Calibrating Probabilistic Object Detectors with Annotator Disagreement
Pith reviewed 2026-06-30 13:06 UTC · model grok-4.3
The pith
Probabilistic object detectors can be calibrated to match annotator disagreement distributions without any ground truth annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
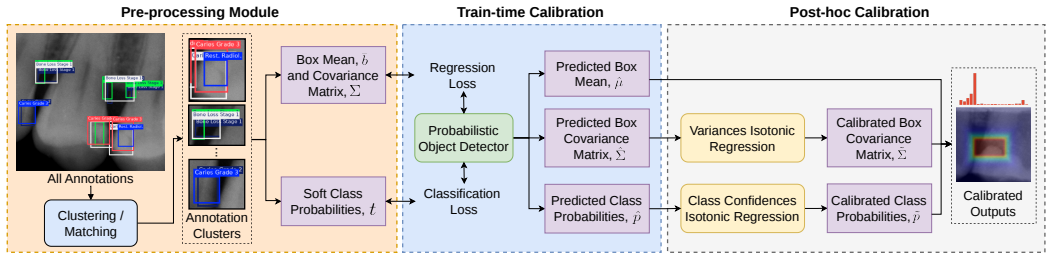
We introduce an interpretable calibration framework for probabilistic object detectors that aligns class confidence and bounding box variance to the annotators' annotation distribution using four evaluation metrics for classification and localization errors, along with train-time calibration and a post-hoc calibrator, all without requiring ground truth annotations.
What carries the argument
The calibration framework consisting of four metrics to measure calibration errors in classification and localization, plus train-time and post-hoc calibration procedures.
If this is right
- The framework generalizes to many probabilistic object detectors including YOLO families and two-stage detectors.
- It enables detectors to express meaningful predictive uncertainties for ambiguous objects.
- Empirical results show superior performance on real-world and synthetic datasets of medical and natural images.
- Calibration can be performed without access to any ground truth.
Where Pith is reading between the lines
- This approach may improve reliability in applications where object boundaries are inherently ambiguous, such as medical diagnosis.
- Future work could test if the calibrated uncertainties improve downstream decision-making in detection pipelines.
- Similar calibration ideas might apply to other vision tasks involving multiple annotations.
Load-bearing premise
The distribution of annotations from multiple annotators serves as an unbiased proxy for the true ambiguity in object detection.
What would settle it
Observing that the calibrated detector's uncertainty estimates do not match the spread of annotations from additional independent annotators on the same ambiguous objects would falsify the calibration effectiveness.
Figures


read the original abstract
High degrees of disagreement among annotators can exist for ambiguous objects, e.g. in medical images, underscoring the challenges of establishing ground truth annotations in object detection tasks. Despite this, all existing object detectors implicitly require access to ground truth annotations for either training or evaluation. The fundamental questions we target are: How can we learn an object detector with multiple annotators' annotations but without objective ground truth annotations due to object ambiguity, and how can we enable the learned detector to express meaningful model predictive uncertainties in detecting ambiguous objects? To answer these questions, we present an interpretable approach to calibrate probabilistic object detectors, where the calibration goal is to align the class confidence and bounding box variance estimates to the annotators' annotation distribution. We introduce an efficient yet effective framework to calibrate probabilistic object detectors by designing four evaluation metrics to measure calibration errors regarding classification and localization, and proposing a train-time calibration and post-hoc calibrator, all without the need to access any ground truth. This framework is generalizable to many existing probabilistic object detectors, such as the YOLO families and two-stage detectors. Empirical results with real-world and synthetic datasets of medical and natural images demonstrate the superior performance of the proposed framework with three popular object detectors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an interpretable calibration framework for probabilistic object detectors that aligns class confidence scores and bounding-box variance estimates to the empirical distribution of multiple annotators' annotations, without requiring objective ground truth. It defines four new evaluation metrics for classification and localization calibration error, proposes both a train-time calibration procedure and a post-hoc calibrator, shows generalizability to YOLO-family and two-stage detectors, and reports superior performance on real-world and synthetic medical and natural-image datasets.
