ExTax: Explainable Disinformation Detection via Persuasion, Emotion, and Narrative Role Taxonomies
Pith reviewed 2026-06-29 18:14 UTC · model grok-4.3
The pith
ExTax detects disinformation by mapping texts to a 17-dimensional space of persuasion, emotion, and narrative roles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
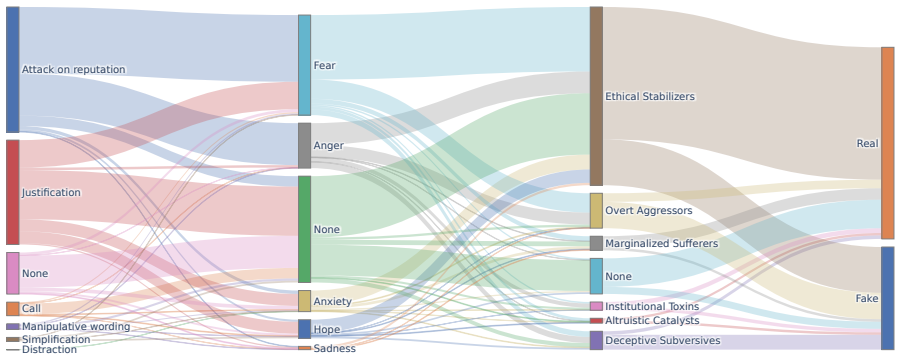
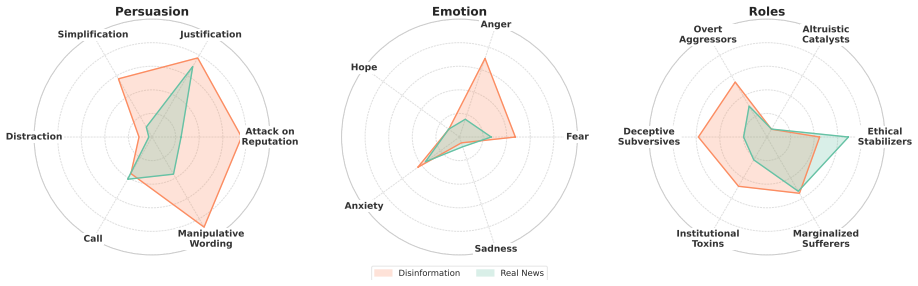
ExTax unifies persuasive rhetoric, emotional manipulation, and narrative roles into a 17-dimensional taxonomic space covering 6 persuasive-rhetoric strategies, 5 emotional-manipulation methods, and 6 narrative-role categories. It elicits attributes from multiple frontier LLMs, reconciles their disagreements through Entropy-driven Dynamic Label Smoothing, and fuses the resulting taxonomic representations with contextual encodings via Heterogeneous Multi-Head Attention, grounding each prediction in an interpretable manipulation profile and achieving an overall Macro F1 of 0.8456 across five benchmarks.
What carries the argument
The 17-dimensional taxonomic space of persuasive rhetoric, emotional manipulation, and narrative roles, which elicits labels from LLMs and fuses them with context via attention to produce explainable predictions.
If this is right
- Maintains superior Macro F1 across five cross-domain and cross-genre benchmarks compared to deep learning and LLM baselines.
- Resists performance drop under severe genre imbalance, unlike the strongest deep baseline which falls sharply.
- Supplies human-auditable explanations by linking each detection to a specific manipulation profile from the taxonomy.
- Unifies three previously separate signal types into one framework for detection.
Where Pith is reading between the lines
- The taxonomy could be tested on non-disinformation deception such as propaganda or phishing to check broader applicability.
- Real-time tools built on the same dimensions might help users spot manipulative framing before sharing content.
- Combining the taxonomy with fact-verification pipelines could address both intent and factual accuracy in one system.
Load-bearing premise
That the 17 dimensions of persuasion, emotion, and narrative roles capture the multi-faceted manipulative intents missed by surface-level syntax or knowledge checks.
