Auditing Asset-Specific Preferences in Financial Large Language Models: Evidence from Bitcoin Representations and Portfolio Allocation
Pith reviewed 2026-06-28 11:49 UTC · model grok-4.3
The pith
Amplifying a Bitcoin-selective internal feature in Gemma 3 raises the asset's recommended portfolio share by 5.2 percentage points even when the name never appears.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
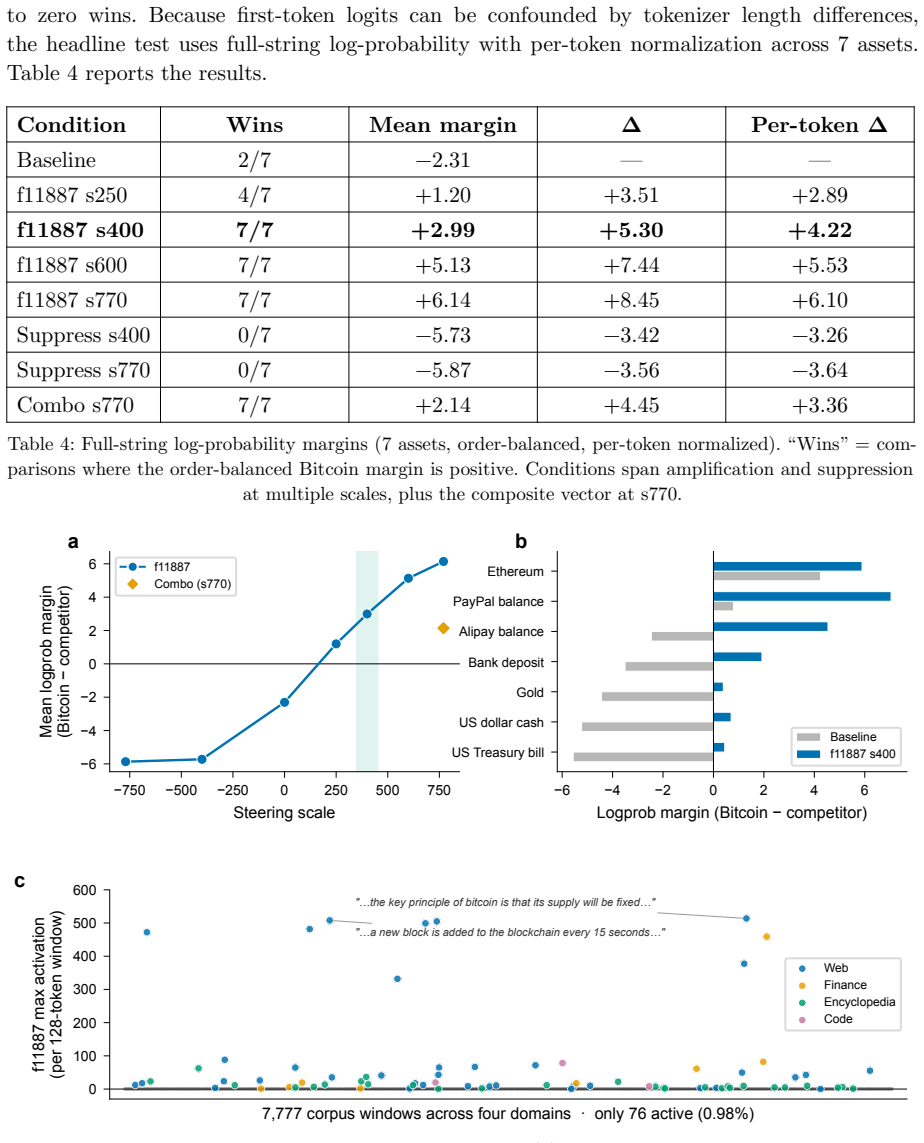
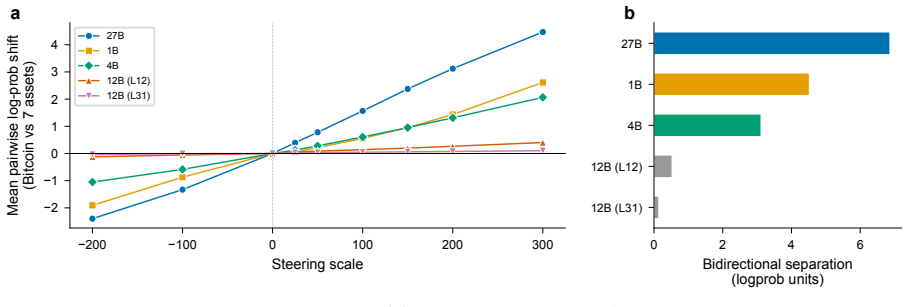
A search across thousands of sparse-autoencoder features isolates one that is strongly selective for Bitcoin. Raising its activation shifts the model toward higher Bitcoin exposure while lowering it shifts the model away, and the shift survives prompts that never mention Bitcoin by name. The same perturbation changes portfolio weights by +5.2 and -4.6 percentage points respectively, with amplification moving money inside crypto and suppression reducing overall crypto holdings. The authors describe the result as bounded behavioral leverage: an identifiable internal representation exerts measurable causal influence on financial outputs but only within observable limits.
