 LP instances and cost distributions.All experiments use repeated general-form LPs in inequality form, min x∈Rd {c⊤x:Ax≤b}, where inequalities originally written in the opposite direction are multiplied by−1, the feasible region X = {x : Ax≤b} ⊆R d is fixed, and only the cost vectorc∈R d varies. For synthetic instances, d is the original decision dimens...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.