Significance. If the metrics and calibration procedures can be shown to produce uncertainties that reflect latent object ambiguity rather than annotation artifacts, the work would meaningfully advance probabilistic detection in domains with high annotator disagreement such as medical imaging. The absence of free parameters in the core construction and the explicit handling of multiple annotations are positive features.
major comments (2)
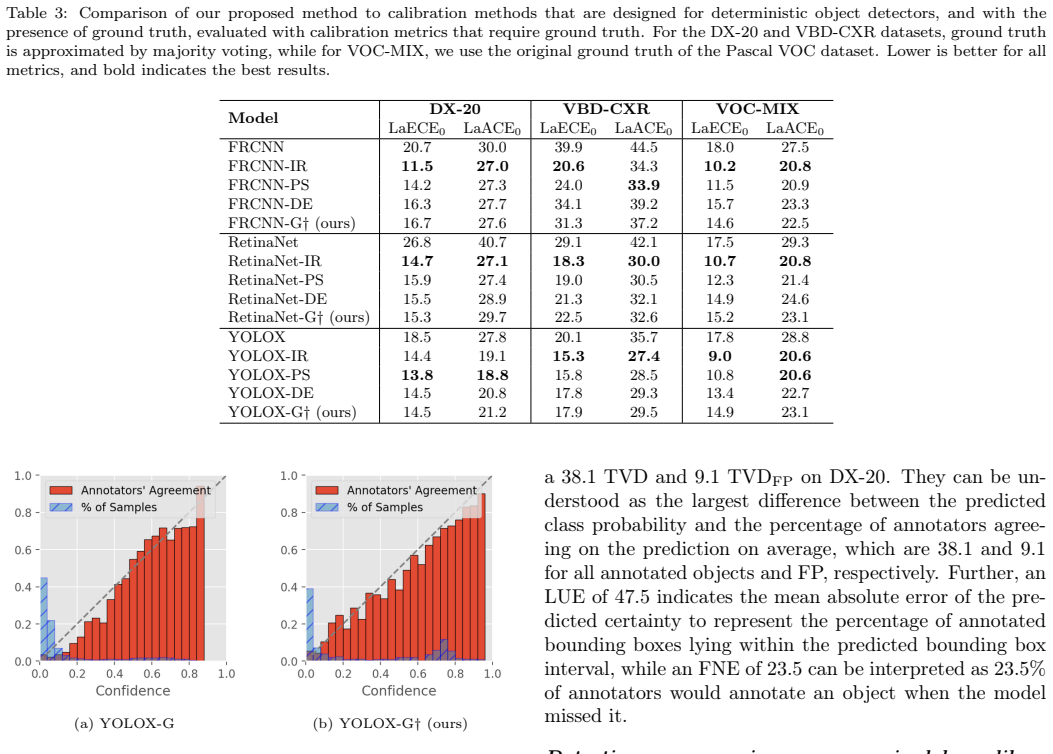
- [§3.2] §3.2 (Calibration Metrics): the four proposed calibration-error metrics are defined by direct comparison of model outputs to the same empirical class frequencies and bounding-box statistics computed from the annotator set that serves as the calibration target. This construction makes the reported error reduction equivalent to measuring how well the model reproduces the annotation distribution, rendering it impossible to distinguish genuine uncertainty calibration from reproduction of annotator-specific biases or label noise.
- [§4] §4 (Experiments): the evaluation protocol uses the same annotator-derived histograms for both training the calibrator and computing the four metrics on held-out images. Without an independent proxy for true ambiguity (e.g., expert consensus on a separate test set or downstream task performance), the claimed superiority over baselines may reflect in-distribution fitting rather than improved calibration.
minor comments (2)
- Notation for the four metrics is introduced without an explicit summary table; adding one would improve readability.
- The abstract states the framework is 'generalizable to many existing probabilistic object detectors' but the experiments only cover three specific models; a brief discussion of the minimal interface required for other detectors would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address the two major concerns point by point below, clarifying the design choices in the metrics and evaluation protocol.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Calibration Metrics): the four proposed calibration-error metrics are defined by direct comparison of model outputs to the same empirical class frequencies and bounding-box statistics computed from the annotator set that serves as the calibration target. This construction makes the reported error reduction equivalent to measuring how well the model reproduces the annotation distribution, rendering it impossible to distinguish genuine uncertainty calibration from reproduction of annotator-specific biases or label noise.
