GRAPE: Graph-Augmented Prototype Explanations for Interactive Medical Image Diagnosis
Pith reviewed 2026-07-01 01:47 UTC · model grok-4.3
The pith
GRAPE combines graph attention, safety checks, and text-based anchoring to overcome independence, unsafe feedback, and retraining limits in prototype medical image classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRAPE is a unified architecture that addresses three clinical limitations of prototype-based medical image classifiers: independent findings, unsafe feedback amplification, and full retraining for new findings. It does so through graph attention for co-occurrence, a concept-mismatch safety check, and open-vocabulary prototype anchoring aligned to clinical text, as shown by performance gains on TBX11K and NIH ChestX-ray14 datasets.
What carries the argument
Graph-Augmented Prototype Explanations (GRAPE) with its Graph Attention Task Head, Concept-Mismatch Safety Check, and Open-Vocabulary Prototype Anchoring mechanism.
If this is right
- Graph attention modeling of concept co-occurrence raises macro-F1 by 13.8 points on TBX11K.
- The safety check detects 85% of erroneous annotations compared to 51% for MC-Dropout.
- A new finding can be added from a single labeled image without retraining other components.
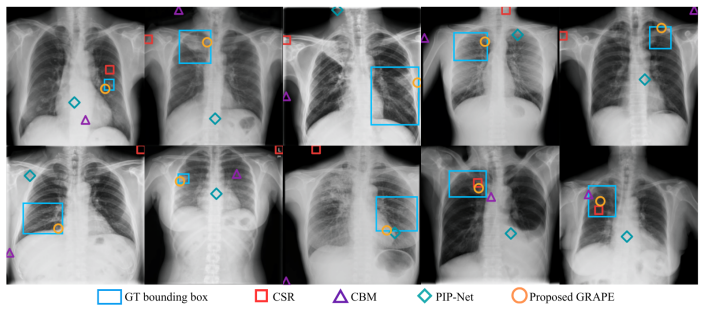
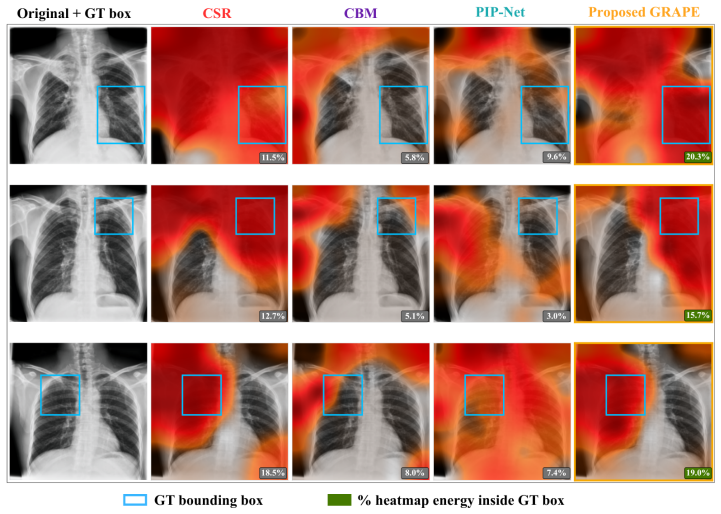
- Prototype localization improves 2.6 times over end-to-end baselines on TBX11K.
- The full system adds only 1 ms latency at interactive batch sizes.
Where Pith is reading between the lines
- The safety mechanism could extend to other interactive AI systems where user input might be erroneous.
- Single-example addition via text might enable rapid adaptation in other vision tasks with descriptive labels.
- The approach suggests prototype methods could support continuous learning in medical imaging without full retraining cycles.
Load-bearing premise
A single labeled image aligned with text is sufficient to add a new finding without loss of performance on prior findings, and the safety check generalizes to other error types.
What would settle it
An experiment adding multiple new findings one by one from single images and checking if performance on the original findings remains stable, or applying the safety check to annotation errors different from those in the TBX11K tests.