What would settle it
A new cross-genre benchmark on which ExTax fails to exceed the Macro F1 of strong deep learning baselines or where human raters systematically disagree with the LLM-elicited taxonomy labels.
Figures

read the original abstract
The democratization of LLMs has accelerated the generation and circulation of highly fluent disinformation, making traditional syntax-semantic verification increasingly insufficient. Such deception rarely relies solely on surface-level falsity; instead, it often combines persuasive rhetoric, emotional manipulation, and narrative role construction to influence readers' interpretations through multiple cognitive pathways. However, existing detectors typically emphasize isolated signals -- such as syntax, external knowledge, persuasion, or affective cues -- and therefore struggle to capture the multi-faceted manipulative intents underlying disinformation or provide human-auditable explanations. To address this gap, we present \textbf{ExTax}, a taxonomy-aligned framework for explainable disinformation detection. ExTax unifies persuasive rhetoric, emotional manipulation, and narrative roles into a 17-dimensional taxonomic space, covering 6 persuasive-rhetoric strategies, 5 emotional-manipulation methods, and 6 narrative-role categories. It elicits attributes from multiple frontier LLMs, reconciles their disagreements through Entropy-driven Dynamic Label Smoothing, and fuses the resulting taxonomic representations with contextual encodings via Heterogeneous Multi-Head Attention, grounding each prediction in an interpretable manipulation profile. Across five cross-domain and cross-genre benchmarks, ExTax achieves an overall Macro $F_1$ of $0.8456$, outperforming state-of-the-art deep learning and LLM-based baselines. It also remains robust under severe genre imbalance, where the strongest deep baseline degrades from $0.9454$ to $0.6194$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExTax, a taxonomy-aligned framework for explainable disinformation detection. It unifies 6 persuasive-rhetoric strategies, 5 emotional-manipulation methods, and 6 narrative-role categories into a 17-dimensional space; elicits labels from multiple frontier LLMs; reconciles disagreements via Entropy-driven Dynamic Label Smoothing; and fuses the taxonomic representations with contextual encodings using Heterogeneous Multi-Head Attention. On five cross-domain and cross-genre benchmarks, it reports an overall Macro F1 of 0.8456, outperforming deep learning and LLM baselines, with claimed robustness under severe genre imbalance (strongest baseline drops from 0.9454 to 0.6194).
Significance. If the central empirical claims hold after addressing validation gaps, the work would offer a concrete advance in explainable disinformation detection by grounding predictions in an auditable 17-dimensional manipulation profile rather than opaque surface or knowledge signals. The reported cross-domain robustness and the explicit reconciliation mechanism (entropy-driven smoothing) are strengths that could support more reliable deployment; however, the absence of human validation for the elicited taxonomy leaves open whether the gains derive from the taxonomy itself or from injected LLM priors.
major comments (2)
- [Abstract / §3] Abstract and §3 (Taxonomy Elicitation): The premise that the 17-dimensional space captures 'multi-faceted manipulative intents' that surface-level or external-knowledge methods miss is load-bearing for the performance claim, yet the manuscript describes LLM-elicited labels without any human-annotated gold labels or inter-annotator agreement reported on the five benchmarks. This leaves the possibility that reported gains (Macro F1 0.8456) arise from LLM knowledge transfer rather than the taxonomy supplying independent, auditable signal.
- [§5 / Table 2] §5 (Experiments) and Table 2: The robustness result (strongest deep baseline degrades from 0.9454 to 0.6194 under genre imbalance) is presented as evidence that the taxonomic fusion helps, but without an ablation that removes or randomizes the 17-dimensional component while keeping the LLM elicitation step, it is impossible to isolate whether the taxonomy or the underlying LLM priors drive the stability.
minor comments (2)
- [§4.1] §4.1: The Heterogeneous Multi-Head Attention fusion is described at a high level; adding a diagram or explicit equations for how the 17 taxonomic dimensions are projected into the attention heads would improve reproducibility.
