Weibull Weight-Scale Parameter Evolution under AdamW Training Dynamics
Pith reviewed 2026-06-27 07:32 UTC · model grok-4.3
The pith
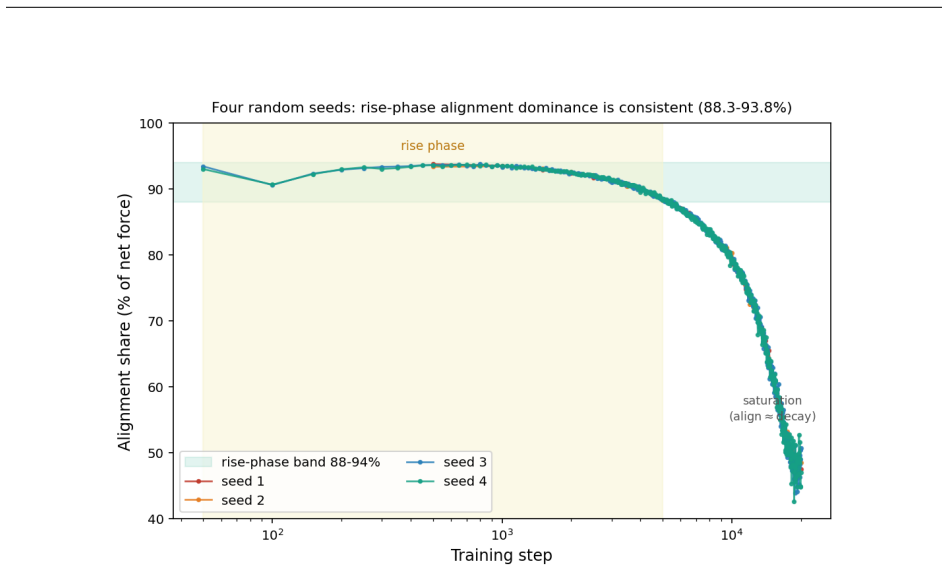
AdamW's alignment force drives 88-94% of the rise in the Weibull weight-scale parameter λ before balancing with decay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
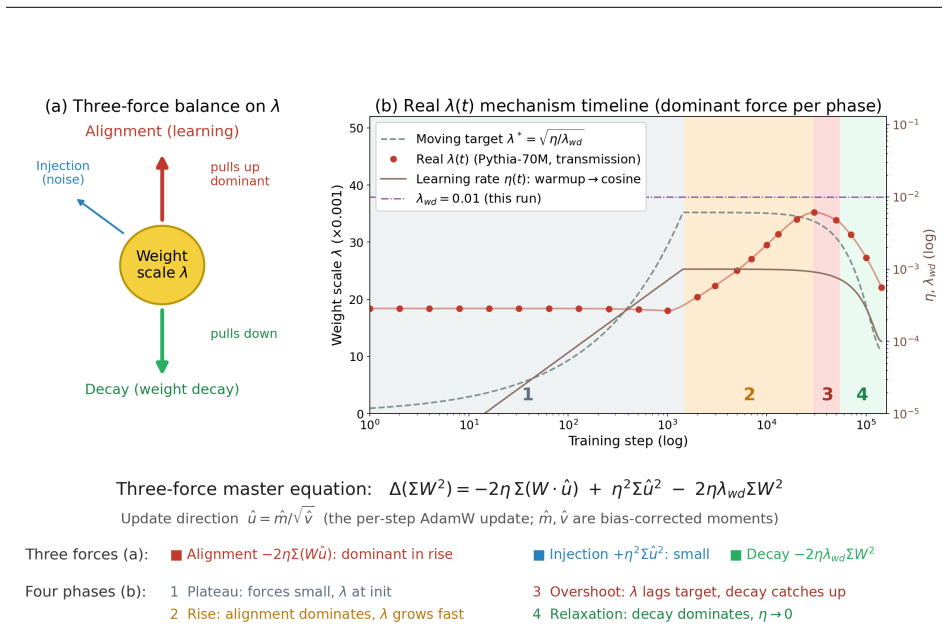