Figures


read the original abstract
Prototype-based medical image classifiers present three clinical limitations: they treat findings as independent, silently amplify unsafe physician feedback, and require full retraining whenever a new finding is needed. We present GRAPE (Graph-Augmented Prototype Explanations), a unified architecture that addresses all three challenges. First, a Graph Attention Task Head models anatomical concept co-occurrence, boosting macro-F1 by +13.8,pp over the prototype baseline on TBX11K. Second, a Concept-Mismatch Safety Check - the first such mechanism in prototype-based medical classifiers - warns when the model's dominant finding inside a doctor-drawn region conflicts with the claimed label, catching 85% of erroneous annotations versus 51% for MC-Dropout with no extra inference cost. Third, Open-Vocabulary Prototype Anchoring aligns visual prototypes to clinical text, allowing a new finding to be added from a single labeled image without modifying any other component. On NIH ChestX-ray14, one Effusion example recovers full-supervision localization accuracy; on TBX11K, prototype maps achieve 2.6x better lesion localization than end-to-end baselines. All three capabilities add only +1~ms latency at interactive batch size. The project page is https://github.com/KurbanIntelligenceLab/GRAPE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRAPE, a unified prototype-based architecture for medical image diagnosis that incorporates (1) a Graph Attention Task Head to model anatomical concept co-occurrence, (2) a Concept-Mismatch Safety Check to detect label errors in physician feedback, and (3) Open-Vocabulary Prototype Anchoring to add new findings from a single labeled image via text alignment without retraining. It reports +13.8 pp macro-F1 on TBX11K, 85% erroneous annotation detection (vs. 51% MC-Dropout), single-image Effusion addition on NIH ChestX-ray14 recovering full-supervision localization, 2.6x better lesion localization, and +1 ms latency.
Significance. If the empirical claims hold under rigorous verification, GRAPE would represent a meaningful advance in making prototype-based classifiers clinically viable by jointly handling co-occurrence, safety, and incremental adaptation with negligible overhead. The low-latency interactive setting and explicit safety mechanism are particularly relevant to deployment constraints in medical imaging.
major comments (2)
- [Abstract] Abstract (Open-Vocabulary Prototype Anchoring paragraph): the central claim that a new finding can be added from one labeled image 'without modifying any other component' and without harming prior performance is load-bearing for the unified-architecture argument, yet the manuscript reports only that the new Effusion prototype recovers localization accuracy; no before/after macro-F1, per-class accuracy, or localization metrics are supplied for the original 13 findings on NIH or TBX11K. In a shared embedding space this omission leaves the no-interference guarantee unverified.
- [Abstract] Abstract (Graph Attention Task Head paragraph): the +13.8 pp macro-F1 gain is presented as evidence that modeling co-occurrence addresses the independence limitation, but the abstract supplies neither the exact baseline prototype model, ablation isolating the graph component, nor statistical significance tests, rendering the magnitude and attribution of the gain difficult to evaluate.
minor comments (2)
- [Abstract] Abstract: '+13.8,pp' contains a typographical error (comma instead of space).
- [Abstract] Abstract: the phrase 'the first such mechanism in prototype-based medical classifiers' is an absolute claim that would benefit from a brief literature qualifier or footnote.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (Open-Vocabulary Prototype Anchoring paragraph): the central claim that a new finding can be added from one labeled image 'without modifying any other component' and without harming prior performance is load-bearing for the unified-architecture argument, yet the manuscript reports only that the new Effusion prototype recovers localization accuracy; no before/after macro-F1, per-class accuracy, or localization metrics are supplied for the original 13 findings on NIH or TBX11K. In a shared embedding space this omission leaves the no-interference guarantee unverified.
Authors: We agree that the no-interference claim requires explicit verification. The current manuscript reports recovery of localization accuracy for the added Effusion prototype but does not supply before/after metrics for the original findings. We will add these comparisons (macro-F1, per-class accuracy, and localization metrics on the original 13 findings before and after addition) to the revised manuscript and update the abstract to reference the no-degradation result. revision: yes
-
Referee: [Abstract] Abstract (Graph Attention Task Head paragraph): the +13.8 pp macro-F1 gain is presented as evidence that modeling co-occurrence addresses the independence limitation, but the abstract supplies neither the exact baseline prototype model, ablation isolating the graph component, nor statistical significance tests, rendering the magnitude and attribution of the gain difficult to evaluate.