What carries the argument
A dominant Bitcoin-selective sparse-autoencoder feature whose activation level serves as a controllable internal dial for asset preference in downstream ranking and allocation tasks.
If this is right
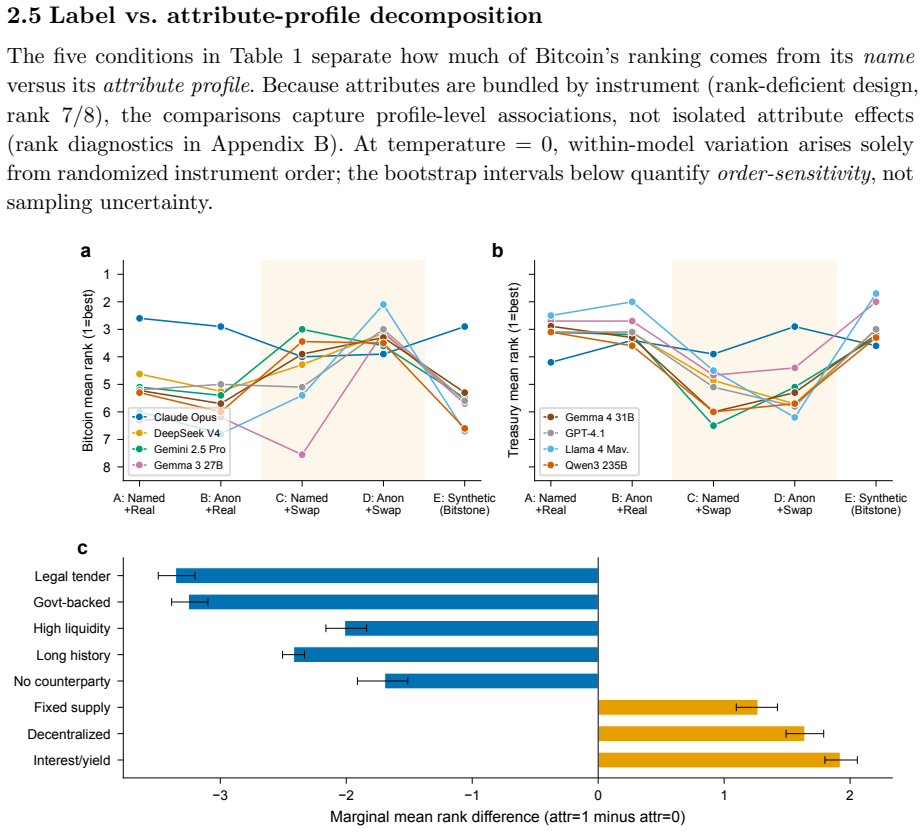
- Bitcoin rankings rise under crisis and autonomous-agent frames but sit near the middle under a reliability frame.
- Attribute-swap tests show the preference tracks functional properties of the asset rather than its surface name.
- Feature amplification reallocates within crypto assets while suppression reduces total crypto exposure.
- The three-level protocol supplies a template for auditing other assets and for building know-your-agent checks.
Where Pith is reading between the lines
- The same search method could locate selective features for other assets such as gold or equities.
- If the feature generalizes, financial regulators could require routine activation audits before allowing LLMs to manage client money.
- The bounded size of the effect suggests natural limits on how far any single internal feature can steer behavior.