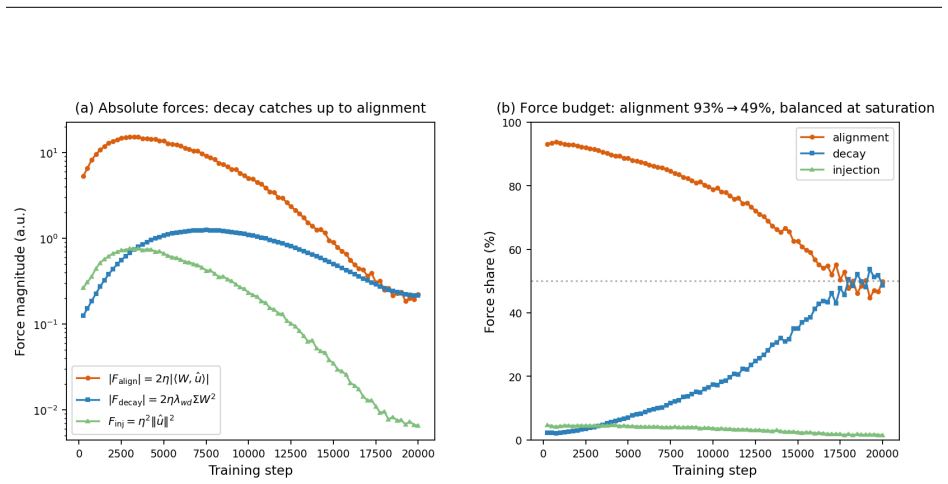
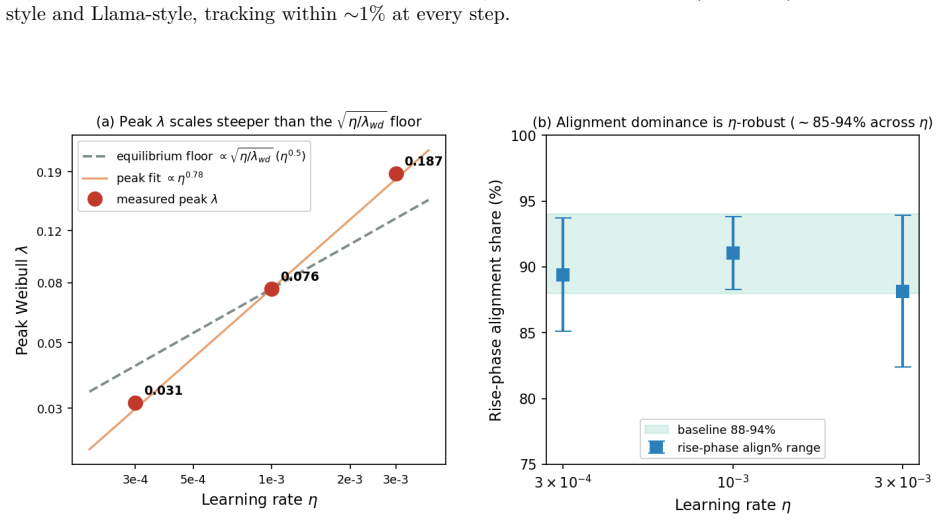
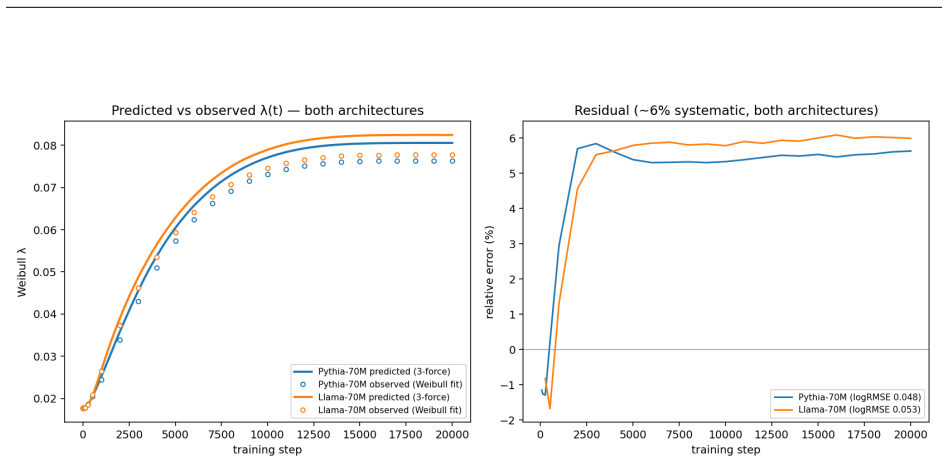
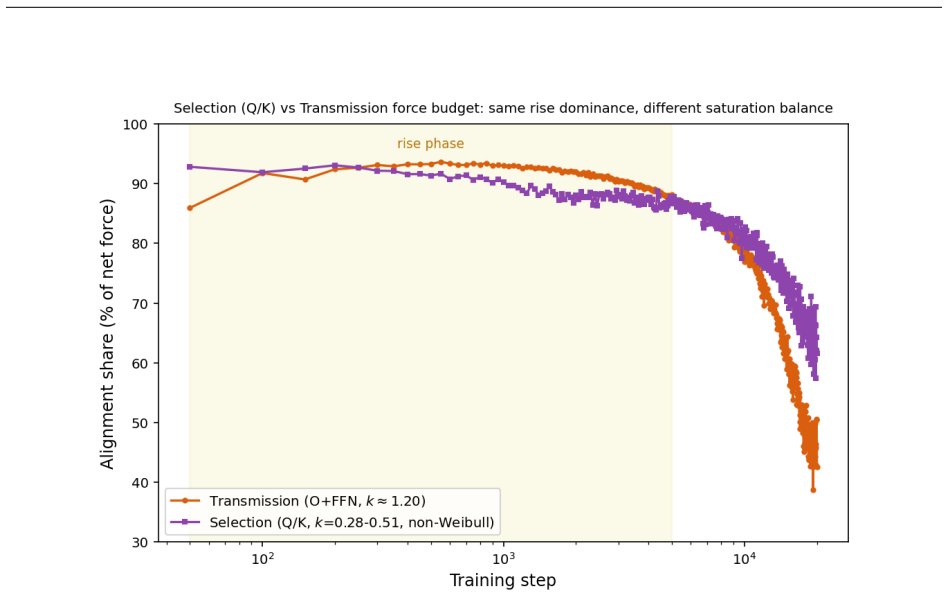
The leading-order three-force decomposition of the squared weight norm from the AdamW update rule shows that the alignment force dominates the rise phase of λ(t), contributing 88-94% of the absolute force budget across random seeds, while near saturation