Authors: The metrics are intentionally defined against the empirical annotator distribution because the paper's explicit goal is to calibrate detectors to match observed annotator disagreement in the absence of objective ground truth. In settings such as medical imaging, where ambiguity is inherent, alignment with the distribution of multiple annotations constitutes the appropriate calibration target rather than an unintended artifact. The framework does not claim to recover an unobserved true label; it provides a measurable way to make model uncertainties consistent with annotator variability. We can add a clarifying sentence in §3.2 to emphasize this distinction. revision: partial
-
Referee: [§4] §4 (Experiments): the evaluation protocol uses the same annotator-derived histograms for both training the calibrator and computing the four metrics on held-out images. Without an independent proxy for true ambiguity (e.g., expert consensus on a separate test set or downstream task performance), the claimed superiority over baselines may reflect in-distribution fitting rather than improved calibration.
Authors: The protocol trains the calibrator on one partition of images and evaluates on held-out images, each using its own annotator-derived histograms; this avoids using identical data for fitting and scoring. The reported gains are measured relative to uncalibrated baselines and other methods that do not target the annotator distribution. While an external proxy for latent ambiguity would be valuable, the current design directly assesses fidelity to the observable calibration objective. We can expand the discussion in §4 to note the absence of downstream-task validation as a limitation. revision: partial
Circularity Check
No circularity: calibration explicitly defined against empirical annotator distribution as target
full rationale
The paper's framework is self-contained because it explicitly sets the calibration target and error metrics to be the empirical distribution of annotator annotations for both classification and localization, without any derivation chain that reduces a claimed prediction or first-principles result back to fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way; the method introduces new metrics and calibrators whose purpose is defined as matching the provided annotator statistics. This matches the standard setup for surrogate-ground-truth calibration tasks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotator annotations form a usable distribution for calibration targets in the absence of objective ground truth
invented entities (1)
-
Four evaluation metrics for classification and localization calibration errors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nguyen, D
D. Nguyen, D. B. Nguyen, H. Q. Nguyen, J. Elliott, N. T. Nguyen, P. Culliton, VinBigData chest x-ray abnormalities detection,https://kaggle.com/competitions/vinbigdata-chest-xray-abnormalities-detection, 2020. Kaggle
2020
- [2]
-
[3]
R. Dibo, A. Galichin, P. Astashev, D. V. Dylov, O. Y. Rogov, DeepLOC: Deep learning-based bone pathology localization and classification in wrist x-ray images, in: Proc. Anal. Images Social Netw. Texts, 2024, pp. 199–211
2024
-
[4]
Everingham, C
M. Everingham, C. K. I. W. Luc Van Gool, J. Winn, A. Zisserman, The PASCAL Visual Object Classes Challenge 2007 (VOC2007), Int. J. Comput. Vis. (IJCV) 88 (2010) 303–338
2007
-
[5]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, L. Zitnick, Microsoft COCO: Common objects in context, in: Proc. Eur. Conf. Comput. Vis. (ECCV), Zurich, Switzerland, 2014, pp. 740–755
2014
-
[6]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens, Z. Chen, D. Anguelov, Scalability in perception for autonomous driving: Waymo open dataset, in: Proc. IEEE Conf. Comput. Vis. Patte...