Authors: The abstract identifies the gain as over 'the prototype baseline' (defined in Section 3.2 as the standard prototype classifier). Ablations isolating the graph attention component and statistical significance tests appear in Table 2 and Section 4.2. We will revise the abstract to add a brief clause referencing these supporting results for improved clarity. revision: partial
Circularity Check
No derivation chain present; claims are empirical
full rationale
The provided manuscript text and abstract contain no equations, derivations, or first-principles steps. All central claims (macro-F1 gains, safety-check rates, single-image prototype addition) are presented as experimental outcomes on TBX11K and NIH ChestX-ray14. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations appear. The architecture is described at the level of components and results, making the paper self-contained against external benchmarks with no circular reduction possible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to exploit temporal structure for biomedical vision-language processing
Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. Learning to exploit temporal structure for biomedical vision-language processing. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15016–15...
2023
-
[2]
B-cos alignment for inherently interpretable cnns and vision transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4504–4518, 2024
Moritz Böhle, Navdeeppal Singh, Mario Fritz, and Bernt Schiele. B-cos alignment for inherently interpretable cnns and vision transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4504–4518, 2024
2024
-
[3]
This looks like that: deep learning for interpretable image recognition.Advances in Neural Information Processing Systems, 32, 2019
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[4]
Multi-label image recognition with graph convolutional networks
Zhao-Min Chen, Xiu-Shen Wei, Peng Wang, and Yanwen Guo. Multi-label image recognition with graph convolutional networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5177–5186, 2019
2019
-
[5]
Deformable protopnet: An interpretable image classifier using deformable prototypes
Jon Donnelly, Alina Jade Barnett, and Chaofan Chen. Deformable protopnet: An interpretable image classifier using deformable prototypes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10265–10275, 2022
2022
-
[6]
Concept embedding models: Beyond the accuracy-explainability trade-off
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelangelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, et al. Concept embedding models: Beyond the accuracy-explainability trade-off. Advances in Neural Information Processing systems, 35:21400–21413, 2022
2022
-
[7]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InInternational Conference on Machine Learning, pages 1050–1059. PMLR, 2016
2016
-
[8]
Interactive medical image analysis with concept-based similarity reasoning
Ta Duc Huy, Sen Kim Tran, Phan Nguyen, Nguyen Hoang Tran, Tran Bao Sam, Anton Van Den Hengel, Zhibin Liao, Johan W Verjans, Minh-Son To, and Vu Minh Hieu Phan. Interactive medical image analysis with concept-based similarity reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30797–30806, 2025
2025
-
[9]
Acquisition of localiza- tion confidence for accurate object detection
Borui Jiang, Ruixuan Luo, Jiayuan Mao, Tete Xiao, and Yuning Jiang. Acquisition of localiza- tion confidence for accurate object detection. InProceedings of the European Conference on Computer Vision (ECCV), pages 784–799, 2018
2018
-
[10]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational Conference on Machine Learning, pages 5338–5348. PMLR, 2020
2020
-
[11]
Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in Neural Information Processing Systems, 30, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[12]
Revisiting computer-aided tuberculosis diagnosis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2316–2332, 2023
Yun Liu, Yu-Huan Wu, Shi-Chen Zhang, Li Liu, Min Wu, and Ming-Ming Cheng. Revisiting computer-aided tuberculosis diagnosis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2316–2332, 2023
2023
-
[13]
This looks like those: Illuminating prototypical concepts using multiple visualizations.Advances in Neural Information Processing Systems, 36:39212–39235, 2023
Chiyu Ma, Brandon Zhao, Chaofan Chen, and Cynthia Rudin. This looks like those: Illuminating prototypical concepts using multiple visualizations.Advances in Neural Information Processing Systems, 36:39212–39235, 2023. 10
2023
-
[14]
Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289, 2021
Andrei Margeloiu, Matthew Ashman, Umang Bhatt, Yanzhi Chen, Mateja Jamnik, and Adrian Weller. Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289, 2021
-
[15]
Pip-net: Patch-based intuitive prototypes for interpretable image classification