alignment and decay approach balance to explain the transition from growth to relaxation.
What carries the argument
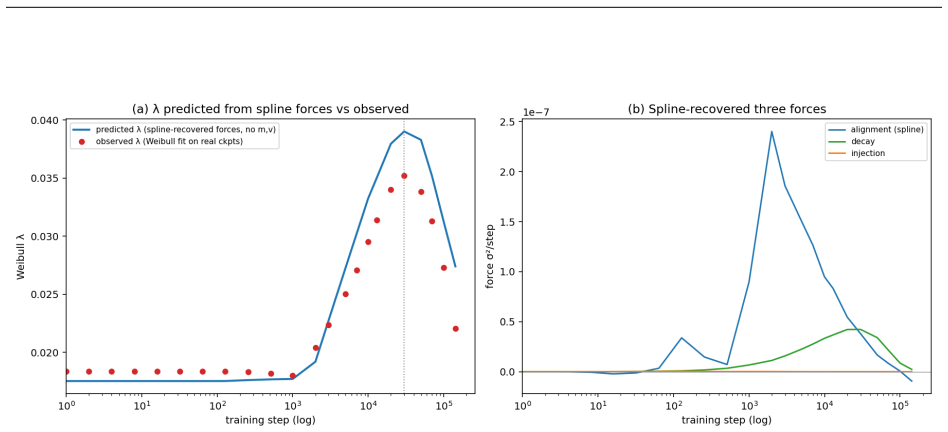
Leading-order three-force decomposition of the squared weight norm consisting of alignment force (correlation between weights and adaptive update direction), injection force (adaptive step magnitude), and decay force (decoupled weight decay).