- [Related Work] Related Work: Several recent LLM-based disinformation detectors (e.g., those using chain-of-thought or knowledge-graph augmentation) are cited only briefly; a more systematic comparison table would clarify the precise novelty of the entropy-smoothing reconciliation step.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments below, providing clarifications and proposing revisions where appropriate to strengthen the validation of our approach.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Taxonomy Elicitation): The premise that the 17-dimensional space captures 'multi-faceted manipulative intents' that surface-level or external-knowledge methods miss is load-bearing for the performance claim, yet the manuscript describes LLM-elicited labels without any human-annotated gold labels or inter-annotator agreement reported on the five benchmarks. This leaves the possibility that reported gains (Macro F1 0.8456) arise from LLM knowledge transfer rather than the taxonomy supplying independent, auditable signal.
Authors: We acknowledge the value of human validation for confirming that the elicited labels align with the intended taxonomy. The 17 categories are derived from established taxonomies in the literature on persuasion, emotion, and narrative (see §3 for references). The LLM elicitation is structured to assign instances to these predefined categories rather than generating free-form explanations. To address the concern, we will conduct a human annotation study on a sample from the benchmarks, reporting agreement metrics, and include these results in the revised manuscript. This will help demonstrate that the taxonomy provides structured signal beyond raw LLM capabilities. revision: yes
-
Referee: [§5 / Table 2] §5 (Experiments) and Table 2: The robustness result (strongest deep baseline degrades from 0.9454 to 0.6194 under genre imbalance) is presented as evidence that the taxonomic fusion helps, but without an ablation that removes or randomizes the 17-dimensional component while keeping the LLM elicitation step, it is impossible to isolate whether the taxonomy or the underlying LLM priors drive the stability.
Authors: We agree that an ablation isolating the contribution of the structured 17-dimensional taxonomy versus general LLM knowledge would be informative. Note that the LLM elicitation step is specifically designed to populate the taxonomy dimensions; a direct removal while keeping elicitation is not straightforward as the two are coupled. We will add an ablation study in the revision comparing against variants that use unstructured LLM features without taxonomy alignment and with randomized labels to clarify the taxonomy's role in robustness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a 17-dimensional taxonomy by author choice, elicits labels via LLM prompting, reconciles them with a smoothing step, and fuses via attention before reporting benchmark F1 scores. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described framework. The performance numbers are measured against independent ground-truth labels on external datasets and do not reduce by construction to quantities defined from the same inputs. The construction is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frontier LLMs can be prompted to assign the 17 taxonomic attributes reliably enough for downstream fusion
- domain assumption The chosen 6+5+6 categories together capture the relevant manipulative pathways that syntax or knowledge checks miss
Reference graph
Works this paper leans on
-
[1]
Jason Lucas, Adaku Uchendu, Michiharu Yamashita, Jooyoung Lee, Shaurya Rohatgi, and Dongwon Lee
Industrialized Deception: The Collateral Ef- fects of LLM-Generated Misinformation on Digital Ecosystems.Preprint, arXiv:2601.21963. Jason Lucas, Adaku Uchendu, Michiharu Yamashita, Jooyoung Lee, Shaurya Rohatgi, and Dongwon Lee
-
[2]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 14279–14305, Singapore
Fighting Fire with Fire: The Dual Role of LLMs in Crafting and Detecting Elusive Disinfor- mation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 14279–14305, Singapore. Association for Computational Linguistics. Tarek Mahmoud, Zhuohan Xie, Dimitar Iliyanov Dim- itrov, Nikolaos Nikolaidis, Purificação Sil...
2023
-
[3]
Attack_on_reputation
Cross-sean: A cross-stitch semi-supervised neural attention model for covid-19 fake news detec- tion.Applied Soft Computing, 107:107393 – 107393. Susannah B. F. Paletz, Michael A. Johns, Egle E. Mu- rauskaite, Ewa M. Golonka, Nick B. Pandža, C. An- ton Rytting, Cody Buntain, and Devin Ellis. 2023. Emotional content and sharing on Facebook: A the- ory cage...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.