2020
-
[7]
Quinn, K
L. Quinn, K. Tryposkiadis, J. Deeks, H. C. De Vet, S. Mallett, L. B. Mokkink, Y. Takwoingi, S. Taylor-Phillips, A. Sitch, Interobserver variability studies in diagnostic imaging: a methodological systematic review, Brit. J. Radiol. 96 (2023) 20220972
2023
-
[8]
Tschirschwitz, F
D. Tschirschwitz, F. Klemstein, B. Stein, V. Rodehorst, A dataset for analysing complex document layouts in the digital humanities and its evaluation with krippendorff’s alpha, in: Proc. German Conf. Pattern Recog., Konstanz, Germany, 2022, p. 354–374
2022
-
[9]
Y. Hu, S. Meina, Crowd R-CNN: An object detection model utilizing crowdsourced labels, in: Proc. Int. Conf. Vis. Image Sig. Process. (ICVISP), Bangkok, Thailand, 2020, pp. 1–7
2020
-
[10]
K. Le, T. Tran, H. Pham, H. Nguyen Trung, T. Le, H. Q. Nguyen, Learning from multiple expert annotators for enhancing anomaly detection in medical image analysis, IEEE Access 11 (2023) 14105–14114
2023
-
[11]
Z. Q. Tan, O. Isupova, G. Carneiro, X. Zhu, Y. Li, Bayesian detector combination for object detection with crowdsourced annotations, in: Proc. Eur. Conf. Comput. Vis. (ECCV), Milan, Italy, 2024, pp. 329–346
2024
-
[12]
Kuppers, J
F. Kuppers, J. Kronenberger, A. Shantia, A. Haselhoff, Multivariate Confidence Calibration for Object Detection, in: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) Worksh., 2020, pp. 1322–1330
2020
-
[13]
Oksuz, T
K. Oksuz, T. Joy, P. K. Dokania, Towards building self-aware object detectors via reliable uncertainty quantification and calibration, in: Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Vancouver, Canada, 2023, pp. 9263–9274
2023
-
[14]
Mehrtash, W
A. Mehrtash, W. M. Wells, C. M. Tempany, P. Abolmaesumi, T. Kapur, Confidence calibration and predictive uncertainty estimation for deep medical image segmentation, IEEE Trans. Med. Imag. 39 (2020) 3868–3878
2020
-
[15]
X. Chen, X. Wang, K. Zhang, K.-M. Fung, T. C. Thai, K. Moore, R. S. Mannel, H. Liu, B. Zheng, Y. Qiu, Recent advances and clinical applications of deep learning in medical image analysis, Med. Image Anal. 79 (2022) 102444
2022
-
[16]
Gawlikowski, C
J. Gawlikowski, C. R. N. Tassi, M. Ali, J. Lee, M. Humt, J. Feng, A. Kruspe, R. Triebel, P. Jung, R. Roscher, M. Shahzad, W. Yang, R. Bamler, X. X. Zhu, A survey of uncertainty in deep neural networks, Artif. Intell. Rev. 56 (2023) 1513–1589
2023
-
[17]
D. Feng, L. Rosenbaum, C. Glaeser, F. Timm, K. Dietmayer, Can we trust you? on calibration of a probabilistic object detector for autonomous driving, in: Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), Macao, China, 2019
2019
-
[18]
M. K. Nowak, J. Cyranka, N. Maslany, A. Kostuch, J. Derbisz, M. Komorkiewicz, P. Siwck, M. J. Wojcik, D. Marchewka, P. Skruch, How Much Noise is There in Labels Generated by Humans? A Method to Validate Automatically Generated Bounding Boxes , in: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) Worksh., Los Alamitos, CA, USA, 2025, pp. 4371–4380
2025
-
[19]
Tschirschwitz, V
D. Tschirschwitz, V. Rodehorst, Label Convergence: Defining an Upper Performance Bound in Object Recognition Through Contradictory Annotations , in: Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), Tucson, AZ, USA, 2025, pp. 6848–6857. 19
2025
-
[20]
D. Zhou, J. Li, J. Li, J. Huang, Q. Nie, Y. Liu, B.-B. Gao, Q. Wang, P.-A. Heng, G. Chen, Distribution-aware calibration for object detection with noisy bounding boxes, in: Proc. Brit. Mach. Vis. Conf. (BMVC), Glasgow, UK, 2024
2024
-
[21]
Murrugarra-Llerena, C
J. Murrugarra-Llerena, C. R. Jung, Noise-aware evaluation of object detectors, in: Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), Tucson, AZ, USA, 2025, pp. 9322–9331
2025
-
[22]
H. Su, J. Deng, L. Fei-Fei, Crowdsourcing annotations for visual object detection, in: AAAI Workshop, Human Computation, Ontario, Canada, 2012, pp. 40–46
2012
-
[23]
C. Guo, G. Pleiss, Y. Sun, K. Q. Weinberger, On calibration of modern neural networks, in: Proc. Int. Conf. Mach. Learn. (ICML), Sydney, Australia, 2017, pp. 1321–1330
2017
-
[24]
Kumar, P