If this is right
- The squared-norm component underlying λ(t) is governed by the balance among alignment, injection, and decay forces.
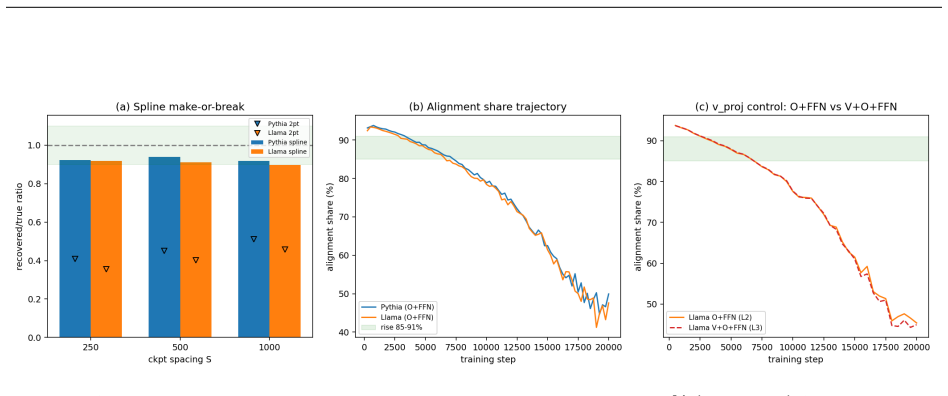
- The RMS-to-Weibull reconstruction offset remains small (5-6%) and decomposes into bridge and integration terms.
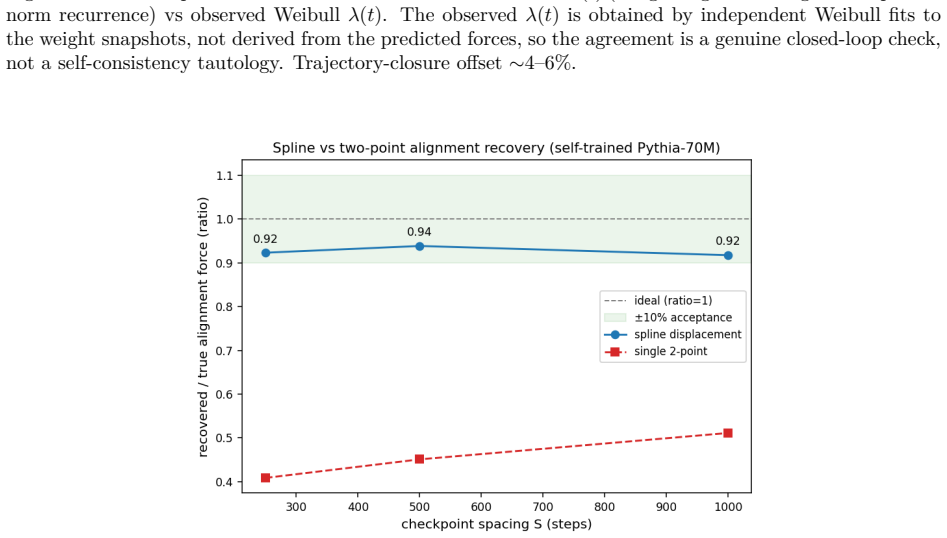
- A spline displacement method recovers the alignment force from sparse checkpoints at 92-94% accuracy, doubling the naive two-point baseline.