Meike Nauta, Jörg Schlötterer, Maurice Van Keulen, and Christin Seifert. Pip-net: Patch-based intuitive prototypes for interpretable image classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2744–2753, 2023
2023
-
[16]
Neural prototype trees for interpretable fine-grained image recognition
Meike Nauta, Ron Van Bree, and Christin Seifert. Neural prototype trees for interpretable fine-grained image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14933–14943, 2021
2021
-
[17]
RISE: Randomized Input Sampling for Explanation of Black-box Models
Vitali Petsiuk, Abir Das, and Kate Saenko. Rise: Randomized input sampling for explanation of black-box models.arXiv preprint arXiv:1806.07421, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
Pranav Rajpurkar, Jeremy Irvin, Kaylie Zhu, Brandon Yang, Hershel Mehta, Tony Duan, Daisy Ding, Aarti Bagul, Curtis Langlotz, Katie Shpanskaya, et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning.arXiv preprint arXiv:1711.05225, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Dawid Rymarczyk, Łukasz Struski, Jacek Tabor, and Bartosz Zieli ´nski. Protopshare: Pro- totype sharing for interpretable image classification and similarity discovery.arXiv preprint arXiv:2011.14340, 2020
-
[20]
Evidential deep learning to quantify classification uncertainty.Advances in Neural Information Processing Systems, 31, 2018
Murat Sensoy, Lance Kaplan, and Melih Kandemir. Evidential deep learning to quantify classification uncertainty.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[21]
Right for better reasons: Training differentiable models by constraining their influence functions
Xiaoting Shao, Arseny Skryagin, Wolfgang Stammer, Patrick Schramowski, and Kristian Kersting. Right for better reasons: Training differentiable models by constraining their influence functions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 9533–9540, 2021
2021
-
[22]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Interactive medical image segmentation using deep learning with image-specific fine tuning.IEEE Transactions on Medical Imaging, 37(7):1562–1573, 2018
Guotai Wang, Wenqi Li, Maria A Zuluaga, Rosalind Pratt, Premal A Patel, Michael Aertsen, Tom Doel, Anna L David, Jan Deprest, Sébastien Ourselin, et al. Interactive medical image segmentation using deep learning with image-specific fine tuning.IEEE Transactions on Medical Imaging, 37(7):1562–1573, 2018
2018
-
[24]
Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly- supervised classification and localization of common thorax diseases
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly- supervised classification and localization of common thorax diseases. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2097–2106, 2017
2097
-
[25]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3876–3887, 2022
2022
-
[26]
MProtoNet: A case-based interpretable model for brain tumor classification with 3D multi-parametric magnetic resonance imaging
Yuanyuan Wei, Roger Tam, and Xiaoying Tang. MProtoNet: A case-based interpretable model for brain tumor classification with 3D multi-parametric magnetic resonance imaging. InMedical Imaging with Deep Learning, Nashville, United States, July 2023
2023
-
[27]
Attention-driven dynamic graph convolutional network for multi-label image recognition
Jin Ye, Junjun He, Xiaojiang Peng, Wenhao Wu, and Yu Qiao. Attention-driven dynamic graph convolutional network for multi-label image recognition. InEuropean Conference on Computer Vision, pages 649–665. Springer, 2020
2020
-
[28]
Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022
-
[29]
Top-down neural attention by excitation backprop.International Journal of Computer Vision, 126(10):1084–1102, 2018
Jianming Zhang, Sarah Adel Bargal, Zhe Lin, Jonathan Brandt, Xiaohui Shen, and Stan Sclaroff. Top-down neural attention by excitation backprop.International Journal of Computer Vision, 126(10):1084–1102, 2018. 11
2018
-
[30]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023. Appendix overview The supplementary material is organized as follows. A...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Modular interpretability.Staged training decouples concept learning, prototype learning, and task classification; each stage can be inspected, retrained, or replaced independently
-
[32]
0.091), directly reflecting more faithful prototype localisation
Spatial faithfulness.Staged training achieves higher and more stable PG (0.111 vs. 0.091), directly reflecting more faithful prototype localisation
-
[33]
Few-shot responsiveness.Staged prototypes respond more cleanly to few-shot fine-tuning for new concepts, a property required for Module C in clinical deployment. We recommend E2E training for practitioners where classification accuracy is the primary goal and interpretability and zero-shot addition are not required. D Dataset Details TBX11K concept descri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.