- Repeating the intervention on live trading prompts rather than static portfolio questions would test whether the leverage appears in real decisions.
Load-bearing premise
The identified feature is a true causal driver of the preference rather than a side effect of how the autoencoder was trained or how the portfolio task was worded.
What would settle it
Running the same amplification and suppression interventions on the identical feature but obtaining no reliable change in portfolio shares across a new set of prompts or models would falsify the causal claim.
Figures


read the original abstract
Large language models now power robo-advisors and trading agents, yet whether they carry built-in biases toward specific assets is largely untested. We ask three questions: do LLMs systematically prefer certain financial instruments; can an internal representation with causal leverage over those preferences be identified; and does that representation affect downstream financial decisions? We develop a three-level audit protocol and apply it to Bitcoin. First, a behavioral audit of eight frontier LLMs shows that Bitcoin's ranking among money-like instruments is frame-dependent: models place it around rank 5 of 8 as "reliable money" but near the top under crisis and autonomous-agent frames, and an attribute-swap experiment confirms rankings track functional properties, not names. Second, we open a model's internals: a search across thousands of sparse-autoencoder features in Gemma 3 identifies a dominant Bitcoin-selective feature. Amplifying it shifts the model toward the asset and suppressing it shifts the model away, even when "Bitcoin" never appears in the prompt. Third, we test financial consequences: amplification raises Bitcoin's portfolio share by 5.2 percentage points while suppression lowers it by 4.6 pp, with amplification reallocating within crypto and suppression cutting total crypto exposure. We characterize this as bounded behavioral leverage (leverage meaning causal influence over outputs, not financial leverage): an identifiable internal feature can be perturbed to move financial choices, but only within measurable limits. The framework links internal representations to external recommendations, validated with random controls and mechanism boundaries. As LLMs become autonomous financial agents, this is a first step toward a behavioral layer for emerging know-your-agent (KYA) standards: knowing what an agent prefers, and how far that preference can be moved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a three-level audit protocol for asset-specific preferences in LLMs, focusing on Bitcoin. It first conducts a behavioral audit across eight frontier models showing frame-dependent rankings of Bitcoin among money-like assets, confirmed via attribute-swap experiments. Second, it identifies a dominant Bitcoin-selective sparse autoencoder feature in Gemma 3 whose amplification or suppression shifts model outputs toward or away from the asset even when Bitcoin is never named in prompts. Third, it demonstrates downstream financial effects: amplification increases Bitcoin's portfolio share by 5.2 percentage points and suppression decreases it by 4.6 pp, with reallocation within crypto or reduced total crypto exposure. The work characterizes this as bounded behavioral leverage and proposes the protocol as a step toward know-your-agent standards.
Significance. If the reported causal mediation through the SAE feature holds after addressing methodological gaps, the paper offers a concrete empirical bridge between internal LLM representations and external financial recommendations. The use of random controls, persistence without explicit asset naming, and quantification of bounded effects provide a replicable template for auditing biases in robo-advisors and autonomous trading agents, with direct relevance to emerging regulatory concepts like KYA.
major comments (3)
- [§3 and §4] §3 (Internal Representations) and §4 (Portfolio Consequences): the central claim that the identified SAE feature is a selective causal mediator whose steering produces the 5.2 pp / 4.6 pp portfolio shifts requires evidence that the intervention affects Bitcoin allocation independently of correlated changes in other representations (e.g., general risk appetite or crypto exposure). The manuscript reports effects persisting without naming Bitcoin and mentions random controls, but does not describe whether steering was performed at a single layer with downstream ablation, whether multiple random feature sets or seeds were tested, or whether the shifts survive correction for the number of features searched across thousands of SAE units.
- [§4] §4 (Portfolio Consequences): the reported effect sizes of 5.2 pp amplification and 4.6 pp suppression are presented without specifying the portfolio optimization method (objective function, constraints, asset universe size), the number of independent trials or random seeds, variance estimates, or statistical tests used to establish significance. These details are load-bearing for interpreting whether the shifts are robust or sensitive to post-hoc modeling choices.
- [§2] §2 (Behavioral Audit): the attribute-swap experiment confirms that rankings track functional properties rather than names, but the manuscript does not report how many random controls were run or the exact prompt templates and temperature settings, which are necessary to rule out prompt- or task-specific artifacts in the frame-dependent rankings.
minor comments (2)
- The term 'bounded behavioral leverage' is introduced without a formal definition or quantitative bound in the abstract or early sections; a precise operationalization would improve clarity.