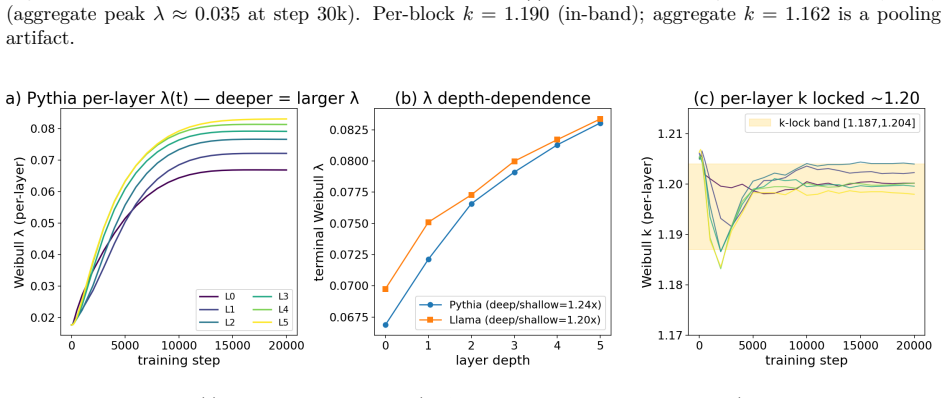
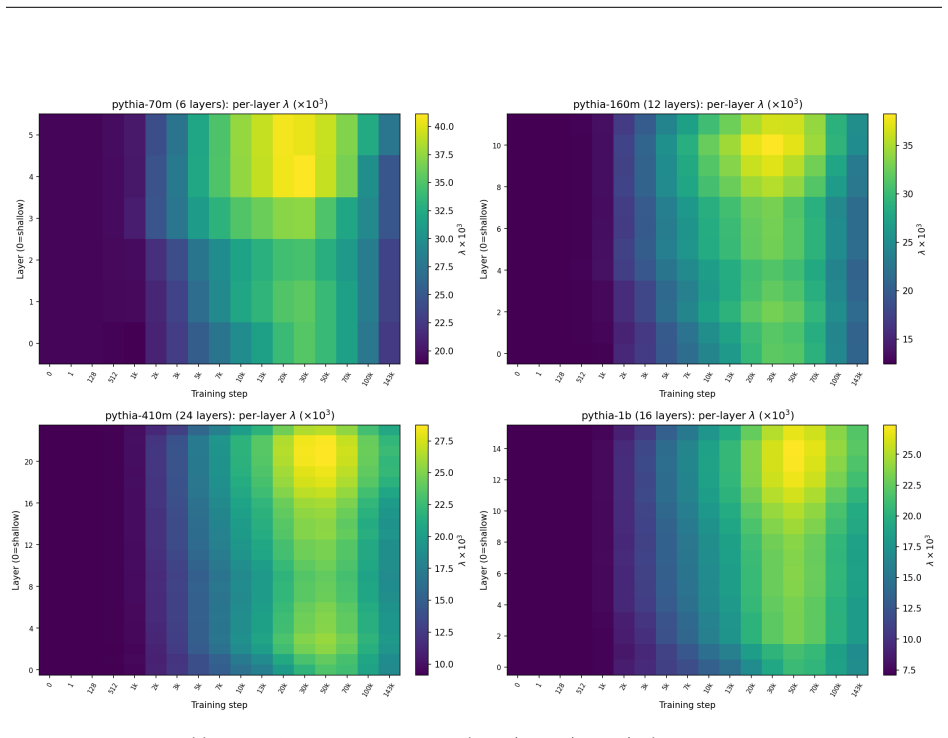
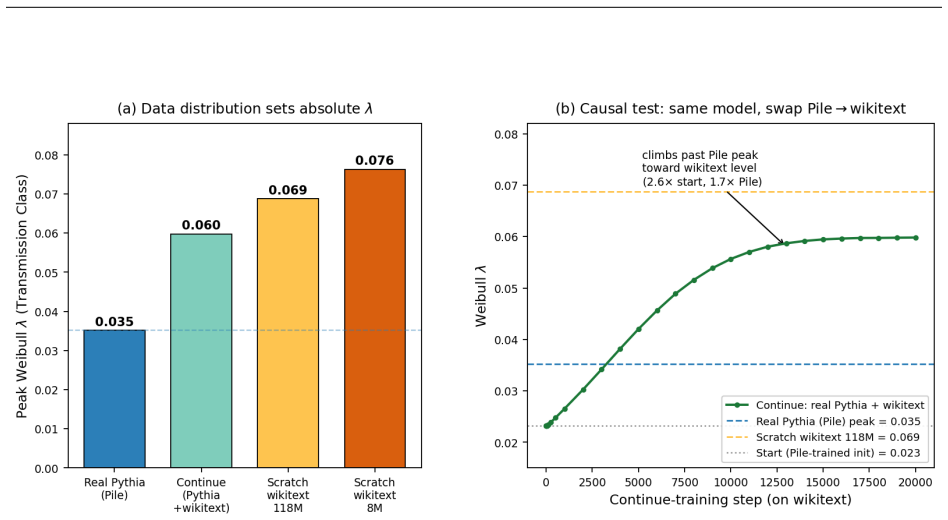
- The peak value of λ(t) varies with training-data coherence, indicating a data-dependent component of scale growth.