A. Kumar, P. S. Liang, T. Ma, Verified uncertainty calibration, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), volume 32, Vancouver, Canada, 2019
2019
-
[25]
Nixon, M
J. Nixon, M. W. Dusenberry, L. Zhang, G. Jerfel, D. Tran, Measuring calibration in deep learning, in: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) Worksh., Long Beach, CA, USA, 2019, pp. 38–41
2019
-
[26]
Mukhoti, V
J. Mukhoti, V. Kulharia, A. Sanyal, S. Golodetz, P. H. S. Torr, P. K. Dokania, Calibrating deep neural networks using focal loss, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), 2020, pp. 15288–15299
2020
-
[27]
D.-B. Wang, L. Feng, M.-L. Zhang, Rethinking calibration of deep neural networks: Do not be afraid of overconfidence, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), 2021, pp. 11809–11820
2021
-
[28]
Kuzucu, K
S. Kuzucu, K. Oksuz, J. Sadeghi, P. K. Dokania, On calibration of object detectors: Pitfalls, evaluation and baselines, in: Proc. Eur. Conf. Comput. Vis. (ECCV), Milan, Italy, 2024
2024
-
[29]
Y.-J. Park, C. Sobolewski, N. Azizan, Uncertainty quantification in detection transformers: Object-level calibration and image-level reliability, 2026.arXiv:2412.01782
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
M. A. Munir, M. H. Khan, M. Sarfraz, M. Ali, Towards improving calibration in object detection under domain shift, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), New Orleans, LA, USA, 2022, pp. 38706–38718
2022
-
[31]
Pathiraja, M
B. Pathiraja, M. Gunawardhana, M. H. Khan, Multiclass confidence and localization calibration for object detection, in: Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Vancouver, Canada, 2023, pp. 19734–19743
2023
-
[32]
M. A. Munir, S. Khan, M. H. Khan, M. Ali, F. Khan, Cal-DETR: Calibrated detection transformer, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), New Orleans, LA, USA, 2023
2023
-
[33]
M. A. Munir, M. H. Khan, S. Khan, F. S. Khan, Bridging precision and confidence: A train-time loss for calibrating object detection, in: Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Vancouver, Canada, 2023, pp. 11474–11483
2023
-
[34]
Popordanoska, A
T. Popordanoska, A. Tiulpin, M. B. Blaschko, Beyond classification: Definition and density-based estimation of calibration in object detection, in: Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), Waikoloa, HI, USA, 2024, pp. 574–583
2024
-
[35]
K. P. Alexandridis, I. Elezi, J. Deng, A. Nguyen, S. Luo, Fractal calibration for long-tailed object detection, in: Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Nashville, TN, USA, 2025
2025
-
[36]
D. Hall, F. Dayoub, J. Skinner, H. Zhang, D. Miller, P. Corke, G. Carneiro, A. Angelova, N. Sünderhauf, Probabilistic object detection: Definition and evaluation, in: Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), Snowmass Village, CO, USA, 2020, pp. 1020–1029
2020
-
[37]
D. Feng, A. Harakeh, S. L. Waslander, K. Dietmayer, A review and comparative study on probabilistic object detection in autonomous driving, IEEE Trans Intell. Transportation Syst. 23 (2022) 9961–9980
2022
-
[38]
Miller, L
D. Miller, L. Nicholson, F. Dayoub, N. Sünderhauf, Dropout sampling for robust object detection in open-set conditions, in: Proc. IEEE Int. Conf. Robot. Automat. (ICRA), Brisbane, Australia, 2018, pp. 3243–3249
2018
-
[39]
Miller, F
D. Miller, F. Dayoub, M. Milford, N. Sünderhauf, Evaluating merging strategies for sampling-based uncertainty techniques in object detection, in: Proc. IEEE Int. Conf. Robot. Automat. (ICRA), Montreal, Canada, 2019, pp. 2348–2354
2019
-
[40]
Z. Lyu, N. Gutierrez, A. Rajguru, W. J. Beksi, Probabilistic object detection via deep ensembles, in: Eur. Conf. Comput. Vis. (ECCV) Workshop, 2020, pp. 67–75
2020
-
[41]
R. M. Neal, Bayesian Learning for Neural Networks, Springer-Verlag, 1996
1996
-
[42]
IEEE Intell
M.T.Le, F.Diehl, T.Brunner, A.Knoll, Uncertaintyestimationfordeepneuralobjectdetectorsinsafety-criticalapplications, in: Proc. IEEE Intell. Transportation Syst. Conf., Maui, HA, USA, 2018, pp. 3873–3878. 20
2018
-
[43]