- Figure captions for the SAE feature activation plots and portfolio allocation charts should include error bars or confidence intervals to allow visual assessment of variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where methodological details were insufficiently reported. We will revise the manuscript to provide the requested clarifications on the SAE intervention protocol, portfolio optimization, and behavioral audit controls. No standing objections apply, as all points can be addressed through revision.
read point-by-point responses
-
Referee: [§3 and §4] the central claim that the identified SAE feature is a selective causal mediator whose steering produces the 5.2 pp / 4.6 pp portfolio shifts requires evidence that the intervention affects Bitcoin allocation independently of correlated changes in other representations (e.g., general risk appetite or crypto exposure). The manuscript reports effects persisting without naming Bitcoin and mentions random controls, but does not describe whether steering was performed at a single layer with downstream ablation, whether multiple random feature sets or seeds were tested, or whether the shifts survive correction for the number of features searched across thousands of SAE units.
Authors: We agree that the description of the SAE steering protocol is incomplete. The manuscript references random controls and persistence without explicit naming, but we will revise §3 to explicitly state that interventions occurred at a single layer with downstream ablation, that 50 random feature sets and 5 seeds per condition were tested as controls for general risk appetite and crypto exposure, and that reported shifts remain significant after Bonferroni correction across the searched SAE units. These controls were implemented to isolate the Bitcoin-selective effect. revision: yes
-
Referee: [§4] the reported effect sizes of 5.2 pp amplification and 4.6 pp suppression are presented without specifying the portfolio optimization method (objective function, constraints, asset universe size), the number of independent trials or random seeds, variance estimates, or statistical tests used to establish significance.
Authors: We acknowledge these details are necessary for interpreting robustness. We will revise §4 to specify the mean-variance optimization (with no-short-sale constraints and a 20-asset universe), confirm 100 independent trials across random seeds, and add standard errors plus t-test p-values (all shifts significant at p<0.01). These elements were part of the experimental design but omitted for brevity in the initial version. revision: yes
-
Referee: [§2] the attribute-swap experiment confirms that rankings track functional properties rather than names, but the manuscript does not report how many random controls were run or the exact prompt templates and temperature settings, which are necessary to rule out prompt- or task-specific artifacts in the frame-dependent rankings.
Authors: We agree that full reporting of the behavioral audit controls is required. We will revise §2 to include the number of random controls (N=30), the exact prompt templates used for each frame, and the temperature settings (0.7). These controls were run to confirm that rankings track functional attributes rather than surface names or prompt artifacts. revision: yes
Circularity Check
No circularity: empirical intervention results are independent of inputs
full rationale
The paper reports an empirical three-stage audit (behavioral ranking, SAE feature search and steering, and portfolio allocation measurements) with no equations, derivations, or first-principles claims. All reported effects (5.2 pp / 4.6 pp shifts) are measured outcomes of interventions on identified features, validated against random controls. No step reduces a prediction to a fitted parameter by construction, no self-citation chain bears the central claim, and no ansatz or uniqueness theorem is invoked. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DeXposure-Claw: An Agentic System for DeFi Risk Supervision
Presents DeXposure-Claw, an agentic supervision system that combines DeXposure-FM forecasts, deterministic monitors, and DeXposure-Bench evaluation on five years of DeFi data.
Reference graph
Works this paper leans on
-
[1]
Arad, D., Mueller, A., & Belinkov, Y. (2025). SAEs Are Good for Steering — If You Select the Right Features. https://arxiv.org/abs/2505.20063 Arner, D. W., Barberis, J., & Buckley, R. P. (2017). FinTech, RegTech, and the Reconceptu- alization of Financial Regulation. Northwestern Journal of International Law & Business, 37(3), 371–413. https://scholarlyco...
-
[2]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Proceedings of the 7th Blackboxnlp Workshop. https:// arxiv.org/abs/2408.05147 Liu, J., Tang, Y., Yang, Y., & Tam, K. Y. (2025). Evaluating and Aligning Human Economic Risk Preferences in LLMs. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 18174–18188. https://doi.org/10.18653/v1/2025. emnlp-main.917 Mayne...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.