Where Pith is reading between the lines
- If alignment is the dominant driver, targeted interventions that reduce weight-update correlation could limit overshoot in λ without changing the optimizer.
- The spline recovery technique opens the possibility of tracking alignment dynamics in production runs where optimizer moments are not stored.
- The data-coherence dependence of peak λ suggests experiments that hold model size fixed while varying dataset structure to isolate the effect.
- The same force decomposition could be applied to other decoupled optimizers to test whether alignment dominance is specific to AdamW.
Load-bearing premise
The three-force decomposition of the squared weight norm fully captures the dynamics governing the squared-norm component of λ(t).
What would settle it
A direct measurement of the three forces during the rise phase that finds the alignment contribution below 80% or above 95% of the absolute budget would falsify the reported dominance.
Figures


read the original abstract
Building on a two-parameter Weibull framework for diagnosing transformer weight distributions, we study why the Weibull weight-scale parameter $\lambda$ grows, overshoots, and then relaxes during AdamW training. We derive a leading-order three-force decomposition of the squared weight norm from the AdamW update: an alignment force measuring the correlation between weights and the adaptive update direction, an injection force from adaptive step magnitude, and a decay force from decoupled weight decay. On self-trained Pythia-70M models with ground-truth optimizer moments, alignment dominates the rise phase, contributing 88-94% of the absolute force budget across four random seeds and remaining robust to super-weight removal. Near saturation, alignment and decay approach balance, explaining the transition from weight-scale growth to relaxation. These force dynamics directly govern the squared-norm component underlying $\lambda(t)$; the remaining RMS-to-Weibull reconstruction offset is measurable and decomposes into bridge and integration components, totaling approximately 5-6% in densely sampled regions. To extend the analysis to real models where optimizer moments are unavailable, we introduce a spline displacement method that recovers the alignment force from sparse checkpoints with approximately 92-94% accuracy, about twice the naive two-point baseline. We further observe that the peak value of $\lambda(t)$ varies with training-data coherence in our experiments, suggesting a data-dependent component of weight-scale growth that we leave to a controlled follow-up study. Code and data are available at https://github.com/tiexinding/NPM-Weibull-public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a leading-order three-force decomposition (alignment, injection, decay) of the squared weight norm directly from the AdamW update rule to explain the rise, overshoot, and relaxation of the Weibull scale parameter λ(t). On self-trained Pythia-70M models with ground-truth optimizer moments, alignment is shown to contribute 88-94% of the absolute force budget in the rise phase across four seeds and remains robust to super-weight removal; near saturation, alignment and decay balance. A spline displacement method recovers the alignment force from sparse checkpoints at 92-94% accuracy (versus a two-point baseline), and the RMS-to-Weibull offset is quantified at 5-6% and decomposed. Observations on data-coherence effects on peak λ(t) are noted for future work, with code and data released.