J. Choi, D. Chun, H. Kim, H.-J. Lee, Gaussian YOLOv3: An accurate and fast object detector using localization uncertainty for autonomous driving, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Seoul, Korea, 2019, pp. 502–511
2019
-
[44]
Y. He, C. Zhu, J. Wang, M. Savvides, X. Zhang, Bounding box regression with uncertainty for accurate object detection, in: Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Long Beach, CA, USA, 2019, pp. 2883–2892
2019
-
[45]
Kraus, K
F. Kraus, K. Dietmayer, Uncertainty estimation in one-stage object detection, in: Proc. IEEE Intell. Transportation Syst. Conf., Auckland, New Zealand, 2019, pp. 53–60
2019
-
[46]
Harakeh, M
A. Harakeh, M. Smart, S. L. Waslander, Bayesod: A bayesian approach for uncertainty estimation in deep object detectors, in: Proc. IEEE Int. Conf. Robot. Automat. (ICRA), 2020, pp. 87–93
2020
-
[47]
Y. He, J. Wang, Deep mixture density network for probabilistic object detection, in: Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), 2020, pp. 10550–10555
2020
-
[48]
Harakeh, S
A. Harakeh, S. L. Waslander, Estimating and evaluating regression predictive uncertainty in deep object detectors, in: Proc. Int. Conf. Learn. Represent. (ICLR), 2021
2021
-
[49]
S. Su, Y. Li, S. He, S. Han, C. Feng, C. Ding, F. Miao, Uncertainty quantification of collaborative detection for self-driving, in: Proc. IEEE Int. Conf. Robot. Automat. (ICRA), London, United Kingdom, 2023, pp. 5588–5594
2023
-
[50]
Ausiello, P
G. Ausiello, P. Crescenzi, G. Gambosi, V. Kann, A. Marchetti-Spaccamela, M. Protasi, Complexity and Approximation: Combinatorial Optimization Problems and Their Approximability Properties, Springer Publishing Company, 2013
2013
-
[51]
P. C. Mahalanobis, On the generalized distance in statistics, Proceedings of the National Institute of Sciences of India 2 (1936) 49–55
1936
-
[52]
A. B. Tsybakov, Introduction to Nonparametric Estimation, Springer Series in Statistics, Springer, New York, NY, USA, 2009, p. 83
2009
-
[53]
Krishnamoorthy, Normal distribution, in: Handbook of Statistical Distributions with Applications, CRC Press, Boca Raton, FL, USA, 2006, p
K. Krishnamoorthy, Normal distribution, in: Handbook of Statistical Distributions with Applications, CRC Press, Boca Raton, FL, USA, 2006, p. 151
2006
-
[54]
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), Montréal, Canada, 2015, pp. 91–99
2015
-
[55]
Z. Ge, S. Liu, F. Wang, Z. Li, J. Sun, YOLOX: Exceeding YOLO series in 2021, 2021.arXiv:2107.08430
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[56]
C.-Y. Wang, A. Bochkovskiy, H.-Y. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in: Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Vancouver, Canada, 2023, pp. 7464–7475
2023
-
[57]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollar, Focal loss for dense object detection, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Venice, Italy, 2017
2017
-
[58]
Robertson, F
T. Robertson, F. T. Wright, R. Dykstra, Order Restricted Statistical Inference, Wiley, 1988
1988
-
[59]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, E. Duchesnay, Scikit-learn: Machine learning in Python, J. Mach. Learn. Res. (JMLR) 12 (2011) 2825–2830
2011
-
[60]
Kendall, Y
A. Kendall, Y. Gal, What uncertainties do we need in bayesian deep learning for computer vision?, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), Long Beach, California, USA, 2017, pp. 5580––5590
2017
-
[61]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, Pytorch: An imperative style, high-performance deep learning library, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIP...
2019
-
[62]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, C. Blundell, Simple and scalable predictive uncertainty estimation using deep ensembles, in: Proc. Adv. Neural Inform. Process. Syst. (NeurIPS), Long Beach, California, USA, 2017, pp. 6405—-6416
2017
-
[63]
Oksuz, B
K. Oksuz, B. C. Cam, S. Kalkan, E. Akbas, One metric to measure them all: Localisation recall precision (LRP) for evaluating visual detection tasks, IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 44 (2022) 9446–9463. 21
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.