Significance. If the claims hold, the work supplies a direct, optimizer-equation-derived mechanistic account of weight-distribution evolution in transformers that is grounded in explicit force terms rather than post-hoc fitting. Reproducibility is strengthened by the public repository, validation against logged m/v/w states on self-trained models, and the quantified robustness checks; the spline recovery method extends the analysis beyond models with moment access.
minor comments (1)
- [Abstract] The abstract states that the spline method achieves 'approximately 92-94% accuracy, about twice the naive two-point baseline'; a brief definition or citation to the exact baseline computation in the methods or results section would improve standalone readability.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of the contributions, and recommendation to accept.
Circularity Check
No significant circularity; derivation is direct algebraic expansion from AdamW rule
full rationale
The paper's central derivation expands Δ(‖w‖²) directly from the AdamW update using logged m, v, and w values to obtain the alignment (dot-product), injection (quadratic), and decay terms. Percentages (88-94%) and the 5-6% RMS-to-Weibull offset are computed quantities from these expansions on self-trained models, not fitted parameters renamed as predictions. The spline recovery is validated at 92-94% against the identical ground-truth states. No step reduces by construction to its inputs, no load-bearing self-citation chain exists, and the Weibull framework is presupposed only as context while the force analysis remains independent and externally verifiable from the optimizer equations.
Axiom & Free-Parameter Ledger
free parameters (1)
- spline knot placement and regularization
axioms (1)
- domain assumption AdamW update can be decomposed into alignment, injection, and decay forces at leading order
Reference graph
Works this paper leans on
-
[1]
Dissecting
Balles, Lukas and Hennig, Philipp , booktitle =. Dissecting. 2018 , publisher =
2018
-
[2]
Transactions on Machine Learning Research , issn =
Feature learning as alignment: a structural property of gradient descent in non-linear neural networks , author =. Transactions on Machine Learning Research , issn =. 2024 , url =
2024
-
[4]
Weight Decay may matter more than
Kosson, Atli and Welborn, Jeremy and Liu, Yang and Jaggi, Martin and Chen, Xi , booktitle =. Weight Decay may matter more than. 2026 , note =
2026
-
[5]
International Conference on Machine Learning (ICML) , pages =
Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks , author =. International Conference on Machine Learning (ICML) , pages =. 2024 , note =
2024
-
[6]
Understanding Why Neural Networks Generalize Well Through
Liu, Jinlong and Jiang, Guoqing and Bai, Yunzhi and Chen, Ting and Wang, Huayan , booktitle =. Understanding Why Neural Networks Generalize Well Through. 2020 , note =
2020
-
[7]
Noise Is Not the Main Factor Behind the Gap Between
Kunstner, Frederik and Chen, Jacques and Lavington, Jonathan Wilder and Schmidt, Mark , booktitle =. Noise Is Not the Main Factor Behind the Gap Between. 2023 , note =
2023
-
[8]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[9]
Ding, Tiexin , year =. A Two-Parameter. 2605.18898 , archivePrefix =
-
[10]
2025 , eprint =
Correction of Decoupled Weight Decay , author =. 2025 , eprint =
2025
-
[11]
Advances in Neural Information Processing Systems 39 (NeurIPS 2025) , year =
Gradient-Weight Alignment as a Train-Time Proxy for Generalization in Classification Tasks , author =. Advances in Neural Information Processing Systems 39 (NeurIPS 2025) , year =
2025
-
[12]
International Conference on Machine Learning (ICML) , pages =
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. International Conference on Machine Learning (ICML) , pages =. 2023 , note =
2023
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , pages =
Reconciling Modern Deep Learning with Traditional Optimization Analyses: The Intrinsic Learning Rate , author =. Advances in Neural Information Processing Systems (NeurIPS) , pages =. 2020 , note =
2020
-
[14]
2025 , eprint =
Why Gradients Rapidly Increase Near the End of Training , author =. 2025 , eprint =
2025
-
[15]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Effects of Parameter Norm Growth During Transformer Training: Inductive Bias from Gradient Descent , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[16]
NeurIPS , year =
Why Do We Need Weight Decay in Modern Deep Learning? , author =. NeurIPS , year =
-
[17]
arXiv preprint arXiv:1706.05350 , year =
L2 Regularization versus Batch and Weight Normalization , author =. arXiv preprint arXiv:1706.05350 , year =
-
[18]
arXiv preprint arXiv:1812.06162 , year =
An Empirical Model of Large-Batch Training , author =. arXiv preprint arXiv:1812.06162 , year =
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Scaling Data-Constrained Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[21]
IEEE Transactions on Information Theory , volume =
The Sample Complexity of Pattern Classification with Neural Networks: The Size of the Weights is More Important than the Size of the Network , author =. IEEE Transactions on Information Theory , volume =
-
[22]
Conference on Learning Theory (COLT) , series =
Norm-Based Capacity Control in Neural Networks , author =. Conference on Learning Theory (COLT) , series =. 2015 , note =
2015
-
[23]
Journal of Machine Learning Research , volume =
Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning , author =. Journal of Machine Learning Research , volume =
-
[24]
Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , pages =
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models , author =. Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , pages =. 2022 , note =
2022
-
[25]
Yang Ba, Michelle V. Mancenido, and Rong Pan. Data diversity as implicit regularization: How does diversity shape the weight space of deep neural networks? arXiv preprint arXiv:2410.14602, 2024
arXiv 2024
-
[26]
Dissecting Adam : The sign, magnitude and variance of stochastic gradients
Lukas Balles and Philipp Hennig. Dissecting Adam : The sign, magnitude and variance of stochastic gradients. In Proceedings of the 35th International Conference on Machine Learning (ICML), volume 80 of Proceedings of Machine Learning Research, pp.\ 404--413. PMLR, 2018. arXiv:1705.07774
arXiv 2018
-
[27]
Daniel Beaglehole, Ioannis Mitliagkas, and Atish Agarwala. Feature learning as alignment: a structural property of gradient descent in non-linear neural networks. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=JXCe2ZcUXr. arXiv:2402.05271
arXiv 2024
-
[28]
Correction of decoupled weight decay, 2025
Jason Chuan-Chih Chou. Correction of decoupled weight decay, 2025. arXiv:2512.08217
Pith/arXiv arXiv 2025
-
[29]
A Two-Parameter Weibull Framework for Diagnosing Transformer Weight Distributions
Tiexin Ding. A two-parameter Weibull framework for diagnosing transformer weight distributions. arXiv:2605.18898 [cs.LG], 2026. doi:10.48550/arXiv.2605.18898
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.18898 2026
-
[30]
Robust layerwise scaling rules by proper weight decay tuning
Zhiyuan Fan, Yifeng Liu, Qingyue Zhao, Angela Yuan, and Quanquan Gu. Robust layerwise scaling rules by proper weight decay tuning. arXiv preprint arXiv:2510.15262, 2025
arXiv 2025
-
[31]
Rotational equilibrium: How weight decay balances learning across neural networks
Atli Kosson, Bettina Messmer, and Martin Jaggi. Rotational equilibrium: How weight decay balances learning across neural networks. In International Conference on Machine Learning (ICML), pp.\ 25333--25369, 2024. arXiv:2305.17212
arXiv 2024
-
[32]
Weight decay may matter more than P for learning rate transfer in practice
Atli Kosson, Jeremy Welborn, Yang Liu, Martin Jaggi, and Xi Chen. Weight decay may matter more than P for learning rate transfer in practice. In International Conference on Learning Representations (ICLR), 2026. arXiv:2510.19093
arXiv 2026
-
[33]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations (ICLR), 2019. arXiv:1711.05101
Pith/arXiv arXiv 2019
-
[34]
Markosyan, Luke Zettlemoyer, and Armen Aghajanyan
Kushal Tirumala, Aram H. Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. Memorization without overfitting: Analyzing the training dynamics of large language models. In Advances in Neural Information Processing Systems 35 (NeurIPS 2022), pp.\ 38274--38290, 2022. arXiv:2205.10770
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.